Kettle日常使用汇总整理
Kettle日常使用汇总整理
Kettle源码下载地址:
https://github.com/pentaho/pentaho-kettle
Kettle软件下载地址:
https://sourceforge.net/projects/pentaho/files/Data%20Integration
kettle-plugin源码下载地址:
kettle-big-data-plugin源码下载地址:
https://github.com/pentaho/big-data-plugin
Kettle帮助文档下载地址:
一、如何将kettle部署到linux中去:(以root用户操作为例)
1、将window中正常使用的kettle的data-integration文件夹压缩成tar包;
2、将tar包上传到linux的指定文件夹中去;
3、利用tar命令将tar包进行解压;
4、运行./kitchen.sh命令,出现options内容,表示部署正常:

5、将连接数据库的驱动jar包换到对应的linux文件夹中,不然会连接不到数据库;
6、通过以上步骤,就可以完成对kettle在linux上的部署工作;
二、如何在Linux上登录kettle的文件资源库或数据库资源库:
说明:在window中可以通过可视化界面来登录kettle的资源库,在linux中没有可视化界面,windows中kettle的资源库信息是存储在一个配置文件中的,只需要将该配置文件上传到linux中指定文件位置即可,在执行某个转换或作业的时候,在命令中输入相应的资源库即可;
1、找到window中存储kettle资源库信息的配置文件:
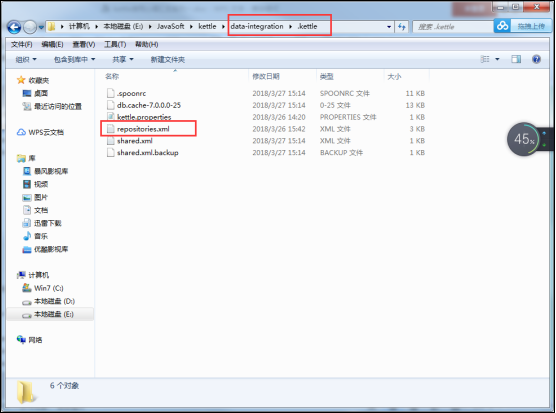
2、如果是文件库资源库,那么需要修改该配置文件中文件的路径:
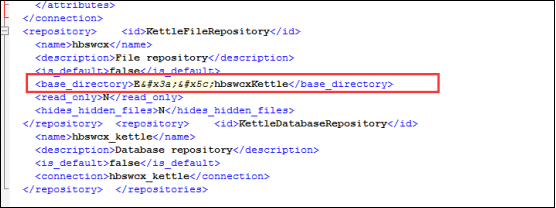
3、如果是数据库资源库,那么不需要修改任何内容;
4、将该配置文件上传到linux中部署kettle用户文件下隐藏的.kettle文件夹下,本人是利用root用户部署的,因此放在/root/.kettle文件夹下即可:
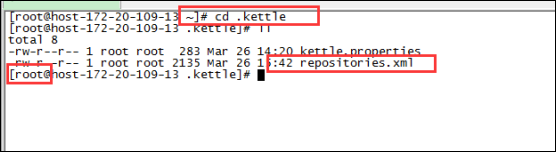
5、通过以上几步,可以完成kettle资源库从window迁移到linux上;
三、Window中kettle的文件资源库如何在linux中执行:
1、首先要完成kettle中作业或转换所在的资源库迁移到linux上;
2、将需要执行的转换或作业文件迁移到linux中指定的文件资源库中去;

3、如果转换中还有数据库连接,那么需要将存储有数据库连接的配置文件也上传到linux上:(.kdb格式文件就是数据库配置文件)

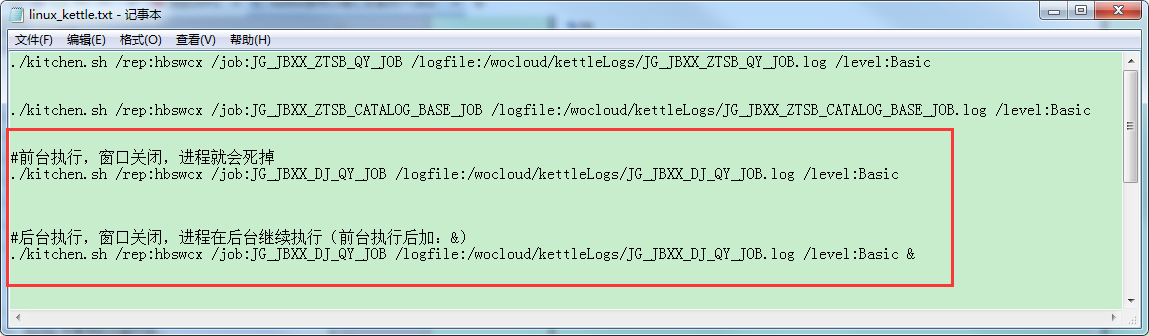
4、然后登录linux,进入到Kettle的data-integration文件夹下,就可以通过百度linux kettle 命令行 ktr/job进行执行了。
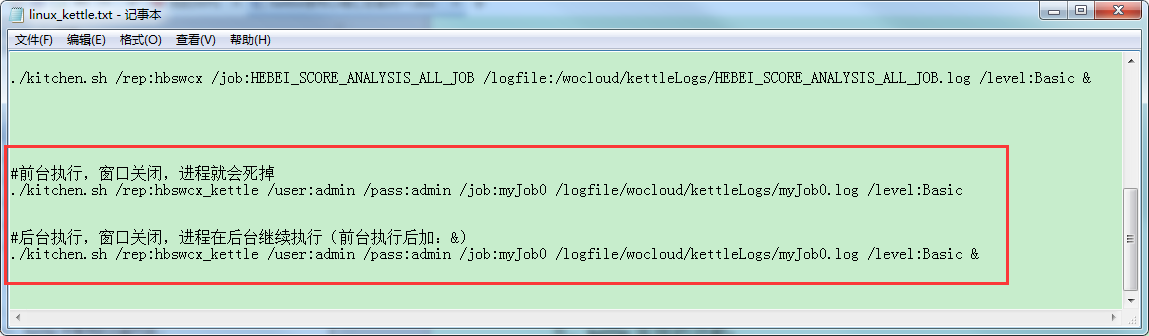
命令例子:
四、Window中kettle的数据库资源库如何在linux中执行:
1、首先,完成对window中登录数据库资源库配置文件上传到Linux中对应的位置;
2、然后登录linux,进入到Kettle的data-integration文件夹下,就可以通过百度linux kettle 命令行 ktr/job进行执行了。
命令例子:
五、Kettle文件资源库与数据库资源库内容如何转换:
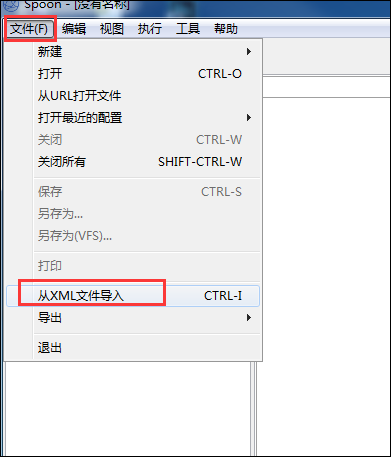
1、文件资源库导入到数据库资源库:
(1)首先,在kettle软件中登录到数据库资源库;
(2)然后,文件---从xml文件中导入,选择自己要导入的作业或转换,然后ctrl+s保存即可;
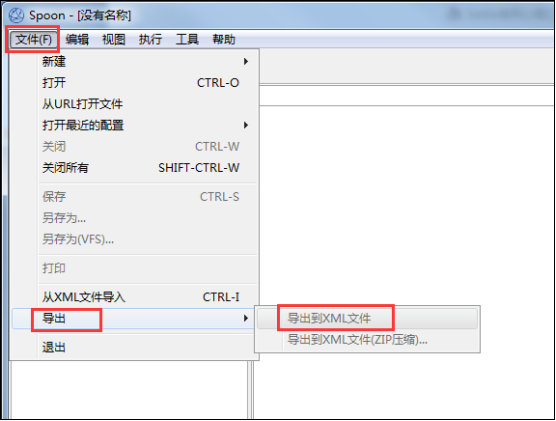
2、数据库资源库导入到文件资源库:
(1)首先,在kettle软件中登录到数据库资源库;
(2)然后,文件---导出-----导出到xml文件即可;
