Spring事务(二)事务自定义标签
摘要: 本文结合《Spring源码深度解析》来分析Spring 5.0.6版本的源代码。若有描述错误之处,欢迎指正。
目录
一、注册 InfrastructureAdvisorAutoProxyCreator
二、获取对应class/method的增强器
1. 寻找候选增强器
2. 候选增强器中寻找到匹配项
3. 提取事务标签
对于Spring中事务功能的代码分析,我们首先从配置文件开始人手,在配置文件中有这样一个配置:<tx:annotation-driven/>。可以说此处配置是事务的开关,如果没有此处配置,那么Spring中将不存在事务的功能。那么我们就从这个配置开始分析。
根据之前的分析,我们因此可以判断,在自定义标签中的解析过程中一定是做了一些辅助操作,于是我们先从自定义标签入手进行分析。
使用Idea搜索全局代码,关键字annotation-driven,最终锁定类TxNamespaceHandler,在TxNamespaceHandler中的 init 方法中:
@Override
public void init() {
registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());
registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser());
registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser());
}
根据自定义标签的使用规则以及上面的代码,可以知道,在遇到诸如tx:annotation-driven为开头的配置后,Spring都会使用AnnotationDrivenBeanDefinitionParser类的parse方法进行解析。
/**
* Parses the {@code <tx:annotation-driven/>} tag. Will
* {@link AopNamespaceUtils#registerAutoProxyCreatorIfNecessary register an AutoProxyCreator}
* with the container as necessary.
*/
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
registerTransactionalEventListenerFactory(parserContext);
String mode = element.getAttribute("mode");
if ("aspectj".equals(mode)) {
// mode="aspectj"
registerTransactionAspect(element, parserContext);
if (ClassUtils.isPresent("javax.transaction.Transactional", getClass().getClassLoader())) {
registerJtaTransactionAspect(element, parserContext);
}
}
else {
// mode="proxy"
AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);
}
return null;
}
在解析中存在对于mode属性的判断,根据代码,如果我们需要使用AspectJ的方式进行事务切入(Spring中的事务是以AOP为基础的),那么可以使用这样的配置:
<tx:annotation-driven transaction-manager="transactionManager" mode="aspectj"/>
一、注册 InfrastructureAdvisorAutoProxyCreator
我们以默认配置为例进行分析,进人AopAutoProxyConfigurer类的configureAutoProxyCreator:
public static void configureAutoProxyCreator(Element element, ParserContext parserContext) {
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
String txAdvisorBeanName = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME;
if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {
Object eleSource = parserContext.extractSource(element);
// Create the TransactionAttributeSource definition.
//创建TransactionAttributeSource的bean
RootBeanDefinition sourceDef = new RootBeanDefinition(
"org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");
sourceDef.setSource(eleSource);
sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
// 注册bean,并使用Spring中的定义规则生成beanName
String sourceName = parserContext.getReaderContext().registerWithGeneratedName(sourceDef);
// Create the TransactionInterceptor definition.
// 创建TransactionInterceptor的bean
RootBeanDefinition interceptorDef = new RootBeanDefinition(TransactionInterceptor.class);
interceptorDef.setSource(eleSource);
interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registerTransactionManager(element, interceptorDef);
interceptorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
// 注册bean,并使用Spring中的定义规则生成beanName
String interceptorName = parserContext.getReaderContext().registerWithGeneratedName(interceptorDef);
// Create the TransactionAttributeSourceAdvisor definition.
// 创建TransactionAttributeSourceAdvisor的bean
RootBeanDefinition advisorDef = new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);
advisorDef.setSource(eleSource);
advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
// 将interceptorName的bean注入advisorDef的adviceBeanName属性中
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
// 如果配置了order属性,则加入到bean中
if (element.hasAttribute("order")) {
advisorDef.getPropertyValues().add("order", element.getAttribute("order"));
}
parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);
// 创建CompositeComponentDefinition
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), eleSource);
compositeDef.addNestedComponent(new BeanComponentDefinition(sourceDef, sourceName));
compositeDef.addNestedComponent(new BeanComponentDefinition(interceptorDef, interceptorName));
compositeDef.addNestedComponent(new BeanComponentDefinition(advisorDef, txAdvisorBeanName));
parserContext.registerComponent(compositeDef);
}
}
上面的代码注册了代理类及三个bean,很多读者会直接略过,认为只是注册三个bean而已,确实,这里只注册了三个bean,但是这三个bean支撑了整个的事务功能,那么这三个bean是怎么组织起来的呢?
