使用TensorFlow高级别的API进行编程
这里涉及到的高级别API主要是使用Estimator类来编写机器学习的程序,此外你还需要用到一些数据导入的知识。
为什么使用Estimator
Estimator类是定义在tf.estimator.Estimator中的,你可以使用其中已经有的Estimator,叫做预创建的Estimator,也可以自定义Estimator。Estimator已经封装了训练(train),评估(evaluate),预测(predict),导出以供使用等方法。
此外,Estimator会为我们提供诸如图构建、创建session等管道工作,不用我们再做这些重复的工作。它还提供了安全的分布式训练循环。相比于低级的API,我们可以把大部分的时间和精力放在处理数据、训练模型、调整参数上面,而不是创建张量、构建图、使用session运行张量上面。
使用Estimator的步骤
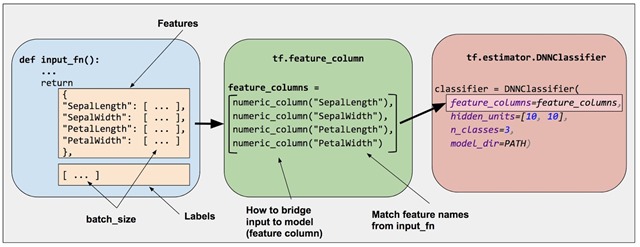
1:需要编写一个数据输入的函数input_fn
input_fn是输入函数,这个函数的作用在于对数据进行预处理,并且在模型train,predict,evaluate的时候给模型送进去数据。所以input_fn主要作用的时机在模型训练、预测和评估的时候,在模型定义的时候不需要传入输入函数,而是传入一个预定义的特征列。可以使用系统自带的函数,可以编写自定义的输入函数。
使用系统自带的数据输入函数:
系统自带的输入函数为tf.estimator.inputs.numpy_input_fn,它的输入参数如下:
def numpy_input_fn(x,
y=None,
batch_size=128,
num_epochs=1,
shuffle=None,
queue_capacity=1000,
num_threads=1)
x为numpy数组或者numpy数组的字典,当为numpy数组的时候,这个数组被当做单一的特征对待。
一个例子如下,这个例子是tf.estimator Quickstart tutorial中的一段代码:
import numpy as np training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING, target_dtype=np.int, features_dtype=np.float32) train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": np.array(training_set.data)},
y=np.array(training_set.target),
num_epochs=None,
shuffle=True) classifier.train(input_fn=train_input_fn, steps=2000)
自定义导入数据的函数:
要自定义导入函数,要知道tensorflow中关于数据的概念,以及知道自定义的函数应该返回的值,下面我将梳理一下这里面的概念:
自定义函数的基本框架以及返回值
def my_input_fn():
# 在这里进行数据的预处理...
# ...返回两个值 1) 一个由特征列和包含特征的Tensors组成的映射(字典) 2) 一个包含labels的Tensor
return feature_cols, labels
自定义函数需要返回两个值,一个值是feature_cols,是一个字典,其中字典的key为特征的列名称,字典的value为包含特征值的Tensor对象。labels是一个包含标签值的Tensor对象。
tf.data.API对于数据的两个抽象:
使用tf.data.API来构建数据输入的管道,帮助我们导入数据,无论是图像,文本还是分布式的数据,都可以用它来完成。
一个抽象的概念是tf.data.Dataset,一个Dataset是一个数据集,它是由一系列的元素组成的,每个元素的类型都是相同的。其中每个元素包含一个或者多个Tensor对象。我们可以以两种方式来创建Dataset对象,一种方式是创建它的来源,比如使用Dataset.from_tensor_slices(),可以使用张量来创建Dataset对象,另外一种方式是运用转换的方式,可以将一个Dataset来变成另外一个Dataset,比如Dataset.batch()。
另外一个抽象的概念是tf.data.Iterator,它代表的是迭代器。表示的是如何从数据集里面取出元素,最简答的迭代器是单次迭代器,Dataset.make_one_shot_iterator()可以创建单次迭代器。创建迭代器以后,可以使用Iterator.get_next()来获取下一个元素。
其它的创建数据集的方法:
Dataset.from_tensor()创建一个Dataset,并将传入的Tensor当做一个元素。 Dataset.from_tensor_slices()会创建一个Dataset,并且将传入的Tensor在第0维上面切面,分成一些列的元素。还可以使用TFRecordDataset来获得磁盘上面TFRecord格式的数据。
