详解REST架构风格
|
引言
作为Web开发者,你可能或多或少了解一些REST的知识,甚至已经非常习惯于它,以至于在正式地学习REST的时候,你可能心里会想:“本来就是这样做的啊,不然还能怎么做呢?”
确实是这样,REST已经成为Web世界的一种内在架构原则。这主要是因为REST的产生确实与HTTP有着密不可分的联系。REST的提出者Roy Fielding在Web界是一位举足轻重的人物,他是HTTP协议(1.0版和1.1版)的主要设计者、Apache服务器软件的作者之一、Apache基金会的第一任主席……Fielding在几年以后 回顾起REST的设计过程时,他说道:
Throughout the HTTP standardization process, I was called on to defend the design choices of the Web. That is an extremely difficult thing to do within a process that accepts proposals from anyone on a topic that was rapidly becoming the center of an entire industry. I had comments from well over 500 developers, many of whom were distinguished engineers with decades of experience, and I had to explain everything from the most abstract notions of Web interaction to the finest details of HTTP syntax. That process honed my model down to a core set of principles, properties, and constraints that are now called REST.
在HTTP标准化的过程中,Fielding作为作者之一,负责向外界对HTTP的设计作出解释和辩护。在这个过程中,他的思维模型受到不断地锤炼,一套准则从中沉淀了下来,这就是REST。
REST
REST是Representational State Transfer(在表示层上的状态传输)的缩写,这个词的字面意思要在文章的后面才能解释清楚。REST是一种WEB应用的架构风格,它被定义为6个限制,满足这6个限制,能够获得诸多优势(详细优点在文章最后总结)。
先用一句话来概括RESTful API(具有REST风格的API): 用URL定位资源,用HTTP动词(GET,HEAD,POST,PUT,PATCH,DELETE)描述操作,用响应状态码表示操作结果。
但是REST远远不仅是指API的风格,它是一种网络应用的架构风格。我们到后面会有所体会。
另外,需要注意的是,REST的原则不仅仅适用于HTTP协议。但是,由于REST的应用场景绝大部分是WEB应用,本篇文章将基于HTTP来讨论REST。
引入:从另一个角度看待前后端分离
我们浏览一个网站,说到底就是与这个网站中的资源进行互动(获取、提交、更新、删除)。前端的工作,就是为用户从服务端获取资源、展示资源、请求服务端改变资源。
RESTful API有助于客户端和服务端的功能分离,服务器完全扮演着一个“资源服务商”的角色。各种不同的客户端都可以通过一致的API与这个“资源服务商”交流,从而与资源进行互动。
资源
在REST架构中,“资源”扮演者主要角色。它具有以下特点:
资源是任何可以操作(获取、提交、更新、删除)的数据,比如一个文档(document)、一张图片……
wikipedia: "Web resources" were first defined on the World Wide Web as documents or files identified by their URLs. However, today they have a much more generic and abstract definition that encompasses every thing or entity that can be identified, named, addressed, or handled, in any way whatsoever, on the web. “资源”包括Web中任何可以被标识、命名、定位、处理的事物。
资源的集合也是一种资源,比如blogs表示博客(资源)的集合。
进行资源操作的时候,用URI来指定被操作的资源。如果一个URI不仅能标识一个网络上的资源,还能够定位这个资源,那么这个URI也叫URL。
资源是一个抽象的概念,资源无法被传输,只能传输资源的表示(representation)。一个资源可以有多种表示,比如,一个资源可以用HTML、XML、JSON来表示。具体传输哪种表示取决于服务端的能力和客户端的要求。传输的表示未必就是服务器存储时使用的表示,比如,这个资源在服务器不是以HTML或XML或JSON来存储的,可能是一种更加利于压缩的表示。总的来说,“表示”是“资源”的存储和传输形式,“资源”是“表示”的内容(抽象概念)。不管用什么形式来表示,始终描述的是这个资源。
举一个例子,当我们讨论“文章列表”这个资源时,我们并不在乎它是json格式还是xml格式,我们指的是它的含义:某个用户的所有文章。但是当我们真的要在服务器与客户端之间传输数据的时候,不能直接“传输资源”,因为资源太抽象了,发送方必须要以某一种表示(representation)来传递它(比如json),接收方才能很好地解析和处理。
表示(representation)包括数据(data,表示资源本身)和元数据(metadata,用于描述这个representation)。在Roy Fielding的论文中有这个定义:A representation is a sequence of bytes, plus representation metadata to describe those bytes.
