HDFS要点剖析
谈到大数据,不得不提的一个名词是“HDFS”。它是一种分布式文件存储系统,其系统架构图如下图所示:
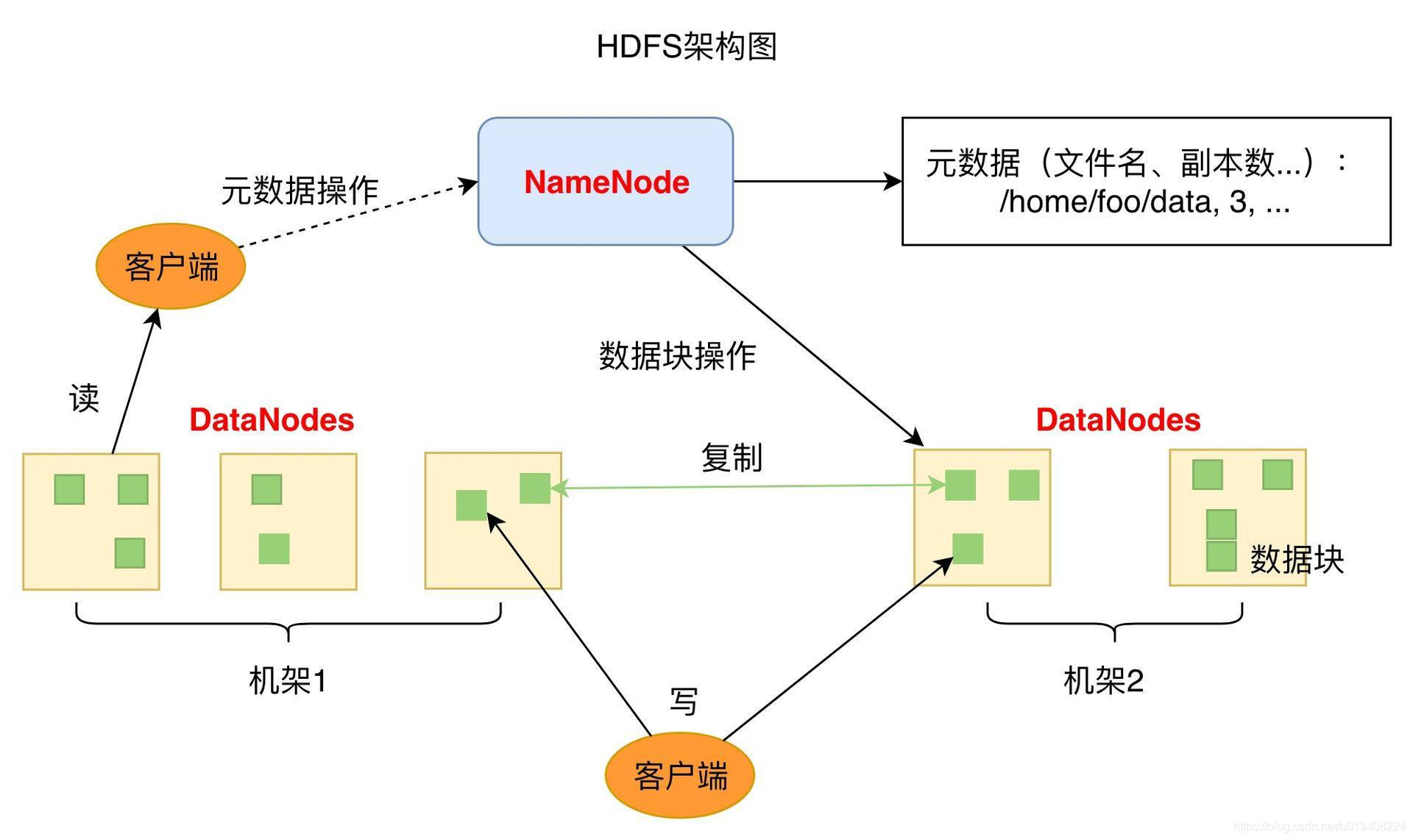
从图中可以了解到的几个关键概念
- 元数据(MetaData)
- 机架(Rock)
- 块(Block)
从图中可以了解到的两个重要组件:
- NameNode
- DataNode
需要了解的另一个组件:
- SecondaryNameNode
三个重要的组件说明
NameNode
简单地说,NameNode 有管理和存储两个作用。NameNode 管理文件系统的命名空间,维护文件系统树以及树中的所有文件和目录。它存储的是元数据(Metadata)信息,包括文件名目录以及它们之间的层级关系、文件目录的所有者及其权限、每个文件块的名以及文件有哪些块组成等。
这里就很容易理解为什么Hadoop倾向存储大文件的原因了:因为文件越小,存储同等大小文件需要的元信息就越多,会给NameNode 带来了存储压力。
在 NameNode 中存放元信息的文件是 fsimage 。在系统运行期间,所有对元信息的操作都需要保存到内存中并持久化到另一个文件 edit logs,我们在讲解 SecondaryNameNode 组件时还会提到这两个文件。
