Kafka分布式环境搭建 (二)赞
这篇文章将介绍如何搭建kafka环境,我们会从单机版开始,然后逐渐往分布式扩展。单机版的搭建官网上就有,比较容易实现,这里我就简单介绍下即可,而分布式的搭建官网却没有描述,我们最终的目的还是用分布式来解决问题,所以这部分会是重点。
Kafka的中文文档并不多,所以我们尽量详细点儿写。要交会你搭建分布式其实很简单,手把手的教程大不了我录个视频就好了,可我觉得那不是走这条路的方 式。只有真正了解原理,并且理解的透彻了才能最大限度的发挥一个框架的作用。所以,如果你不了解什么事kafka,请先看:《kafka初步》
我们从搭建单机版的环境开始说起,如果你喜欢看英文版:这里有官方的《quick start》
单机版的部署很简单,我就讲几点比较重要的,首先kafka是用scala编写的,可以跑在JVM上,所以我们并不需要单独去搭建scala的环境,后面会涉及到编程的时候我们再说如何去配置scala的问题,这里用不到,当然你要知道这个是跑在linux上的。第二,我用的是最新版0.7.2的版本,你下载完kafka你可以打开它的目录浏览一下:
我就不介绍每个包里的内容是干嘛的,我就着重说一点,你在这个文件夹里只能找到3个jar包,并且这3个还不能用于后面的编程,而且你也没法在里面找到pom这样用于构建的xml。也别急,也别满世界找,这些依赖库得等你把它放到linux上才会出现(当然需要命令)。
搭建单机版环境,简单的说有那么几步:
1. 安装java环境,我用的是最新的版本jdk7的
2. 将下载下来的kafka扔到linux上,并解压。我用的red het server的linux。
3. 接下来就是下载kafka的依赖包和构建kafka的环境。注意,这一步需要电脑联网。具体命令就是官网介绍的./sbt update 和 ./sbt package。
4. 执行完上面这步大概会花个10多分钟吧,我在自己家里ubuntu没有成功,报了下载不到jline的错。单位里用虚拟机ubuntu成功了,我深刻怀疑是网的问题。上面这不执行完了有两点要注意,一是sbt帮你下载完了所有依赖库,但是这些jar都是分散在各个目录下的,注意区分。二是,这些jar一部分是kafka的编程包,一部分是scala的环境包,上面说了没必要自己去搭scala的环境道理就在这边,你自己去下一个2.9的scala,但人家kafka只支持2.8、2.7。所以编程的时候就用sbt给你下好的包即可。后面讲到编程的时候,会写怎么搭编程环境,很简单的。
上面的步骤都执行完了,环境算是好了,下面我们要测试下是否能成功运行kafka:
1. 启动zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是为了能退出命令行)
2. 启动kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka为我们提供了一个console来做连通性测试,下面我们先运行producer:bin/kafka-console-producer.sh --zookeeper localhost:2181 --topic test 这是相当于开启了一个producer的命令行。命令行的参数我们一会儿再解释。
4. 接下来运行consumer,新启一个terminal:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
5. 执行完consumer的命令后,你可以在producer的terminal中输入信息,马上在consumer的terminal中就会出现你输的信息。有点儿像一个通信客户端。
具体可看《quick start》
如果你能看到5执行了,说明你单机版部署成功了。下面解释下两条命令中参数的意思。--zookeeper localhost:2181 这个说明了去连本机2181端口的zookeeper server,--topic test,在kafka里,消息按topic来区分,我们这里的topic叫test,所以不管是consumer还是producer都指向了test。其他的参数,我就截图了,首先是producer的参数:
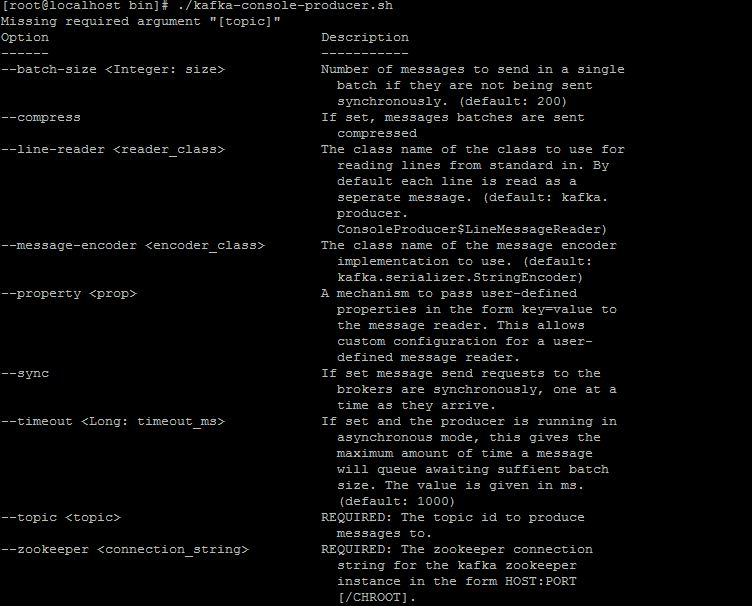
Consumer的参数:
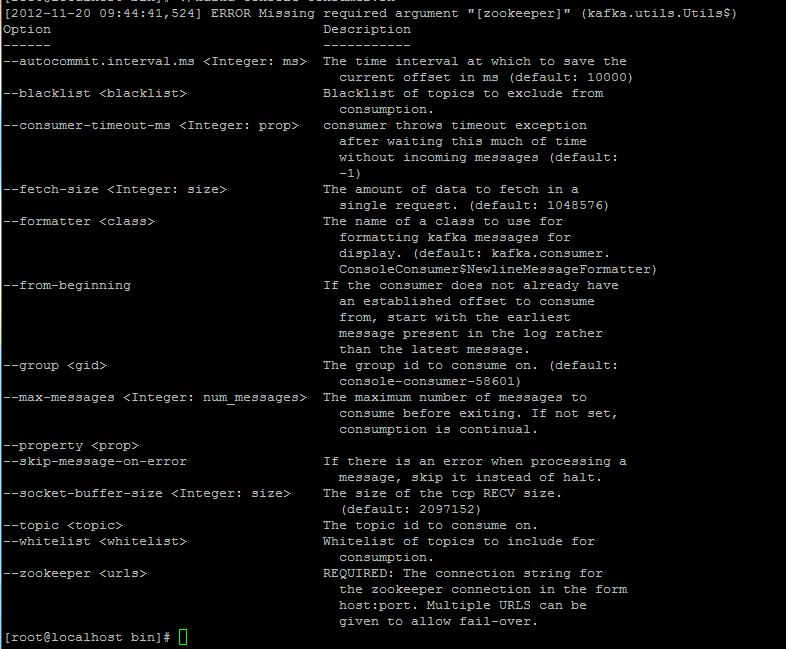
这些参数你可以先看个大概,之后会在编程中使用到,都可以动态的配置。