其它的创建迭代器的方法:
除了dataset.make_one_shot_iterator()这种单次迭代器以外,你还可以创建可初始化、可重新初始化、可馈送迭代器。
导入数据集的基本的工作机制:
1:创建Dataset对象 –> 2:将Dataset进行转化 –> 3:创建迭代器 –> 4:用迭代器返回下一个元素。
下面用一个例子来说明一下:
from tensorflow.python.data import Dataset
import numpy as np
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
"""自定义的输入函数 Args:
features: 使用pandas中的DataFrame对象来表示的features
targets: 使用pandas的taFrame对象表示的targets
batch_size: 批次的大小
shuffle: 是否将数据进行重新打乱
num_epochs: 需要重复的epochs的数量,一个epochs代表一个训练周期. None = repeat indefinitely
Returns:
下一批次数据的元组 (features, labels)
""" # 将pandas对象转换为字典,其中字典的值为numpy的数组
features = {key:np.array(value) for key,value in dict(features).items()} # 创建一个Dataset,并且设置好批次和重复的次数
ds = Dataset.from_tensor_slices((features,targets)) # warning: 2GB limit
ds = ds.batch(batch_size).repeat(num_epochs) # 是否进行数据扰动
if shuffle:
ds = ds.shuffle(10000) # 返回下个批次的数据
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels
上面自定义了数据导入的函数,使用Dataset.from_tensor_slices()来创建Dataset。然后使用batch、repeat、shuffle进行转换。 接着创建迭代器,并且获得下一个元素。
2:定义特征列
使用tf.feature_column来标识特征名称、类型和任何输入预处理。
特征列在原始数据和模型之间起到了连接的作用。在编写模型的时候需要预先确定输入数据的特征列。
比如包含经度和维度两个特征的特征列,它们都是数值类型,这个特征列在模型定义的时候需要传入:
import tensorflow as tf
longitude = tf.feature_column.numeric_column('longitude')
latitude = tf.feature_column.numeric_column('latitude')
feature_column = [longitude, latitude]
特征列在原始数据与模型所需的数据之间架起了桥梁。
3:实例化相关的预创建的Estimator
这个步骤就简单了,以深度学习模型为例,运用上面创建的经纬度特征列,使用10*10的隐层创建一个深度神经网络的回归模型:
hidden_units = [10, 10]
dnn_regressor = tf.estimator.DNNRegressor(
feature_columns=feature_columns,
hidden_units=hidden_units,
)
4:调用训练、评估或推理方法
使用上述创建的模型进行train、evaluate、predict操作。首先需要定理训练的输入函数,将训练集的特征和标签都传进去,然后开始训练,例子如下:
training_input_fn = lambda:my_input_fn(train_df, train_target_df)
dnn_regressor.train(
input_fn=training_input_fn,
steps=300
)
参考:
Estimator 高级的API,介绍了创建estimator的流程
导入数据 介绍了数据集,还有迭代器的知识
Building Input Functions with tf.estimator 讲解了如何定义输入函数
特征列 详细介绍了特征列,里面有9中特征列可以学习
google机器学习速成课程的神经网络简介 ,完整的机器学习过程
使用TensorFlow高级别的API进行编程的更多相关文章
- 使用TensorFlow低级别的API进行编程
Tensorflow的低级API要使用张量(Tensor).图(Graph).会话(Session)等来进行编程.虽然从一定程度上来看使用低级的API非常的繁重,但是它能够帮助我们更好的理解Tenso ...