DataNode
DataNode 具有的作用如下:
- 负责存储数据块(磁盘读写的基本单位),并提供数据块的读写服务。
- 根据 NameNode 的指示进行创建、删除和复制等操作。
- 通过心跳机制,定期报告文件块列表信息。
- 进行 DataNode 之间通信,以及块的副本处理。
SecondaryNameNode
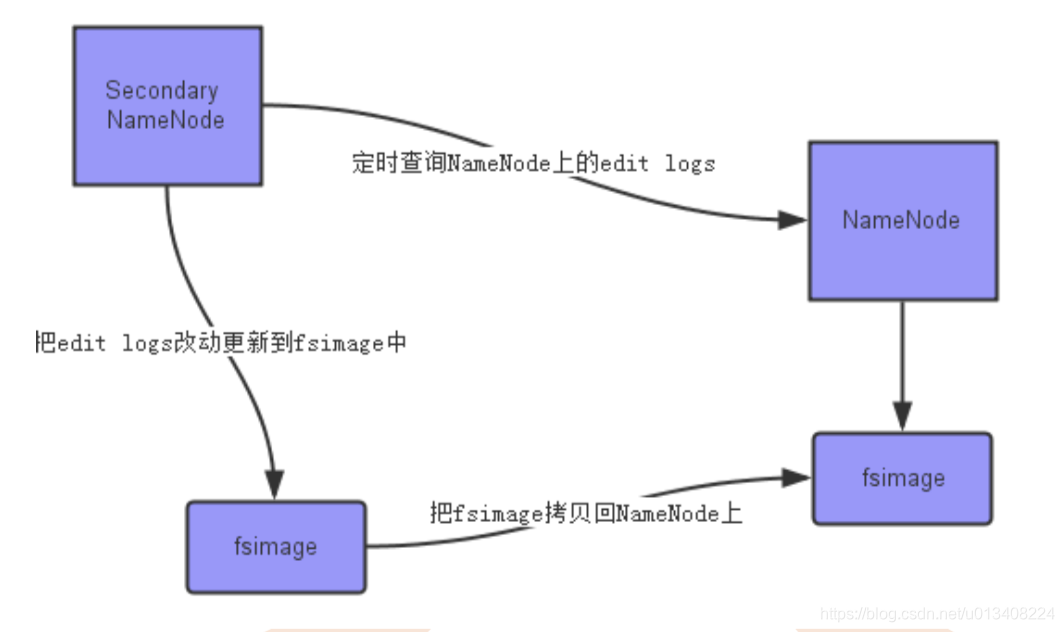
SecondaryNameNode并不是 NameNode 的备份,这点很容易理解错。SecondaryNameNode 是在文件系统中设置一个检查站点帮助 NameNode 更好的工作。
这里我们简单梳理一下 NameNode 的加载过程:NameNode 启动时通过 fsimage 文件获取整个文件系统的快照,启动后将对文件系统的改动写到 edit logs 中,SecondaryNameNode 定时去获取 这个 edit logs,并更新到自己的 fsimage 中。一旦有了新的 fsimage,将其再拷贝回 NameNode 中,NameNode下次启动时会使用这个新的 fsimage,这个过程如下图所示:
HDFS 的高可用设计
机架感知策略
