python3+selenium3+requests爬取我的博客粉丝的名称
爬取目标
1.本次代码是在python3上运行通过的
- selenium3 +firefox59.0.1(最新)
- BeautifulSoup
- requests
2.爬取目标网站,我的博客:https://home.cnblogs.com/u/lxs1314
爬取内容:爬我的博客的所有粉丝的名称,并保存到txt
3.由于博客园的登录是需要人机验证的,所以是无法直接用账号密码登录,需借助selenium登录
直接贴代码:
# coding:utf-8
# __author__ = 'Carry' import requests
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import time # firefox浏览器配置文件地址
profile_directory = r'C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\pxp74n2x.default' s = requests.session() # 新建session
url = "https://home.cnblogs.com/u/lxs1314" def get_cookies(url):
'''启动selenium获取登录的cookies'''
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)
driver.get(url+"/followers") time.sleep(3)
cookies = driver.get_cookies() # 获取浏览器cookies
print(cookies)
driver.quit()
return cookies def add_cookies(cookies):
'''往session添加cookies'''
# 添加cookies到CookieJar
c = requests.cookies.RequestsCookieJar()
for i in cookies:
c.set(i["name"], i['value']) s.cookies.update(c) # 更新session里cookies def get_ye_nub(url):
# 发请求
r1 = s.get(url+"/relation/followers")
soup = BeautifulSoup(r1.content, "html.parser")
# 抓取我的粉丝数
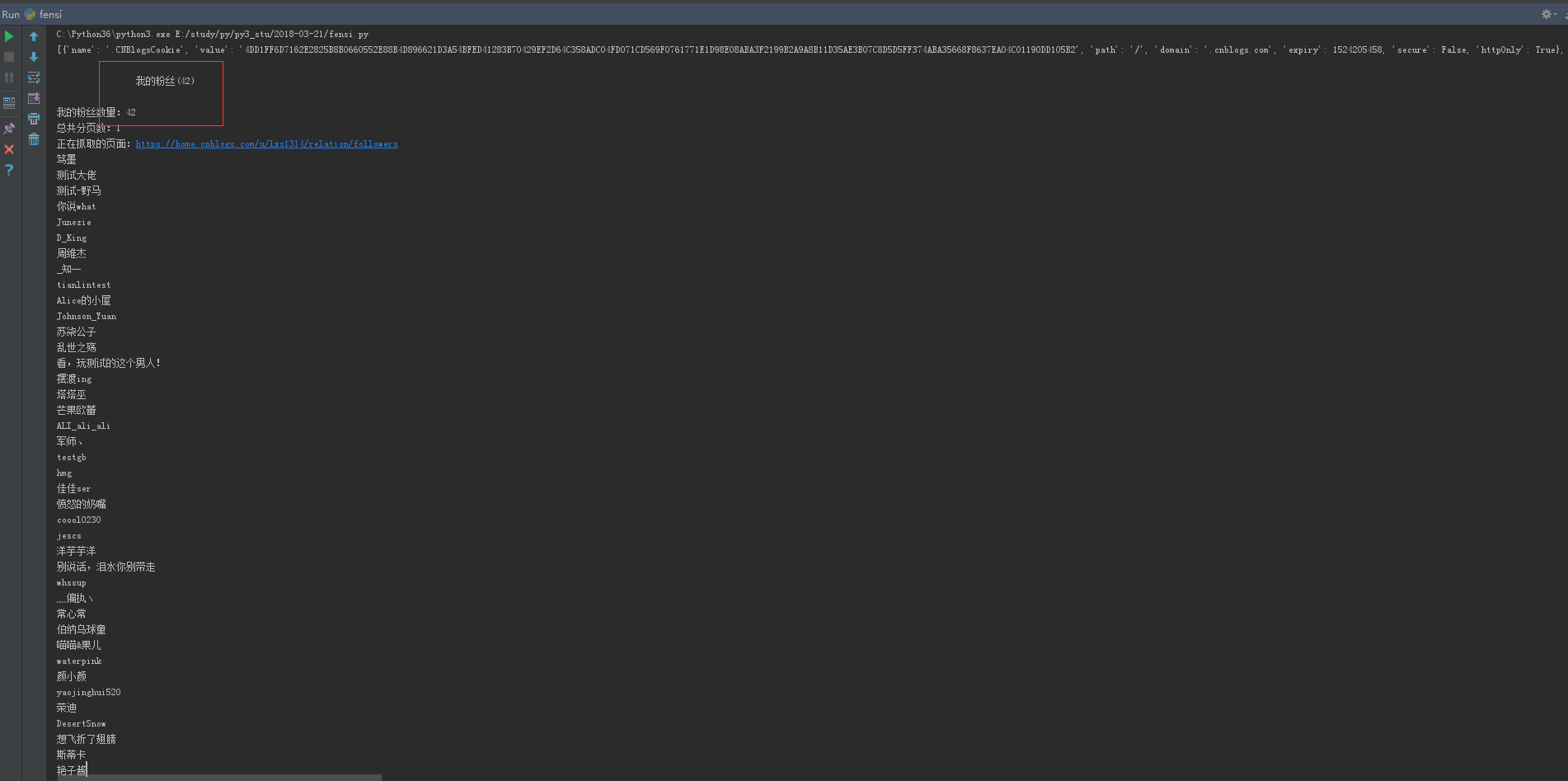
fensinub = soup.find_all(class_="current_nav")
print (fensinub[0].string)
num = re.findall(u"我的粉丝\((.+?)\)", fensinub[0].string)
print (u"我的粉丝数量:%s"%str(num[0])) # 计算有多少页,每页45条
ye = int(int(num[0])/45)+1
print (u"总共分页数:%s"%str(ye))
return ye def save_name(nub):
# 抓取第一页的数据
if nub <= 1:
url_page = url+"/relation/followers"
else:
url_page = url+"/relation/followers?page=%s" % str(nub)
print (u"正在抓取的页面:%s" %url_page)
r2 = s.get(url_page)
soup = BeautifulSoup(r2.content, "html.parser")
fensi = soup.find_all(class_="avatar_name")
for i in fensi:
name = i.string.replace("\n", "").replace(" ","")
print (name)
with open("name.txt", "a") as f: # 追加写入
f.write(name+"\n")
#name.encode("utf-8") if __name__ == "__main__":
cookies = get_cookies(url)
add_cookies(cookies)
n = get_ye_nub(url)
for i in range(1, n+1):
save_name(i)
原文链接:http://www.cnblogs.com/yoyoketang/p/8610779.html
