高并发第十三弹:J.U.C 队列 SynchronousQueue.ArrayBlockingQueue.LinkedBlockingQueue.LinkedTransferQueue
因为下一节会说线程池,要用线程池 那么线程池有个很重要的参数 就是Queue的选择
常用的队列其实就两种:
先进先出(FIFO):先插入的队列的元素也最先出队列,类似于排队的功能。从某种程度上来说这种队列也体现了一种公平性。
后进先出(LIFO):后插入队列的元素最先出队列,这种队列优先处理最近发生的事件。
常用queue的分类:
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
DealyQueue:一个使用优先级队列实现的无界阻塞队列。
这几个queue都是
extends AbstractQueue<E>
implements BlockingQueue<E> {
AbstractQueue<E>:优先队列
AbstractQueue是 Java Collections Framework 的成员,是一个基于优先级堆的极大优先级队列。此队列按照在构造时所指定的顺序对元素排序,既可以根据元素的自然顺序来指定排序,也可以根据 Comparator 来指定,这取决于使用哪种构造方法。优先级队列不允许 null 元素。依靠自然排序的优先级队列还不允许插入不可比较的对象。
AbstractQueue的add,remove,element方法分别基于offer,poll,peek的实现,但是当队列为null时,抛出异常,而不是返回false或null。offer,poll,peek,并没有实现待子类扩展。清空,循环poll,直到为空。addAll为循环遍历集合元素,add到队列;
总结:记住这是一个优先队列即可
BlockingQueue:阻塞队列
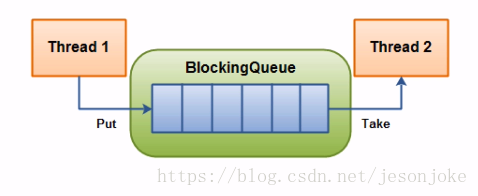

主要应用场景:生产者消费者模型,是线程安全的
多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和“消费者”模型中,通过队列可以很便利地实现两者之间的数据共享。假设我们有若干生产者线程,另外又有若干个消费者线程。如果生产者线程需要把准备好的数据共享给消费者线程,利用队列的方式来传递数据,就可以很方便地解决他们之间的数据共享问题。但如果生产者和消费者在某个时间段内,万一发生数据处理速度不匹配的情况呢?理想情况下,如果生产者产出数据的速度大于消费者消费的速度,并且当生产出来的数据累积到一定程度的时候,那么生产者必须暂停等待一下(阻塞生产者线程),以便等待消费者线程把累积的数据处理完毕,反之亦然。然而,在concurrent包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。好在此时,强大的concurrent包横空出世了,而他也给我们带来了强大的BlockingQueue。(在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤醒)
下面两幅图演示了BlockingQueue的两个常见阻塞场景: 如上图所示:当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起),直到有数据放入队列。
如上图所示:当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起),直到有数据放入队列。

如上图所示:当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。
这也是我们在多线程环境下,为什么需要BlockingQueue的原因。作为BlockingQueue的使用者,我们再也不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都给你一手包办了。既然BlockingQueue如此神通广大让我们一起来见识下它的常用方法:
BlockingQueue的核心方法:
放入数据:
offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,
则返回true,否则返回false.(本方法不阻塞当前执行方法的线程)
offer(E o, long timeout, TimeUnit unit),可以设定等待的时间,如果在指定的时间内,还不能往队列中
加入BlockingQueue,则返回失败。
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断
直到BlockingQueue里面有空间再继续.
获取数据:
poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,
取不到时返回null;
poll(long timeout, TimeUnit unit):从BlockingQueue取出一个队首的对象,如果在指定时间内,
队列一旦有数据可取,则立即返回队列中的数据。否则知道时间超时还没有数据可取,返回失败。
take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到
BlockingQueue有新的数据被加入;
drainTo():一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),
通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。

