大话JVM(一):垃圾收集算法
系列介绍|本系列主要是记录学习jvm过程中觉得重要的内容,方便以后复习
在说垃圾收集算法之前,先要说一下垃圾收集,从大的讲,垃圾收集需要考虑三件事情:
1.哪些内存需要回收
2.什么时候回收
3.如何回收
JVM在执行java程序时,把他管理的内存分为多个数据区域:
1.程序计数器(记录程序执行到哪了,各线程之间独立存储, 互不影响)
2.虚拟机栈(这个栈就是我们常说的jvm的“堆”和“栈”中的栈,这里存放的是编译期间可知的各种数据类型(8种基本类型)、对象引用(reference类型,就是一种数据指针,指向对象的起始地址,或者句柄,或者是对象相关的位置)
3.本地方法栈(这个跟虚拟机栈非常相似,只不过虚拟机栈是为虚拟机执行java方法服务的,而本地方法栈是为虚拟机使用Natvie方法服务的,虚拟机规范中没有对本地方法栈做强制规定,HotSpot把虚拟机栈和本地方法栈合二为一了)
4.java堆(这堆是JVM管理内存中最多的一块,几乎所有的对象实例都存放在这里,java虚拟机规范中描述:所有对象的实例以及数据都要在堆上分配,GC就是主要管理这个区域)
5.方法区(在HotSpot中,这个区就是我们常说的“永久代”,这是一个线程共享的区域,它主要用来存储被虚拟机加载的类信息、常量、静态变量、JIT编译后的代码等数据)
其中程序计数器、虚拟机栈、本地方法栈3个区随线程而生,随线程而灭;栈中的栈帧随方法的进入和退出有条不紊的执行出栈和入栈操作,内存的分配是在类结构确定下来时就已知的,内存的分配和回收都具有确定性,因此这几个区域不需要过多考虑回收问题,因为方法结束或线程结束时,内存自然跟着回收了。主要考虑的是JAVA堆和方法区,因为这部分内存分配是动态的,程序在运行时才知道创建哪个对象实例,执行哪个方法。
GC回收前需要考虑对象已经“死”了吗
判断对象是否存活有两种算法,一种是引用计数算法,另一种是可达性算法
1)引用计数算法
引用计数算法就是给对象中添加一个引用计数器,每当有地方引用他时,计算器值加1,当引用失效时,计数器值减1,计算器值为0时,表示对象不再被使用。
引用计数算法实现简单,判定效率高,但是有个致命确定,就是循环引用时无法正常工作。
public class CountGC {
public Object instance = null;
public static void testGC(String[] args){
//创建了一个CountGC对象,并发把它赋给了countGC1,CountGC的对象引用计数值加1
CountGC countGC1 = new CountGC();
//又创建了一个CountGC对象,并发把它赋给了countGC2,另一个CountGC的对象引用计数值加1
CountGC countGC2 = new CountGC();
//把第一个CountGC对象的instance字段赋值上第二个CountGC对象,第二个CountGC对象引用计数值再加1,这是就变成了2
countGC1.instance = countGC2;
//把第二个CountGC对象的instance字段赋值上第一个CountGC对象,第一个CountGC对象的引用计数值再加2,这时也变成了2
countGC2.instance = countGC1;
//countGC1赋空值,第一个CountGC对象引用减1
countGC1 = null;
//countGC2赋空值,第二个CountGC对象引用减1
countGC2 = null;
//如果这时候回收,这两个CountGC对象是无法回收的,因为他们的引用计数值不为0
System.gc();
}
}
2)可达性算法
可达性算法就是以一个 GC Roots对象向下搜索,能搜索到的对象就说明是存活的,搜索不到的对象说明就是不可用的。
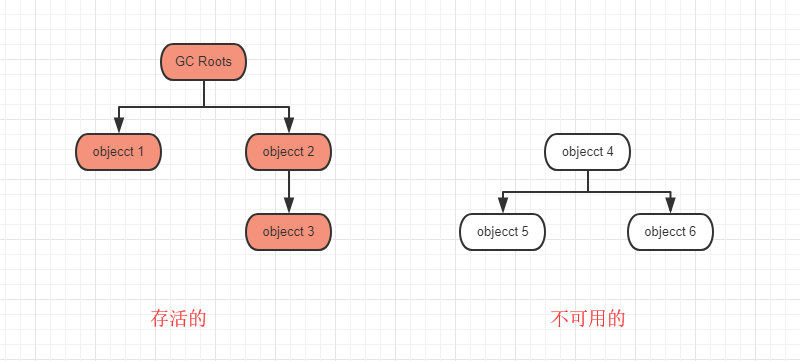
不管是引用计数算法,还是不可达算法,最终判断对象是否存活的关键,是引用。