首先,其中的两个bean被注册到了一个名为advisorDef的bean中,advisorDef使用BeanFactoryTransactionAttributeSourceAdvisor作为其class属性。也就是说BeanFactoryTransactionAttributeSourceAdvisor代表着当前bean,如下图所示,具体代码如下:
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
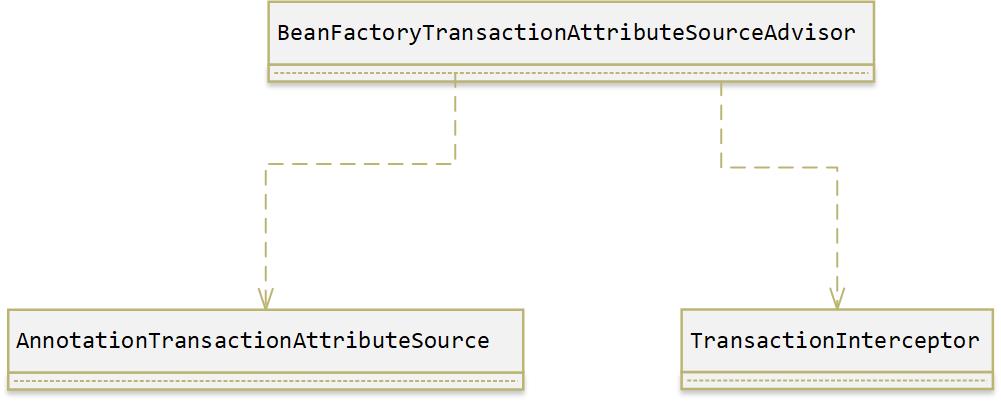
那么如此组装的目的是什么呢?我们暂且留下一个悬念,接着分析代码。上面函数configureAutoProxyCreator中的第一句貌似很简单却是很重要的代码:
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
进入这个函数:
public static void registerAutoProxyCreatorIfNecessary(
ParserContext parserContext, Element sourceElement) { BeanDefinition beanDefinition = AopConfigUtils.registerAutoProxyCreatorIfNecessary(
parserContext.getRegistry(), parserContext.extractSource(sourceElement));
useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement);
registerComponentIfNecessary(beanDefinition, parserContext);
} @Nullable
public static BeanDefinition registerAutoProxyCreatorIfNecessary(BeanDefinitionRegistry registry,
@Nullable Object source) { return registerOrEscalateApcAsRequired(InfrastructureAdvisorAutoProxyCreator.class, registry, source);
}
对于解析来的代码流程AOP中已经有所分析,上面的两个函数主要目的是注册了InfrastructureAdvisorAutoProxyCreator类型的bean,那么注册这个类的目的是什么呢?查看这个类的层次,如下图所示:
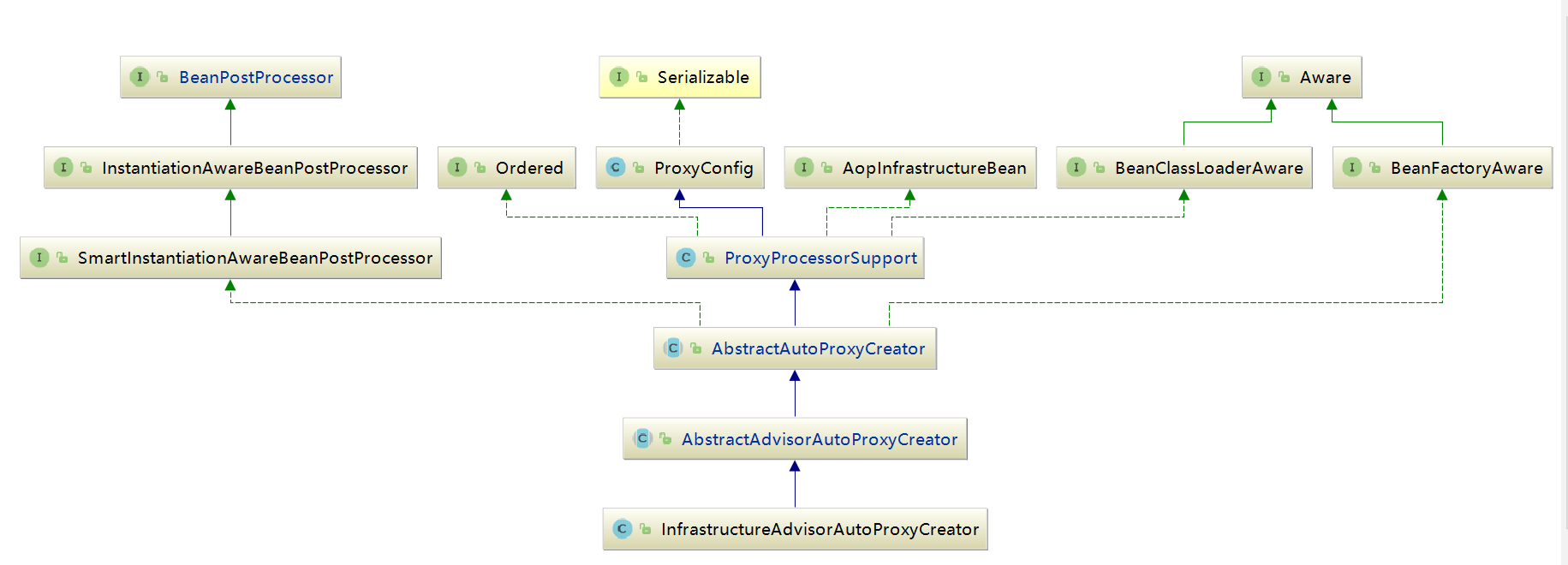
从上面的层次结构中可以看到,InfrastructureAdvisorAutoProxyCreator间接实现了SmartInstantiationAwareBeanPostProcessor,而SmartInstantiationAwareBeanPostProcessor又继承自InstantiationAwareBeanPostProcessor,也就是说在Spring中,所有bean实例化时Spring都会保证调用其postProcessAfterInstantiation方法,其实现是在父类AbstractAutoProxyCreator类中实现。