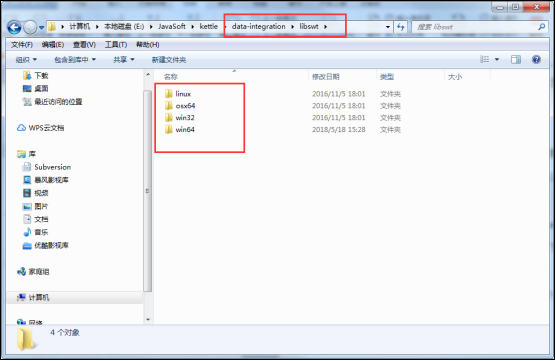
六、Kettle连接不同数据库驱动jar包放置位置:
Kettle软件部署在不同操作系统中,连接各种数据库的驱动jar包防止的位置是不同的,与操作系统有关,不同的操作系统上,驱动jar包放在对应的文件夹中即可,如下图:
七、kettle实现的功能:
kettle可以实现从不同数据源(excel、数据库、文本文件等)获取数据,然后将数据进行整合、转换处理,可以再将数据输出到指定的位置(excel、数据库、文本文件)等;
通过kettle处理大量数据非常方便,如果window服务器或者Linux服务器硬件一般情况下,对于处理千万级一下的数据都是可以的;
八、Kettle作业与转换如何配合使用:
1、一个作业相当于一个主要任务项,在这个主线中可以调用其它若干个转换,每个转换中可以从作业这个主线中获取数据,然后将数据进行相应的处理操作,再将数据传递给作业主线,也可以在转换中单独获取数据------处理数据------输出数据;
2、并且如果对于需要设置变量的情况下,一般也是需要用到作业与转换的配合使用,因为变量在当前线中设置,不能再当前线中获取,需要到下一个线中才能够获取;
3、一个任务只能够有一个主作业,但是可以有多个子作业,主作业中可以调用转换,也可以调用子作业,具体是调用转换还是调用子作业,需要根据不同的需求,进行不同的定制;
九、Kettle中设置编码格式:
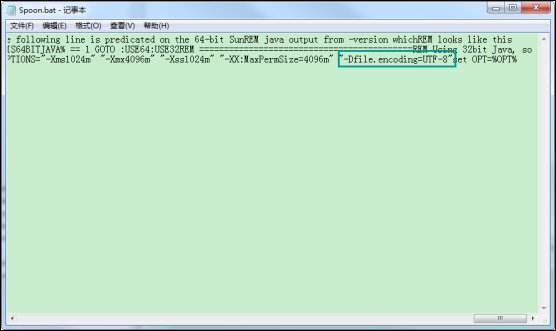
如果处理的数据中有中文,需要对中文设置编码格式,一般是utf8格式,彻底的修改格式的方法就是,修改spoon.bat文件中增加如下信息:"-Dfile.encoding=UTF-8";
十、Kettle中调整运行性能:
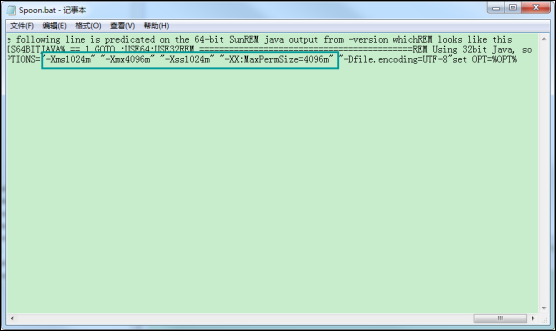
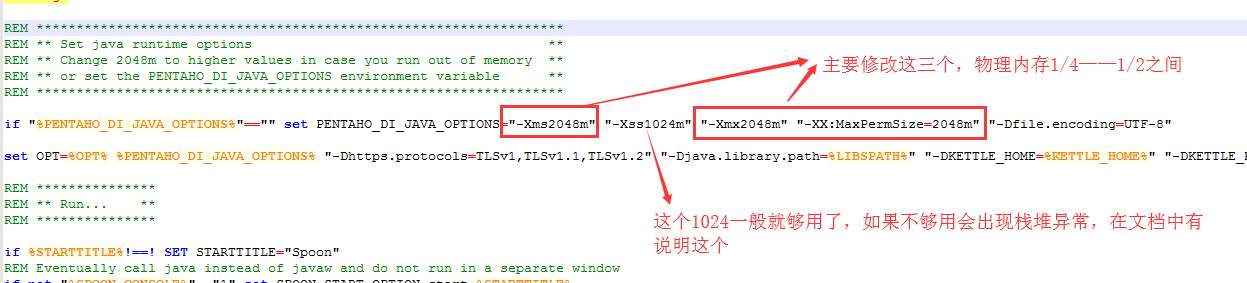
Kettle默认的性能适用于普通的一般硬件,如果自己的电脑硬件比较好(内存比较大),可以对kettle的spoon.bat中的参数进行修改,这样可以适当的提高kettle的运行性能,主要是修改-Xms、-Xmx、-XX:MaxPermSize三个参数的值:
-Xms:设置JVM初始内存 ;
-Xmx:设置JVM最大可用内存 ;
-XX:MaxPermSize:设置JVM最大允许分配内存,按需分配;
非常注意:
1、 -Xmx必须小于等于系统内存的1/4,要不然会报错,其他两个选项不大于-Xmx ;
2、当系统内存为4G时-Xmx不能大于1G,当系统内存为8G或更大时,java版本必须是64位的才能识别出来,此时-Xmx可以为2G或更高
自己配置的信息:window服务器内存8G:
-XX:MaxPermSize = -Xmx = 4096m;
-Xms = 1024m
十一、Kettle中常用的控件:
(1)作业中常用控件:
1、通用——START:作业开始;
2、通用——作业:指定某个作业循环执行;
3、通用——转换:指定某个转换,加入到作业中来;
4、通用——设置变量:设置变量,为了转换或者作业中获取变量;
5、通用——成功:作业完成操作;
6、通用——DUMMY:空操作,什么也不执行;
7、邮件——发送邮件:给指定邮箱发送邮件,发件人的账号需要开通第三方发送邮件的功能;
8、文件管理——复制/移动结果文件:复制/移动文件;
9、文件管理——创建一个目录:创建指定的目录;
10、文件管理——删除一个文件:删除指定的一个文件;
11、文件管理——复制文件:复制指定的文件;
12、文件管理——删除目录:删除指定的目录;
13、文件管理——删除多个文件:通过正则表达式批量删除文件;
14、条件——检查数据库连接:检查数据库是否能够连接通;
15、条件——检查表是否存在:检查指定的表是否存在;
16、文件传输——SFTP下载:可以通过SSH进行远程下载文件;
17、文件传输——SFTP上传:可以通过SSH进行远程上传文件;
18、文件传输——FTP删除:可以远程删除指定的文件;
(2)转换中常用控件:
1、输入——Excel输入:从excel文件中读取数据;
2、输入——文本文件输入:从文本文件中读取数据;
