Hadoop基础-Protocol Buffers串行化与反串行化
Hadoop基础-Protocol Buffers串行化与反串行化
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
我们之前学习过很多种序列化文件格式,比如python中的pickle序列化方式(https://www.cnblogs.com/yinzhengjie/p/8531308.html),golang的Gob序列化方式(https://www.cnblogs.com/yinzhengjie/p/7807051.html),hadoop的SequenceFile序列化文件(https://www.cnblogs.com/yinzhengjie/p/9114301.html),Java内置的ObjectOutputStream序列化方式(https://www.cnblogs.com/yinzhengjie/p/8988003.html)等等。
当然,除了语言自己内置的序列化方式外,还有一些手动二进制编码的序列化文件,以及人性化可读格式的序列化文件,比如XMl,JSON,DOM,SAX,STAX,JAXB,JAXP等等,不过这些序列化方式都不是今天的主角,我今天要介绍的是Google公司在2008年就开源的一种序列化方式,即Protocol Buffers序列化。
一.Protocol Buffers 简介
1>.什么是 Protocol Buffers
第一:A description language(一种描述语言);
第二:A complier(它是一个编译器);
第三:A library(它是一种库);
2>.Protocol Buffers 优点
第一:易于使用,高效的二进制编码;
第二:它是由谷歌公司研发的;
第三:简单高效的串行化技术,在2008公开该技术;
3>.支持跨语言
官方支持:Java, C++, and Python等等
非官方支持:C, C#, Erlang, Perl, PHP, Ruby等等
二.Protocol Buffers 代码生成
1>.创建emp.proto自描述文件(非java文件,具体内容如下)
package tutorial;
option java_package = "tutorialspoint.com";
option java_outer_classname = "Emp2";
message Emp {
required int32 id = 1;
required string name = 2;
required int32 age = 3;
required int32 salary = 4;
required string address = 5;
}
2>.将emp.proto(下载地址:链接:https://pan.baidu.com/s/1crYmFwI68kUnzwJgoyOdpw 密码:bh63)和protobuf\src\protoc.exe放在同一个文件夹
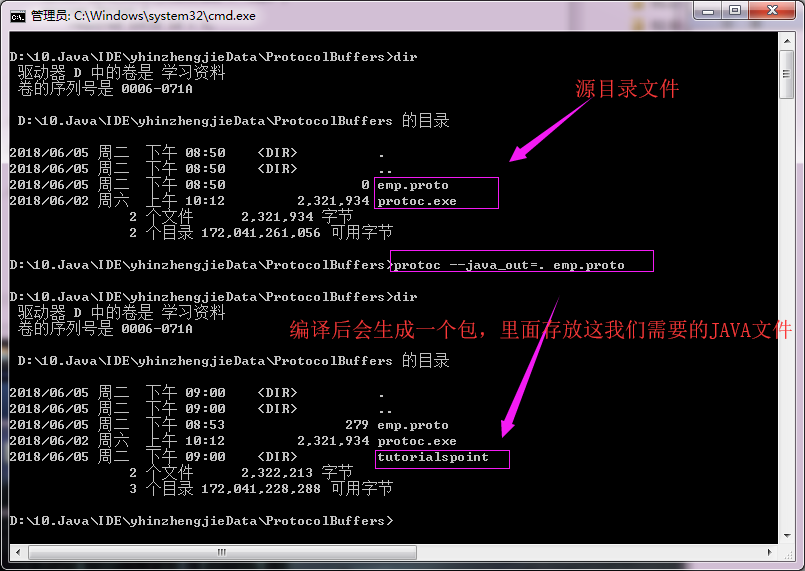
3>.编译emp.proto(protoc --java_out=. emp.proto)
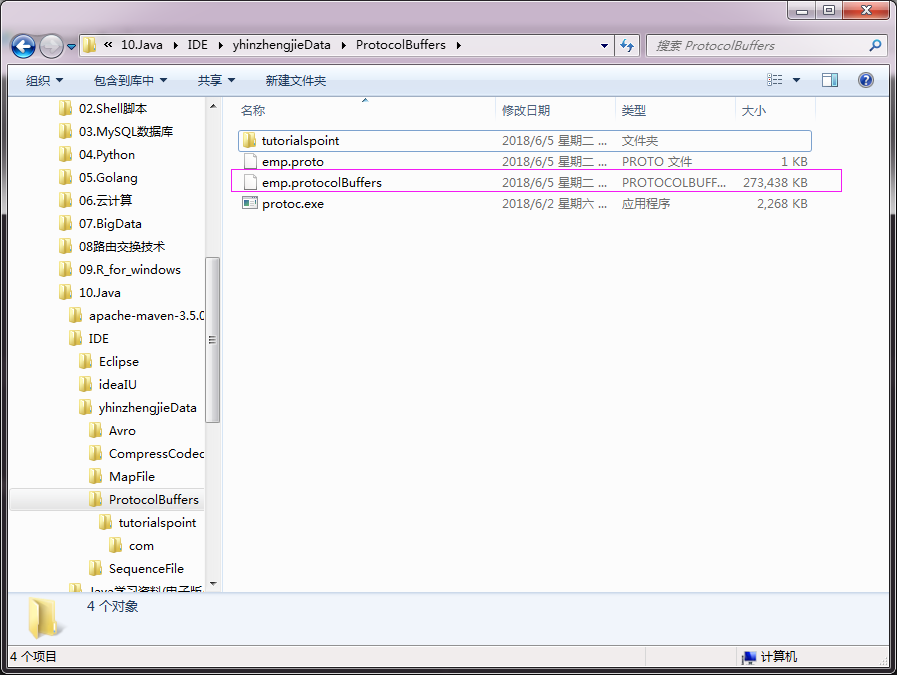
4>.将"D:\10.Java\IDE\yhinzhengjieData\ProtocolBuffers\tutorialspoint\com"(这是我本地目录)下的Emp2.java放置在idea中,包名“tutorialspoint.com”


三.编写代码
1>.编写串行化代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.protocolBuffers; import tutorialspoint.com.Emp2; import java.io.File;
import java.io.FileOutputStream; public class MyProtocolBuffers { private static final File protocolBuffers = new File("D:\\10.Java\\IDE\\yhinzhengjieData\\ProtocolBuffers\\emp.protocolBuffers"); public static void main(String[] args) throws Exception {
protocolBuffersSerial();
}
/**
* 定义序列化方式
*/
public static void protocolBuffersSerial() throws Exception {
long start = System.currentTimeMillis();
FileOutputStream fos = new FileOutputStream(protocolBuffers);