在前面的例子中,严格来说,“json字符串”并不是完整的representation,整个HTTP响应才是representation。HTTP body中的是数据,HTTP header中的是元数据(尤其是Content-Type这种字段)。
用URL定位资源
在RESTful架构风格中,URL用来指定一个资源。资源就是服务器上可操作的实体(可以理解为数据)。比如说URL/api/users表示的是该网站的所有用户,这是一种资源,可以与之互动(获取、提交、更新、删除)。另外,资源地址具有层次结构,比如/api/users/csr表示用户名为'csr'的用户,/api/users/csr/blogs表示'csr'的所有博客,/api/users/csr/blogs/1234567表示其中的某一篇博客。这些都是资源,后者嵌套在前者之中。
既然URL表示一个资源,自然就不应该包含动词,它应该由名词组成。一个 not RESTful 的例子是通过向api/delete/resource发送GET请求来删除一个资源。
更详细的URL设计可以查看阮一峰的"RESTful API 设计指南"或者知乎高票回答。URL风格只是REST的外表,不是本文的重点。
操作资源
既然通过URL能够指定一个服务器上的资源。那么我们应该如何与这个资源进行互动呢?我们对这个资源(URL)使用不同的HTTP方法,就代表对这个资源的不同操作:
GET(SELECT):从服务器获取资源(一个资源或资源集合)。
POST(CREATE):在服务器新建一个资源(也可以用于更新资源)。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的部分)。
DELETE(DELETE):从服务器删除资源。
HEAD:获取资源的元数据。
OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
GET、HEAD、PUT、DELETE方法是幂等方法(对于同一个内容的请求,发出n次的效果与发出1次的效果相同)。
GET、HEAD方法是安全方法(不会造成服务器上资源的改变)。
PATCH不一定是幂等的。PATCH的实现方式有可能是"提供一个用来替换的数据",也有可能是"提供一个更新数据的方法"(比如data++)。如果是后者,那么PATCH不是幂等的。
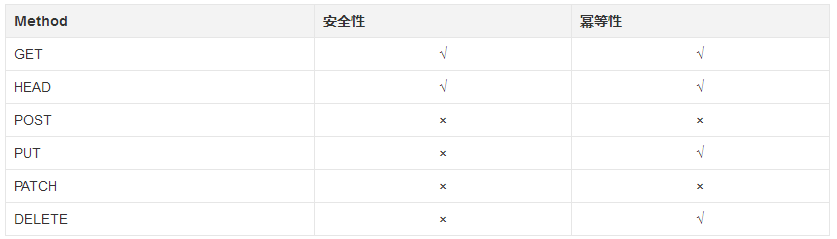
参考:HTTP Methods for RESTful Services
通过HTTP状态码表示操作的结果
虽然HTTP状态码设计的本意就是表示操作结果,但是有时候人们往往没有很好的利用它,RESTful API要求充分利用HTTP状态码
| 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务) 204 NO CONTENT - [DELETE]:用户删除数据成功。 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。 |
如何设计RESTful API
在过去不使用RESTful架构风格的时候,如果我们要设计一个系统,会以“操作”为出发点,然后围绕它去建设其他需要的东西。
举个例子,我们要向系统中增加一个用户登陆的功能:
需要一个用户登陆的功能(操作)
约定一个用于登录的API(也就是URL)
约定这个API的使用方式(发送响应什么数据、格式是什么)
前后端针对这个API进行开发
这种设计方式有如下缺点:
当我们不断为这个系统增加操作,每增加一个操作都要按照上面的流程设计一次,第2和3点的工作实际是可以大大削减的(通过REST)。
操作之间可能是有依赖的,依赖多起来,系统会变得很复杂。
我们的API缺乏一致性(需要一份庞大的文档来记录api的地址、使用方式)。
操作通常被认为是有副作用(Side Effect)的,很难使用缓存技术。
而如果我们设计REST风格的系统,资源是第一位的考虑,首先从资源的角度进行系统的拆分、设计,而不是像以往一样以操作为角度来进行设计。
用两个例子来说明:银行的转账API,即时通讯软件中发送消息的API。
这两个功能非常具有“动作性”,看起来和“资源”联系不大,很容易就会设计成not RESTful的API:POST /transfer/${amount}/to/${toUserID}、POST /api/sendMessage。
一旦在URL中引入了动词,这个URL的功能就定死了,无法用于别的用途(比如,GET /transfer/${amount}/to/${toUserID}或GET /api/sendMessage的语义很奇怪,不好使用)。并且,不同功能的API有各自的结构,一致性很差,需要一份详细的API文档才能使用。
这种情况下,要如何通过RESTful架构风格,设计一套一致、多用途的URL呢?
