苏宁OLAP架构设计
一. 功能综述
OLAP引擎为存储和计算二合一的引擎,自身内部涵盖了对数据的管理以及提供查询能力。底层数据完全规划在引擎内部,外部系统不允许直接操作底层数据,而是需要通过暴露出来的接口来读写引擎内部数据。
目前整体来说OLAP功能由两部分组成:数据管理,查询引擎。
1.1 数据管理
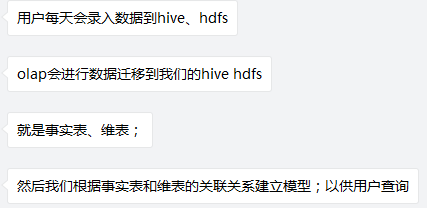
引擎中数据核心概念包括:事实表,维度表,模型表,加速表,其中事实表和维度表统称为Dataset表。数据操作包括以下几点:
- 事实表创建、定时导入、清理、补数。
- 维度表创建、定时导入、清理、补数;
- 模型表创建、删除;
- 加速表Scheme探测、定时加速、清理、补数;
其中事实表和维度有以下设计关注点:
- 事实表和维度表构造起整个OLAP引擎内部的星型结构,可以通过接口创建一个新的事实表或者维度表;对于事实表,也可以在创建模型自动创建。
- OLAP引擎内部可以根据事实表,维度表,模型表创建过程中所提供的信息,动态的感知出事实表的时间维度、多值维度、外键维度、普通维度、去重统计维度以及度量,也可以感知出维度表中的外键维度、普通维度。
- 事实表和维度表的存储方式可以根据上面感知到的信息来进行自我规划,对上层应用来说完全隐藏。
其中维度表有以下设计关注点:
- 每个维度表都有version版本属性,即系统中会存在多个版本的维度数据,默认会保存最新N个版本。后续的加速表的每个批次的数据都是和相应版本的维度表关联。
- 维度表导入任务与业务维度表生成任务构成导入任务链,每次导入都会生成一个新版本的维度表。
- 针对模型自动加速,OLAP引擎只要感知到相应的维度表当天版本已经生成,既可以开始相应的加速,加速时会选择当天最新版本的维度表。系统当天不会自动对已经加速的数据因为维度变更而自动更新,需要手动发起加速表的重构操作。
其中事实表有以下设计关注点:
- 事实表导入任务与业务事实表生成任务构成导入任务链。上游业务事实表任务结束以后,会调起我的事实表导入任务,并传递上游执行任务所属于的batch时间。
- 事实表补数操作是OLAP对外提供单次服务接口。OLAP引擎会对请求时间进行拆分,转化为多个批次的事实表补数任务,并分发给IDE去执行。
对于一个事实表补数操作,与该事件表的数据加速任务是互斥的,即会对相应的bacth加上读写锁,只有拿到写锁,才可以进行补数操作,否则会一直等待当前批次关联的加速任务完成。事实表补数结束以后,会对已经完成的加速表进行数据重构操作。
其中模型表有以下设计关注点:
- 模型表为一个视图表,对外提供表的Create、Delete操作,Delete操作对外接口只会删除模型相关的meta信息,但是后端需要同时删除该模型相关联的加速表的数据。
- OLAP引擎需要根据模型表join关系,确定模型所归属的事实表和维度表,构建起整个数据导入以及加速任务链。
其中加速表有以下设计关注点:
- 加速表是模型的物化表。对于百川来说,默认会进行Druid和Carbondata两级物化。
- 对于默认应用场景,OLAP引擎会选择Druid进行指标的查询;只有在SQL中强制指定使用Carbondata进行查询的时候,才会使用Carbondata进行查询。
- 在维度表变更以后,可以通过OLAP引擎接口,一致性重写相应维度表关联的加速表,默认情况下,加速表都会使用当前最新可用的维度表进行加速。
- 加速表的每一个批次的加速都有锁的存在,在锁冲突的情况,不会排队等待,而是会直接失败,只有当前拿到锁的加速任务,才可以进行相应批次的加速。
1.2 调度与执行架构
OLAP引擎调度架构是在Bigquery上进行改进。其中会把服务接口升级为三种类型:
- 同步阻塞服务接口。
