hadoop2.6 上hive运行 报“native-lzo library not available”异常处理
环境:Hadoop 2.6.0 + hive-0.14.0
问题出现的背景:在hive中建表 (建表语句如下),并且表的字段中有Map,Set,Collection等集合类型。
CREATE EXTERNAL TABLE agnes_app_hour(
start_id string,
current_time string,
app_name string,
app_version string,
app_store string,
send_time string,
letv_uid string,
app_run_id string,
start_from string,
props map<string,string>,
ip string,
server_time string)
PARTITIONED BY (
dt string,
hour string,
product string)
ROW FORMAT DELIMITED
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
STORED AS RCFILE ;
执行hive语句,执行
hive - e "select count(1) from temp_agnes_app_hour ; "
提交map/reduce 到yarn时报出如下异常:
Diagnostic Messages for this Task:
Error: java.io.IOException: java.lang.reflect.InvocationTargetException
at org.apache.hadoop.hive.io.HiveIOExceptionHandlerChain.handleRecordReaderCreationException(HiveIOExceptionHandlerChain.java:97)
at org.apache.hadoop.hive.io.HiveIOExceptionHandlerUtil.handleRecordReaderCreationException(HiveIOExceptionHandlerUtil.java:57)
at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileRecordReader.initNextRecordReader(HadoopShimsSecure.java:312)
at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileRecordReader.<init>(HadoopShimsSecure.java:259)
at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileInputFormatShim.getRecordReader(HadoopShimsSecure.java:386)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getRecordReader(CombineHiveInputFormat.java:652)
at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.<init>(MapTask.java:169)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:429)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileRecordReader.initNextRecordReader(HadoopShimsSecure.java:298)
... 11 more
Caused by: java.lang.RuntimeException: native-lzo library not available
at com.hadoop.compression.lzo.LzoCodec.getDecompressorType(LzoCodec.java:187)
at org.apache.hadoop.hive.ql.io.CodecPool.getDecompressor(CodecPool.java:122)
at org.apache.hadoop.hive.ql.io.RCFile$Reader.init(RCFile.java:1518)
at org.apache.hadoop.hive.ql.io.RCFile$Reader.<init>(RCFile.java:1363)
at org.apache.hadoop.hive.ql.io.RCFile$Reader.<init>(RCFile.java:1343)
at org.apache.hadoop.hive.ql.io.RCFileRecordReader.<init>(RCFileRecordReader.java:100)
at org.apache.hadoop.hive.ql.io.RCFileInputFormat.getRecordReader(RCFileInputFormat.java:57)
at org.apache.hadoop.hive.ql.io.CombineHiveRecordReader.<init>(CombineHiveRecordReader.java:65)
针对"native-lzo library not available" 异常即lzo安装的异常。
===========================================
####安装lzo的过程
1.验证安装环境(以root账户执行):
yum -y install lzo-devel zlib-devel gcc autoconf automake libtool
2.安装LZO (以下以haodop用户执行)
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz
tar -zxvf lzo-2.06.tar.gz
./configure -enable-shared -prefix=/usr/local/hadoop/lzo/
make && make test && make install
3.安装LZOP
wget http://www.lzop.org/download/lzop-1.03.tar.gz
tar -zxvf lzop-1.03.tar.gz
./configure -enable-shared -prefix=/usr/local/hadoop/lzop