简单地说,就是将一个“动作”理解为“操作一个资源”。这里的“操作”是指HTTP的方法。
对于转账动作,就可以理解为“新建一个转账事务”(转账事务是资源),因此API就可以设置成这样: POST /transactions,请求体为:to=632&amount=500。这样的设计不但简洁明了,而且我们可以将这个URL用于别的用途:通过GET /transactions来获取该用户的所有转账事务。还可以将GET /transactions/456828定义为“获取某一次转账记录”。
即时通讯软件中发送消息的动作,我们可以理解为“操作聊天记录(聊天记录是资源,它是由“消息”组成的集合,消息也是资源)”,所以API设计为
| POST /messages # 创建新的聊天记录(body传输消息的内容) GET /messages # 获取聊天记录(返回一个数组,其中每个项是一个消息) GET /messages/${messageID} # 获取某个消息的详细信息 PUT /messages/${messageID} # 更新某个消息(body传输消息的内容) DELETE /messages/${messageID} # 删除某个消息的记录 |
同理,论坛类应用发帖、回帖的API也可以这样设计。
从以上的两个例子我们可以看出,使用RESTful风格可以克服传统架构风格的那4个缺陷:
设计API工作量减少,因为功能需求一旦出来,需要操作的资源、操作的方式立刻就能分析出来,因此资源URL和API的使用方式(GET, POST...)都很容易得到。
没有了操作之间的依赖。资源之间虽然可能有关联,但是小得多。
对资源的操作也就那么几种(获取、新建、修改、删除),API的一致性、自我描述性很强,不需要过多解释。
对于GET请求,我们都可以考虑使用缓存,因为在RESTful的架构中,GET请求代表获取数据,必须是安全、幂等的。
服务器无状态
根据REST的架构限制,RESTful的服务器必须是无状态的,这意味着来自客户的每一个请求必须包含服务器处理该请求所需的所有信息, 服务器不能利用任何已经存储的“上下文(context,在这里表示用户的会话状态)”来处理新到来的请求,会话状态只能由客户端来保存,并且在请求时一并提供。
这里注意两点。1. 服务器不能存储“上下文”不代表连数据库都不能有,“上下文”指那些在服务器内存中的、非持久化的数据。2. 无状态不代表不能有会话(sessions),无状态仅仅指服务器无状态。服务器不记录、维护会话,但是会话状态可以由客户端在每次请求的时候提供。
我一开始以为无状态与用户登陆是冲突的,后来在Do sessions really violate RESTfulness? - StackOverflow上找到了一个令我满意的解答。以下两幅图摘录自这个答案。
无状态的认证机制:
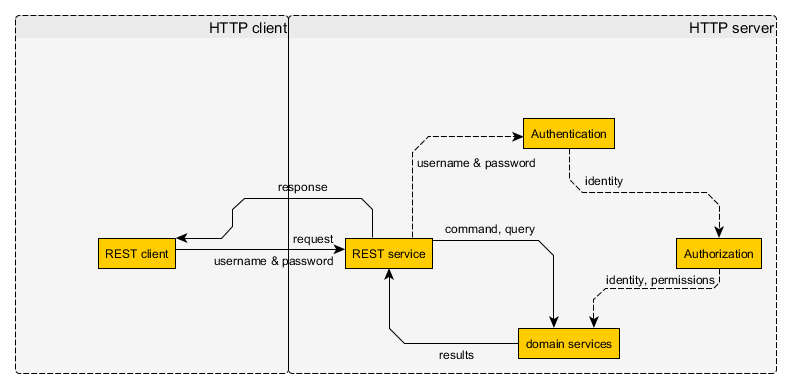
What you need is storing username and password on the client and send it with every request. You don't need more to do this than HTTP basic auth and an encrypted connection.