- 异步非阻塞服务接口。
- IDE定时调度接口。
其中同步阻塞接口主要用于请求耗时在3s以内的查询,其中包括数据管理,集群管理,以及指标数据查询;异步非阻塞接口主要服务耗时较差或不可沽的服务接口,其中包括用于数据探测。如果OLAP引擎用于服务百川,与外部数据的交互,包括定时数据迁移,加速及补数,都需要通过IDE任务来实现,OLAP引擎不会直接与外部数据源交互。
二. 架构设计

上图是OLAP引擎整体架构图,分为三个层面:数据存储层,计算资源层以及OLAP服务层。
1. 数据存储和计算资源层
- OLAP引擎是基于Spark和Hadoop的SQL引擎,内部依赖Druid,HDFS,HIVE存储来存储相关数据。为了与离线计算集群解耦,OLAP自身内部有一套完整的HDFS存储,HIVE存储以及Yarn资源池。
- OLAP引擎内部
Spark指标计算,异步化任务都是托管在自身的Yarn资源池内部,同时也只会消费处理自身的Druid、HDFS和HIVE数据。 - OLAP引擎外部对底层HIVE访问需要通过API层进行转发,比如新增分区,修改表结构等,运行在离线计算集群上的加速等任务无法操作OLAP引擎底层Hive数据仓库。
- OLAP引擎读取离线计算集群Hive TableMeta操作,必须通过ThriftServer进行访问,离线计算集群Hive配置不会托管到OLAP引擎中。
- 对于
数据入库以及模型加速两种任务,是由IDE平台负责调度。它是运行在离线计算集群上面,它可以读写离线大集群上的HIVE仓库以及HDFS存储,也可以通过Alluxio Proxy来读写OLAP引擎底层的HDFS,但是不可以直接读写OLAP引擎HIVE仓库,需要通过API层的Query请求进行转发。 - OLAP引擎底层还采用了HBase作为KV存储,来存储异步化任务相关信息;以及采用MySQL来存储OLAP集群Meta信息。
2. OLAP服务层
OLAP接口服务层主要为外部提供数据管理以及指标查询能力。其中定时数据入库任务、模型加速任务及补数等数据管理操作都是由API层将请求分发给IDE-API层,后续由IDE调度层负责任务的调度和定时执行。OLAP引擎提供的指标计算以及异步化任务都是在OLAP引擎自身调度层的调度下,完成任务执行,其中调度层也负责整个计算的请求路由以及集群管理。
3. 主服务接口流程
3.1. 模型创建
- 获取模型关联的事实表以及维度表,并判断在当前集群中是否已经存在;如果相关的维度表不存在,直接报错;
1.1 如果事实表不存在。
1.1.1 请求离线计算集群ThritServer,将事实表的scheme克隆到OLAP引擎中,期间会使用Parquet进行存储。
1.1.2 请求IDE,构建一个事实表迁移任务;
1.1.3 请求IDE,手动补数最近1天(可配置)数据;
1.2 如果事实表已经存在。根据这次提供的事实表相关信息,完善当前我们对事实表的认识。- 对查询请求进行SQL翻译,并在OLAP引擎中构建模型表,在model数据表中存储模型信息;
- 请求IDE,构建模型的定时加速任务,并记录到speed表中。
- 模型创建成功。
3.2 指标查询
- API将请求转发到调度层,由调度层根据当前后端负载情况,返回一个可用worker。
- API层直接请求worker进行查询执行。worker首先将SQL按照
;进行切分,如果为普通的set语句,DDL语句,即立即执行;如果为select语句,worker对SQL进行解析和校验,其中校验点包括:
2.1 是否为衍生指标查询?衍生计算逻辑是否支持?
2.2 内部查询是否为UNION子查询?并校验每一个子查询模型是否存在?
2.3 校验子查询是否有主时间维度?并校验涉及到的分片数是否在阈值之内?