以之前的示例为例,当实例化userService的bean时便会调用此方法,方法如下:
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
// 根据给定的bean的class和name构建出key,格式:beanClassName_beanName
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (!this.earlyProxyReferences.contains(cacheKey)) {
// 如果它适合被代理,则需要封装指定bean
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
这里实现的主要目的是对指定bean进行封装,当然首先要确定是否需要封装,检测与封装的工作都委托给了wrapIfNecessary函数进行。
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 如果已经处理过
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
// 无需增强
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
// 给定的bean类是否代表一个基础设施类,基础设施类不应代理,或者配置了指定bean不需要自动代理
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
// 如果存在增强方法则创建代理
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
// 如果获取到了增强则需要针对增强创建代理
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 创建代理
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
wrapIfNecessary函数功能实现起来很复杂,但是逻辑上理解起来还是相对简单的,在wrapIfNecessary函数中主要的工作如下:
(1)找出指定bean对应的增强器。
(2)根据找出的增强器创建代理。
听起来似乎简单的逻辑,Spring中又做了哪些复杂的工作呢?对于创建代理的部分,通过之前的分析相信大家已经很熟悉了,但是对于增强器的获取,Spring又是怎么做的呢?
二、获取对应class/method的增强器
获取指定bean对应的增强器,其中包含两个关键字:增强器与对应。也就是说在 getAdvicesAndAdvisorsForBean函数中,不但要找出增强器,而且还需要判断增强器是否满足要求。
@Override
@Nullable
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) { List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
} /**
* Find all eligible Advisors for auto-proxying this class.
