CS231N assignment1
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] #类别列表
num_classes = len(classes) #类别数目
samples_per_class = 7 # 每个类别采样个数
for y, cls in enumerate(classes): # 对列表的元素位置和元素进行循环,y表示元素位置(0,num_class),cls元素本身'plane'等
idxs = np.flatnonzero(y_train == y) #找出标签中y类的位置
idxs = np.random.choice(idxs, samples_per_class, replace=False) #从中选出我们所需的7个样本
for i, idx in enumerate(idxs): #对所选的样本的位置和样本所对应的图片在训练集中的位置进行循环
plt_idx = i * num_classes + y + 1 # 在子图中所占位置的计算
plt.subplot(samples_per_class, num_classes, plt_idx) # 说明要画的子图的编号
plt.imshow(X_train[idx].astype('uint8')) # 画图
plt.axis('off')
if i == 0:
plt.title(cls) # 写上标题,也就是类别名
plt.show() # 显示

用矩阵运算取代两次循环运算,大大减少运算时间。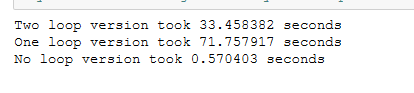
核心的公式:https://blog.csdn.net/zhyh1435589631/article/details/54236643
https://blog.csdn.net/geekmanong/article/details/51524402

我自己的经验总结:先看最终目标矩阵的大小,可以确定前面位置。

交叉验证这里:
在进行分类前,一定要通过reshape函数,来确定数据输入的形状是不是符合要求。
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100] X_train_folds = []
y_train_folds = []
################################################################################
# TODO: #
# Split up the training data into folds. After splitting, X_train_folds and #
# y_train_folds should each be lists of length num_folds, where #
# y_train_folds[i] is the label vector for the points in X_train_folds[i]. #
# Hint: Look up the numpy array_split function. #
################################################################################
X_train_folds=np.array_split(X_train,num_folds)
y_train_folds=np.array_split(y_train,num_folds) ################################################################################
# END OF YOUR CODE #
################################################################################ # A dictionary holding the accuracies for different values of k that we find
# when running cross-validation. After running cross-validation,
# k_to_accuracies[k] should be a list of length num_folds giving the different
# accuracy values that we found when using that value of k.
k_to_accuracies = {} ################################################################################
# TODO: #
# Perform k-fold cross validation to find the best value of k. For each #
# possible value of k, run the k-nearest-neighbor algorithm num_folds times, #
# where in each case you use all but one of the folds as training data and the #
# last fold as a validation set. Store the accuracies for all fold and all #
# values of k in the k_to_accuracies dictionary. #
################################################################################
num_test = X_train_folds[0].shape[0]
for j in range(len(k_choices)):
k = k_choices[j]
for i in range(1,num_folds+1):
X_train_temp = np.concatenate((X_train_folds[num_folds-i],X_train_folds[num_folds-i-1],X_train_folds[num_folds-i-2],X_train_folds[num_folds-i-3]),axis = 0)
y_train_temp = np.concatenate((y_train_folds[num_folds-i],y_train_folds[num_folds-i-1],y_train_folds[num_folds-i-2],y_train_folds[num_folds-i-3]))
X_test_temp = X_train_folds[num_folds-i-4]
y_test_temp = y_train_folds[num_folds-i-4]
classifier.train(X_train_temp, y_train_temp)
y_test_pred = classifier.predict(X_test_temp, k=k)
num_correct = np.sum(y_test_pred == y_test_temp)
accuracy = float(num_correct) / num_test
k_to_accuracies.setdefault(k,[]).append(accuracy) ################################################################################
# END OF YOUR CODE #
################################################################################ # Print out the computed accuracies
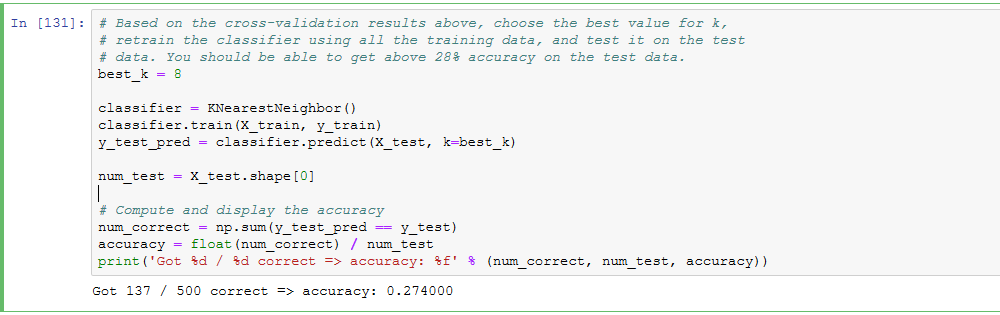
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
将所有数据分为train/val/test三组,使用train训练,用val调整超参数,在最后的最后,才可以使用test,并且test只允许使用这一次,并将这一次的结果作为最终结果上报。否则得到的classifier会overfitting,或者结果不准确,有cheat的嫌疑。
Evaluate on the test set only a single time, at the very end.
所谓5-fold cross validation就是将所有的train data均匀分成5份,每次取4份做train,另外一份做val,重复五次,将五次结果平均。这样做的话每个数据都做了四次train,一次val。这样做的缺点是太expensive,NN中通常不用。注意,在这个过程中,test是不参与其中的。一定先将test set拿出来放到一边,不到最后交结果的时候不要碰它。
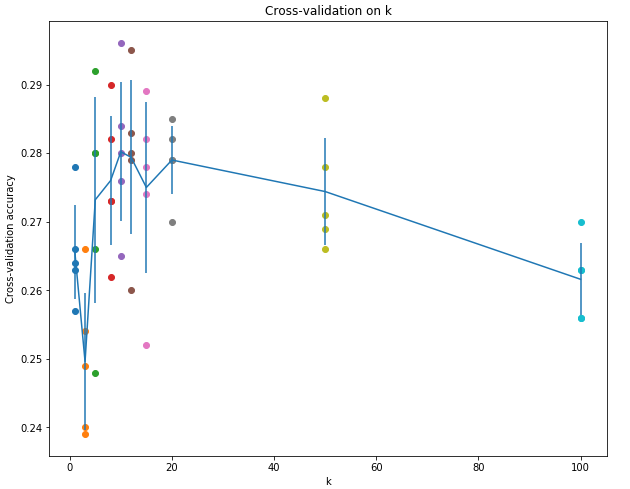