python3+selenium3+requests爬取我的博客粉丝的名称的更多相关文章
- python+selenium+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python2上运行通过的,python3的最需改2行代码,用到其它python模块 selenium 2.53.6 +firefox 44 BeautifulSoup re ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- python3使用requests爬取新浪热门微博
微博登录的实现代码来源:https://gist.github.com/mrluanma/3621775 相关环境 使用的python3.4,发现配置好环境后可以直接使用pip easy_instal ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- step2: 爬取廖雪峰博客
#https://zhuanlan.zhihu.com/p/26342933 #https://zhuanlan.zhihu.com/p/26833760 scrapy startproject li ...
- scrapy 爬取自己的博客
定义项目 # -*- coding: utf-8 -*- # items.py import scrapy class LianxiCnblogsItem(scrapy.Item): # define ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
随机推荐
- USACO Section1.2
section1.1主要包括四道题和两个编程知识介绍.下面将对这6个部分内容进行学习. Your Ride Is Here 这道题没什么难度,读懂题目意思就行:把两个字符串按照题目要求转换成数字,然后 ...
- [TJOI2015]概率论[卡特兰数]
题意 \(n\) 个节点二叉树的叶子节点的期望个数. \(n\leq 10^9\) . 分析 实际询问可以转化为 \(n\) 个点的不同形态的二叉树的叶子节点总数. 定义 \(f_n\) 表示 \(n ...
- CSS中的height与line-height的区别
<p class='text'>高与行高的区别</p> 那么我要想让这些字上下居中那么可以用宽度和行高控制 .text{ height:25px; line-height:25 ...
- SQL Server 内存和换页(Paging)
在进程开始执行时,进程首先申请虚拟地址空间VAS(Virtural Address Space),VAS是进程能够访问的地址空间,由于VAS不是真正的物理内存空间,操作系统必须将VAS隐射到物理内存空 ...
- 安装vs2017后,RDLC 报表定义具有无法升级的无效目标命名空间
原先的RDLC报表定义用的命名空间是2008,用vs2017报表设计器重新保存后,会自动升级成2016,导致无法使用. 不想升级控件,太麻烦,所以就手动修改RDLC文件吧. 1.修改http://sc ...
- Linux 技巧
Linux Handbook For RedHat Enterprise Linux System System # clean old kernel packages package-cleanup ...
- java学习(一) 环境搭建、hello world的demo
本程序媛搞前端的,上班偶有空闲,不妨来学习学习,不然怎么包养小白脸,走上人生巅峰? 说实话,每个语言都相通,有了javascript的基础,并且有了两三年跟java打交道的经验,简单学习下java想必 ...
- python OptionParser模块使用
OptionParser是python中用来处理命令行的模块,在我们使用python进行流程化开发中必要的工具 Optparse,它功能强大,而且易于使用,可以方便地生成标准的.符合Unix/Posi ...
- iOS分类Category探索
什么是Category? Category是Objective-C 2.0之后添加的语言特性,Category的主要作用是为已经存在的类添加方法,一般称为分类,文件名格式是"NSObject ...
- php从入门到放弃系列-02.php基础语法
php从入门到放弃系列-02.php基础语法 一.学习语法,从hello world开始 PHP(全称:PHP:Hypertext Preprocessor,即"PHP:超文本预处理器&qu ...