* @param beanClass the clazz to find advisors for
* @param beanName the name of the currently proxied bean
* @return the empty List, not {@code null},
* if there are no pointcuts or interceptors
* @see #findCandidateAdvisors
* @see #sortAdvisors
* @see #extendAdvisors
*/
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
List<Advisor> candidateAdvisors = findCandidateAdvisors();
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
其实我们也渐渐地体会到了Spring中代码的优秀,即使是一个很复杂的逻辑,在Spring中也会被拆分成若干个小的逻辑,然后在每个函数中实现,使得每个函数的逻辑简单到我们能快速地理解,而不会像有些人开发的那样,将一大堆的逻辑都罗列在一个函数中,给后期维护人员造成巨大的困扰。
同样,通过上面的函数,Spring又将任务进行了拆分,分成了获取所有增强器与增强器是否匹配两个功能点。
1. 寻找候选增强器
protected List<Advisor> findCandidateAdvisors() {
Assert.state(this.advisorRetrievalHelper != null, "No BeanFactoryAdvisorRetrievalHelper available");
return this.advisorRetrievalHelper.findAdvisorBeans();
}
public List<Advisor> findAdvisorBeans() {
// Determine list of advisor bean names, if not cached already.
String[] advisorNames = this.cachedAdvisorBeanNames;
if (advisorNames == null) {
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the auto-proxy creator apply to them!
advisorNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this.beanFactory, Advisor.class, true, false);
this.cachedAdvisorBeanNames = advisorNames;
}
if (advisorNames.length == 0) {
return new ArrayList<>();
}
List<Advisor> advisors = new ArrayList<>();
for (String name : advisorNames) {
if (isEligibleBean(name)) {
if (this.beanFactory.isCurrentlyInCreation(name)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping currently created advisor '" + name + "'");
}
}
else {
try {
advisors.add(this.beanFactory.getBean(name, Advisor.class));
}
catch (BeanCreationException ex) {
Throwable rootCause = ex.getMostSpecificCause();
if (rootCause instanceof BeanCurrentlyInCreationException) {
BeanCreationException bce = (BeanCreationException) rootCause;
String bceBeanName = bce.getBeanName();
if (bceBeanName != null && this.beanFactory.isCurrentlyInCreation(bceBeanName)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping advisor '" + name +
"' with dependency on currently created bean: " + ex.getMessage());
}
// Ignore: indicates a reference back to the bean we're trying to advise.
// We want to find advisors other than the currently created bean itself.
continue;
}
}
throw ex;
}
}
}
}
return advisors;
}
对于上面的函数,你看懂其中的奥妙了吗?首先是通过BeanFactoryUtils类提供的工具方法获取所有对应Advisor.class的类,获取办法无非是使用ListableBeanFactory中提供的方法:
String[] getBeanNamesForType(@Nullable Class<?> type, boolean includeNonSingletons, boolean allowEagerInit);
而当我们知道增强器在容器中的beanName时,获取增强器已经不是问题了,在BeanFactory 中提供了这样的方法,可以帮助我们快速定位对应的bean实例。
<T> T getBean(String name, Class<T> requiredType) throws BeansException;
或许你已经忘了之前留下的悬念,在我们讲解自定义标签时曾经注册了一个类型为 BeanFactoryTransactionAttributeSourceAdvisor 的 bean,而在此 bean 中我们又注入了另外两个Bean,那么此时这个 Bean 就会被开始使用了。因为 BeanFactoryTransactionAttributeSourceAdvisor同样也实现了 Advisor接口,那么在获取所有增强器时自然也会将此bean提取出来, 并随着其他增强器一起在后续的步骤中被织入代理。
2. 候选增强器中寻找到匹配项
当找出对应的增强器后,接下来的任务就是看这些增强器是否与对应的class匹配了,当然不只是class,class内部的方法如果匹配也可以通过验证。
public static List<Advisor> findAdvisorsThatCanApply(List<Advisor> candidateAdvisors, Class<?> clazz) {
if (candidateAdvisors.isEmpty()) {
return candidateAdvisors;
}
List<Advisor> eligibleAdvisors = new ArrayList<>();
// 首先处理引介增强
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor && canApply(candidate, clazz)) {
eligibleAdvisors.add(candidate);
}
}
boolean hasIntroductions = !eligibleAdvisors.isEmpty();
for (Advisor candidate : candidateAdvisors) {
// 引介增强已经处理
if (candidate instanceof IntroductionAdvisor) {
// already processed
continue;
}
// 对于普通bean的处理
if (canApply(candidate, clazz, hasIntroductions)) {
eligibleAdvisors.add(candidate);
}
}
return eligibleAdvisors;
}
public static boolean canApply(Advisor advisor, Class<?> targetClass, boolean hasIntroductions) {
if (advisor instanceof IntroductionAdvisor) {
return ((IntroductionAdvisor) advisor).getClassFilter().matches(targetClass);
}
else if (advisor instanceof PointcutAdvisor) {
PointcutAdvisor pca = (PointcutAdvisor) advisor;
return canApply(pca.getPointcut(), targetClass, hasIntroductions);
}
else {
// It doesn't have a pointcut so we assume it applies.