好了单机版就部署完了,那是不是我把consumer的放到另一台机器上就算分布式了呢。是的,前提是,你还能运行到上面的第5步。在讲配置之前,我们还是将上篇写的分布式来回顾一下,当然我们简化一下情况,按照实际部署的分析:

假设我只有两台机器,server1和server2。我现在想把zookeeper server和kafka server 和producer都放在一台机器上server1,把consumer放在server2上。这当然也叫分布式了,虽然机子不多,但是这个部署成功了,扩展是相当的容易。
我们还是按照那5个步骤来做,当然你肯定能知道,3、4两步的参数要改了,我们假设server1的IP是192.168.10.11 server2的IP是192.168.10.10:
1. 启动zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是为了能退出命令行)
2. 启动kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka为我们提供了一个console来做连通性测试,下面我们先运行producer:bin/kafka-console-producer.sh --zookeeper 192.168.10.11:2181 --topic test 这是相当于开启了一个producer的命令行。
4. 接下来运行consumer,新启一个terminal:bin/kafka-console-consumer.sh --zookeeper 192.168.10.11:2181 --topic test --from-beginning
5. 执行完consumer的命令后,你可以在producer的terminal中输入信息,马上在consumer的terminal中就会出现你输的信息。
这个时候你能执行出第5步的效果么,是不是报了下面的错了:

我来说原因,在这之前想请你再回去看看《kafka初步》,看看里面讲分布式的内容:
这里的kafka server就是broker,broker是存数据的,producer把数据给broker,consumer从broker取数据。那zookeeper是干嘛的,说的肤浅点儿,zookeeper就是他们之间的选择分发器,所有的连接都要先注册到zookeeper上。你可以把它想象成NIO,zookeeper就是selector,producer、consumer和broker都要注册到selector上,并且留下了相应的key。
所以问题就出在了kafka server的配置server.properties上。Kafka注册到zookeeper上的信息不对,才导致了上面的错误。我们看config中server.properties的配置就可以知道:
|
1
2
3
4
|
# Hostname the broker will advertise to consumers. If not set, kafka will use the value returned# from InetAddress.getLocalHost(). If there are multiple interfaces getLocalHost# may not be what you want.#hostname= |
默认的hostname如果你不设置,就是127.0.0.1,所以你把这个hostname设置成192.168.10.11即可,这样你重启下kafka server端,就能执行第5步了。
成功配置的话,你能看到下面的效果,左边的是producer,右边的是consumer,看最下面两行好了,前面的是我之前测试用过的:

如果你还是云里雾里的,建议你回头去看看上篇文章,将kafka分布式基本原理的,kafka实际操作是要建立在对原理熟悉的情况下的。
搭建完了环境,后面就要开始写程序去处理实际问题了。当然再写程序之前,下一篇我会先写一点kafka为什么会有如此高的性能,它是怎么保障这些性能的。
来源http://my.oschina.net/ielts0909/blog/93190
Kafka分布式环境搭建 (二)赞的更多相关文章
- Kafka 分布式环境搭建