3、输入——生成随机数:用来生成指定类型的随机数;
4、输入——自定义数据常量:将值不变的变量存入到此处,方便管理;
5、输入——获取系统信息:可以获取系统信息(日期、命令行参数);
6、输入——表输入:从数据库表中读取数据;
7、输出——Excle输出:注意.xls格式输出行数有限制,一般输出.xlsx最好;
8、输出——插入/更新:根据指定的匹配字段,可以检测是插入新数据,还是修改旧数据;
9、输出——文本文件输出:将结果数据输出到文本文件中去;
10、输出——表输出:将结果数据输出到某个数据库的某个表中;
11、转换——增加常量:在原数据中将常量值增加新一列;
12、转换——排序记录:对原数据按照某个字段进行排序;
13、转换——剪切字符串:对字符串进行截图;
14、转换——去重复记录:对于某个字段有重复的记录进行过滤;
15、转换——字段选择:筛选流中的字段,慎用,过滤后后面的控件将无法获取流中筛除的字段了;
16、流程——空操作:将不需要的数据放到此处,类似垃圾箱;
17、流程——过滤记录:按照条件进行过滤,类似if-else;
18、流程——Switch/Case:与java中switch/case一样;
19、脚本——java代码:执行java代码;
20、脚本——javascript代码:执行javascript代码;
21、脚本——执行SQL脚本:执行sql;
22、连接——记录集连接:类似于sql的left join/right join/inner join,但是使用前的数据必须要经过排序;
23、作业——从结果获取记录:从作业中获取数据;
24、作业——复制记录到结果:将转换中的结果数据放到作业中去;
25、作业——获取变量:从作业中获取变量;
26、作业——设置变量:设置变量,从而让作业中能够获取变量;
十二、Kettle中javascript脚本执行:
在javascript脚本中可以直接定义变量,可以直接从上一个控件中获取值,获取值的方法直接写前一个控件中某列的列明就好,定义的变量在后续的控件中都可以直接获取:
十三、Kettle中常用的功能代码:
1、javascript生成uuid的代码:
var uuid = replace(java.util.UUID.randomUUID(),"_","");
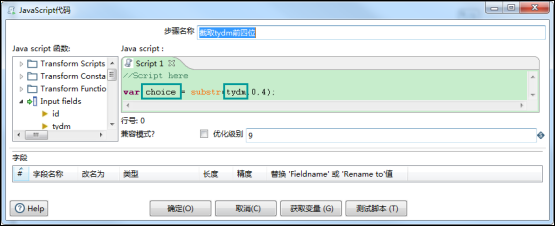
2、Javascript截取前一个控件中某个字段的长度,获取另外一个变量:
var choice = substr(tydm,0,4);
0:开始截取的角标;4:表示截取的长度;
十四、Kettle中常见的异常处理:
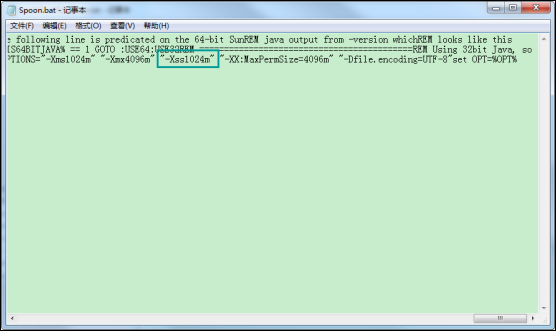
1、异常类型:java.lang.stackOverFlowError
原因:栈溢出,可能是在处理的数据比较大,栈默认值不够使用了;
解决方法:修改kettle中的启动项spoon.bat中的信息,添加一个Xss=1024m即可解决,如果还不够,可根据硬件来适当增加值;
2、中文输出乱码问题:
设置编码格式,具体操作上述有步骤;
3、连接不上数据库,报java.lang.NullPointerException异常:
原因:kettle中放置的连接数据库的驱动jar包版本低于要连接的数据库版本;
解决方法:首先查看自己要连接的数据库版本,然后选择驱动jar包版本要对应或者高于但要最接近于数据库版本的jar包即可解决;
4、启动kettle:Prepared statement contains too many placeholders
表输出每次提交的设置数量太高了,降低每次输出数量即可解决问题;
5、正常运行一会突然报错:Communications link failure
错误一:
java.net.SocketException: Connection reset by peer: socket write error
错误二:
com.mysql.jdbc.exceptions.MySQLNonTransientConnectionException: Communications link failure during commit(). Transaction resolution unknown.