return true;
}
}
当前我们分析的是对于UserService是否适用于此增强方法,那么当前的advisor就是之前查找出来的类型为BeanFactoryTransactionAttributeSourceAdvisor的bean实例,而通过类的层次结构我们又知道:BeanFactoryTransactionAttributeSourceAdvisor 间接实现了PointcutAdvisor。 因此,在canApply函数中的第二个if判断时就会通过判断,会将BeanFactoryTransactionAttributeSourceAdvisor中的getPointcut()方法返回值作为参数继续调用canApply方法,而 getPoint()方法返回的是TransactionAttributeSourcePointcut类型的实例。对于 transactionAttributeSource这个属性大家还有印象吗?这是在解析自定义标签时注入进去的。
private final TransactionAttributeSourcePointcut pointcut = new TransactionAttributeSourcePointcut() {
@Override
@Nullable
protected TransactionAttributeSource getTransactionAttributeSource() {
return transactionAttributeSource;
}
};
那么,使用TransactionAttributeSourcePointcut类型的实例作为函数参数继续跟踪canApply。
public static boolean canApply(Pointcut pc, Class<?> targetClass, boolean hasIntroductions) {
Assert.notNull(pc, "Pointcut must not be null");
if (!pc.getClassFilter().matches(targetClass)) {
return false;
}
// 此时的pc表示TransactionAttributeSourcePointcut
// pc.getMethodMatcher()返回的正是自身(this)
MethodMatcher methodMatcher = pc.getMethodMatcher();
if (methodMatcher == MethodMatcher.TRUE) {
// No need to iterate the methods if we're matching any method anyway...
return true;
}
IntroductionAwareMethodMatcher introductionAwareMethodMatcher = null;
if (methodMatcher instanceof IntroductionAwareMethodMatcher) {
introductionAwareMethodMatcher = (IntroductionAwareMethodMatcher) methodMatcher;
}
Set<Class<?>> classes = new LinkedHashSet<>();
if (!Proxy.isProxyClass(targetClass)) {
classes.add(ClassUtils.getUserClass(targetClass));
}
classes.addAll(ClassUtils.getAllInterfacesForClassAsSet(targetClass));
for (Class<?> clazz : classes) {
Method[] methods = ReflectionUtils.getAllDeclaredMethods(clazz);
for (Method method : methods) {
if (introductionAwareMethodMatcher != null ?
introductionAwareMethodMatcher.matches(method, targetClass, hasIntroductions) :
methodMatcher.matches(method, targetClass)) {
return true;
}
}
}
return false;
}
通过上面函数大致可以理清大体脉络,首先获取对应类的所有接口并连同类本身一起遍历,遍历过程中又对类中的方法再次遍历,一旦匹配成功便认为这个类适用于当前增强器。
到这里我们不禁会有疑问,对于事物的配置不仅仅局限于在函数上配置,我们都知道,在类或接口上的配置可以延续到类中的每个函数,那么,如果针对每个函数迸行检测,在类本身上配罝的事务属性岂不是检测不到了吗?带着这个疑问,我们继续探求matcher方法。
做匹配的时候 methodMatcher.matches(method, targetClass)会使用 TransactionAttributeSourcePointcut 类的 matches 方法。
@Override
public boolean matches(Method method, Class<?> targetClass) {
if (TransactionalProxy.class.isAssignableFrom(targetClass)) {
return false;
}
// 自定义标签解析时注入
TransactionAttributeSource tas = getTransactionAttributeSource();
return (tas == null || tas.getTransactionAttribute(method, targetClass) != null);
}
此时的 tas 表示 AnnotationTransactionAttributeSource 类型,而 AnnotationTransactionAttributeSource 类型的 getTransactionAttribute 方法如下:
@Override
@Nullable
public TransactionAttribute getTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
} // First, see if we have a cached value.