下面我们正式介绍垃圾收集算法,我们主要介绍下面几种算法:
1.标记 - 清除算法
2.复制算法
3.标记 - 整理算法
4.分代收集算法
1)标记 - 清除算法
标记 - 清除算法就跟他的名字一样,分为“标记”和“清除”两阶段,首选标记出所有可回收的对象,然后统一回收所有被标记的对象。
标记 - 清除算法是最基础的算法,后续的几个算法都是基于这种算法思路对其不足进行改进得到的。
它的不足主要表现在两个方面,一是效率问题,二是空间利用问题
效率不高是因为,它标记是需要遍历所有内存空间,清除时也是一个个清除
空间利用率问题是因为清理后内存空间是零碎的,当需要分配大空间时,没有连续空间,需要再次触发GC
回收前状态:
回收后状态:



2)复制算法
为了解决效率问题,复制算法出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中一块,当这一块的内存用完时,就将存活的对象复制到另外一块内存上面,然后把使用过的内存空间一次清理掉。
回收前状态:
回收后状态:




复制算法的优点是:实现简单,运行高效
缺点是:浪费内存,从上面算法来看,实际使用只有原来内存的一半,浪费太大了。
现在的商用虚拟机都采用这种算法来回收新生代,IBM公司专门研究表明,新生代中的对象98%都是“朝生夕死”的,所以并不需要按照1:1来划分内存,而是将内存分成一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和一块Survivor,另一个Survivor作为预留空间。(HotSopt中默认分配比例是8:1:1,这样只浪费了10%的空间)。
采用这种内存分配方式的回收过程:
1.每次使用Eden和一块Survivor,另一块Survivor作为预留空间,
2.标记出Eden和一块Survivor空间中存活的对象,并复制到另一块Survivor空间中
3.清理掉使用过的Eden和一块Survivor空间。
这种做法有一个不足之处,就是当Eden和一块Survivor空间中存活的对象(对象存活率较高)大于另一块Survivor空间时,需要老年代担保分配,这时候效率非常低(因为存活对象是一个个复制到预留内存空间的,对象存活率特别高时,对象数也会非常多),而且还浪费空间(这时候预留空间就起不到作用了,浪费了预留空间的内存)。
因为当发现Eden和一块Survivor空间中存活的对象大于另一块Survivor空间时,这时候会把存活对象直接分配到老年代。
3)标记 - 整理算法
标记 - 整理算法就是把标记 - 清除算法中的清除替换成整理,整理时不直接对回收对象清理,而是让所有存活对象向一端移动,然后直接清理掉边界以外的内存。
回收前状态:
回收后状态:
这个算法是根据老年代的特点设计出来的,因为老年代中对象存活率较高,并且没有额外的空间对它进行分配担保,就必须采用“标记 - 清楚” 或者 “标记 - 整理”算法来进行回收。
4)分代收集
当前商业虚拟机都是采用“分代收集”算法,这种算法并没有什么新的思想,只是按照对象存活周期不同将内存划分为几个区域,就像java堆中的新生代和老年代一样,这样做的好处是,可以根据各个年代的特点采用适当的收集算法。
大话JVM(一):垃圾收集算法的更多相关文章
- JVM中垃圾收集算法总结
通过前面的介绍我们了解了对象创建和销毁的过程.那么JVM中垃圾收集器具体对对象回收采用的是什么算法呢?本文主要记录下JVM中垃圾收集的几种算法. JVM的垃圾回收的算法 标记-清除算法(Mark- ...
- 深入浅出JVM之垃圾收集算法
判断哪些对象需要被回收 引用计数算法: 给对象中添加一个引用计数器,每当有一个地方引用时,计数器值就加1:当引用失效时,计数器值就减1:任何时刻计数器为0的对象就是不可能再被使用的. 但是JVM没有使 ...
- JVM笔记-垃圾收集算法与垃圾收集器
1. 一些概念 1.1 垃圾&垃圾收集 垃圾:在 JVM 语境下,"垃圾"指的是死亡的对象所占据的堆空间. 垃圾收集:所谓"垃圾收集",就是将已分配出去 ...
