对HashMap的理解(二):高并发下的HashMap
在分析hashmap高并发场景之前,我们要先搞清楚ReHash这个概念。ReHash是HashMap在扩容时的一个步骤。
HashMap的容量是有限的。当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高。这时候,HashMap需要扩展它的长度,也就是进行Resize。
影响发生Resize的因素有两个:
1.Capacity:HashMap的当前长度。上一篇曾经说过,HashMap的长度是2的幂。
2.LoadFactor:HashMap负载因子,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:
HashMap.Size >= Capacity * LoadFactor
Resize的两个步骤:
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
让我们回顾一下Hash公式:
index = HashCode(Key) & (Length - 1)
当原数组长度为8时,Hash运算是和111B做与运算;新数组长度为16,Hash运算是和1111B做与运算。Hash结果显然不同。
Resize前的HashMap:

Resize后的HashMap:
ReHash的Java代码如下:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
上述流程在单线程下执行是没有问题的,但在多线程下,HashMap并非线程安全的。下面在演示在多线程环境下,HashMap的ReHash操作可能带来什么样的问题之前,先说明在单线程下的执行情况。
在说明之前,先将ReHash的代码分为如下三部分:

(一)、单线程的情况下:
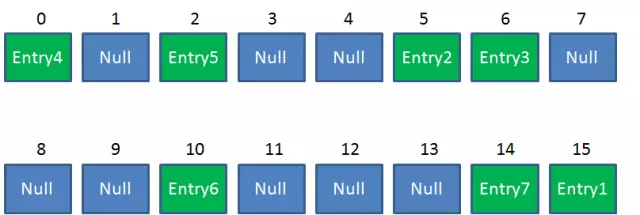
假设一个HashMap已经到了Resize的临界点:
1. 扩容

2. ReHash
首先遍历Entry4对象:e = Entry4
第8行:next = e.next; => next = null; //此时:e = Entry4, next = null
第12行:假设i = 1;
第13-15行:e.next = newTable[1]; => e.next = null;
newTable[1] = e; => newTable[1] = Entry4;
e = next; => e = null; //此时:e = null, next = null
Entry4放入newTable[1]的位置,结束while循环。开始遍历下一个对象:e = Entry3 第8行:next = e.next; => next = Entry2; //此时:e = Entry3, next = Entry2
第12行:假设i = 3;
第13-15行:e.next = newTable[3]; => e.next = null; //要插入的结点的next指向newTable[i]
newTable[3] = e; => newTable[3] = Entry3; //要插入的结点放在newTable[i]处
e = next; => e = Entry2; //此时:e = Entry2, next = Entry2
Entry3放入newTable[3]的位置,继续while循环,开始遍历下一个对象:e = Entry2 第8行:next = e.next; => next = Entry1; //此时:e = Entry2, next = Entry1
第12行:假设i = 3;
第13-15行:e.next = newTable[3]; => e.next = Entry3;
newTable[3] = e; => newTable[3] = Entry2;
e = next; => e = Entry1; //此时:e = Entry1, next = Entry1
Entry2放入newTable[3]的位置,且Entry2.next = Entry3,继续while循环,开始遍历下一个对象:e = Entry1 .....