Object cacheKey = getCacheKey(method, targetClass);
Object cached = this.attributeCache.get(cacheKey);
if (cached != null) {
// Value will either be canonical value indicating there is no transaction attribute,
// or an actual transaction attribute.
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return (TransactionAttribute) cached;
}
}
else {
// We need to work it out.
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// Put it in the cache.
if (txAttr == null) {
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
((DefaultTransactionAttribute) txAttr).setDescriptor(methodIdentification);
}
if (logger.isDebugEnabled()) {
logger.debug("Adding transactional method '" + methodIdentification + "' with attribute: " + txAttr);
}
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
很遗憾,在getTransactionAttribute函数中并没有找到我们想要的代码,这里是指常规的一贯的套路。尝试从缓存加载,如果对应信息没有被缓存的话,工作又委托给了computeTransactionAttribute函数,在computeTransactionAttribute函数中我们终于看到了事务标签的提取过程。
3. 提取事务标签
@Nullable
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
} // The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
// method代表接口中的方法,specificMethod代表实现类中的方法
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass); // First try is the method in the target class.
// 查看方法中是否存在事务声明
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
} // Second try is the transaction attribute on the target class.
// 查看方法所在类中是否存在事务声明
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
} // 如果存在接口,则到接口中去寻找
if (specificMethod != method) {
// Fallback is to look at the original method.
// 查找接口方法
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
// Last fallback is the class of the original method.
// 到接口中的类中去寻找
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
} return null;
}
对于事务属性的获取规则相信大家都已经很清楚,如果方法中存在事务属性,则使用方法上的属性,否则使用方法所在的类上的属性,如果方法所在类的属性上还是没有搜寻到对应的事务属性,那么在搜寻接口中的方法,再没有的话,最后尝试搜寻接口的类上面的声明。对于函数computeTransactionAttribute中的逻辑与我们所认识的规则并无差別,但是上面函数中并没有真正的去做搜寻事务属性的逻辑,而是搭建了个执行框架,将搜寻事务属性的任务委托给了 findTransactionAttribute 方法去执行。
@Override
@Nullable
protected TransactionAttribute findTransactionAttribute(Class<?> clazz) {
return determineTransactionAttribute(clazz);
} /**
* Determine the transaction attribute for the given method or class.
* <p>This implementation delegates to configured
* {@link TransactionAnnotationParser TransactionAnnotationParsers}
* for parsing known annotations into Spring's metadata attribute class.
* Returns {@code null} if it's not transactional.
* <p>Can be overridden to support custom annotations that carry transaction metadata.