//注意,在序列化一个对象的时候,都是打点的方式设置的哟!在设置完毕后需要以".build"结束!
Emp2.Emp emp = Emp2.Emp.newBuilder().
setId(1).
setName("尹正杰").
setAge(18).
setSalary(66666666).
setAddress("北京").build();
//我们循环写入数据
for (int i = 0; i < 10000000; i++) {
emp.writeTo(fos);
}
fos.close();
System.out.printf("这是protocol Buffers序列化方式: 生成文件大小:[%d],用时:[%d]\n",protocolBuffers.length(),System.currentTimeMillis() - start);
}
} /*
以上代码执行结果如下:
这是protocol Buffers序列化方式: 生成文件大小:[280000000],用时:[10960]
*/
执行以上代码后,在本地目录会生成一个文件如下:
2>.编写反串行化代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.protocolBuffers; import tutorialspoint.com.Emp2; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream; public class MyProtocolBuffers { private static final File protocolBuffers = new File("D:\\BigData\\JavaSE\\yinzhengjieData\\ProtocolBuffers\\emp.protocolBuffers"); public static void main(String[] args) throws Exception {
protocolBuffersSerial();
protocolBuffersDeserial();
}
/**
* 定义序列化方式
*/
public static void protocolBuffersSerial() throws Exception {
long start = System.currentTimeMillis();
FileOutputStream fos = new FileOutputStream(protocolBuffers);
//注意,在序列化一个对象的时候,都是打点的方式设置的哟!在设置完毕后需要以".build"结束!
Emp2.Emp emp = Emp2.Emp.newBuilder().
setId(1).
setName("尹正杰").
setAge(18).
setSalary(66666666).
setAddress("北京").build();
//我们循环写入数据
for (int i = 0; i < 2000000; i++) {
emp.writeTo(fos);
}
fos.close();
System.out.printf("这是protocol Buffers序列化方式: 生成文件大小:[%d],用时:[%d]\n",protocolBuffers.length(),System.currentTimeMillis() - start);
} /**
* 定义反序列化方式
*/
public static void protocolBuffersDeserial() throws Exception {
long start = System.currentTimeMillis();
FileInputStream fis = new FileInputStream(protocolBuffers); Emp2.Emp emp = Emp2.Emp.parseFrom(fis); for (int i = 0; i < 2000000; i++) {
emp.getId();
emp.getName();
emp.getAge();
emp.getSalary();
emp.getAddress();
}
System.out.printf("这是protocol Buffers反序列化方式: 生成文件大小:[%d],用时:[%d]\n",protocolBuffers.length(),System.currentTimeMillis() - start);
} }
Hadoop基础-Protocol Buffers串行化与反串行化的更多相关文章
- Hadoop基础-Apache Avro串行化的与反串行化
Hadoop基础-Apache Avro串行化的与反串行化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Apache Avro简介 1>.Apache Avro的来源 ...