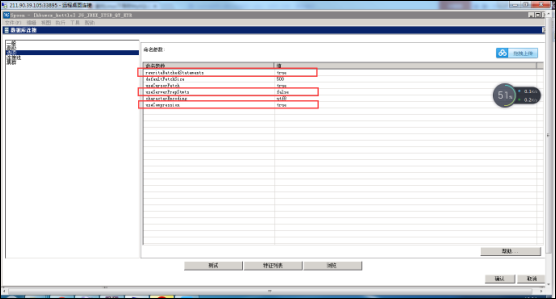
产生上述两个错误的原因:可能是kettle默认使用的是服务端提供的statement,因为一些原因服务端可能会关闭statement,因此要对连接的数据库设置一些参数,使用kettle自身提供的statement就可以
(1)解决问题:设置参数如下:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
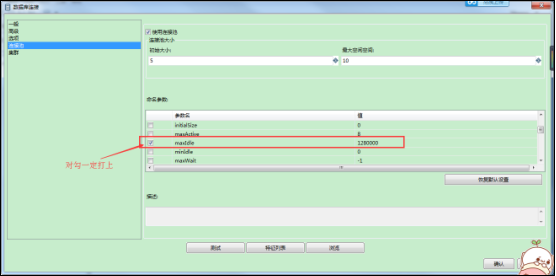
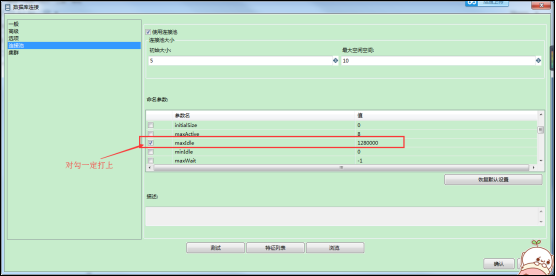
(2)如果使用连接池,并将连接池总的maxIDle数值设的比较大:
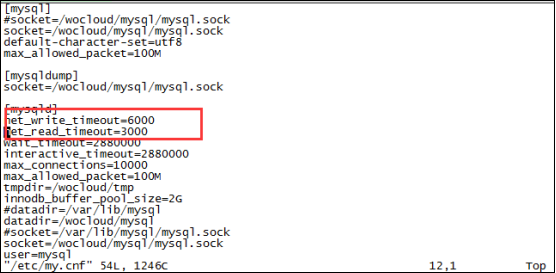
(3)对数据库中的net_write_timeout和net_read_timeout设置大点,即修改my.cnf配置文件中参数值的大小,如果没有该参数,自己增加即可:
如果还是报错,可能是服务器性能不好,稍等一会或者第二天再尝试,就可能好了。
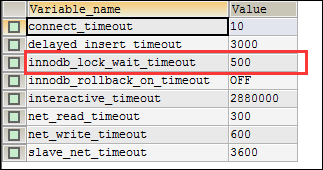
(4)如果数据量多,请求有修改,可能是锁了sql了,需要将innodb_lock_wait_timeout值设置大点,如果数据量特别大,那就值更大点。就可以解决问题了。
6、运行速度慢,卡,解决方法是:增加内存:
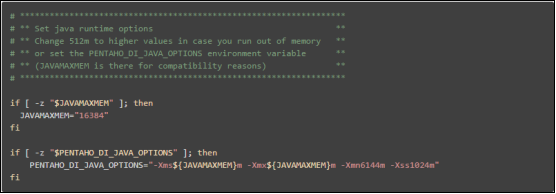
(1)JAVAMAXMEM:为物理内存的1/4,如果物理内存在16g以上,最大可以尝试1/2;
(2)Xms和Xmx:等于JAVAMAXMEM的大小;
(3)Xmn:为xmx的3/8
(4)Xss:一般1024够了,主要是防止StackOverFlowError出现的。
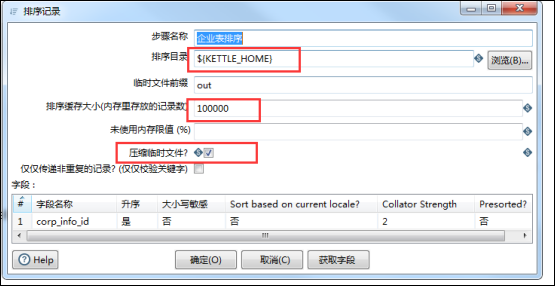
7、多张表关联插入时,报:Unable to write value data to output stream,No space left on device:(临时文件输出到指定地方,该地方磁盘空间不够)
解决方法:
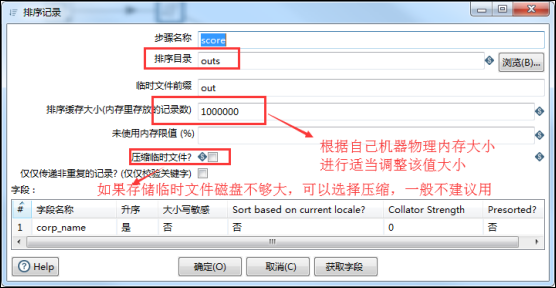
(1)将排序目录指定到一个磁盘比较大的位置;
(2)将排序缓存大小设置的适当小点;
(3)将临时文件进行压缩;
(4)排序目录默认的就是系统配置的kettle_home的路径,一般直接写outs就行,并在kettle_home路径下创建一个outs文件夹即可;
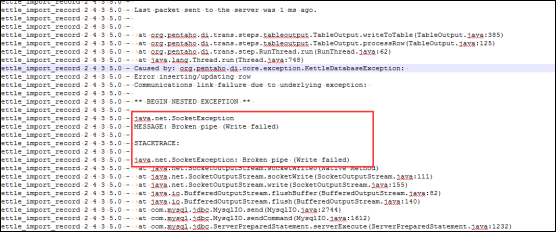
8、异常:java.net.SocketException: Broken pipe (Write failed):