* @param ae the annotated method or class
* @return the configured transaction attribute,
* or {@code null} if none was found
*/
@Nullable
protected TransactionAttribute determineTransactionAttribute(AnnotatedElement ae) {
for (TransactionAnnotationParser annotationParser : this.annotationParsers) {
TransactionAttribute attr = annotationParser.parseTransactionAnnotation(ae);
if (attr != null) {
return attr;
}
}
return null;
}
this.annotationParsers 是在当前类 AnnotationTransactionAttributeSource 初始化的时候初始化的,其中的值被加入了 SpringTransactionAnnotationParser,也就是当进行属性获取的时候其实是使用 SpringTransactionAnnotationParser 类的 parseTransactionAnnotation 方法进行解析的。
@Override
@Nullable
public TransactionAttribute parseTransactionAnnotation(AnnotatedElement ae) {
AnnotationAttributes attributes = AnnotatedElementUtils.findMergedAnnotationAttributes(
ae, Transactional.class, false, false);
if (attributes != null) {
return parseTransactionAnnotation(attributes);
}
else {
return null;
}
}
至此,我们终于看到了想看到的获取注解标记的代码。首先会判断当前的类是否含有 Transactional注解,这是事务属性的基础,当然如果有的话会继续调用parseTransactionAnnotation 方法解析详细的属性。
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
Propagation propagation = attributes.getEnum("propagation");
// 解析propagation
rbta.setPropagationBehavior(propagation.value());
Isolation isolation = attributes.getEnum("isolation");
// 解析isolation
rbta.setIsolationLevel(isolation.value());
// 解析timeout
rbta.setTimeout(attributes.getNumber("timeout").intValue());
// 解析readOnly
rbta.setReadOnly(attributes.getBoolean("readOnly"));
// 解析value
rbta.setQualifier(attributes.getString("value"));
ArrayList<RollbackRuleAttribute> rollBackRules = new ArrayList<>();
// 解析rollbackFor
Class<?>[] rbf = attributes.getClassArray("rollbackFor");
for (Class<?> rbRule : rbf) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析rollbackForClassName
String[] rbfc = attributes.getStringArray("rollbackForClassName");
for (String rbRule : rbfc) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析noRollbackFor
Class<?>[] nrbf = attributes.getClassArray("noRollbackFor");
for (Class<?> rbRule : nrbf) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析noRollbackForClassName
String[] nrbfc = attributes.getStringArray("noRollbackForClassName");
for (String rbRule : nrbfc) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
rbta.getRollbackRules().addAll(rollBackRules);
return rbta;
}
上面方法中实现了对对应类或者方法的事务属性解析,你会在这个类中看到任何你常用或者不常用的属性提取。
至此,我们终于完成了事务标签的解析。我们是不是分析的太远了,似乎已经忘了从哪里开始了。再回顾一下,我们现在的任务是找出某个增强器是否适合于对应的类,而是否匹配的关键则在于是否从指定的类或类中的方法中找到对应的事务属性,现在,我们以UserServicelmpl为例,已经在它的接口UserService中找到了事务属性,所以,它是与事务增强器匹配的,也就是它会被事务功能修饰。
至此,事务功能的初始化工作便结束了,当判断某个bean适用于事务增强时,也就是适用于增强器BeanFactoryTransactionAttributeSourceAdvisor,没错,还是这个类,所以说,在自定义标签解析时,注入的类成为了整个事务功能的基础。
BeanFactoryTransactionAttributeSourceAdvisor 作为 Advisor 的实现类,自然要遵从 Advisor 的处理方式,当代理被调用时会调用这个类的增强方法,也就是此bean的Advise,又因为在解析事务定义标签时我们把Transactionlnterceptor类S的bean注人到了 BeanFactoryTransactionAttributeSourceAdvisor中,所以,在调用事务增强器增强的代理类时会首先执行Transactionlnterceptor进行增强,同时,也就是在Transactionlnterceptor类中的invoke方法中完成了整个事务的逻辑。
Spring事务(二)事务自定义标签的更多相关文章
- Spring 系列教程之自定义标签的解析
Spring 系列教程之自定义标签的解析 在之前的章节中,我们提到了在 Spring 中存在默认标签与自定义标签两种,而在上一章节中我们分析了 Spring 中对默认标签的解析过程,相信大家一定已经有 ...
- Spring源码学习——自定义标签
2019独角兽企业重金招聘Python工程师标准>>> 1.自定义标签步骤 创建一个需要扩展的组件 定义xsd文件描述组件内容 创建一个文件,实现BeanDefinitionPars ...
- DEDECMS织梦常用二开自定义标签
网站名称:{dede:global.cfg_webname/} 网站根网址:{dede:global.cfg_basehost/} 网站根目录:{dede:global.cfg_cmsurl/} 网页 ...
- Spring自定义标签
一.原理: 1.Spring通过XML解析程序将其解析为DOM树, 2.通过NamespaceHandler指定对应的Namespace的BeanDefinitionParser将其转换成BeanDe ...
- spring源码-自定义标签-4
一.自定义标签,自定义标签在使用上面相对来说非常常见了,这个也算是spring对于容器的拓展.通过自定义标签的方式可以创造出很多新的配置方式,并且交给容器直接管理,不需要人工太多的关注.这也是spri ...