1,2显然不正确;因为kNN是非线性分类器,所以边界也是非线性的;training set越大,在predict时需要计算test example与所有training的距离,所以在相同算力条件下,taining set越大,predict一个test sample所需时间越多,时间复杂度为O(N)。
CS231N assignment1的更多相关文章
- cs231n assignment1 KNN
title: cs231n assignment1 KNN tags: - KNN - cs231n categories: - 机器学习 date: 2019年9月16日 17:03:13 利用KN ...
- 笔记:CS231n+assignment1(作业一)
CS231n的课后作业非常的好,这里记录一下自己对作业一些笔记. 一.第一个是KNN的代码,这里的trick是计算距离的三种方法,核心的话还是python和machine learning中非常实用的 ...
- 【cs231n笔记】assignment1之KNN
k-Nearest Neighbor (kNN) 练习 这篇博文是对cs231n课程assignment1的第一个问题KNN算法的完成,参考了一些网上的博客,不具有什么创造性,以个人学习笔记为目的发布 ...
- 【cs231n作业笔记】二:SVM分类器
可以参考:cs231n assignment1 SVM 完整代码 231n作业 多类 SVM 的损失函数及其梯度计算(最好)https://blog.csdn.net/NODIECANFLY/ar ...
- cs231n线性分类器作业 svm代码 softmax
CS231n之线性分类器 斯坦福CS231n项目实战(二):线性支持向量机SVM CS231n 2016 通关 第三章-SVM与Softmax cs231n:assignment1——Q3: Impl ...
- 【cs231n作业笔记】一:KNN分类器
安装anaconda,下载assignment作业代码 作业代码数据集等2018版基于python3.6 下载提取码4put 本课程内容参考: cs231n官方笔记地址 贺完结!CS231n官方笔记授 ...
- cs231n笔记:线性分类器
cs231n线性分类器学习笔记,非完全翻译,根据自己的学习情况总结出的内容: 线性分类 本节介绍线性分类器,该方法可以自然延伸到神经网络和卷积神经网络中,这类方法主要有两部分组成,一个是评分函数(sc ...
- CS231n 2017 学习笔记01——KNN(K-Nearest Neighbors)
本博客内容来自 Stanford University CS231N 2017 Lecture 2 - Image Classification 课程官网:http://cs231n.stanford ...
- cs231n --- 3 : Convolutional Neural Networks (CNNs / ConvNets)
CNN介绍 与之前的神经网络不同之处在于,CNN明确指定了输入就是图像,这允许我们将某些特征编码到CNN的结构中去,不仅易于实现,还能极大减少网络的参数. 一. 结构概述 与一般的神经网络不同,卷积神 ...
随机推荐
- 小程序:获取input输入的值
wxml <input placeholder='输入你的姓名' value='{{name}}' bindblur='nameblur'></input> js data ...
- 微信获取openId
router.beforeEach(function(to, from, next){ //中间页等待跳转 if(to.meta.requireCheck=="WaitLogin" ...
- vs2017 + Python3.6 +Django1.11 连接mysql数据库
不废话直接来. vs2017创建一个新的python web项目之后默认链接数据库是sqlite.但是我就想连接到Mysql 上面玩,于是开始倒腾了.下面是步骤 1.修改settings.py 文件需 ...
- AIX修改时区,配置NTP服务
AIX修改时区 smitty --> System Environments -->Change/Show Data and Time -->Change Time Zone Usi ...
- angular2上传图片
话不多说,直接写 一.html页面 二.html代码: <div class="descright"> <div class="clinic-img ...
- Spring Boot--02MVC设置
package com.smartmap.sample.ch1.conf; import java.util.List; import javax.servlet.http.HttpServletRe ...
- CentOS7系列--1.5CentOS7配置vim
CentOS7配置vim 1. 安装vim [root@centos7 ~]# yum -y install vim-enhanced Loaded plugins: fastestmirror ba ...
- 直到黎明 Until Dawn 后感
直到黎明 会免游戏.白金神作.近些年的恐怖电影都有游戏化的趋势,韩国的某岩vlog,美国的真心话大冒险,都把观众作为meta代入游戏,几乎模糊了游戏与游戏的边界,直到黎明这部电影,与当年的暴雨和超凡双 ...
- MOTT介绍(2)window安装MQTT服务器和client
MQTT目录: MQTT简单介绍 window安装MQTT服务器和client java模拟MQTT的发布,订阅 window安装MQTT服务器,我这里下载了一个apache-apollo-1.7.1 ...
- Windows 7 添加快速启动栏
1.右击任务栏空白处,选择 “工具栏” ,单击 “新建工具栏” 2.输入 以下路径: %userprofile%\AppData\Roaming\Microsoft\Internet Explorer ...