BlockingQueue提供了四套方法,分别来进行插入、移除、检查。每套方法在不能立刻执行时都有不同的反应。
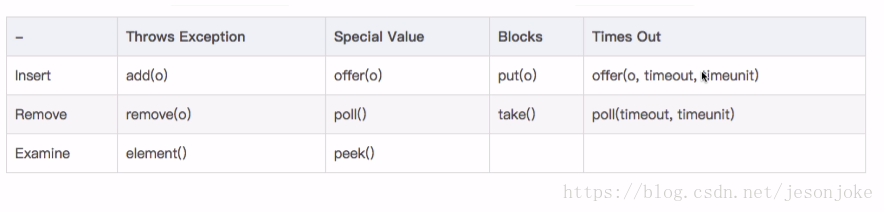
- Throws Exceptions :如果不能立即执行就抛出异常。
- Special Value:如果不能立即执行就返回一个特殊的值。
- Blocks:如果不能立即执行就阻塞
- Times Out:如果不能立即执行就阻塞一段时间,如果过了设定时间还没有被执行,则返回一个值
所以我们先来介绍以下具体子类
ArrayBlockingQueue :一个由数组支持的有界队列初始化时指定容量大小,一旦指定大小就不能再变.
基本结构

顾名思义 这是一个底层由数组来保存数据的
/** The queued items */
final Object[] items;
同时使用ReentrantLock 来确保并发安全的
/** Main lock guarding all access */
final ReentrantLock lock;
构造方法
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
构造方法实际是通Lock 来确定公平性的
ArrayBlockingQueue详解具体方法
2. LinkedBlockingQueue 一个由链表结构组成的有界阻塞队列。
实现了一个内部类
/**
* Linked list node class
*/
static class Node<E> {
E item; /**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next; Node(E x) { item = x; }
}
构造方法
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
大小配置可选,如果初始化时指定了大小,那么它就是有边界的。不指定就无边界(最大整型值)。内部实现是链表,采用FIFO形式保存数据。
详细方法深入理解LinkedBlockingQueue
3.LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
LinkedBlockingDeque是双向链表实现的双向并发阻塞队列。该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除);并且,该阻塞队列是支持线程安全。
此外,LinkedBlockingDeque还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。

