ceph crush算法和crushmap浅析
1 什么是crushmap
crushmap就相当于是ceph集群的一张数据分布地图,crush算法通过该地图可以知道数据应该如何分布;找到数据存放位置从而直接与对应的osd进行数据访问和写入;故障域的设置和数据冗余选择策略等。crushmap的灵活设置显示出了ceph的软件定义存储方案。
这里可以引入raid相关的概念来对比下:
raid0:又称为Stripe,中文名为条带,它是所有RAID级别中存储性能最高的,它的原理就是把连续的数据分散存储到多个磁盘中,充分利用了每个磁盘的吞吐,突破了单个磁盘的吞吐限制。
raid1:又称为Mirror,中文名为镜像,它的主要宗旨是保证用户的数据可用性和可修复性,它的原理是把用户写入硬盘的数据百分之百的自动复制到另外一个磁盘上。
raid10:高可靠性与高效磁盘结构,可以理解为raid0和raid1的互补结合,类似于ceph中的多副本策略。
raid5:是一种存储性能、存储成本和数据安全都兼顾的一种方案,它的原理是不对存储的数据进行备份,而是把数据和存储校验信息存储到组成raid5的各个磁盘上,当raid5的一个磁盘损坏时,可以根据剩下的数据和奇偶校验信息来恢复损坏的数据,类似于ceph中的纠删码策略。
对导出的crushmap进行反编译后得到的内容如下:
# begin crush map 选择存放副本位置时的选择算法策略中的变量配置
tunable choose_local_tries
tunable choose_local_fallback_tries
tunable choose_total_tries
tunable chooseleaf_descend_once
tunable straw_calc_version # devices 一般指的是叶子节点osd
device osd.
device osd.
device osd. # types 树形下的多种类型
type osd # 一般一个osd对应一个磁盘
type host # 一般host表示是一个主机,即某一台服务器
type chassis # 系列
type rack # 机架
type row # 排
type pdu #
type pod #
type room # 机房
type datacenter # 数据中心
type region # 区域
type root # 根 # buckets 躯干部分 host一般是表示一个物理节点,root是树形的根部
host thinstack-test0 {
id - # do not change unnecessarily
# weight 0.031
alg straw # ceph作者实现的选择item的算法
hash # rjenkins1 这代表的是使用哪个hash算法,0表示选择rjenkins1这种hash算法
item osd. weight 0.031
}
host thinstack-test1 {
id - # do not change unnecessarily
# weight 0.031
alg straw
hash # rjenkins1
item osd. weight 0.031
}
host thinstack-test2 {
id - # do not change unnecessarily
# weight 0.031
alg straw
hash # rjenkins1
item osd. weight 0.031
}
root default {
id - # do not change unnecessarily
# weight 0.094
alg straw
hash # rjenkins1
item thinstack-test0 weight 0.031
item thinstack-test1 weight 0.031
item thinstack-test2 weight 0.031
} # rules 副本选取规则的设定
rule replicated_ruleset {
ruleset
type replicated
min_size
max_size
step take default # 以default root为入口
step chooseleaf firstn type host # 看如下 解释1
step emit # 提交
} # end crush map 解释1:
step chooseleaf firstn {num} type {bucket-type}
chooseleaf表示选择bucket-type的bucket并选择其的叶子节点(osd)
当num等于0时:表示选择副本数量个bucket
当num > and num < 副本数量时:表示选择num个bucket
当num < : 表示选择 副本数量 - num 个bucket
2 crush的基本原理
常用的分布式数据分布算法有一致性Hash算法和Crush算法,Crush也称为可扩展的伪随机数据分布算法
一致性Hash算法原理:
对一个圆形(圆形可以是0-2的31次方-1)用n个虚拟节点将其划分成n个区域,每个虚拟节点管控一个范围,如下图所示: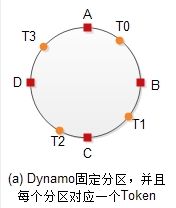
T0负责[A, B],T1负责[B, C],T2负责[C,D],T3负责[D,A]
由于分区是固定的,所以我们很容易知道哪些数据要迁移,哪些数据不需要迁移。
在每个节点的存储容量相等且虚拟节点跟物理节点个数一致时,就会是每个节点对应一段相同大小的区段,从而可以达到最佳的数据分布。
Crush算法原理:
Crush算法跟一致性Hash算法原理很类似,其中的pg就是充当上面所说的虚拟节点的作用,用以分割区域,每个pg管理的数据区间相同,因而数据能够均匀的分布到pg上。
crush分布数据过程:
数据x经过hash函数得到一个值,将该值与pg数量取模得到数值,该数值即是pg的编号,然后通过crush算法知道pg是对应哪些osd的,最后是将数据存放到pg对应的osd上。其中经过了两次的映射,一次是数据到pg的映射,一次是pg到osd的映射,由于pg是抽象的存储节点,一般情况下,pg的数量是保持的不变的,不随着节点的增加或减少而改变,因此数据到pg的映射是稳定的。
3 利用crushmap可以做哪些事
(1)故障域的设置
ceph中已经定义的故障域有:
# types
type 0 osd # 一般一个osd对应一个磁盘
type 1 host # 一般host表示是一个主机,即某一台服务器
type 2 chassis # 系列
type 3 rack # 机架
type 4 row # 排
type 5 pdu #
type 6 pod #
type 7 room # 机房
type 8 datacenter # 数据中心
type 9 region # 区域
type 10 root # 根
当然也可以自定义类型
比如有3台服务器,设置的故障域为host,数据冗余策略为多副本的2副本策略,则数据会保存到其中的两台服务器上,这样当其中一台服务器挂掉时,确保还有冗余数据在另外一台服务器上,保证了数据的可靠性。
(2)指定数据存放到指定位置上
比如对于一些私有云来说,可以划分ssd的磁盘用以存放镜像等数据,这样虚拟机启动会比较快,对于快照和备份等冷数据则可存放在sata盘中。
(3)保证数据尽可能的均衡
可以设定osd的权重,如果只考虑容量,则一般1T容量权重设为1.0
(4)尽可能保证数据不会大量迁移引起性能问题
当有节点故障时需要进行数据均衡时,可以设定合理的crushmap让数据的迁移只发生在一个小范围内
4 crushmap实践
(1)获取当前crushmap并修改和应用
获取当前集群中应用的crushmap文件到一个文件中:ceph osd getcrushmap -o crushmap.txt
上面导出的crushmap.txt是乱码的,需要进行反编译来查看:crushtool -d crushmap.txt -o crushmap-decompile
此时就是文本形式了,可以在这个文件上修改,修改后进行编译:crushtool -c crushmap-decompile -o crushmap-compiled
然后应用到集群中:ceph osd setcrushmap -i crushmap-compiled
注意:这样修改如果想要服务重启后保持原来的,需要在配置文件的[osd]上加上:osd crush update on start = false,否则启动时会校验当前位置是否是正确的位置,如果不是则会自动移动到之前的位置
如果只是想查看下当前的crush map分布,可以用命令行查看:ceph osd crush tree
(2)命令行构建crush map
<1>添加bucket:ceph osd crush add-bucket {bucket-name} {bucket-type}
比如添加一个root类型的名为default的bucket:ceph osd crush add-bucket default root
添加一个host类型的名为test1的bucket:ceph osd crush add-bucket test1 host
<2>移动一个bucket:ceph osd crush move {bucket-name} {bucket-type}={bucket-name}, [...]
比如我想将bucket1 test1移动到root类型的名为default2下:ceph osd crush move test1 root=default2
move操作是针对host及host以上的bucket的,如果是想把osd移动到某个bucket上,则可以先ceph osd crush remove 掉osd,然后再ceph osd crush add重新指定到想要指定的bucket下去
<3>移除一个bucket:ceph osd crush remove {bucket-name}
比如:ceph osd crush remove test1
<4>添加或移动osd的crush map位置:ceph osd crush set {name} {weight} root={root} [{bucket-type}={bucket-name} ...]