只需要将用户名和密码存储在客户端,然后客户端每次发送请求都附带上用户名和密码。要做到这点你只需要HTTP基本认证(简单来说就是将用户名和密码放在HTTP头部)和一个加密的连接(HTTPS)。
如果每次认证,都要去数据库查询用户的信息来核对,那么响应会非常慢,而且服务器也会有很大的性能损失。为了加快认证的速度,最好在内存中使用认证缓存。这并不违背“无状态”的限制,因为缓存的作用仅仅起加速的作用,没有缓存照样能工作。
无状态的第三方鉴权机制:
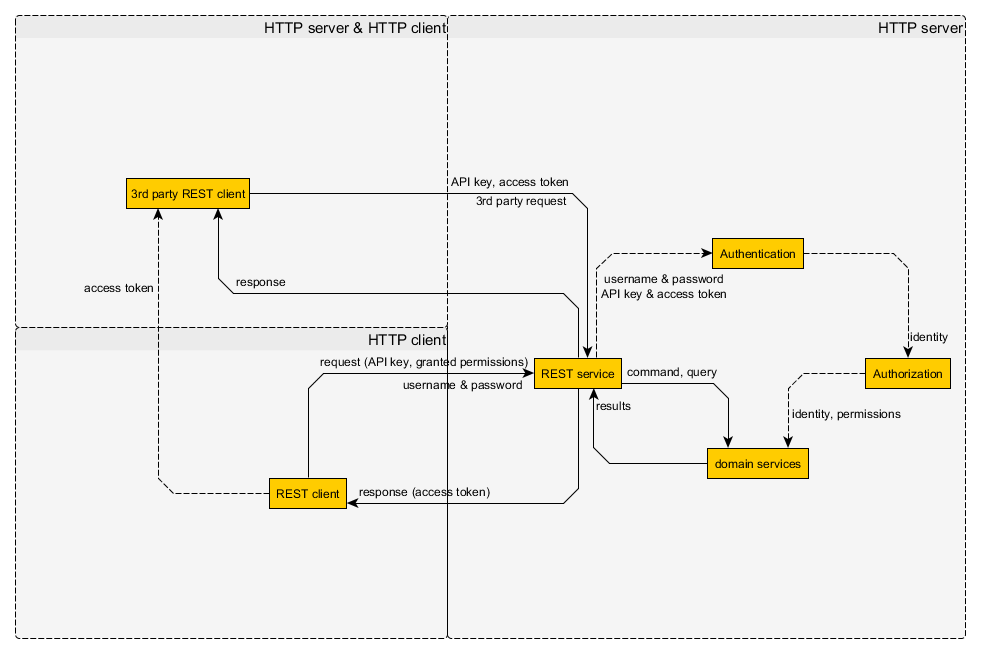
What about 3rd party clients? They cannot have the username and password and all the permissions of the users. So you have to store separately what permissions a 3rd party client can have by a specific user. So the client developers can register they 3rd party clients, and get an unique API key and the users can allow 3rd party clients to access some part of their permissions. Like reading the name and email address, or listing their friends, etc... After allowing a 3rd party client the server will generate an access token. These access token can be used by the 3rd party client to access the permissions granted by the user.