- javaweb学习总结(二十三)——jsp自定义标签开发入门
一.自定义标签的作用 自定义标签主要用于移除Jsp页面中的java代码. 二.自定义标签开发和使用 2.1.自定义标签开发步骤 1.编写一个实现Tag接口的Java类(标签处理器类) 1 packag ...
- Spring源码学习(3)—— 自定义标签
上一篇讲了Spring对默认标签的解析,Spring提供了很多属性,可以供开发者根据不同情况使用.绝大多数情况下,这些功能就已经足够了.但是,当用户有更特殊的需求,又或者很多公司自己实现的服务治理框架 ...
- javaweb(二十三)——jsp自定义标签开发入门
一.自定义标签的作用 自定义标签主要用于移除Jsp页面中的java代码. 二.自定义标签开发和使用 2.1.自定义标签开发步骤 1.编写一个实现Tag接口的Java类(标签处理器类) 1 packag ...
- 一、JSP标签介绍,自定义标签
一.JSP标签介绍 1. 标签库有什么作用 自定义标签库是一种优秀的表现层技术,之前介绍的MVC模式,我们使用jsp作为表现层,但是jsp语法嵌套在html页面,美工还是很难直接参与开发,并且jsp脚 ...
- Django 05 自定义过滤器、自定义标签
Django 05 自定义过滤器.自定义标签 一.自定义过滤器 #1.在项目目录下创建一个python package包 取名为common(这个名字可以自定义) #2.在common目录下创建一个t ...
随机推荐
- setInterval和setTimeout的区别以及setInterval越来越快问题的解决方法
setInterval()和setTimeout()方法都是js原生的定时方法,当然它们两个的作用也是不同的,并且最近在做上下滚动公告栏的时候,发现了setInterval()非常令人抓狂的问题,那就 ...
- ajax 异步请求返回只刷新一次页面
success:function (res) { if (res == "ok") { // $('#dg').bootstrapTable(('refresh')); if (l ...
- CSS 几款比较常用的翻转特效
第一个:360度翻转特效 <style>* { margin:0; padding:0; } .aa { width: 220px; height: 220px; margin: 0 au ...
- node(4)express 框架 EJS模板,cookie, session的学习
一.EJS 概述:前端咱们使用过的一个模板套路,是underscore的套路.接下来EJS它属于后台工程师人的模板. https://www.npmjs.com/package/ejs 官网地址 特点 ...
- 一个Interface 继承多个Interface 的总结
我们知道在Java中的继承都是单继承的,就是说一个父类可以被多个子类继承但是一个子类只能有一个父类.但是一个接口可以被不同实现类去实现,这就是我们说的Java中的多态的概念.下面我们再来说一下接口的多 ...
- tls/ssl工作原理及相关技术
https://www.wosign dot com/faq/faq2016-0309-03.htm TLS/SSL的功能实现主要依赖于三类基本算法:散列函数 Hash.对称加密和非对称加密,其利用非 ...
- datediff
DateDiff()是计算机函数. 中文名 日期比较函数 外文名 DateDiff() 作 用 得 出两个日期之间的间隔 用 途 返回两个日期之间的差值 允许数据类型 timeinterv ...
- 一次存储链路抖动因I/O timeout不同在AIX和HPUX上的不同表现(转)
去年一个故障案例经过时间的沉淀问题没在发生今天有时间简单的总结一下,当时正时午睡时分,突然告警4库8个实例同时不可用,这么大面积的故障多数是有共性的关连,当时查看数据库DB ALERT日志都是I/O错 ...
- Oracle特殊恢复原理与实战(DSI系列)
1.深入浅出Oracle(DSI系列Ⅰ) 2.Oracle特殊恢复原理与实战(DSI系列Ⅱ) 3.Oracle SQL Tuning(DSI系列Ⅲ)即将开设 4.Oracle DB Performan ...
- ORACLE DBA应该掌握的9个免费工具
TOP1 : 录像机OS Watcher 如果说,作为一个Oracle维护工程师,你至少应该装一个工具在你维护的系统里,那么我首推这个.它就像银行自助取款机顶上的摄像头,默默的记录下你操作系统中的 ...