机架感知策略简单点说就是副本放置策略。HDFS 中默认一个块具有三个副本,其分布如下图所示:
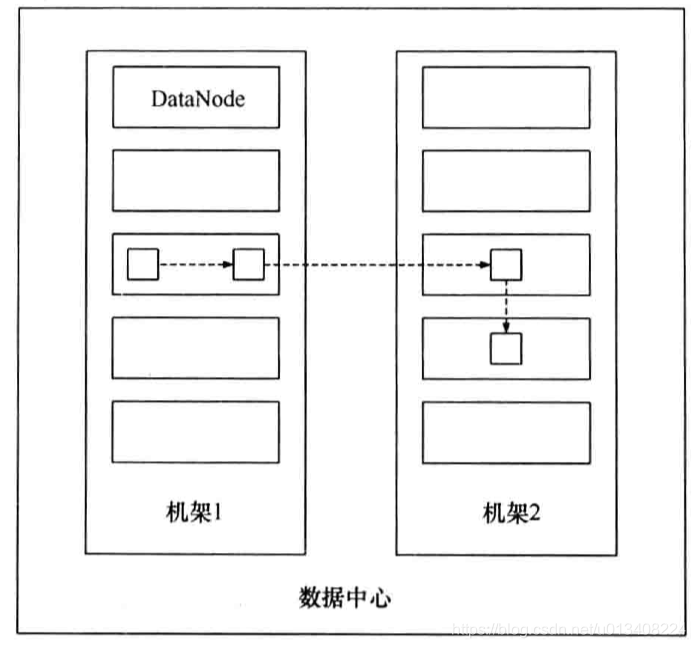
第一个副本放在客户端相同的节点上,第二个副本放在不同机架的节点上,第三个副本放在与第二个副本同机架但不同节点上。
容错
我们在讨论容错时,通常关注这四个角度:数据存储故障容错、磁盘故障容错、DataNode 故障容错以及 NameNode 故障容错。对于这几个角度的容错又可以从三个维度去分析:冗余备份、失效转移和降级限流。例如:NameNode 的故障检测通过 fsimage 文件和 edit logs文件;数据的故障容错通过冗余备份——机架感知策略等。
HDFS 的特点
HDFS 能够管理和存储PB级别数据,处理非结构化数据,一般对数据的及时性要求不高,通常适合 write-once-read-many 存取模式。
HDFS 不建议存储小文件,不建议大量随机读,不支持多用户写入以及不支持对文件的修改。
HDFS 写流程
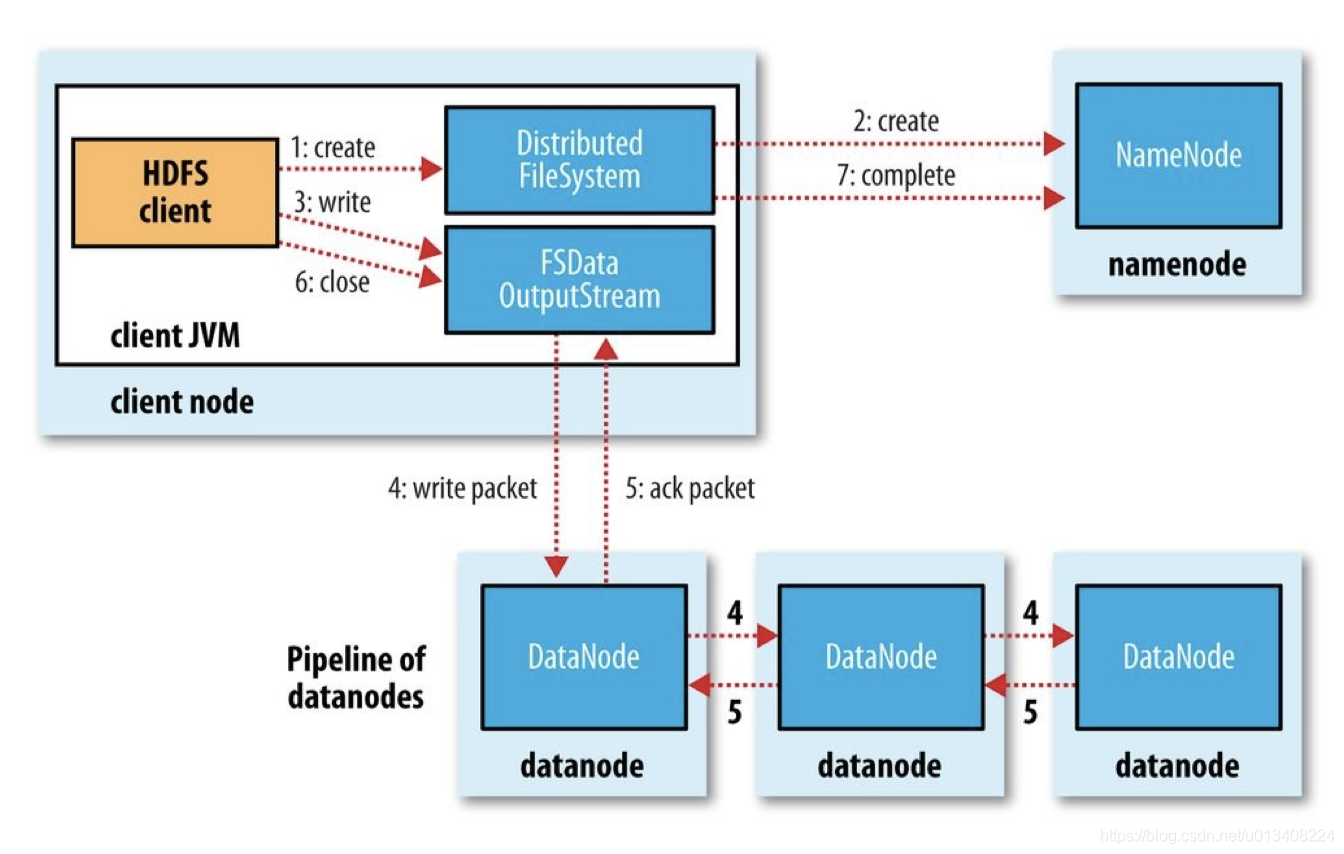
客户端调用 create()来创建文件,Distributed File System 用 RPC 调用 NameNode 节点,在文件系统的命名空间中创建一个新的文件。NameNode 节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