通过这个方式,用户可以给第三方应用授权,让第三方应用拿着用户的“令牌”访问网站的一些服务。
以上两幅图讲的是RESTful风格的身份认证机制。在实践中最好使用OAuth 2.0框架。
无状态增强了系统的故障恢复能力,因为在服务器上没有保存session的状态,所以恢复起来更容易。
更重要的是,无状态意味着分布式系统能够更好地工作,负载均衡器可以自由地将请求分发到任意的服务器。因为请求中都已经包含了服务器所需的所有信息,任何服务器都可以处理。
不仅仅是服务器,代理、网关、防火墙也可以理解消息,从而可以在不修改接口的情况下,增加更多强大的功能(比如代理缓存)。
并且,无状态让系统的横向拓展能力强大。因为不需要在不同的服务器之间同步session状态,所以服务器之间的沟通开销很低。增加服务器的数量不会带来明显的性能损失(“1+1”更接近于“2”了)。
需要注意的是,REST不是一个“宗教”。在你自己的应用中,遵循REST的同时应该保持合适的尺度。通过权衡利弊,选择总体效益最大的方案,即使这个方案有可能“稍微违反REST的原则”。详见"REST is not a religion..." - stackoverflow
HATEOAS
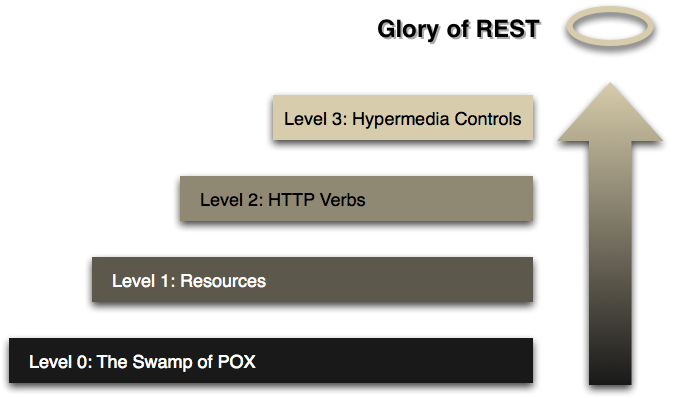
图片来自steps toward the glory of REST。
前面已经讨论了level 1和level 2,实际上REST还有一个更高的层次:HATEOAS(Hypermedia As The Engine Of Application State)。
对于客户端的资源请求,服务器不仅要返回所请求的资源,而且要返回客户端所处的状态和可转移的状态。(客户端有状态)
状态可以简单地理解为客户端展示的数据。可以把客户端比喻成一个状态机,那么这个状态机跳转到一个新的状态,就会显示新的内容。“首页”“文章列表”“某篇文章”就是三种客户端状态。
客户端不需要提前知道应用有哪些状态,而是根据服务端响应的“可转移的状态”,提供给用户选择,从而发生状态转移。
用简单的话来说,在严格的RESTful架构中,客户端不需要提前知道服务端的API有哪些、怎么调用,在客户端与服务器通信的过程中,服务端会告诉客户端:在你当前所处的状态下,有哪些API可以使用、可以转移到哪些状态。
既然服务器是无状态的,那么它要如何知道发起请求的用户处于什么状态呢?这就要求客户端在发送请求的时候要携带上足够的信息,让服务器能够判断客户端所处的状态。
这就很像10086的“电话自动语音应答服务”:你想要查询你的手机流量,只需要会拨打“10086”,对方会提示你按下哪些按键就能进入哪些状态。进入下一个状态以后,又会有语音提示你接下来能够按哪些按键……最终,你能进入到你想要的那个状态(流量查询服务)。你需要记住的仅仅是“10086”这个号码而已!
10086的语音提示相当于Hypermedia,是驱动应用状态转换的“引擎”。
再进一步想想,在RESTful架构中,所有的状态其实就组成了一颗树(更准确地说是网):根节点就是网站的基地址。在你获取一个节点中的资源的同时,服务器还会返回给你这个节点的边:Hypermedia(超链接就是一种Hypermedia)。通过Hypermedia,你能够知道相邻节点的基本信息、地址。
结果就是:你能够访问到这颗树的所有节点,而你所需要提前知道的只是“如何到达根节点”而已!
每个节点就是一个状态。用户可以在这个状态网中不断跳转。
这个例子(知乎)和这个例子(stackoverflow)也是不错的解释。
wikipedia的解释:a REST client should then be able to use server-provided links dynamically to discover all the available actions and resources it needs. As access proceeds, the server responds with text that includes hyperlinks to other actions that are currently available. There is no need for the client to be hard-coded with information regarding the structure or dynamics of the REST service.