2.4 校验所有分片是否都已加速?
2.5 校验聚合指标是否为sum,count,max,min,count distincts五种?
2.6 校验count distinct的维度是否在模型配置列表中?
2.7 校验case when语句是否为单case when语句,并且else被置为0或者null?- 如果
bigquery.accurate.count_distinct=true,只能选择carbondata进行加速,否则默认都选择druid进行加速。- 在carbondata或者druid上完成SQL查询,并直接返回查询结果给API层。
注意:处理到第一条select语句后,将会结束后面SQL的执行。
注意:关于多时间维度:
对于一个模型,它必须要有一个分区时间字段和1个或多个业务时间字段,其中分区时间字段为粗粒度,而业务时间字段为细粒度。
在模型加速过程中,如果一个模型只有一个1个业务时间字段,即使用业务时间字段作为主时间维度;否则将使用分区时间字段作为主时间字段进行加速。
在指标查询过程中,必须带上
主时间维度过滤条件。对于单时间模型,查询的时候必须带上相应的业务时间过滤条件;对于多时间模型,查询的时候就必须带上分区时间过滤条件。 比如多时间模型,分区时间为a,两个业务时间b,c,查询的时候必须在维度上a做时间过滤,否则会全表扫描; 比如单时间模型,分区时间为a,业务时间为b,查询必须是基于业务时间b来构建过滤条件。
三. 接口设计
http://www.xiaoyaoji.cn/dashboard/#!/share/AmjDtLow2
四. 存储设计
如上所述,OLAP引擎由三组存储组成:MySQL核心Meta存储、HBase异步化任务状态KV存储、以及Hive/HDFS数据存储。其中核心Meta存储采用MySQL进行存储,包括Dataset,Model,speedup,Partition四个表;HBase仅仅用来存储数据探测等异步化任务相关信息;事实表、维度表、加速表等数据存储在Hive/HDFS中。
1. Dataset表——存储事实表和维度表Meta信息
dataset表存储了系统中所有的事实表和维度表,通过type字段进行标识,可选{"0":"事实表","1":"维度表"};
在创建事实、维度表时,需要指定表所关联的上游任务pre_ide_job_id和granularity,OLAP引擎在IDE中创建定期迁移数据任务,任务流ID和任务ID分别为ide_flow_id、ide_job_id;
meta字段是OLAP对该表的认知,随着上层模型建立,认知也会逐渐丰富起来。
CREATE TABLE `bigquery_dataset` (
`id` INTEGER NULL AUTO_INCREMENT DEFAULT NULL,
`database` VARCHAR(128) NULL DEFAULT NULL,
`tablename` VARCHAR(128) NULL DEFAULT NULL,
`type` TINYINT NULL DEFAULT NULL,
`pre_ide_job_id` VARCHAR(128) NULL DEFAULT NULL,
`granularity` TINYINT NULL DEFAULT NULL,
`ide_flow_id` VARCHAR(128) NULL DEFAULT NULL,
`ide_job_id` VARCHAR(128) NULL DEFAULT NULL,
`meta` MEDIUMTEXT NULL DEFAULT NULL COMMENT 'json',
PRIMARY KEY (`id`),
UNIQUE KEY `dataset_unique_key` (`database`,`tablename`),
UNIQUE KEY `pre_ide_job_id_unique_key` (`pre_ide_job_id`),
UNIQUE KEY `ide_job_id_unique_key` (`ide_flow_id`,`ide_job_id`),
);
其中meta字段Json结果如下所示:
{
"dimensions":[
{
"dimension":"维度名称",
"type": "维度类型",
"cardinality":"维度基数",
"is_time":"是否为时间字段",
"time_format":"时间字段格式",
"is_partition":"是否为分区字段",
"is_key":"是否为维度外键",
"is_multivalue":"是否为多值列",
},
],
"measures": [
{
"measure":"度量名称",
"type":"度量类型",
},
],
}
2. Model表——模型视图表
model为存储业务模型,每个模型归属一个database;granularity为模型时间间隔,它与所依赖的事实表时间间隔一致;ttl单位天,表示模型关注的时间,超过这个时间的物化数据,将会从系统中移除。meta存储详细描述信息。
CREATE TABLE `bigquery_model` (
`id` INTEGER NULL AUTO_INCREMENT DEFAULT NULL,