- 谷歌开源的TensorFlow Object Detection API视频物体识别系统实现教程
视频中的物体识别 摘要 物体识别(Object Recognition)在计算机视觉领域里指的是在一张图像或一组视频序列中找到给定的物体.本文主要是利用谷歌开源TensorFlow Object De ...
- [Tensorflow] Object Detection API - predict through your exclusive model
开始预测 一.训练结果 From: Testing Custom Object Detector - TensorFlow Object Detection API Tutorial p.6 训练结果 ...
- 使用Tensorflow object detection API——环境搭建与测试
[软件环境搭建] 操作系统:windows 10 64位 内存:8G CPU:I7-6700 Tensorflow: 1.4 Python:3.5 Anaconda3 (64-bit) 以上环境搭建请 ...
- 【翻译】Keras.NET简介 - 高级神经网络API in C#
Keras.NET是一个高级神经网络API,它使用C#编写,并带有Python绑定,可以在Tensorflow.CNTK或Theano上运行.其关注点是实现快速实验.因为做好研究的关键是:能在尽可能短 ...
- Tensorflow object detection API(1)---环境搭建与测试
参考: https://blog.csdn.net/dy_guox/article/details/79081499 https://blog.csdn.net/u010103202/article/ ...
- 使用TensorFlow Object Detection API+Google ML Engine训练自己的手掌识别器
上次使用Google ML Engine跑了一下TensorFlow Object Detection API中的Quick Start(http://www.cnblogs.com/take-fet ...
- TensorFlow object detection API
cloud执行:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_pet ...
- Tensorflow object detection API 搭建属于自己的物体识别模型
一.下载Tensorflow object detection API工程源码 网址:https://github.com/tensorflow/models,可通过Git下载,打开Git Bash, ...
随机推荐
- 使用Python扫描网络MAC地址对应的IP地址
#!/usr/bin/env python # -*- coding: utf-8 -*- from scapy.all import srp,Ether,ARP,conf ipscan='192.1 ...
- HTTP之二 http 301 和 302的区别
1.什么是301转向?什么是301重定向? 301转向(或叫301重定向,301跳转)是当用户或搜索引擎向网站服务器发出浏览请求时,服务器返回的HTTP数据流中头信息(header)中的状态码的一种, ...
- 十三、springboot集成定时任务(Scheduling Tasks)
定时任务(Scheduling Tasks) 在springboot创建定时任务比较简单,只需2步: 1.在程序的入口加上@EnableScheduling注解. 2.在定时方法上加@Schedule ...
- CCScale9Sprite 的 setContentSize setPreferredSize 区别
CCScale9Sprite 设置图片大小方式: updateButtonSpriteMark->setContentSize(size);//设置图片的原始大小设置节点的未转换大小.无论节点被 ...
- 用sklearn计算卡方检验P值
情形: 1. 对于一批分类变量,我们通常要评价两两之间的相关程度. 2. 因变量是分类变量,衡量其他分类变量和因变量的相关性高低. 来源:https://blog.csdn.net/snowdropt ...
- Python 正则表达式提高
re模块的高级用法 search re.search(pattern, string[, flags]) 若string中包含pattern子串,则返回Match对象,否则返回None,注意,如果 ...
- 安装window系统
安装服务器系统,进入windowpe后将iso中sources,bootmgr,和boot拷贝到C盘,执行bootsect.exe /nt60 c:,调试froad13的consle win8 改 ...
- arp命令 清arp表
平常删除arp都用arp-d.大量存在的时候 arp -n|awk '/^[1-9]/ {print arp -d $1}' | sh 清除所有arp表,以前用这个来清arp表貌会清空,没注意到存在i ...
- jersey中的405错误 method not allowed
- JAVA复习笔记之GC部分
前言:垃圾回收机制,大家都知道JAVA的垃圾回收都是JVM自动回收的,不需要程序员去管理.但是我们还是得知道原理才能在适当时机进行JVM调优 原理:当我们new 一个对象时JVM堆区就会分配一块 ...