比如我将osd.1设置test1下:ceph osd crush set osd.1 1.0 root=default host=test1
或者用ceph osd crush add osd.1 host=test1
<5>调整osd的权重:ceph osd crush reweight {name} {weight}
比如:ceph osd crush reweight osd.1 2.0
<6>移除osd crush map:ceph osd crush remove {name}
比如:ceph osd crush remove osd.1
<7>创建一个副本策略:ceph osd crush rule create-replicated {name} {root} {failure-domain-type} [{class}] # 低版本没有这个,比如0.94.10就没有
比如创建一个故障域级别为host的副本策略:ceph osd crush rule create-replicated rep_test default host
自己项目中用的创建命令:ceph osd crush rule create-simple rep_test default host firstn # 原型是osd crush rule create-simple <name> <root> <type> {firstn|indep}
<8>给pool指定副本策略:ceph osd pool set <pool-name> crush_rule <rule-name>
比如:ceph osd pool set testpool crush_rule test_rule
(3)创建指定主副本放在host A上,其它副本放在host B上
# rules
rule replicated_ruleset {
ruleset
type replicated
min_size
max_size
step take A
step chooseleaf firstn type osd
step emit step take B
step chooseleaf firstn - type osd
step emit
}
这时可以用ceph pg dump命令看pg的分布是否是如我们所想的那样分布。
或者测试数据是否真的落到我们想要的osd上:
put一个文件命名对象名为uuu到testpool中去:rados put uuu kk.txt -p volumes
查看该对象是在哪个osd上:ceph osd map testpool uuu
还有个简单的方法来设置某个osd作为主的,某个为副osd:
假设只有osd.0和osd.1,要将osd.0作为副本osd,1作为主osd,则可以将osd.0的主亲和力设置为0,这样osd.0就只能做副本osd
ceph tell mon.\* injectargs '--mon_osd_allow_primary_affinity=true'
ceph osd primary-affinity osd.0 0
(4)将ssd磁盘的osd用来放主副本,hdd磁盘的osd用来放副本
思路:可以创建两个root类型,一个名为ssd,一个名为hdd,然后ssd磁盘的osd移到root=sdd下,hdd磁盘的osd移到root=hdd下,crushmap内容如下:
# begin crush map
tunable choose_local_tries
tunable choose_local_fallback_tries
tunable choose_total_tries
tunable chooseleaf_descend_once
tunable straw_calc_version # devices
device osd.
device osd. # types
type osd
type host
type chassis
type rack
type row
type pdu
type pod
type room
type datacenter
type region
type root # buckets
host A {
id - # do not change unnecessarily
# weight 0.031
alg straw
hash # rjenkins1
item osd. weight 0.031
}
host B {
id - # do not change unnecessarily
# weight 0.031
alg straw
hash # rjenkins1
item osd. weight 0.031
}
root ssd {
id - # do not change unnecessarily
# weight 0.031
alg straw
hash # rjenkins1
item A weight 0.031
}
root hdd {
id - # do not change unnecessarily
# weight 0.031
alg straw
hash # rjenkins1
item B weight 0.031
} # rules
rule replicated_ruleset {
ruleset
type replicated
min_size
max_size
step take ssd
step chooseleaf firstn type host
step emit step take hdd
step chooseleaf firstn - type host
step emit
} # end crush map
ceph osd tree的命令执行如下:
[root@test ~]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
- 0.03099 root hdd
- 0.03099 host thinstack-test1
0.03099 osd. up 1.00000 1.00000
- 0.03099 root ssd
- 0.03099 host thinstack-test0
0.03099 osd. up 1.00000 1.00000
ceph crush算法和crushmap浅析的更多相关文章
- 014 Ceph管理和自定义CRUSHMAP
一.概念 1.1 Ceph集群写操作流程 client首先访问ceph monitor获取cluster map的一个副本,知晓集群的状态和配置 数据被转化为一个或多个对象,每个对象都具有对象名称和存 ...