`name` VARCHAR(256) NULL DEFAULT NULL,
`database` VARCHAR(256) NULL DEFAULT NULL,
`queryGranularity` VARCHAR(64) NULL DEFAULT NULL,
`ttl` INTEGER NULL DEFAULT -1 COMMENT 'model关注时间',
`meta` MEDIUMTEXT NULL DEFAULT NULL COMMENT '存储模型详细信息',
PRIMARY KEY (`id`),
UNIQUE KEY `model_unique_key` (`name`,`database`),
);
其中meta格式如下所示:
meta={
"fact":{},
"relations":[],
}
//
fact={
"database":"",
"tablename":"",
"filter":"",
"meta":{
"dimensions":[
{
"name":"",
"dimension":"",
"type":"",
"is_time":"",
"time_format":"",
"is_partition":"",
"is_multivalue":"",
"is_radix":"",
}
],
"measures":[
{
"name":"",
"measure":"",
"type":"",
}
],
}
}
//
relations=[
{
"database":"",
"tablename":"",
"dimensions":[
{
"name":"",
"dimension":"",
"type":"",
"is_multivalue":"",
"is_radix","",
}
],
"join":{
"type":"",
"items":[
{
"dimension":"",
"fact_dimension":"",
},
],
},
"filter":"",
}
]
3. speedup表——模型加速表
speedup为模型加速表,单个模型可以有druid和carbondata两种加速类型,通过type字段进行标识;每一种类型加速根据聚合粒度queryGranularity,可以有多个加速宽表,每一个加速宽表对应一个IDE实体迁移任务ide_job_id。
CREATE TABLE `speedup` (
`id` INTEGER NULL AUTO_INCREMENT DEFAULT NULL,
`model` VARCHAR(256) NULL DEFAULT NULL,
`database` VARCHAR(256) NULL DEFAULT NULL,
`type` INTEGER NULL DEFAULT NULL,
`name` INTEGER NULL DEFAULT NULL,
`ide_flow_id` INTEGER NULL DEFAULT NULL,
`ide_job_id` INTEGER NULL DEFAULT NULL,
`queryGranularity` INTEGER NULL DEFAULT NULL,
`scheme` MEDIUMTEXT NULL DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `speedup_unique_key` (`model`,`database`, `type`, `queryGranularity`),
UNIQUE KEY `speedup_name_unique_key` (`name`),
);
4. Partition表——事实表、维度表、加速表分区状态表
partition数据分区表。不管是dataset还是speedup,都只是存储表的逻辑信息,实际数据都需要以分区的形式迁移或假设而来(注意:维度表迁移是完整迁移,可以理解分区为0到无穷大),每一次迁移或拉宽都对应一条记录存储在partition分区表中。
type表示分区类型,可选值有dataset,speedup,relation_id为外键,分别关联dataset.relation_id和speedup.relation_id;每一个分区都有一个interval字段,标识该分区所属于的时间段,参考标准。
interval记录可以有多个版本,通过version表示;对于speedup以及dataset.fact数据,底层数据只会保存一个版本,数据库中记录也只有一条(通过updateOrInsert来实现);而对于dataset.dim数据,底层会保存历史多个版本,数据库中记录条数也会有多条记录。
如果type=speedup,versions字段存储了它所依赖的各个表的维度信息,格式为[{"database":"","tablename":"","version":""}]
CREATE TABLE `partition` (
`relation_id` INTEGER NULL DEFAULT NULL,
`type` VARCHAR(128) NULL DEFAULT NULL,
`interval` INTEGER NULL DEFAULT NULL,