Distributed File System 返回 DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream 将数据分成块,写入 Data Queue。Data Queue 由 Data Streamer 读取,并通知 NameNode 节点分配数据节点,用来存储数据块(每块默认复制 3 块)。分配的数据节点放在一个 Pipeline 里。Data Streamer 将数据块写入 Pipeline 中的第一个数据节点。 第一个数据节点将数据块发送给第二个数据节点。 第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream 为发出去的数据块保存了 Ack Queue,等待 Pipeline 中的数据节点告知数据已经写入成功。
HDFS 读流程
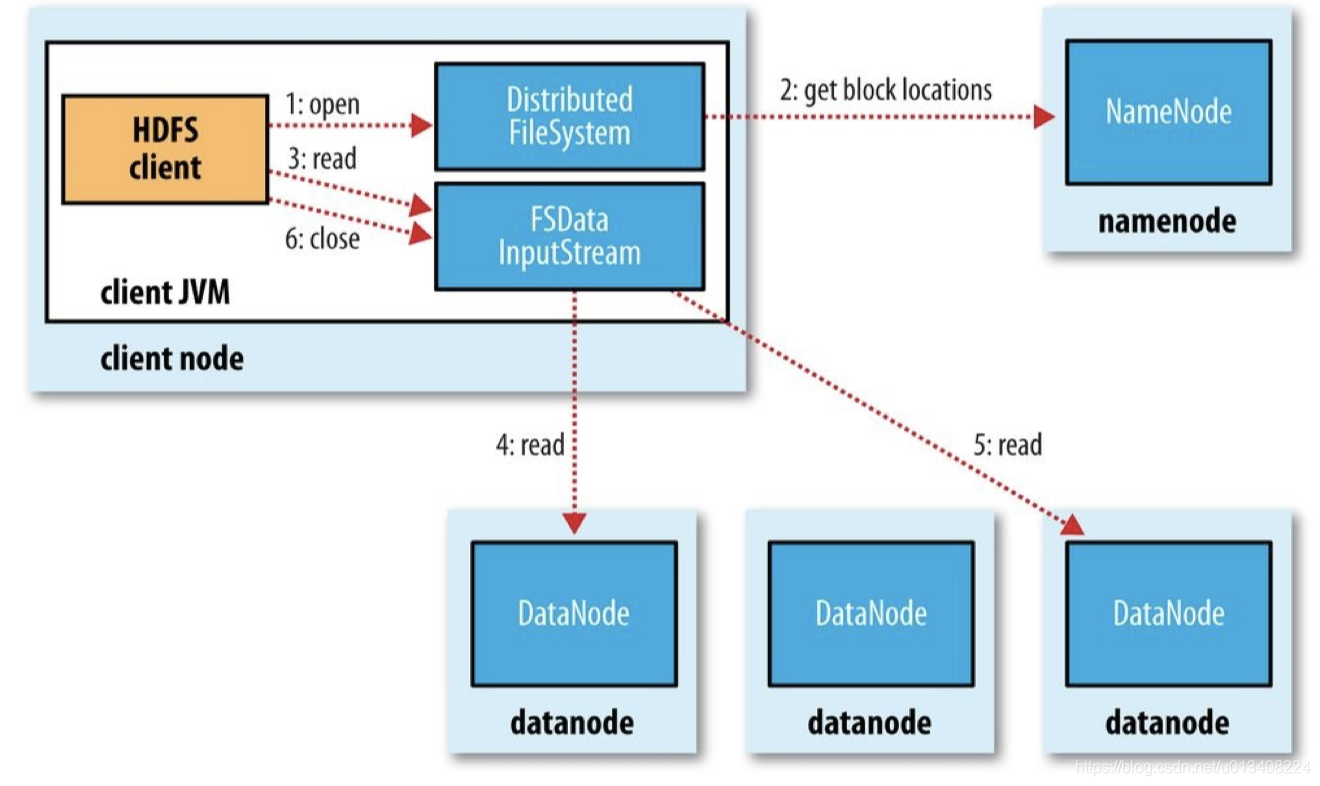
首先 Client 通过 File System的 Open函数打开文件, Distributed File System用RPC 调用 NameNode 节点,得到文件的数据块信息。
对于每一个数据块,NameNode 节点返回保存数据块的数据节点的地址。Distributed File System 返回 FSDataInputStream 给客户端, 用来读取数据。 客户端调用 stream 的 read()函数开始读取数据。 DFSInputStream 连接保存此文件第一个数据块的最近的数据节点。DataNode 从数据节点读到客户端(client),当此数据块读取完毕时,DFSInputStream 关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。当客户端读取完毕数据的时候,调用FSDataInputStream 的 close 函数。
在读取数据的过程中, 如果客户端在与数据节点通信出现错误, 则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
HDFS要点剖析的更多相关文章
- HDFS数据流-剖析文件读取及写入
HDFS数据流-剖析文件读取及写入 文件读取 1. 客户端通过调用FileSystem对象的open方法来打开希望读取的文件,对于HDFS来说,这个对象是分布式文件系统的一个实例.2. Distrib ...