(1)可能是kettle用的mysql-connection的jar包版本问题,换个与mysql数据库最接近的jar包版本。
(2)可能是某一个转换中用了事物,应该去掉事物的。
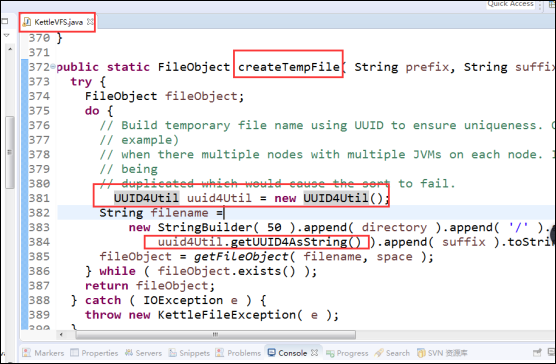
9、java.lang.ClassNotFoundException: org.safehaus.uuid.UUIDGenerator
原因1:kettle作业用生成UUID随机数使用的是UUID,把UUID改成UUID4就可以解决问题了。
原因2:如果是数据写入临时文件时出现这个异常,那么就需要修改Kettle的源码了,然后将编译后的.class文件放在kettle-core的jar包中对应的文件夹下进行替换即可:
10、大量数据修改出现异常:lock wait timeout exceeded
解决方法:给数据配置以下信息:
net_read_timeout=28800
net_write_timeout=28800
innodb_lock_wait_timeout=500
十五、Kettle解析XML文件获取数据:
1、核心思路:就是指定要循环读取XML的路径,并指定该路径下每个字段对应的路径,以便kettle能够循环读取XML中的数据,从而获取所有记录中不同字段的值。
2、具体步骤如下:
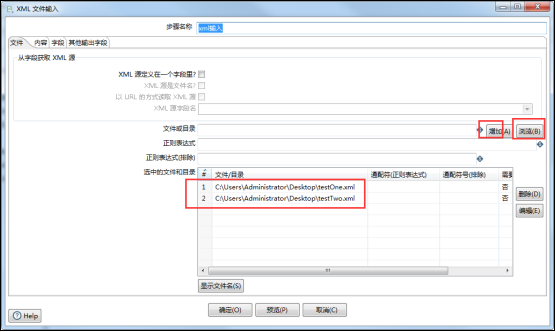
(1)选择XML文件路径(如果文件中各种节点路径一模一样,可以选择多个文件,也可以通过正则表达式等选择一定规则的多个文件):
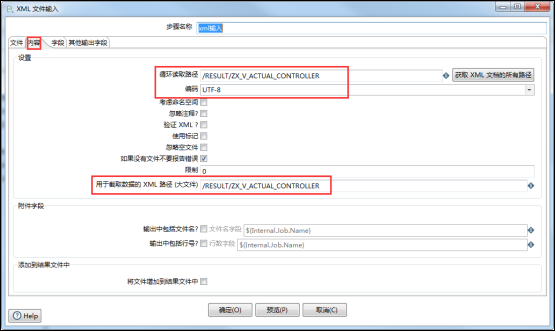
(2)指定要循环读取的XMP路径,主要是从根节点开始到哪个节点需要循环读取:
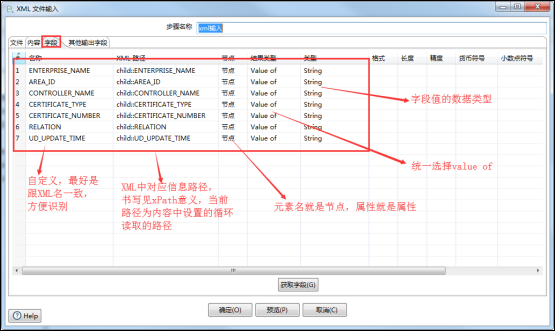
(3)指定每次读取节点下的各个字段的名称、路径(书写参照xPath意义)、属性、数据类型等属性:
(4)通过以上三步的操作,便可以完成简单的XML文件读取。
十六、使用kettle时必须要注意并且做到的几个要点:
1、检查连接数据库的驱动版本,要做到jar包的版本和数据库版本尽量接近;
2、创建数据库连接的url中必须加上以下两个参数:
?autoReconnect=true&failOverReadOnly=false
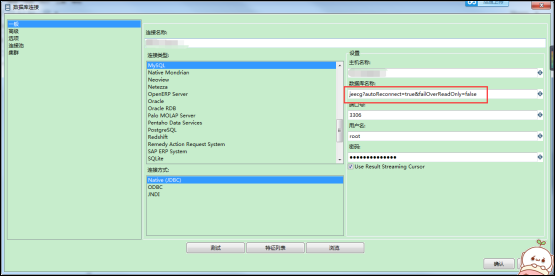
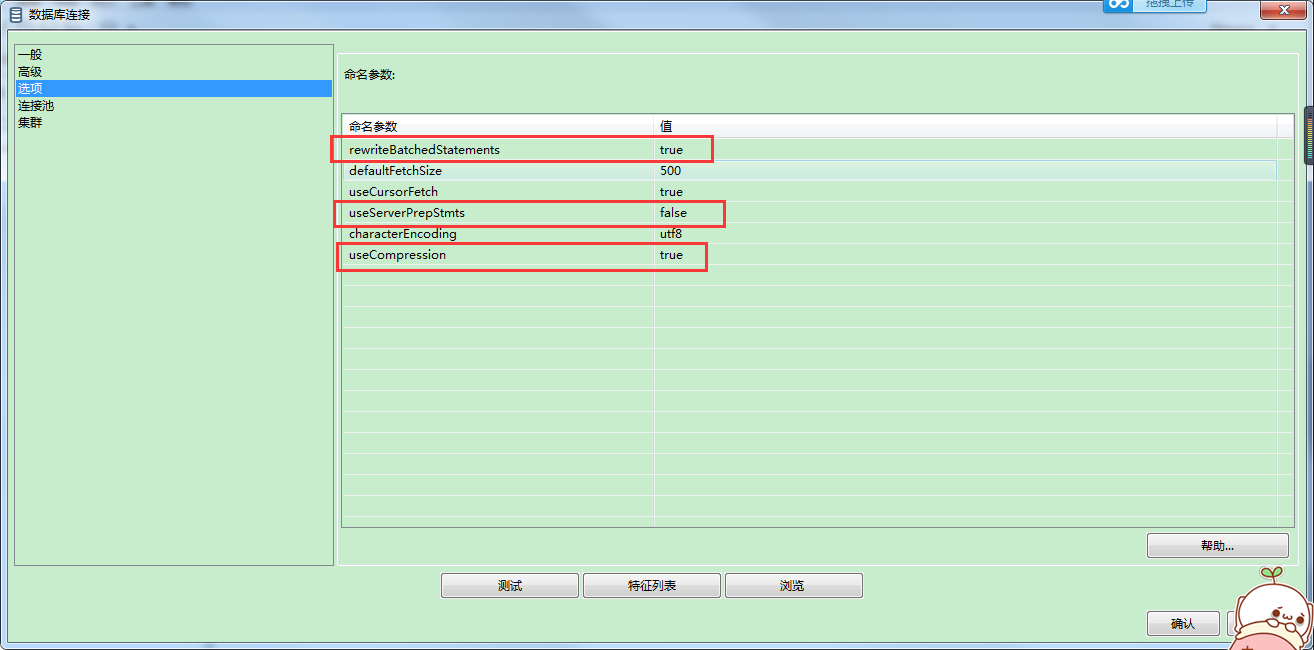
3、创建数据库连接的参数中必须加上以下三个参数:(用于增加数据写入速度)
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
4、创建数据库连接,如果使用的连接池,必须设置maxIdl值较大:
5、必须根据kettle软件所在的硬件,修改spoon.bat(window)或spoon.sh(linux)的内存大小:
Window:
Linux:
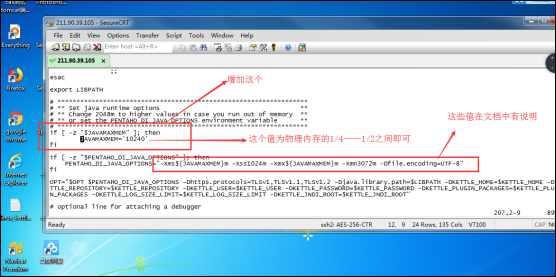
6、能用控件处理的,就尽量不要写js或java等处理了:比如uuid的生成等;
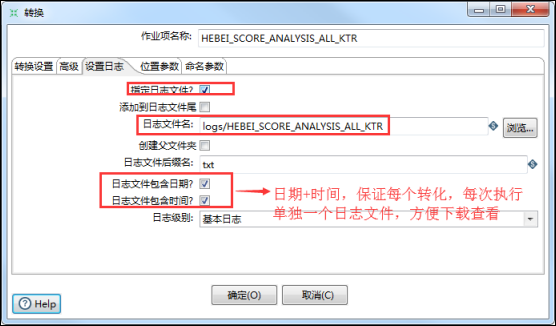
7、在作业中调用的任何一个转换,都要将该转换输出到data-integration/logs文件夹下,参数设置如下:(在kettle转换和作用中,默认的当前目录就是KETTLE_HOME设定的data-integration目录下)
8、在转换中,如果用到了对记录进行排序,将排序目录设置在data-integration/outs文件夹,参数设置如下:(在kettle转换和作用中,默认的当前目录就是KETTLE_HOME设定的data-integration目录下)
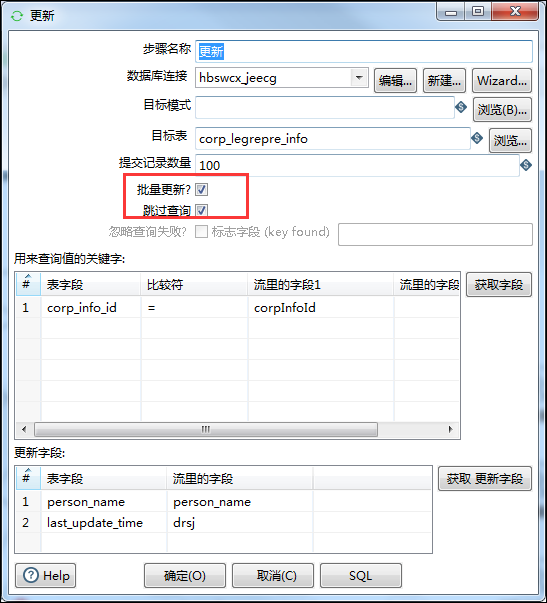
9、如果用到更新的时候,一定要选择批量?跳过查询两个勾选:这样可以提高更新的速度。
10、生成随机数一定要用UUID4,否则管理平台调用会出现问题。
11、在每一个作业中,最好使用一个发邮件功能,在开始和成功中间任何一个步骤到发出一个异常流程,指向发邮件,这样如果作业中任何一个环节出现异常,就会自动给指定的邮箱进行发送邮件(非常注意:发送邮件的发送邮箱一定要开通第三方授权码,通过授权码作为密码来发送功能)
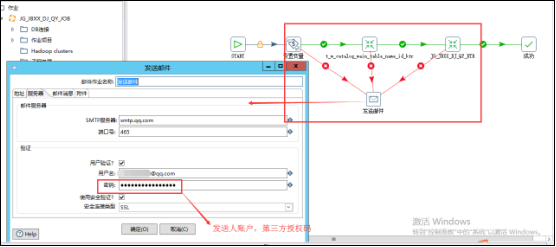
12、在每一个作业开始执行时,都要添加一个检查数据库连接控件,用来检查该作业中所有用到的数据库连接是否能够正常连接,如果连接不上,则可以通过发送邮件进行提醒,如果不检查的话,数据库因为网络通信问题连接不上,kettle作业中的异常是不会发送邮件的:
非常注意:如果检测的是多个数据库连接,那么只有所有的数据库都能连接上,才算是正确,如果有任何一个数据库连接不上,都会是异常。

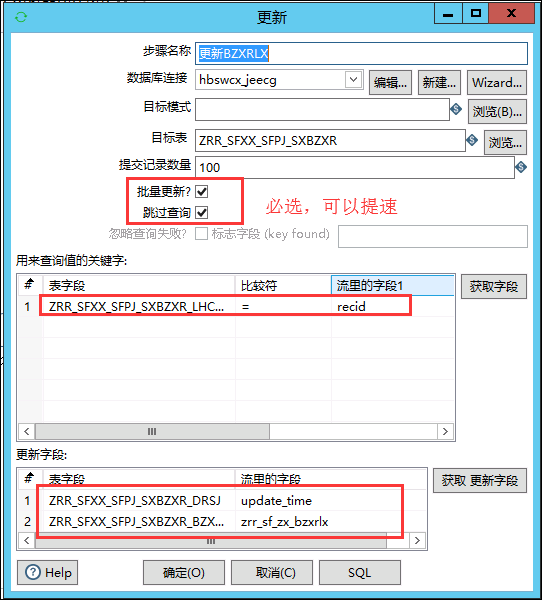
13、如果用Kettle做大量数据,很多字段的更新的话,如果用简单的更新控件,更新速度非常的慢,通过经验发现,通过这样处理,可以增加更新的效率,缺点就是操作人员写作业时间较长:
(1)不是更新所有字段,而是先判断该字段是否发生变化,如果发生变化了就只更新该字段+更新时间,两个字段值;
(2)因此需要对获取的记录通过复制的方式,分发给不同字段判断的过滤条件控件;
(3)在更新控件中,一定要勾选批量更新、跳过查询,可以提高速度。
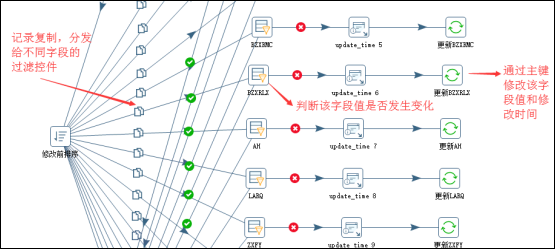