`version` VARCHAR(64) NULL DEFAULT NULL,
`status` TINYINT NULL DEFAULT NULL,
`ide_instance_id` INTEGER NULL DEFAULT NULL,
`versions` MEDIUMTEXT NULL DEFAULT NULL,
UNIQUE KEY `partition_unique_key` (`relation_id`,`type`,`interval`, `version`)
);
5. Task表——异步化任务状态表
task为HBase表,存储了Task相关信息,通过type参数来区分不同类型。cf1.content字段存储任务的参数信息;cf2.data字段存储任务的执行过程中或者结束以后大Blob信息。
{
"name": "ns_bigdata:bigquery_task"
"cf1": {
"type":"任务类型",
"content":"任务内容",
"user":"",
"create_time":"",
"priority":"",
"timeout":"",
"status":"",
"update_time":"",
"worker:"",
"progress":"",
"schedule_cost:"",
"execute_cost:"",
"fail_desc:"",
"count:"",
},
"cf2": {
"scheme":"查询结果的scheme",
"data":"查询结果"
}
}
针对不同的Type,content等字段取值也有所有不同。
//type=survey/create
content={
"query":"查询sql语句",
"sample": {
"block_enabled":true,
"record_enabled":true,
"ratio":""
},
}
process=[
{
"sub_query":"",
"sub_query_status":"",
"sub_query_detail":[
"job_id":"",
"job_status":"",
"job_detail":[
{
"stage_id":"",
"stage_status":"",
"total_tasks":"",
"succeeded_tasks":"",
"failed_tasks":"",
"start_time":"",
"end_time":"",
}
]
],
}
]
//type=migrate/delete
content={
"database":"",
"tablename":"",
}
//type=migrate/redo
content={
"relations":[
{
"database":"",
"tablename":"",
"interval":"",
},
],
"migrate":true,
"speedup":true
}
process={
"migrate":[
{
"database":"",
"tablename":"",
"interval":"",
"ide_instance_id":"",
}
],
"speedup":[
{
"model":"",
"interval":"",
"type":"",
"task_id":"",
}
],
}
//type=model/delete
content={
"model":""
}
//type=speedup/create
content={
"model":"",
"interval":"",
"type":"",
"queryGranularity":""
}
progress=[
{
"interval":"",
"queryGranularity":"",
"ide_instance_id":"",
}
]
五. 数据搬迁和加速任务实现
OLAP引擎数据搬迁和加速操作都是以任务的形式运行在IDE平台上,调度方式包括定时调度和手动补数两种类型。对于定时调度,OLAP引擎负责IDE任务及任务流的创建,IDE负责定时执行任务;对于手动补数,OLAP引擎负责对请求进行拆分为多个IDE补数任务,由IDE进行调度排队及执行。
migrate和speedup为两个java二进制程序,资源托管在IDE平台中。IDE平台支持创建任务/api/bigquery/ide/flow/create时,通过指定该资源名称或者ID来使用它们,同时也支持对任务资源进行升级/api/bigquery/ide/task/upgrade。
migrate和speedup使用方式如下:
migrate database tablename [batch]
speedup model type queryGranularity [batch]
//参数描述:
//database、tablename和speedup、model、type是在创建IDE任务时指定的任务自定义参数param。在定时调度以及补数时,IDE负责将其作为参数传递的程序。
//batch为IDE内部调度过程中,传递给程序的参数,程序内部还需要通过batch获取到当前执行的ide_instance_id。
//如果为补数任务,batch支持通过接口传递给IDE
