Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述


2.排序分类

3.WritableComparable案例
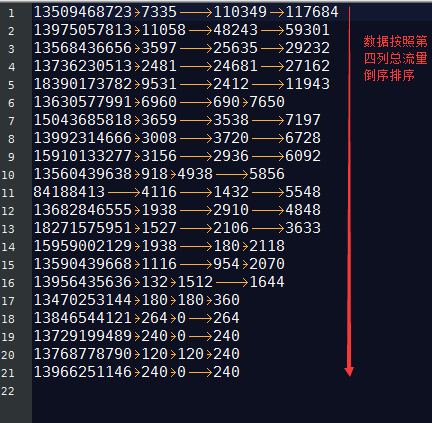
这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进行了字典排序
13470253144 180 180 360
13509468723 7335 110349 117684
13560439638 918 4938 5856
13568436656 3597 25635 29232
13590439668 1116 954 2070
13630577991 6960 690 7650
13682846555 1938 2910 4848
13729199489 240 0 240
13736230513 2481 24681 27162
13768778790 120 120 240
13846544121 264 0 264
13956435636 132 1512 1644
13966251146 240 0 240
13975057813 11058 48243 59301
13992314666 3008 3720 6728
15043685818 3659 3538 7197
15910133277 3156 2936 6092
15959002129 1938 180 2118
18271575951 1527 2106 3633
18390173782 9531 2412 11943
84188413 4116 1432 5548
字段含义分别为手机号,上行流量,下行流量,总流量
需求是根据总流量进行排序
Bean对象,需要实现序列化,反序列化和Comparable接口
package com.nty.writableComparable; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; /**
* author nty
* date time 2018-12-12 16:33
*/ /**
* 实现WritableComparable接口
* 原先将bean序列化时,需要实现Writable接口,现在再实现Comparable接口
*
* public interface WritableComparable<T> extends Writable, Comparable<T>
*
* 所以我们可以实现Writable和Comparable两个接口,也可以实现WritableComparable接口
*/
public class Flow implements WritableComparable<Flow> { private long upflow;
private long downflow;
private long total; public long getUpflow() {
return upflow;
} public void setUpflow(long upflow) {
this.upflow = upflow;
} public long getDownflow() {
return downflow;
} public void setDownflow(long downflow) {
this.downflow = downflow;
} public long getTotal() {
return total;
} public void setTotal(long total) {
this.total = total;
} //快速赋值
public void setFlow(long upflow, long downflow){
this.upflow = upflow;
this.downflow = downflow;
this.total = upflow + downflow;
} @Override
public String toString() {
return upflow + "\t" + downflow + "\t" + total;
} //重写compareTo方法
@Override
public int compareTo(Flow o) {
return Long.compare(o.total, this.total);
} //序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upflow);
out.writeLong(downflow);
out.writeLong(total);
} //反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
upflow = in.readLong();
downflow = in.readLong();
total = in.readLong();
}
}
Mapper类
package com.nty.writableComparable; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* author nty
* date time 2018-12-12 16:47
*/
public class FlowMapper extends Mapper<LongWritable, Text, Flow, Text> { private Text phone = new Text(); private Flow flow = new Flow(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//13470253144 180 180 360
//分割行数据
String[] flieds = value.toString().split("\t"); //赋值
phone.set(flieds[0]); flow.setFlow(Long.parseLong(flieds[1]), Long.parseLong(flieds[2])); //写出
context.write(flow, phone);
}
}
Reducer类
package com.nty.writableComparable; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* author nty
* date time 2018-12-12 16:47
*/
//注意一下输出类型
public class FlowReducer extends Reducer<Flow, Text, Text, Flow> { @Override
protected void reduce(Flow key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
//输出
context.write(value,key);
}
}
}
Driver类
package com.nty.writableComparable; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* author nty
* date time 2018-12-12 16:47
*/
public class FlowDriver { public static void main(String[] args) throws Exception {
//1. 获取Job实例
Configuration configuration = new Configuration();
Job instance = Job.getInstance(configuration); //2. 设置类路径
instance.setJarByClass(FlowDriver.class); //3. 设置Mapper和Reducer
instance.setMapperClass(FlowMapper.class);
instance.setReducerClass(FlowReducer.class); //4. 设置输出类型
instance.setMapOutputKeyClass(Flow.class);
instance.setMapOutputValueClass(Text.class); instance.setOutputKeyClass(Text.class);
instance.setOutputValueClass(Flow.class); //5. 设置输入输出路径
FileInputFormat.setInputPaths(instance, new Path("d:\\Hadoop_test"));
FileOutputFormat.setOutputPath(instance, new Path("d:\\Hadoop_test_out")); //6. 提交
boolean b = instance.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
结果
4.GroupingComparator案例
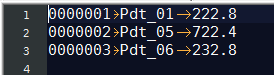
订单id 商品id 商品金额
0000001 Pdt_01 222.8
0000002 Pdt_05 722.4
0000001 Pdt_02 33.8
0000003 Pdt_06 232.8
0000003 Pdt_02 33.8