make && make install
4.把lzop复制到/usr/bin/
ln -s /usr/local/hadoop/lzop/bin/lzop /usr/bin/lzop
5.测试lzop
lzop /home/hadoop/data/access_20131219.log
会在生成一个lzo后缀的压缩文件: /home/hadoop/data/access_20131219.log.lzo
2,3,4,5 可以使用如下脚本批量执行。
####安装Hadoop-LZO
1. 下载Hadoop-LZO源码,
hadoop-lzo:下载地址
https://github.com/twitter/hadoop-lzo
https://github.com/twitter/hadoop-lzo
git clone https://github.com/twitter/hadoop-lzo
ps: 下载的时,有时候会连接超时,所以多试几次,就可以下载。
2.编译hadoop-lzo的源码
cd hadoop-lzo
mvn clean package
cd ~/twiter-hadoop-lzo/hadoop-lzo/target/
ls
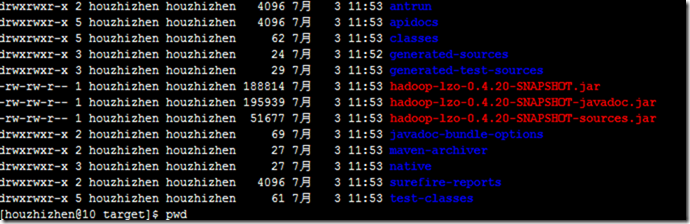
3.上传hadoop-lzo-0.4.20-SNAPSHOT.jar 到hadoop各个节点的安装目录的/usr/local/hadoop/share/hadoop/common/目录下
hadoop-lzo.jar文件:
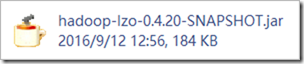
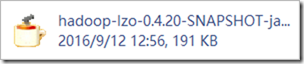

ls /usr/local/hadoop/share/hadoop/common/
4. 修改各个hadoop节点的hadoop的配置文件:
vi hadoop-env.sh :
添加如下配置:
# Extra Java CLASSPATH elements. Optional.
export HADOOP_CLASSPATH="<extra_entries>:$HADOOP_CLASSPATH:${HADOOP_HOME}/share/hadoop/common"
#export JAVA_LIBRARY_PATH=${JAVA_LIBRARY_PATH}:/usr/local/hadoop/lib/native:/opt/glibc-2.14/lib
export JAVA_LIBRARY_PATH=${JAVA_LIBRARY_PATH}:/usr/local/hadoop/lib/native

vi core-site.xml :
添加如下配置:
<property >
<name >io.compression.codec.lzo.class </name>
<value >com.hadoop.compression.lzo.LzoCodec </value>
</property >
<property >
<name >io.compression.codecs </name>
<value> org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec </value>
</property >
vi mapred-site.xml
<property>
<name >mapred.compress.map.output </name>
<value >true </value>
</property>
<property>
<name >mapred.map.output.compression.codec </name>
<value >com.hadoop.compression.lzo.LzoCodec </value>
</property>
<property>
<name >mapreduce.map.env </name>
<value >LD_LIBRARY_PATH=/ usr/local/hadoop /lzo/lib</value>
</property >
<property >
<name >mapreduce.reduce.env </name>
<value >LD_LIBRARY_PATH=/ usr/local/hadoop /lzo/lib</value>
</property >
<property >
<name >mapred.child.env </name>
<value >LD_LIBRARY_PATH=/ usr/local/hadoop /lzo/lib</value>
</property >
5.分发 配置文件到所有的hadoop服务器节点
#分发hadoop-lzo.jar
./upgrade.sh distribute temp/allnodes_hosts /letv/setupHadoop/hadoop-2.6.0/share/hadoop/common/hadoop-lzo-0.4.20-SNAPSHOT.jar /usr/local/hadoop/share/hadoop/common/
#分发修改好的hadoop配置文件
./upgrade.sh distribute cluster_nodes hadoop-2.6.0/etc/hadoop/mapred-site.xml /usr/local/hadoop/etc/hadoop/
./upgrade.sh distribute cluster_nodes hadoop-2.6.0/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/
./upgrade.sh distribute cluster_nodes hadoop-2.6.0/etc/hadoop/hadoop-env.sh /usr/local/hadoop/etc/hadoop/
hadoop2.6 上hive运行 报“native-lzo library not available”异常处理的更多相关文章
- [sql]sqlite3板子上安装运行报错
不管是apt-get install还是deb直接安装都抱如下错误: SQLite header and source version mismatch -- ***** -- *****
- react native-调用react-native-fs插件时,如果数据的接口是需要验证信息的,在android上运行报错
调用react-native-fs插件时,如果数据的接口是需要验证信息的,在android上运行报错,而在iOS上运行没问题.原因是因为接口是有验证信息的,而调用这个插件时没有传入,在iOS上会自动加 ...