这种架构的优势非常明显:前后端之间的耦合更加微弱。
随着应用功能的升级改变,“树”的样子会大大改变,但是只需要让后端修改返回的资源内容和Hypermedia,前端几乎不用改动。功能的演化更加灵活了。
“资源”和“状态”的关系
现在你应该明白Representational State Transfer中的State Transfer(状态传输)是什么意思了:在HATEOAS中,服务端将客户端所处的状态和可以达到的状态传输给客户端。
等一下,在前面的资源小节,我们不是说过传输的是资源表示(representation)吗?怎么这里又说传输的是状态?
其实在REST架构风格中,“传输状态”和“传输资源表示”是同一个意思。客户端所处的状态,是由它接收到的资源表示来决定的。比如,客户端接收到/user/csr/blogs资源,那么客户端的状态就变成/user/csr/blogs(显示csr的文章列表)。
等一下,为什么客户端会收到“/user/csr/blogs”资源?因为客户端请求的就是“/user/csr/blogs”资源。
继续追溯,为什么客户端会请求这个资源?因为用户点击了“查看文章列表”的链接(这个链接其实就是一个Hypermedia)。
继续追溯,为什么有一个“查看文章列表”的链接显示给用户点击?因为HATEOAS:服务端在返回上一个状态(资源)的时候,会返回所有相邻状态的Hypermedia,其中就包括“查看文章列表”这个Hypermedia。客户端会展示所有相邻状态的Hypermedia供用户选择。
按照从前往后的顺序梳理一遍:
客户端请求根资源
=> 服务器返回根资源的表示,以及相邻资源的Hypermedia
=> 客户端进入“根资源”状态(比如说,展示首页)
=> 客户端显示所有相邻状态的Hypermedia供用户选择(比如,在首页有一个导航栏,里面有几个链接)
=> 用户选择了某个Hypermedia(比如,点击了“查看文章列表”的链接)
=> 客户端请求“文章列表”资源
=> 服务器返回“文章列表”资源的表示,以及相邻资源的Hypermedia
=> 客户端进入“文章列表”状态
=> 客户端显示所有相邻状态的Hypermedia供用户选择(比如,在文章列表里,显示所有文章的链接)
……
不难发现,客户端接收到一个新的资源表示,就会跳转到新的状态,这个过程称为状态传输(服务器给客户端传输新状态)。因此状态传输是通过传输资源表示来完成的。
REST的字面意思
Representational State Transfer的语法结构是(Representational (State Transfer)),在这里我们用的是representation的形容词形式,意思是在表示层上的状态传输。这个词的字面意思是通过传输资源表示来传输客户端状态。
REST的字面意思在网络上有很多种理解,我参考了某位答主的两个回答:https://stackoverflow.com/a/1...和 https://stackoverflow.com/a/4... ,因为这位答主的回答最符合wikipedia的解释:"The term is intended to evoke an image of how a well-designed Web application behaves: it is a network of Web resources (a virtual state-machine) where the user progresses through the application by selecting links, such as /user/tom, and operations such as GET or DELETE (state transitions), resulting in the next resource (representing the next state of the application) being transferred to the user for their use."
总结
至此,我们应该能够体会到REST已经不仅仅是一种API风格了,它是一种软件架构风格(REST本身不是一种架构)。REST风格的软件架构具有很强的演化、拓展能力:
一致的URL和HTTP动词使用:确保系统能够接纳多样而又标准的客户端,保证客户端的演化能力。
无状态:保证了系统的横向拓展能力、服务端的演化能力。
HATEOAS:保证了应用本身的演化能力(功能增加、改变)。
这3点是单单对演化拓展优势的说明,这个回答总结了REST的6个约束分别对应的优点。
http://www.uml.org.cn/zjjs/201805142.asp
详解REST架构风格的更多相关文章
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- 【tomcat系列】详解tomcat架构(上篇)
java中,常用的web服务器一般由tomcat,weblogic,jetty,undertwo等,但从用户使用广泛度来说,tomcat用户量相对比较大一些,当然这也基于它开源和免费的特点. 从软件架 ...