关于batch的概念:
在OLAP引擎中,数据是按照interval进行表示,但是在IDE任务中,是通过batch来进行标识,它们关系如下:
batch=interval_end_time即batch为interval结束时间interval=batch-max(granularity,queryGranularity)/batch。
对于migrate任务,queryGranularity=0;
对于speedup任务,queryGranularity=granularity * n,默认n=1。
migrate任务流程如下:
- 校验待迁移源数据进行校验:
dataset数据库中有该事实表或者维度表记录?源Hive分区数据是否存在,并预计算分区内数据条目数。- 尝试获取该表的迁移分区的
写锁。处于写锁状态的分区,不允许并行写,也不允许被加速任务读取。锁的值需要记录当前锁持有者的相关信息,包括当前锁持有者的机器,进程号,服务类型。如果当前有另外一个服务占用写锁,那该任务将会直接失败;如果因为当前有读锁,那么将会持续等待下去,最长等待时间为30分钟(每次sleep 1分钟,重试获取30次)。- 在OLAP引擎
Partition表中记录该次迁移的描述信息,状态标记为running。其中如果为维度表,在Partition中新增一条记录;如果为事实表,直接在原有记录上进行修改。- 如果为事实表,需要删除原始实时表底层的HIVE分区以及底层HDFS数据。
- 开始HDFS数据迁移,并且对迁移后的数据进行条目数校验。
- 将HDFS路径关联到OLAP引擎Hive Meta中。如果为事实表,通过
add partition来将相应的HDFS路径关联到表中;如果为维度表,通过alert table来修改当前维度表的path路径。- 迁移结束以后,更新分区表Partition中迁移状态。
- 释放
写锁- 收集数据迁移相关metric信息,完成迁移操作。
speedup任务流程如下:
- 校验当前
batch是否为queryGranularity结束点,如果不是,选择跳过。比如queryGranularity=1d,如果batch为2017071812就直接跳过,只处理batch=2017071900。- 获取指定
speedup分区的全局写锁;获取所依赖的事实表、维度表指定分区的全局读锁- 校验所依赖的事实表、维度表指定的分区数据是否存在,如果不存在,直接报错;否则就获取相应的版本信息。
- 校验当前拉宽后的scheme是否存在(存储在
speedup表的scheme字段),如果没有,进入scheme探测逻辑。
4.1 尝试获取指定speedup表的scheme探测全局锁。
4.2 拿到全局锁,进行scheme探测逻辑,生成scheme,并写到speedup表中,释放全局锁。
4.3 未拿到全局锁,等待1分钟,再次检查scheme是否存在,进入2.1步逻辑。
4.4 最长等待时间为30分钟。- 在分区表Partition中记录该次加速的描述信息,状态标记为
running。- 开始加速。
- 迁移结束以后,更新分区表Partition中迁移状态。
- 通过zk进行事件通知,通知所有的worker有新的加速分区上线。
- 释放所依赖分区的
全局读锁;释放加速分区的全局写锁。- 收集数据迁移相关metric信息,完成迁移操作。
六. 查询路由方案
1. 请求模块间交互逻辑
针对百川,OLAP引擎提供指标查询的接口为同步,而针对数据探测项目,是采用异步接口。请求模块间流转如下所示:
异步接口:
- API层响应数据探测任务的创建操作,在HBase中记录任务相关信息,并返回任务ID给业务端。
- API层将任务转发给Master层,由Master负责排队等待,并将请求调度到指定Worker层进行处理。
- 在任务运行过程中,Master层随时会响应来自API层的任务Kill请求,Master会与任务运行Worker进行通信,从而将任务从Worker中杀死。
- 任务计算过程中,Worker会将任务的中间状态更新到HBase中,从而可以被API层查询并返回给业务端。
- 任务计算完成以后,Worker会在HBase/HDFS中写入任务状态和数据。同时通知Master层,任务执行结束。
- API层通过查询HBase/HDFS记录信息来获取任务的执行结果,并返回给业务端。
整个环节中,API层不会和Worker直接进行RPC通信。
同步接口:
- API层响应百川的指标查询请求,此时会创建一个任务ID,但是不会在HBase中记录该Task的任何信息。
- API层请求Master,根据任务相关信息,由Master进行负载均衡,流控等操作,并给出可用的后端Worker,并返回给API层。
- API层同步请求后端Worker,等待Worker完成指标的计算,并返回计算结果给API层。期间Worker不会将状态、数据落地到HBase和HDFS中。
- Worker计算完成以后,需要通知Master层;
- 在Worker计算过程中,Master层支持响应Kill操作来杀死指标查询请求(仅仅用于运维管理)。
2. 模型数据路由
在OLAP引擎中,模型或者模型表是虚拟概念,其中不真正包含数据,对模型的查询,需要通过一个策略转换为对模型的加速表的查询,这个策略即模型数据路由。