其实就多了一个可头可尾的操作
4. PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
支持优先级排序,那么肯定需要排序的 所以 须是实现Comparable接口,队列通过这个接口的compare方法确定对象的priority。当前和其他对象比较,如果compare方法返回负数,那么在队列里面的优先级就比较高.优先级中传入的实体对象
比较规则:当前对象和其他对象做比较,当前优先级大就返回-1,优先级小就返回1
构造方法
add方法
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
if (cmp == null)
siftUpComparable(n, e, array);
else
siftUpUsingComparator(n, e, array, cmp);
size = n + 1;
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
比较有趣也就是扩容方法了
/**
* Tries to grow array to accommodate at least one more element
* (but normally expand by about 50%), giving up (allowing retry)
* on contention (which we expect to be rare). Call only while
* holding lock.
*
* @param array the heap array
* @param oldCap the length of the array
*/
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) // back off if another thread is allocating
Thread.yield();
lock.lock();
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
其先放开了锁,然后通过CAS设置allocationSpinLock来判断哪个线程获得了扩容权限,如果没抢到权限就会让出CPU使用权。最后还是要锁住开始真正的扩容。扩容权限争取到了就是计算大小,分配数组。暂不肯定为什么这么麻烦要分配数组的时候释放锁,暂猜测这样做效率会更高。
测试类
public class ObjectBean implements Comparable<ObjectBean> {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "ObjectBean [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(ObjectBean o) {
return this.age.compareTo(o.getAge());
}
本人能力有限 这节写的虎头蛇尾.如果以后把数据结构学习一下再回来重写吧
高并发第十三弹:J.U.C 队列 SynchronousQueue.ArrayBlockingQueue.LinkedBlockingQueue.LinkedTransferQueue的更多相关文章
- 高并发第八弹:J.U.C起航(java.util.concurrent)
java.util.concurrent是JDK自带的一个并发的包主要分为以下5部分: 并发工具类(tools) 显示锁(locks) 原子变量类(aotmic) 并发集合(collections) ...
- 高并发第十一弹:J.U.C -AQS(AbstractQueuedSynchronizer) 组件:Lock,ReentrantLock,ReentrantReadWriteLock,StampedLock
既然说到J.U.C 的AQS(AbstractQueuedSynchronizer) 不说 Lock 是不可能的.不过实话来说,一般 JKD8 以后我一般都不用Lock了.毕竟sychronize ...
- 并发与高并发(十三)J.U.C之AQS
前言 什么是AQS,是AbstractQueuedSynchronizer类的简称.J.U.C大大提高了并发的性能,而AQS又是J.U.S的核心. 主体概要 J.U.C之AQS介绍 J.U.C之AQS ...
- 高并发第十单:J.U.C AQS(AbstractQueuedSynchronizer) 组件:CountDownLatch. CyclicBarrier .Semaphore
这里有一篇介绍AQS的文章 非常好: Java并发之AQS详解 AQS全名:AbstractQueuedSynchronizer,是并发容器J.U.C(java.lang.concurrent)下lo ...
- 高并发第六弹:线程封闭(ThreadLocal)
当访问共享的可变数据时,通常需要使用同步.一种避免使用同步的方式就是不共享数据.如果仅在单线程内访问数据,就不需要同步.这种技术被称为线程封闭. 它其实就是把对象封装到一个线程里,只有一个线程能看到这 ...
- java高并发编程(四)高并发的一些容器
摘抄自马士兵java并发视频课程: 一.需求背景: 有N张火车票,每张票都有一个编号,同时有10个窗口对外售票, 请写一个模拟程序. 分析下面的程序可能会产生哪些问题?重复销售?超量销售? /** * ...
- Java 多线程高并发编程 笔记(二)
1. 单例模式(在内存之中永远只有一个对象) 1.1 多线程安全单例模式——不使用同步锁 public class Singleton { private static Singleton sin=n ...
- 并发编程-concurrent指南-阻塞双端队列-链阻塞双端队列LinkedBlockingDeque
LinkedBlockingDeque是双向链表实现的阻塞队列.该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除): 在不能够插入元素时,它将阻塞住试图插入元 ...
- Java高并发 -- J.U.C.组件扩展
Java高并发 -- J.U.C.组件扩展 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 FutureTask Future模式,核心思想是异步调用.和同步调用的区别 ...
随机推荐
- Java 8 LocalDateTime 初使用
LocalTime : 只包括时间 LocalDate : 只包括日期 LocalDateTime : 包括日期和时间 JDBC映射 LocalTime 对应 time LocalDate 对应 d ...
- hdoj1175 连连看(dfs+剪枝)
处理连连看问题. 要求拐弯方向不多于两次.剪枝很重要!!! 用dir记录当前方向.Orz,居然没想到. #include<iostream> #include<cstring> ...
- 使用Dockerfile定制镜像
Dockerfile是一个文本文件,其中包含额一条一条的指令,每一条指令构建一层,因此每一条指令的作用就是描述这一层应当如何的构建. 以构建nginx镜像为例,使用Dockerfile构建的步骤如下: ...
- JPA总结——实体关系映射(一对多@OneToMany)
JPA总结——实体关系映射(一对多@OneToMany) 注意:本文出自“阿飞”的博客,如果要转载本文章,请与作者联系! 并注明来源: http://blog.sina.com.cn/s/blog_4 ...
- C#里面const和readonly
一.const关键字限定一个变量不允许被改变. 使用const在一定程度上可以提高程序的安全性和可靠性. 1.用于修改字段或局部变量的声明,表示指定的字段或局部变量的值是常数,不能被修改. 2.常数声 ...
- Swift 里集合类型协议的关系
  Sequence A type that provides sequential, iterated access to its elements. 是最基础的协议,可以通过迭代来获取它的元素 ...
- postgresql 脏读-dirtied
共享缓冲区 在内存中读取或写入数据总是比在任何其他介质上更快.数据库服务器还需要用于快速访问数据的内存,无论是READ还是WRITE访问.在PostgreSQL中,这被称为"共享缓冲区&qu ...
- postgresql-数据库网络地址存储探索
问题背景 数据库审核过程中发现有存储ip的字段类型为varchar(50).想到postgresql有专门的存储ip类型.然而存在即合理.所以主要对比varchar和inet存储ip的不同. 网络地址 ...
- Scala 中的foreach和map方法比较
Scala中的集合对象都有foreach和map两个方法.两个方法的共同点在于:都是用于遍历集合对象,并对每一项执行指定的方法.而两者的差异在于:foreach无返回值(准确说返回void),map返 ...
- EJB3 阶段总结+一个EJB3案例 (1)
经过一段时时间的学习,对EJB3的相关知识和jboss8的配置有了大概的了解. 网上对EJB的评论很多,基本都是负面的,都表示EJB太过于沉重,不容易维护.但通过这段时间的学习,私下认为,EJB3在某 ...