- PHP中的抽象类与抽象方法/静态属性和静态方法/PHP中的单利模式(单态模式)/串行化与反串行化(序列化与反序列化)/约束类型/魔术方法小结
前 言 OOP 学习了好久的PHP,今天来总结一下PHP中的抽象类与抽象方法/静态属性和静态方法/PHP中的单利模式(单态模式)/串行化与反串行化(序列化与反序列化). 1 PHP中的抽象 ...
- C#基础知识回顾--串行化与反串行化
串行化是指存储和获取磁盘文件.内存或其他地方中的对象.在串行化时,所有的实例数据都保存到存储介质上, 在取消串行化时,对象会被还原,且不能与其原实例区别开来.只需给类添加Serializable属性, ...
- C#--串行化与反串行化
串行化是指存储和获取磁盘文件.内存或其他地方中的对象.在串行化时,所有的实例数据都保存到存储介质上,在取消串行化时,对象会被还原,且不能与其原实例区别开来.只需给类添加Serializable属性,就 ...
- Hadoop基于Protocol Buffer的RPC实现代码分析-Server端
http://yanbohappy.sinaapp.com/?p=110 最新版本的Hadoop代码中已经默认了Protocol buffer(以下简称PB,http://code.google.co ...
- Protocol Buffers学习教程
最近看公司代码的过程中,看到了很多proto后缀的文件,这是个啥玩意?问了大佬,原来这是Protocol Buffers! 这玩意是干啥的?查完资料才知道,又是谷歌大佬推的开源组件,这玩意完全可以取代 ...
- Google Protocol Buffers 入门
Google Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化.它很适合做数据存储或 RPC 数据交换格式.可用于通讯协议.数据存储等领域的 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
随机推荐
- 第三周linux学习
实验二 Linux下C语言编程基础 一.实验目的 1. 熟悉Linux系统下的开发环境 2. 熟悉vi的基本操作 3. 熟悉gcc编译器的基本原理 4. 熟练使用gcc编译器的常用选项 5 .熟练使用 ...
- 现代软件工程构建之法 前五章阅读感想&困惑
第一章 第一节 新时代中国的IT产业市场规则不规范,书中提到社会上有个别软件公司的软件一定要卸载别家公司的软件才能运行,我这里感到疑惑---————是不是说如果 一间软件公司他能做出一个像微软操作系统 ...
- 【CS231N】2、多类SVM
一.疑问 1. assignments1 linear_svm.py文件的函数 svm_loss_naive中,使用循环的方式实现梯度计算 linear_svm.py文件的函数 svm_loss_ve ...
- 【搜索】POJ-3050 基础DFS
一.题目 Description The cows play the child's game of hopscotch in a non-traditional way. Instead of a ...
- Error: Unable to access jarfile D:\Apache\apache-jmeter-3.0\bin\ApacheJMete.jar
双击jmeter.bat后,在cmd窗口显示Error: Unable to access jarfile D:\Apache\apache-jmeter-3.0\bin\ApacheJMete.ja ...
- Nfs的简单了解
近期在上传公司课件课程,上传的思路是,在45服务器上建立44服务器的nfs的连接,然后将43服务器上的课件拷贝到建立好的nfs上,再运行课件解析工具,解析整理好的excel即可完成课程的上传.在45服 ...
- [日常工作] 应用服务器上面应该尽量少开各种应用 --Chrome 内存泄露 让应用服务器非常缓慢
1. 前段时间修改 服务器的密码 导致应用程序的web site 启动有问题 ,打开chrome 查看了错误详细信息 但是忘记关了.. 今天反馈机器非常缓慢 简单看了下内存 吐血... 所以以后不能在 ...
- Java并发编程之线程创建和启动(Thread、Runnable、Callable和Future)
这一系列的文章暂不涉及Java多线程开发中的底层原理以及JMM.JVM部分的解析(将另文总结),主要关注实际编码中Java并发编程的核心知识点和应知应会部分. 说在前面,Java并发编程的实质,是线程 ...
- linq 左连接实现两个集合的合并
//第一个集合为所有的数据 var specilist = new List<Me.SpecificationsInfo>(); var resultall = (from a in db ...
- 【转】Latex编译报错后中断编译并改正,然后重复出现不明原因报错的解决方法
转自:https://www.douban.com/note/419828344/ 目录: 一.问题描述 二.测试情况(可以跳过,直接看建议) 三.建议 四.参考资料 正文: 问题描述: 错漏某个符号 ...