14、设置的变量作用范围:核心一点,最好就是变量的作用范围为当前作业,尤其对于费定时任务,有可能多个作业同时启动的,一定要将变量的作用范围设定在当前作业中,如果设置变量的操作是在一个转换中,然后一个作业进行调用这个转换,那么变量的作用范围就是parent-job,一般不选择整个JVM,具体情况,根据设定变量这个操作的位置不同,决定其作用范围的设置,一句话,一个作业中的变量作用范围,最好就是在该作业内有效。
十七、利用kettle实现动态迁移整个数据库:
1、主题思路:
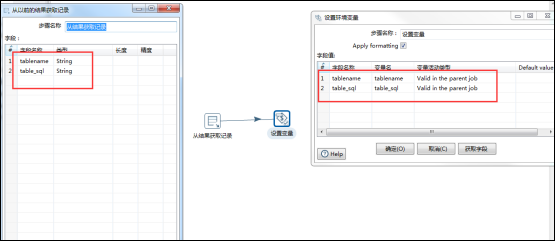
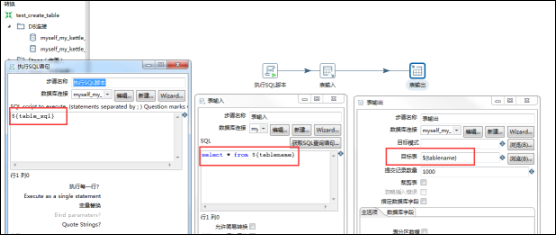
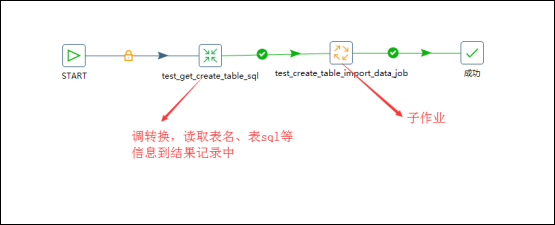
有主作业、子作业两个作业组成这个流程,在主作业中,首先调用一个转换用来获取指定库中所有的表名、表sql等内容复制到结果记录,然后调用一个子作业,子作业中先调用一个转换用来结果记录中的信息,然后设置变量,变量有效范围为parent_job,然后子作业再调用一个转换,用来执行sql脚本创建表结构和获取源数据表中的数据再输出到对应的目标数据库中表中即可,因为字段名称是一致的,所以不需要指定字段映射;
2、实现过程截图:
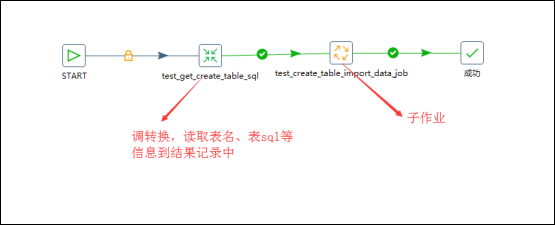
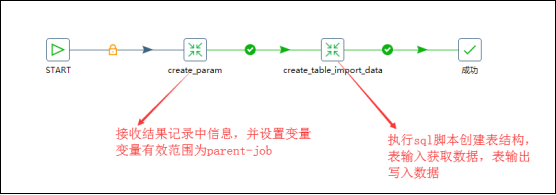
3、具体作业,详情见自我总结常用功能/整库迁移中的作业
自我感悟:如果想要动态的设置变量,就需要在主作业中嵌套一个子作业,子作业中调用一个转换,转换的功能就是通过从子作业的上一步中获取结果信息,然后将信息设置成变量,变量的有效范围parent-job;
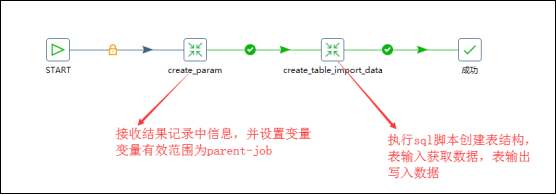
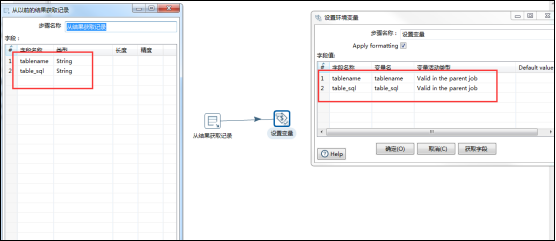
十八、Kettle寻找资源库的原理:
Kettle首先是通过KETTLE_HOME下寻找.kettle文件下的资源库,如果没有配置KETTLE_HOME那么kettle寻找资源库是通过当前登录用户下的.kettle文件寻找资源库;
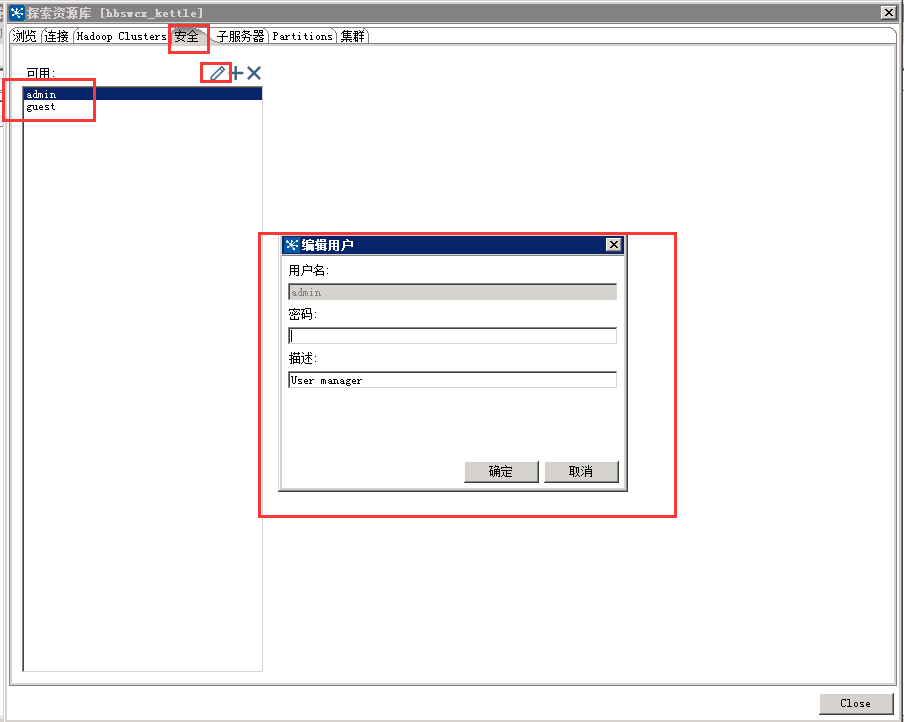
十九、Kettle修改资源库登录用户密码:
Kettle资源库创建好后,有默认的admin/admin、guest/guest两个用户,修改用户登录密码操作如下图所示:
二十、Kettle大量数据迁移,跳过异常数据继续执行,输出异常数据:
1、在表输出后添加一个异常输出到excel文件的控件,输出字段自己选择,这样可以让异常数据中的信息输出到excel中;
Kettle日常使用汇总整理的更多相关文章
- Shell脚本使用汇总整理
Shell脚本使用汇总整理 一.Shell脚本常用的头部格式: 头部的作用就是告知linux此脚本的类型: 常用的头部格式如下:(/bin/bash,是bash的路径,如果不知道路径可以通过which ...