- 深入理解JVM(二)--垃圾收集算法
一. 概述 说起垃圾收集(Garbage Collection, GC), 大部分人都把这项技术当做Java语言的伴随生产物. 事实上, GC的历史远远比Java久远, 1960年 诞生于MIT的Li ...
- 面试刷题25:jvm的垃圾收集算法?
垃圾收集是java语言的亮点,大大提高了开发人员的效率. 垃圾收集即GC,当内存不足的时候触发,不同的jvm版本算法和机制都有差别. 我是李福春,我在准备面试,今天的问题是: jvm的垃圾回收算法有哪 ...
- JVM垃圾收集算法之标记算法
前言 总所周知,jvm的垃圾收集算法一般包括标记.清除.整理三个阶段,最近在看了有关于垃圾收集的标记算法,记录一下自己的理解. 垃圾收集中标记算法有两种:一种是引用计数法,一种是根搜索算法. 引用记数 ...
- 深入理解Java虚拟机 - 垃圾收集算法与垃圾收集器
1. 垃圾收集算法 JVM的垃圾收集算法在不同的JVM实现中有所不同,且在平时工作中一般不会深入到收集算法,因此只对算法做较为简单的介绍. 1.1 标记-清除算法 ...
- JVM垃圾收集算法(标记-清除、复制、标记-整理)
[JVM垃圾收集算法] 1)标记-清除算法: 标记阶段:先通过根节点,标记所有从根节点开始的对象,未被标记的为垃圾对象(错了吧?) 清除阶段:清除所有未被标记的对象 2)复制算法: 将原有的内存空间 ...
- JVM垃圾收集算法
JVM垃圾收集 1. 判断对象是否存活 引用计数算法 对象添加一个引用计数器,每个地方引用它,计数器值加+1:当引用失效,计算器值减1:任何时刻计数器为0的对象不可能被使用.引用计数算法实现简单,高效 ...
随机推荐
- Jmeter服务器监控 serveragent如何使用
安装jmeter插件Plugins Managerjmeter-plugins.org推出了全新的Plugins Manager,对于其提供的插件进行了集中的管理,我们只需要安装这个管理插件,即可以在 ...
- NSTimer、performSelector 函数没有被调用的原因
performSelector 指定的方法没有被调用 Invokes a method of the receiver on the current thread using the default ...
- day 33js 后续 函数.对象
前情提要: 今天学习的是js的函数以及简单的类的使用 一:函数的初识别 <!DOCTYPE html> <html lang="en"> <head& ...
- Docker镜像(二)
一. 获取镜像 1.1. docker pull 镜像是运行容器的前提,也就是说没有镜像就没有办法创建容器 获取镜像的命令: docker pull 这个命令可以直接在docker Hub镜像源下载镜 ...
- editplus配置csharp
只要是写代码的,我们肯定常有用到EditPlus..Net开发也是如此.有时我们需要调试一小段C#(或VB.Net)代码,这时去大动干戈在臃肿的VS.Net中新建“控制台应用程序”项目,写满“Cons ...
- 剑指offer六十之按之把二叉树打印成多行
一.题目 从上到下按层打印二叉树,同一层结点从左至右输出.每一层输出一行.二.思路 队列LinkedList完成层序遍历,用end记录每层结点数目 三.代码 import java.util.Arra ...
- (转)DB2 HADR 监控详解
原文:https://www.ibm.com/developerworks/cn/data/library/techarticles/dm-1010baosf/ HADR 简介 HADR( 高可用性灾 ...
- .NET源码Stack<T>和Queue<T>的实现
这阵子在重温数据结构的时候,顺便用ILSpy看了一些.NET类库的实现,发现一些基本的数据结构的实现方法也是挺有意思的,所以这里拿出来跟大家分享一下.这篇文章讨论的是Stack和Queue的泛型实现. ...
- linux内核模块的安全
linux可以动态的加载内核模块,在很多场合可能需要确保加载内核的安全性.如果被攻击者加载恶意内核模块,将会使得内核变得极其危险. 当然,稳妥的做法就是给内核模块进行签名,内核只加载能正确验证的签名. ...
- Linq基础知识之延迟执行
Linq中的绝大多数查询运算符都有延迟执行的特性,查询并不是在查询创建的时候执行,而是在遍历的时候执行,也就是在enumerator的MoveNext()方法被调用的时候执行,大说数Linq查询操作实 ...