- ceph 009 管理定义crushmap 故障域
管理和自定义crushmap 定义pg到osd的映射关系 通过crush算法使三副本映射到理想的主机或者机架 更改故障域提高可靠性 pg到osd映射由crush实现 下载时需要将对象从osd搜索到,组 ...
- 最小生成树---Prim算法和Kruskal算法
Prim算法 1.概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (gra ...
- 经典算法和OJ网站(开发者必备-转)
一. Online Judge简介: Online Judge系统(简称OJ)是一个在线的判题系统.用户可以在线提交程序多种程序(如C.C++.Pascal)源代码,系统对源代码进行编译和执行,并通过 ...
- BM算法和Sunday快速字符串匹配算法
BM算法研究了很久了,说实话BM算法的资料还是比较少的,之前找了个资料看了,还是觉得有点生涩难懂,找了篇更好的和算法更好的,总算是把BM算法搞懂了. 1977年,Robert S.Boyer和J St ...
- 台球游戏的核心算法和AI(2)
前言: 最近研究了box2dweb, 觉得自己编写Html5版台球游戏的时机已然成熟. 这也算是圆自己的一个愿望, 一个梦想. 承接该序列的相关博文: • 台球游戏核心算法和AI(1) 同时结合htm ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- 转载:最小生成树-Prim算法和Kruskal算法
本文摘自:http://www.cnblogs.com/biyeymyhjob/archive/2012/07/30/2615542.html 最小生成树-Prim算法和Kruskal算法 Prim算 ...
随机推荐
- sql中非存储过程定义参数并使用
DECLARE @dt datetime SET @dt=GETDATE()--1.短日期格式:yyyy-m-d SELECT REPLACE(CONVERT(varchar(10),@dt,120) ...
- javascript中字符串常用操作总结
String对象属性 (1) length属性 length算是字符串中非常常用的一个属性了,它的功能是获取字符串的长度.当然需要注意的是js中的中文每个汉字也只代表一个字符,这里可能跟其他语言有些不 ...
- 对于移动端浏览器touch事件的研究总结(4)判断手指滑动方向
最近有一些微信的项目,虽然页面很简单,但配合手势后的效果却是很不错的.最基本的效果就是手指向上滑,页面配合css3出现一个展开效果,手指向下滑将展开的内容按原路径收起.其实就是一个简单的判断手指滑动方 ...
- SSH框架中NoSuchMethodError: antlr.collections.AST.getLine()的解决方案
问题: 当配置好SSH框架后,使用Hibernate的Query功能时发生如下异常: NoSuchMethodError: antlr.collections.AST.getLine() 原因: St ...
- SDWebImage实现图片展示、缓存、清除缓存
1. /* 图片显示 */ [self.imageView sd_setImageWithURL:[NSURL URLWithString:urlString]]; [s ...
- element-ui中使用font-awesome字体图标
element-ui提供的字体图标是很少的,所以我们需要集成其它图标来使用,nodejs的集成官方有说明,这里说明一下非nodejs开发集成图标 首先下载fontawesome,需要更改里面图标前缀, ...
- springboot中使用druid和监控配置
如果想要监控自己的项目的访问情况及查看配置信息,druid是一个很好的选择,可能你会问druid是什么?有什么用?优点是什么? Druid简介 Druid是阿里巴巴开源的数据库连接池,号称是Java语 ...
- react生命周期获取异步数据
当react组件需要获取异步数据的时候,建议在ComponentDidMount周期里执行获取动作, 如果非异步数据,可以在ComponentWillMount获取 因为ComponentWillMo ...
- 星级评分进度条(RatingBar)
星级评分进度条(RatingBar):(主要用于评价等方面) 常用的xml属性; android:isIndicator:RatingBar是否是一个指示器(用户无法进行更改) android:num ...
- Pig store用法举例
store:将数据存储到HDFS等文件系统里 将数据保存到/data目录 store data into '/data'; 以逗号为分隔符 store data into '/data' usin ...