(二)、多线程的情况下:
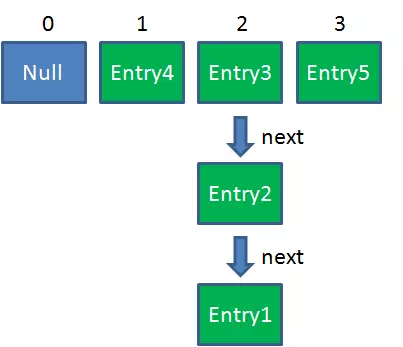
1. 假设一个HashMap已经到了Resize的临界点:
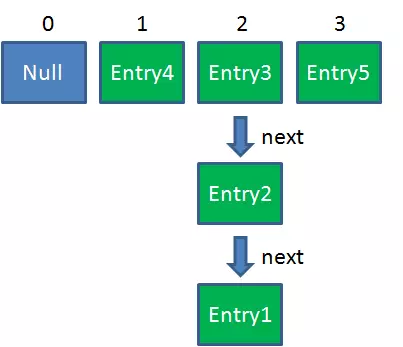
2. 此时有两个线程A和B,在同一时刻对HashMap进行Put操作:
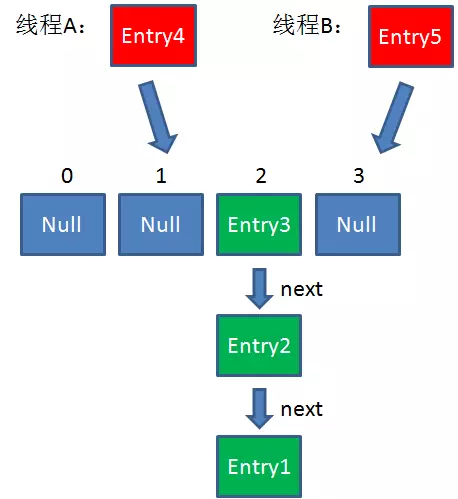
3. 此时达到Resize条件,两个线程各自进行Rezie的第一步,也就是扩容:
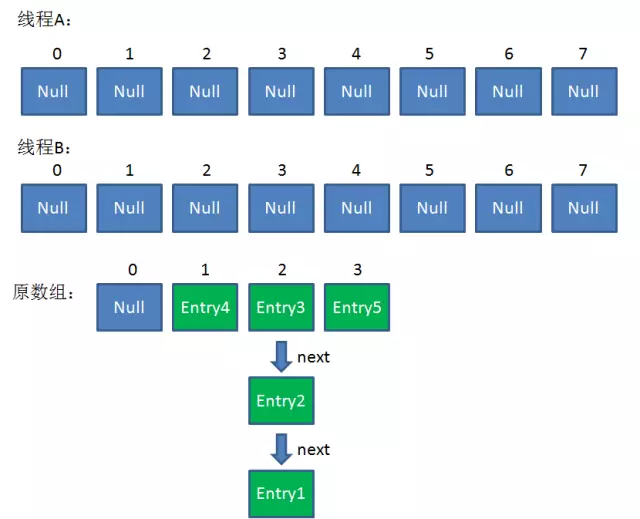
4. 这时候,两个线程都走到了ReHash的步骤。
假如此时线程B遍历到Entry3对象,刚执行完第8行代码,线程就被挂起。对于线程B来说:
e = Entry3
next = Entry2
这时候线程A畅通无阻地进行着Rehash,当ReHash完成后,结果如下(图中的e和next,代表线程B的两个引用):
直到这一步,看起来没什么毛病。
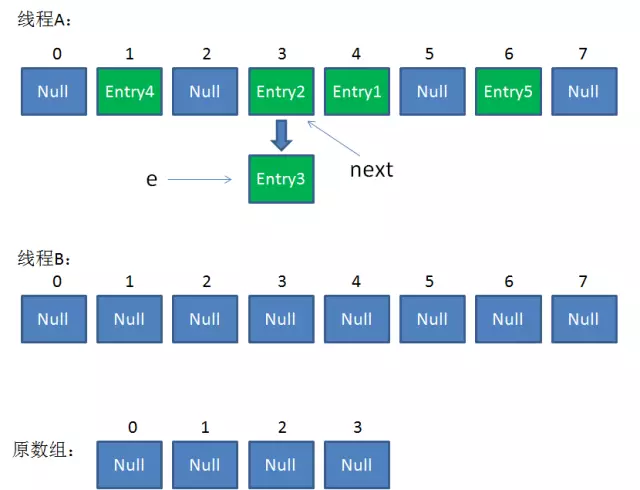
5. 接下来线程B恢复,继续执行属于它自己的ReHash。(e = Entry3, next = Entry2)
//线程B继续执行
第12行:i = 3 //因为刚才线程A对于Entry3的hash结果也是3
第13-15行:e.next = newTable[3]; => e.next = null;
newTable[3] = e; => newTable[3] = Entry3;
e = next; => e = Entry2; //此时:e = Entry2, next = Entry2
Entry3放入线程B中newTable[3]的位置,继续while循环,开始遍历下一个对象:e = Entry2
整体情况如下:(线程A中e和next都指向Entry2,线程B只有Entry3)
6. 继续执行:
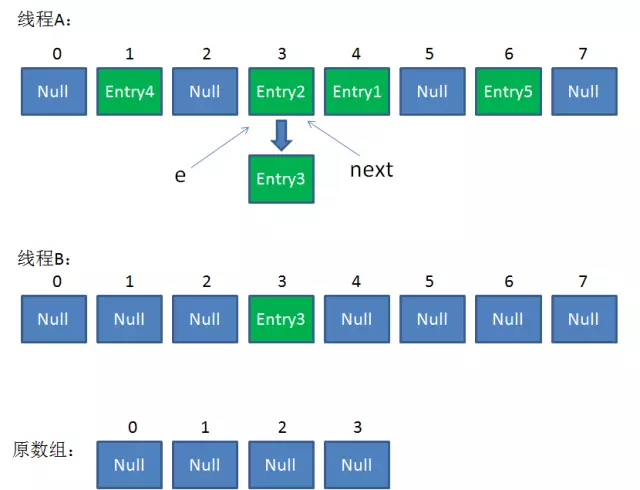
//继续while循环
第8行:next = e.next; => next = Entry3; //此时:e = Entry2, next = Entry3
第12行:i = 3;