- 微信小程序(应用号)资源汇总整理
微信小应用资源汇总整理 开源项目 WeApp - 微信小程序版的微信 wechat-weapp-redux-todos - 微信小程序集成Redux实现的Todo list wechat-weapp- ...
- ROS(indigo)机器人操作系统学习资料和常用功能包汇总整理(ubuntu14.04LTS)
ROS(indigo)机器人操作系统学习资料和常用功能包汇总整理(ubuntu14.04LTS) 1. 网站资源: ROSwiki官网:http://wiki.ros.org/cn GitHub ...
- redis日常使用汇总--持续更新
redis日常使用汇总--持续更新 工作中有较多用到redis的场景,尤其是触及性能优化的方面,传统的缓存策略在处理持久化和多服务间数据共享的问题总是不尽人意,此时引入redis,但redis是单线程 ...
- 黄聪:微信小程序(应用号)资源汇总整理(转)
微信小应用资源汇总整理 开源项目 WeApp - 微信小程序版的微信 wechat-weapp-redux-todos - 微信小程序集成Redux实现的Todo list wechat-weapp- ...
- 编程中遇到的Python错误和解决方法汇总整理
这篇文章主要介绍了自己编程中遇到的Python错误和解决方法汇总整理,本文收集整理了较多的案例,需要的朋友可以参考下 开个贴,用于记录平时经常碰到的Python的错误同时对导致错误的原因进行分析, ...
- Shell脚本使用汇总整理——达梦数据库备份脚本
Shell脚本使用汇总整理——达梦数据库备份脚本 Shell脚本使用的基本知识点汇总详情见连接: https://www.cnblogs.com/lsy-blogs/p/9223477.html 脚本 ...
- Shell脚本使用汇总整理——mysql数据库5.7.8以前备份脚本
Shell脚本使用汇总整理——mysql数据库5.7.8以前备份脚本 Shell脚本使用的基本知识点汇总详情见连接: https://www.cnblogs.com/lsy-blogs/p/92234 ...
- Shell脚本使用汇总整理——mysql数据库5.7.8以后备份脚本
Shell脚本使用汇总整理——mysql数据库5.7.8以后备份脚本 Shell脚本使用的基本知识点汇总详情见连接: https://www.cnblogs.com/lsy-blogs/p/92234 ...
随机推荐
- BZOJ4259:残缺的字符串(FFT)
Description 很久很久以前,在你刚刚学习字符串匹配的时候,有两个仅包含小写字母的字符串A和B,其中A串长度为m,B串长度为n.可当你现在再次碰到这两个串时,这两个串已经老化了,每个串都有不同 ...
- BZOJ2694:Lcm——包看得懂/看不懂题解
http://www.lydsy.com/JudgeOnline/problem.php?id=2694 Description 对于任意的>1的n gcd(a, b)不是n^2的倍数 也就是说 ...
- Sequelize-nodejs-12-Migrations
Migrations迁移 Just like you use Git / SVN to manage changes in your source code, you can use migratio ...
- Docker实战(三)之访问Docker仓库
仓库是集中存放镜像的地方,分为公共仓库和私有仓库.一个容易与之混肴的概念是注册服务器.实际上注册服务器是存放仓库的具体服务器,一个注册服务器上可以有多个仓库,而每个仓库下面可以有多个镜像.从这方面来说 ...
- Java静态代理学习
代理模式 代理模式的作用是:为其他对象提供一种代理以控制对这个对象的访问. 在某些情况下,一个客户不想或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用. 代理模式一般涉及 ...
- Verilog基础知识0(`define、parameter、localparam三者的区别及举例)
1.概述 `define:作用 -> 常用于定义常量可以跨模块.跨文件; 范围 -> 整个工程; parameter: 作用 -> 常用于模块间参数传递; 范围 -> ...
- Gym100920J
求Ax+By<=C,非负整数对(x,y)的个数 首先令y=0;则x<=(C/A);ans=(C/A)+1; 将Ax+By=C反转之后利用类欧几里得算法:f(a,b,c,n)=∑((a*i+ ...
- MySQL 性能测试
MySQL 查询优化器有几个目标,但是其中最主要的目标是尽可能地使用索引,并且使用最严格的索引来消除尽可能多的数据行.最终目标是提交 SELECT 语句查找数据行,而不是排除数据行.优化器试图排除数据 ...
- goalng nil interface浅析
0.遇到一个问题 代码 func GetMap (i interface{})(map[string]interface{}){ if i == nil { //false ??? i = make( ...
- [转]超级强大的SVG SMIL animation动画详解
超级强大的SVG SMIL animation动画详解 本文花费精力惊人,具有先驱前瞻性,转载规则以及申明见文末,当心予以追究.本文地址:http://www.zhangxinxu.com/wordp ...