- HDFS要点
namenode存储的数据: 主控服务器主要有三类数据:文件系统的目录结构数据,各个文件的分块信息,数据块的位置信息(就数据块放置在哪些数据服务器上...).在GFS和HDFS的架构中,只有文件的目录 ...
- hadoop(五)HDFS原理剖析
一.HDFS的工作机制 工作机制的学习主要是为加深对分布式系统的理解,以及增强遇到各种问题时的分析解决能 力,形成一定的集群运维能力PS:很多不是真正理解 hadoop 工作原理的人会常常觉得 HDF ...
- Hadoop 2.x从零基础到挑战百万年薪第一季
鉴于目前大数据Hadoop 2.x被企业广泛使用,在实际的企业项目中需要更加深入的灵活运用,并且Hadoop 2.x是大数据平台处理 的框架的基石,尤其在海量数据的存储HDFS.分布式资源管理和任务调 ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- Oracle OCM提纲
ocm提纲 数据库创建详解 ◆ 通过手动方式创建数据库 环境变量的设置 密码文件的创建过程以及使用情景 Oracle数据库中参数文件的演进过程 参数文件的对比 参数的修改方式介绍 数据库启动过程时的内 ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- HDFS-Architecture剖析
1.概述 从HDFS的应用层面来看,我们可以非常容易的使用其API来操作HDFS,实现目录的创建.删除,文件的上传下载.删除.追加(Hadoop2.x版本以后开始支持)等功能.然而仅仅局限与代码层面是 ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
随机推荐
- httprunner 使用总结
HttpRunner 概念 HttpRunner 是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试.性能测试.线上监控.持续集成等多种测试 ...
- 前端入门CSS(3)
day60 不透明度 opacity()\ opacity (不透明度) 1. 取值0~1 2. 和rgba()的区别: ...
- FunDA(8)- Static Source:保证资源使用安全 - Resource Safety
我们在前面用了许多章节来讨论如何把数据从后台数据库中搬到内存,然后进行逐行操作运算.我们选定的解决方案是把后台数据转换成内存中的数据流.无论在打开数据库表或从数据库读取数据等环节都涉及到对数据库表这项 ...
- 基于Spring Boot的Logback日志轮转配置
在生产环境下,日志是最好的问题调试和跟踪方法,因此日志的地位是十分重要的.我们平时经常使用的log4j,slf4j,logback等等,他们的配置上大同小异.这里就结合Spring Boot配置一下L ...
- poj2488 A Knight's Journey
http://poj.org/problem?id=2488 题目大意:骑士厌倦了一遍又一遍地看到同样的黑白方块,于是决定去旅行. 世界各地.当一个骑士移动时,他走的是“日”字.骑士的世界是他赖以生存 ...
- [JavaScript] 获取昨日前天的日期
var day = new Date(); day.setDate(day.getDate()-1); console(day.pattern('yyyy-MM-dd'));//昨天的日期 day.s ...
- cas单点登陆系统-建立单点登陆系统的应用
上一篇如果已经操作成功,说明casServer已经实现了,下面就是搭建casClient与casServer联合调试.代码已经上传到github上.你可以下载看看,如果自己在搭建的过程中遇到问题,你也 ...
- Swift 里字符串(一)概览
感受一下字符串相关的源文件个数  String 概览 是一个结构体 只有一个变量,类型是 _StringGuts  如上所示,String 真正的内容在__StringStorage或者__Sha ...
- django -orm操作总结
前言 Django框架功能齐全自带数据库操作功能,本文主要介绍Django的ORM框架 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MyS ...
- pythonweb框架Flask学习笔记04-模板继承
# -*- coding:utf-8 -*- from flask import render_template,Flask app=Flask(__name__) @app.route('/hell ...