这篇文章将介绍如何搭建kafka环境,我们会从单机版开始,然后逐渐往分布式扩展.单机版的搭建官网上就有,比较容易实现,这里我就简单介绍下即可,而分布式的搭建官网却没有描述,我们最终的目的还是用分布式来 ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- Hadoop-2.4.1完全分布式环境搭建
Hadoop-2.4.1完全分布式环境搭建 Hadoop-2.4.1完全分布式环境搭建 一.配置步骤如下: 主机环境搭建,这里是使用了5台虚拟机,在ubuntu 13系统上进行搭建hadoop ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Kafka开发环境搭建(五)
如果你要利用代码来跑kafka的应用,那你最好先把官网给出的example先在单机环境和分布式环境下跑通,然后再逐步将原有的consumer.producer和broker替换成自己写的代码.所以在阅 ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- 大数据学习笔记【一】:Hadoop-3.1.2完全分布式环境搭建(Windows 10)
一.前言 Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建). 首先,步骤: ① 准备安装包和工具: hadoop-3 ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
随机推荐
- hdu 5078(2014鞍山现场赛 I题)
数据 表示每次到达某个位置的坐标和时间 计算出每对相邻点之间转移的速度(两点间距离距离/相隔时间) 输出最大值 Sample Input252 1 9//t x y3 7 25 9 06 6 37 6 ...
- Winfom 插件式(Plugins)/模块化开发框架-动态加载DLL窗体-Devexpress
插件式(AddIn)架构,不是一个新名词,应用程序采用插件式拼合,可以更好的支持扩展.很多著名的软件都采用了插件式的架构,如常见的IDE:Eclipse,Visual Studio,SharpDeve ...
- hdoj1203 I NEED A OFFER!(DP,01背包)
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=1203 思路 求最少能收到一份offer的最大概率,可以先求对立面:一份offer也收不到的最小概率,然 ...
- react篇章-React State(状态)-数据自顶向下流动
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title&g ...
- Windows 服务器部署 asp.net core
踩坑日记与 Windows 服务器部署 asp.net core 指南. 准备 操作系统:Windows Server 2008 R2 或更高版本 文件: Microsoft Visual C++ 2 ...
- c语言程序与设计第三版-苏小红--第一轮学习笔记、难点整理
---恢复内容开始--- 1> 编程:需求分析.设计.编写程序(编码.编辑.链接.运行).调试程序 2> 指数形式:e的左边是数值部分(有效数字),不能省略,但可以表示成 .e-4:等等: ...
- MySQL 关于存储过程那点事
存储例程是存储在数据库服务器中的一组sql语句,通过在查询中调用一个指定的名称来执行这些sql语句命令. 简介 SQL语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完 ...
- python中 .write 无法向文件写入内容
问题代码如下 links = open("new") out = open("out.txt","w+") for link in link ...
- 直接插入排序(高级版)之C++实现
直接插入排序(高级版)之C++实现 一.源代码:InsertSortHigh.cpp /*直接插入排序思想: 假设待排序的记录存放在数组R[1..n]中.初始时,R[1]自成1个有序区,无序区为R[2 ...
- BZOJ 3572: [Hnoi2014]世界树 虚树 树形dp
https://www.lydsy.com/JudgeOnline/problem.php?id=3572 http://hzwer.com/6804.html 写的时候参考了hzwer的代码,不会写 ...