第13-15行:e.next = newTable[3]; => e.next = Entry3;
newTable[3] = e; => newTable[3] = Entry2;
e = next; => e = Entry3; //此时:e = Entry3, next = Entry3
Entry2放入newTable[3]的位置,且Entry2.next = Entry3,继续while循环,开始遍历下一个对象:e = Entry3
整体情况如下:(线程A中e和next都指向Entry3,线程B有Entry2和Entry3)
7. 继续执行:
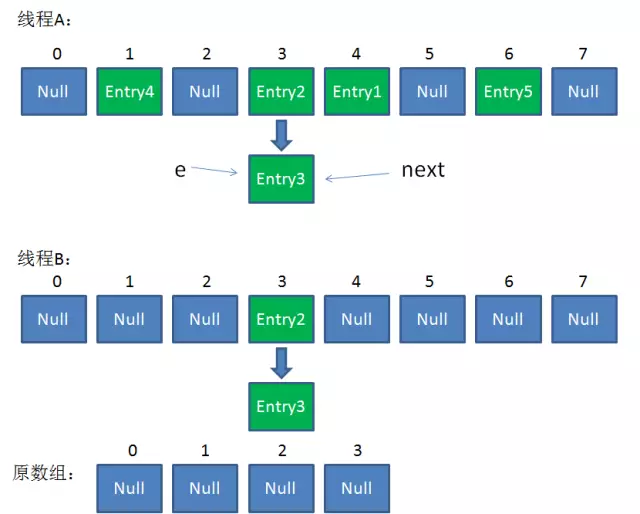
//继续while循环
第8行:next = e.next; => next = null; //此时:e = Entry3, next = null
第9行:i = 3;
第13-15行:e.next = newTable[i]; => e.next = Entry2;
newTable[3] = e; => newTable[3] = Entry3;
e = next; => e = null; //此时:e = null, next = null
Entry3放入newTable[3]的位置,且Entry3.next = Entry2,结束while循环。
整体情况如下:(链表出现了环形)

此时,问题还没有直接产生。当调用Get查找一个不存在的Key,而这个Key的Hash结果恰好等于3的时候,由于位置3带有环形链表,所以程序将会进入死循环!
总结:
1.Hashmap在插入元素过多的时候需要进行Resize,Resize的条件是
HashMap.Size >= Capacity * LoadFactor。
2.Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。
来自公众号:

对HashMap的理解(二):高并发下的HashMap的更多相关文章
- JDK1.7 ConcurrentHashMap--解决高并发下的HashMap使用问题
高并发下也可以使用HashTable .Collections.synchronizedMap因为他们是线程安全的,但是却牺牲了性能,无论是读操作.写操作都是给整个集合加锁,导致同一时间内其他操作均为 ...