- 执行Spark运行在yarn上的命令报错 spark-shell --master yarn-client
1.执行Spark运行在yarn上的命令报错 spark-shell --master yarn-client,错误如下所示: // :: ERROR SparkContext: Error init ...
- 部署网站: 配置项目到iis上运行报目录错误
配置项目到iis上运行报目录错误 以下三种方法可使用: 1.添加文件访问权限 everyone (线上环境慎用) 2.重新注册iis 3.web.config 加一段话 在<system.we ...
- 前段时间,接手一个项目使用的是原始的jdbc作为数据库的访问,发布到服务器上在运行了一段时间之后总是会出现无法访问的情况,登录到服务器,查看tomcat日志发现总是报如下的错误。 Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Data source rejected est
前段时间,接手一个项目使用的是原始的jdbc作为数据库的访问,发布到服务器上在运行了一段时间之后总是会出现无法访问的情况,登录到服务器,查看tomcat日志发现总是报如下的错误. Caused by: ...
- Mac上PyCharm运行多进程报错的解决方案
Mac上PyCharm运行多进程报错的解决方案 运行时报错 may have been in progress in another thread when fork() was called. We ...
- MyEclipse上有main函数类运行报错:Editor does not contain a main type
MyEclipse下有main函数类运行报错:Editor does not contain a main type 出现这种问题的原因是,该java文件所在的包没有被MyEclipse认定为源码包. ...
- MyEclipse上有main函数类运行报错:Editor does not contain a
MyEclipse下有main函数类运行报错:Editor does not contain a main type?出现这种问题的原因是,该java文件 MyEclipse下有main函数类运行 ...
- Mac上Hive安装配置
Mac上Hive安装配置 1.安装 下载hive,地址:http://mirror.bit.edu.cn/apache/hive/ 之前我配置了集群,tjt01.tjt02.tjt03,这里hive安 ...
随机推荐
- Inside Triangle
Inside Triangle https://hihocoder.com/contest/hiho225/problem/1 时间限制:10000ms 单点时限:1000ms 内存限制:256MB ...
- 240. Search a 2D Matrix II&&74. Search a 2D Matrix 都用不严格递增的方法
一句话思路:从左下角开始找.复杂度是o(m+n). 一刷报错: 应该是一个while循环中有几个条件判断语句,而不是每个条件判断语句里去加while,很麻烦 数组越界了.从0开始,y的最大条件应该是& ...
- 【原创】Junit4详解二:Junit4 Runner以及test case执行顺序和源代码理解
概要: 前一篇文章我们总体介绍了Junit4的用法以及一些简单的测试.之前我有个疑惑,Junit4怎么把一个test case跑起来的,在test case之前和之后我们能做些什么? Junit4执行 ...
- php Pthread 多线程 (一) 基本介绍
我们可以通过安装Pthread扩展来让PHP支持多线程. 线程,有时称为轻量级进程,是程序执行的最小单元.线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,它与同属 ...
- tp中url地址大小写问题
在tp配置文件中有一个URL_CASE_INSENSITIVE选项,设置为true,表示大小写不敏感. 'URL_CASE_INSENSITIVE' => true
- 767A Snacktower
A. Snacktower time limit per test 2 seconds memory limit per test 256 megabytes input standard input ...
- 12月6日 被引入的jsp 页面,引入 js 要注意结束符 要用 </script> 而不是 />
12月6日 被引入的jsp 页面,引入 js 要注意结束符 要用 </script> 而不是 />
- 2018.06.30 cdq分治
#cdq分治 ##一种奇妙的分治方法 优点:可以顶替复杂的高级数据结构:常数比较小. 缺点:必须离线操作. CDQ分治的基本思想十分简单.如下: 我们要解决一系列问题,包含修改和查询操作,我们将这些问 ...
- 2018.07.30 bzoj4355: Play with sequence(线段树)
传送门 维护区间覆盖成非负数,区间变成max(xi+a,0)" role="presentation" style="position: relative;&q ...
- hdu-1050(贪心+模拟)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1050 思路:由图可知,1对应2,3对应4,以此类推,如果x,y是偶数则变为奇数: 每次输入两个区间,找 ...