加速表是按照interval对模型进行加速,OLAP引擎核心路由也是基于对查询所依赖的interval分区数据进行路由。OLAP引擎的Worker模块会实时监听每个加速表的interval分区上线以及上线操作,只有一个查询所关注的所有interval分区都在线,该加速表才会提供查询服务。
如果有一个查询因为查询指标和维度只能使用carbondata进行查询,那么将会路由为carbondata加速表,否则默认都是使用druid加速。同时,如果指定的加速表有多个queryGranularity,系统需要自动选择满足查询的最大的queryGranularity;比如查询语句是查询最近1月的聚合指标,那么优先使用queryGranularity=1月的加速表,而不使用queryGranularity=1天的加速表。
关于interval分区上线或上线:
worker启动时,会对partition表进行扫描,对每个模型的每张加速表,会在内存中构建bitmap,bitmap的大小结果如下:hashmap(
2017年->bitmap(366天*24小时/queryGranularity小时),
2016年-> bitmap(366天*24小时/queryGranularity小时)
)
比如queryGranularity为1天的加速表,每年的bitmap大小就为366;如果为1小时的加速表,那么每年的bitmap大小就为366*24。
//
worker在运行过程中,会响应对分区的上线下线操作事件,比如/api/bigquery/datamanager/model/speedup/delete会向所有Worker通知指定interval的数据操作。
在IDE加速任务完成以后,也会通过事件的方式通知所有Worker有新的Interval可以提供查询服务。
七. 支持SQL类型
select count(度量) from 模型 group by window(小时/天), 维度1,维度2 where 过滤条件
select count(case when 过滤条件 then 度量 else null) from 模型 group by window(小时/天), 维度1,维度2 where 过滤条件
//
select count(distinct 维度) from 模型 group by window(小时/天), 维度1,维度2 where 过滤条件
select count(distinct case when 过滤条件 then 度量 else null) from 模型 group by window(小时/天), 维度1,维度2 where 过滤条件
//
select sum(度量) from 模型 group by window(小时/天),维度1,维度2 where 过滤条件
select sum(case when 过滤条件 then 度量 else null) from 模型 group by window(小时/天),维度1,维度2 where 过滤条件
//
select max(度量) from 模型 group by window(小时/天),维度1,维度2 where 过滤条件
select max(case when 过滤条件 then 度量 else null) from 模型 group by window(小时/天),维度1,维度2 where 过滤条件
//
select min(度量) from 模型 group by window(小时/天),维度1,维度2 where 过滤条件
select min(case when 过滤条件 then 度量 else null) from 模型 group by window(小时/天),维度1,维度2 where 过滤条件
//
select metric组合 from 模型 group by window(小时/天),维度1,维度2 where 过滤条件
//
select 维度,度量 from 模型 where 过滤条件
支持SQL Union
度量值,维度值,过滤条件支持UDF转换
过滤条件支持多值组合 and or组合
支持order by和limit num
支持子查询
支持指标结果运算
简单说:OLAP就是
苏宁OLAP架构设计的更多相关文章
- MySQL性能优化总结___本文乃《MySQL性能调优与架构设计》读书笔记!
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- MySQL性能调优与架构设计——第6章 MySQL Server 性能的相关因素
第6章 MySQL Server 性能的相关因素 前言 大部分人都一致认为一个数据库应用系统(这里的数据库应用系统概指所有使用数据库的系统)的性能瓶颈最容易出现在数据的操作方面,而数据库应用系统的大部 ...
- 大数据分析的下一代架构--IOTA架构设计实践[下]
大数据分析的下一代架构--IOTA架构设计实践[下] 原创置顶 代立冬 发布于2018-12-31 20:59:53 阅读数 2151 收藏 展开 IOTA架构提出背景 大数据3.0时代以前,Lam ...