- C++11 并发指南六(atomic 类型详解四 C 风格原子操作介绍)
前面三篇文章<C++11 并发指南六(atomic 类型详解一 atomic_flag 介绍)>.<C++11 并发指南六( <atomic> 类型详解二 std::at ...
- 详解HBase架构原理
一.什么是HBase HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价的PC Server上搭建大规模结构化存储集群. H ...
- (cdh)hive 基础知识 名词详解及架构
过程 启动 hive 之后出现的 CLI 是查询任务的入口,CLI 提交任务给 Driver Driver 接收到任务后调用 Compiler,Executor,Optimizer 将 SQL 语句转 ...
- 基于SOA的高并发和高可用分布式系统架构和组件详解
基于SOA的分布式高可用架构和微服务架构,是时下如日中天的互联网企业级系统开发架构选择方案.在核心思想上,两者都主张对系统的横向细分和扩展,按不同的业务功能模块来对系统进行分割并且使用一定的手段实现服 ...
- MPP大规模并行处理架构详解
面试官:说下你知道的MPP架构的计算引擎? 这个问题不少小伙伴在面试时都遇到过,因为对MPP这个概念了解较少,不少人都卡壳了,但是我们常用的大数据计算引擎有很多都是MPP架构的,像我们熟悉的Impal ...
- ThreadPoolExecutor运转机制详解
ThreadPoolExecutor运转机制详解 - 走向架构师之路 - 博客频道 - CSDN.NET 最近发现几起对ThreadPoolExecutor的误用,其中包括自己,发现都是因为没有仔细看 ...
- Spark框架详解
一.引言 作者:Albert陈凯链接:https://www.jianshu.com/p/f3181afec605來源:简书 Introduction 本文主要讨论 Apache Spark 的设计与 ...
随机推荐
- Microsoft Sql Server 2016安装在CentOS7下
安装过程 如何安装直接参考这个文章:安装sql server 整个安装过程非常简单. 上面的文档里是通过 sudo 命令,用root身份来执行,不过这里为了简单,就用root账号来安装的. (1)下载 ...
- ipad协议7.0,与大佬们分享几套新老版本的协议源码及算法,交流心得。
- JavaScript原型与继承的秘密
在GitHub上看到的关于JavaScript原型与继承的讲解,感觉很有用,为方便以后阅读,copy到自己的随笔中. 原文地址:https://github.com/dreamapplehappy/b ...
- C#克隆
克隆方法是原型设计模式中必须使用的方式,它将返回一个与当前对象数据一致的对象.正如其名,犹如一个模子雕刻而出.克隆类型分为两种:浅克隆.深克隆. 1.浅克隆 浅克隆方式是最简单.最直接的方式.只需要类 ...
- .Net Core在Middleware中解析RouteData
在ASP.Net Core中,如果直接在Middleware中获取RouteData返回的是空值,这是因为RouterMiddleware还没执行.但有些情况下需要获取RouteData,这要怎么做呢 ...
- redis的常用公共方法(2)
之前已经写过一篇redis公共方法的使用(https://www.cnblogs.com/jhy55/p/7681626.html),可是发现在高并发的时候出现 Unknown reply on in ...
- C# DataTable导出EXCEL后身份证、银行卡号等长数字信息显示乱码解决
在DataTable导出EXCEL后发现有些格式显示有问题,比如身份证.银行卡号等大于11位的数字显示为科学计数法.13681-1等 带中划线的两段数字显示为日期格式等. 处理方法如下: public ...
- Python 断言 assert 的用法
assert 后边接的表达式的返回值必须是布尔值 assert expression, "对错误的描述信息" 如果expression表达式返回的是True, 程序正常执行, 如果 ...
- Flask 中的 Response
1.Flask中的HTTPResponse @app.route("/") # app中的路由route装饰器 def index(): # 视图函数 return "I ...
- 主机安全扫描工具-- vuls
https://vuls.io/ 一. 安装 系统管理员有责任定期去检查系统的弱点和更新软件, vuls 可以提供如下功能: 通知管理员机器有安全隐患 支持本地和远程扫描(需要有 ssh 权限) 可以 ...