- JDK1.7 高并发下的HashMap
HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高. 这时候,HashMap需要扩展它的长度,也就是进行Resize. 影响发 ...
- 漫画:高并发下的HashMap
这一期我们来讲解高并发环境下,HashMap可能出现的致命问题. HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高. 这时候 ...
- 高并发下,HashMap会产生哪些问题?
HashMap在高并发环境下会产生的问题 HashMap其实并不是线程安全的,在高并发的情况下,会产生并发引起的问题: 比如: HashMap死循环,造成CPU100%负载 触发fail-fast 下 ...
- 高并发下的HashMap,ConcurrentHashMap
参照: http://mp.weixin.qq.com/s/dzNq50zBQ4iDrOAhM4a70A http://mp.weixin.qq.com/s/1yWSfdz0j-PprGkDgOomh ...
- 高并发下的Java数据结构(List、Set、Map、Queue)
由于并行程序与串行程序的不同特点,适用于串行程序的一些数据结构可能无法直接在并发环境下正常工作,这是因为这些数据结构不是线程安全的.本节将着重介绍一些可以用于多线程环境的数据结构,如并发List.并发 ...
- HashMap 在高并发下引起的死循环
HashMap 基本实现(JDK 8 之前) HashMap 通常会用一个指针数组(假设为 table[])来做分散所有的 key,当一个 key 被加入时,会通过 Hash 算法通过 key 算出这 ...
- HashMap高并发下存在的问题
原文链接:https://blog.csdn.net/bjwfm2011/article/details/81076736 1.什么是HashMap? HashMap底层原理 HashMap是存储键值 ...
- Java高并发下多线程编程
1.创建线程 Java中创建线程主要有三种方式: 继承Thread类创建线程类: 定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务.因此也把run方法称为 ...
随机推荐
- JMeter转制LoadRunner HTTP协议脚本的小技巧
对于Http协议的请求,除了手工编写脚本外,JMeter还提供了录制浏览器操作的功能,甚是方便.那如果手头有一堆HTTP协议的LoadRunner脚本,能不能比较快速的转制成JMeter脚本呢?其实也 ...
- EventBus的基本使用步骤
为什么要使用EventBus 当我们进行项目开发的时候,往往是需要应用程序的各组件间进行通信,比如在子线程中进行请求数据,当数据请求完毕后通过Handler或者是广播通知UI, 通常两个Activit ...
- [Processing]点到线段的最小距离
PVector p1,p2,n; float d = 0; void setup() { size(600,600); p1 = new PVector(150,30);//线段第一个端点 p2 = ...
- Overlay 网络
- c++ 整数和字符串的转化
一.string转int的方式 采用最原始的string, 然后按照十进制的特点进行算术运算得到int,但是这种方式太麻烦,这里不介绍了. 采用标准库中atoi函数. "; int a = ...
- Bootstrap学习--栅格系统
响应式布局页面:即同一套页面可以兼容不同分辨率的设备. Bootstrap依赖于栅格系统实现响应式布局,将一行均分为12个格子,可以指定元素占几个格子. 实现过程 1.定义容器,相当于之前的table ...
- join命令详解
基础命令学习目录首页 原文链接:https://www.cnblogs.com/agilework/archive/2012/04/18/2454877.html 功能说明:将两个文件中,指定栏位内容 ...
- HDFS handler
http://docs.oracle.com/goldengate/bd1221/gg-bd/GADBD/GUID-85A82B2E-CD51-463A-8674-3D686C3C0EC0.htm#G ...
- Scrum立会报告+燃尽图(Final阶段第四次)
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2481 项目地址:https://coding.net/u/wuyy694 ...
- LeetCode 174. Dungeon Game (C++)
题目: The demons had captured the princess (P) and imprisoned her in the bottom-right corner of a dung ...