- 架构设计 | 接口幂等性原则,防重复提交Token管理
本文源码:GitHub·点这里 || GitEE·点这里 一.幂等性概念 1.幂等简介 编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同.就是说,一次和多次请求某一个资源会产 ...
- 万级TPS亿级流水-中台账户系统架构设计
万级TPS亿级流水-中台账户系统架构设计 标签:高并发 万级TPS 亿级流水 账户系统 背景 业务模型 应用层设计 数据层设计 日切对账 背景 我们需要给所有前台业务提供统一的账户系统,用来支撑所有前 ...
- 新零售SaaS架构:组织管理的底层逻辑与架构设计
想要深入理解零售企业的组织架构,是非常困难的一件事.因为大部分人都没有实际经营过一家零售企业,更没有参与设计过零售企业的组织架构. 调研商家时,我们只能了解商家组织架构的现状,我们也很难和企业高层直接 ...
- 浅谈 jQuery 核心架构设计
jQuery对于大家而言并不陌生,因此关于它是什么以及它的作用,在这里我就不多言了,而本篇文章的目的是想通过对源码简单的分析来讨论 jQuery 的核心架构设计,以及jQuery 是如何利用javas ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- 解构C#游戏框架uFrame兼谈游戏架构设计
1.概览 uFrame是提供给Unity3D开发者使用的一个框架插件,它本身模仿了MVVM这种架构模式(事实上并不包含Model部分,且多出了Controller部分).因为用于Unity3D,所以它 ...
随机推荐
- 05_Java基础语法_第5天(方法)_讲义
今日内容介绍 1.方法基础知识 2.方法高级内容 3.方法案例 01方法的概述 * A: 为什么要有方法 * 提高代码的复用性 * B: 什么是方法 * 完成特定功能的代码块. 02方法的定义格式 * ...
- Xcode7~8版本过渡导致的问题
现有项目是早期Xcode7编写的,一直到现在还是使用Xcode7编写.近期一位用户手机下载App出现闪退现象,该用户手机系统(iPhone 6 iOS8.1.2)经查实是由于CoreFoundatio ...
- 第一个spring冲刺心得及感想
在这次spring中,学到了不少东西: 1.团队协作精神 2.任务细节化,任务燃尽图 3.身为sm的责任 但是在过程中也认识到了一些不足 1.对于团队协作完成一个大的项目还是不熟悉 2.个人能力的不足 ...
- Scrum项目6.0 和8910章读后感
Scrum项目6.0总结 这次sprint1通过我们的努力,终于把自动回复做出来了.但之后的任务更加繁重,我们要更加努力,克服各种困难. 也要说说这次自动回复里面的注意之处: 1.不该空格的地方空格, ...
- 统计Github项目信息
项目总述 项目Github传送门 主要任务是从之前同项目的组员建的关系型数据库里提取出我们需要的GitHub的数据,并把结果保存到文件,以便之后插入到数据库. 从已经建立好的关系型数据库上多线程地读取 ...
- java异常处理-finally中使用return和throw语句
java异常语句中的finally块通常用来做资源释放操作,如关闭文件.关闭网络连接.关闭数据库连接等.正常情况下finally语句中不应该使用return语句也不应该抛出异常,以下讨论仅限于java ...
- springmvc+json 前后台数据交互
1. 配置(1) 文件配置参考这里(2) 导入jackson相关包:jackson-annotations-2.9.4.jar,jackson-core-2.9.4.jar,jackson-datab ...
- jmeter函数
1.常用JMeter函数 1)__regexFunction 正则表达式函数可以使用正则表达式(用户提供的)来解析前面的服务器响应(或者是某个变量值).函数会返回一个有模板的字符串,其中携带有可变的值 ...
- 基于c的简易计算器一
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <malloc.h&g ...
- 基于element-ui的后台系统表格、dialog、筛选、自定义按钮、分页的一次性封装
方便基础业务开发封装的一套组件,基于vue2.5.x和element-ui,可以通过配置自动生成表格展示,表格新增.编辑功能.分页.筛选项.自定义显示表格数据等功能. 先上演示图片 --------- ...