0000002 Pdt_03 522.8
0000002 Pdt_04 122.4
求出每一个订单中最贵的商品
需求分析:
1) 将订单id和商品金额作为key,在Map阶段先用订单id升序排序,如果订单id相同,再用商品金额降序排序
2) 在Reduce阶段,用groupingComparator按照订单分组,每一组的第一个即是最贵的商品
先定义bean对象,重写序列化反序列话排序方法
package com.nty.groupingComparator; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; /**
* author nty
* date time 2018-12-12 18:07
*/
public class Order implements WritableComparable<Order> { private String orderId; private String productId; private double price; public String getOrderId() {
return orderId;
} public Order setOrderId(String orderId) {
this.orderId = orderId;
return this;
} public String getProductId() {
return productId;
} public Order setProductId(String productId) {
this.productId = productId;
return this;
} public double getPrice() {
return price;
} public Order setPrice(double price) {
this.price = price;
return this;
} @Override
public String toString() {
return orderId + "\t" + productId + "\t" + price;
} @Override
public int compareTo(Order o) {
//先按照订单排序,正序
int compare = this.orderId.compareTo(o.getOrderId());
if(0 == compare){
//订单相同,再比较价格,倒序
return Double.compare( o.getPrice(),this.price);
}
return compare;
} @Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(productId);
out.writeDouble(price);
} @Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.productId = in.readUTF();
this.price = in.readDouble();
}
}
Mapper类
package com.nty.groupingComparator; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* author nty
* date time 2018-12-12 18:07
*/
public class OrderMapper extends Mapper<LongWritable, Text, Order, NullWritable> { private Order order = new Order(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//0000001 Pdt_01 222.8
//分割行数据
String[] fields = value.toString().split("\t"); //为order赋值
order.setOrderId(fields[0]).setProductId(fields[1]).setPrice(Double.parseDouble(fields[2])); //写出
context.write(order,NullWritable.get());
}
}
GroupingComparator类
package com.nty.groupingComparator; import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; /**
* author nty
* date time 2018-12-12 18:08
*/
public class OrderGroupingComparator extends WritableComparator { //用作比较的对象的具体类型
public OrderGroupingComparator() {
super(Order.class,true);
} //重写的方法要选对哦,一共有三个,选择参数为WritableComparable的方法
//默认的compare方法调用的是a,b对象的compare方法,但是现在我们排序和分组的规则不一致,所以要重写分组规则
@Override
public int compare(WritableComparable a, WritableComparable b) {
Order oa = (Order) a;
Order ob = (Order) b;
//按照订单id分组
return oa.getOrderId().compareTo(ob.getOrderId());
}
}
Reducer类
package com.nty.groupingComparator; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* author nty
* date time 2018-12-12 18:07
*/
public class OrderReducer extends Reducer<Order, NullWritable,Order, NullWritable> { @Override
protected void reduce(Order key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//每一组的第一个即是最高价商品,不需要遍历
context.write(key, NullWritable.get());
}
}
Driver类
package com.nty.groupingComparator; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* author nty
* date time 2018-12-12 18:07
*/
public class OrderDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1获取实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration); //2设置类路径
job.setJarByClass(OrderDriver.class); //3.设置Mapper和Reducer
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class); //4.设置自定义分组类
job.setGroupingComparatorClass(OrderGroupingComparator.class); //5. 设置输出类型
job.setMapOutputKeyClass(Order.class);
job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Order.class);
job.setOutputValueClass(NullWritable.class); //6. 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("d:\\Hadoop_test"));
FileOutputFormat.setOutputPath(job, new Path("d:\\Hadoop_test_out")); //7. 提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
输出结果
Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组的更多相关文章
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- MapReduce之WritableComparable排序
@ 目录 排序概述 获取Mapper输出的key的比较器(源码) 案例实操(区内排序) 自定义排序器,使用降序 排序概述 排序是MapReduce框架中最重要的操作之一. Map Task和Reduc ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- Hadoop(20)-MapReduce框架原理-OutputFormat
1.outputFormat接口实现类 2.自定义outputFormat 步骤: 1). 定义一个类继承FileOutputFormat 2). 定义一个类继承RecordWrite,重写write ...
- Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析
1.MapReduce的数据流 1) Input -> Mapper阶段 这一阶段的主要分工就是将文件切片和把文件转成K,V对 输入源是一个文件,经过InputFormat之后,到了Mapper ...
- Hadoop(19)-MapReduce框架原理-Combiner合并
1. Combiner概述 2. 自定义Combiner实现步骤 1). 定义一个Combiner继承Reducer,重写reduce方法 public class WordcountCombiner ...
- Hadoop(15)-MapReduce框架原理-FileInputFormat的实现类
1. TextInputFormat 2.KeyValueTextInputFormat 3. NLineInputFormat
- Hadoop(14)-MapReduce框架原理-切片机制
1.FileInputFormat切片机制 切片机制 比如一个文件夹下有5个小文件,切片时会切5个片,而不是一个片 案例分析 2.FileInputFormat切片大小的参数配置 源码中计算切片大小的 ...
随机推荐
- redis订阅与发布(把redis作为消息中间件)
订阅频道127.0.0.1:6379> subscribe chat1Reading messages... (press Ctrl-C to quit)1) "subscribe&q ...
- 深入浅出React的一些细节——State
(来源于: https://facebook.github.io/react/docs/state-and-lifecycle.html 翻译by:@TimRChen) Using State Cor ...
- CCSUOJ评测系统——第四次scrum冲刺
1.小组成员 舒 溢 许嘉荣 唐 浩 黄欣欣 廖帅元 刘洋江 薛思汝 2.最终成果及其代码仓库链接 CCSU评测系统 代码仓库 3.评测系统功能 用户注册 用户可选题目进行提交 用户做题结果 排名功能 ...
- C# 希尔排序
引用:对于大规模乱序数组插入排序很慢,因为它只会交换相邻的元素,因此元素只能一点一点的从数组的一端移动到另一端.例如,如果主键最小的元素正好在数组的尽头,要将它挪到正确的位置就需要N-1次移动.希尔排 ...
- 给UIScrollView添加category实现UIScrollView的轮播效果
给UIScrollView添加category实现UIScrollView的轮播效果 大家都知道,要给category添加属性是必须通过runtime来实现的,本教程中给UIScrollView添加c ...
- 禁用休眠(删除休眠文件) 关掉此选项可节省C盘好几G空间:文章内容bat文件源码
@ECHO offTITLE 关掉休眠 MACHENIKE set TempFile_Name=%SystemRoot%\System32\BatTestUACin_SysRt%Random%.bat ...
- EntityFramework Code First便捷工具——数据迁移
使用EntityFramework Code First开发,数据迁移是一个不得不提的技术. 在我们的开发过程中,难免需要对模型进行改进,模型改进后,会导致实体集与数据库不一致,当然我们可以通过删除数 ...
- 解决标题过长的CSS
不知道为什么大家用截取字符串的人很多呢.. <html> <head> <style type="text/css"> .divout { di ...
- * args 和 **kwargs
def func(*args, **kwargs): print(args,kwargs) func("对", "哦",o=4, k=0) 结果---> ...
- C++项目第五次作业之文件的读取
前言 乍看题目,用文件读取数据,这不是很简单的事嘛ps:以前写单个.cpp就是用freopen读取数据,然而当开始写的时候就出现了问题(什么叫做实力作死,有一种痛叫too young too simp ...