MapReduce调优总结与拓展
本文为《hadoop技术内幕:深入解析MapReduce架构设计与实现原理》一书第9章《Hadoop性能调优》的总结。
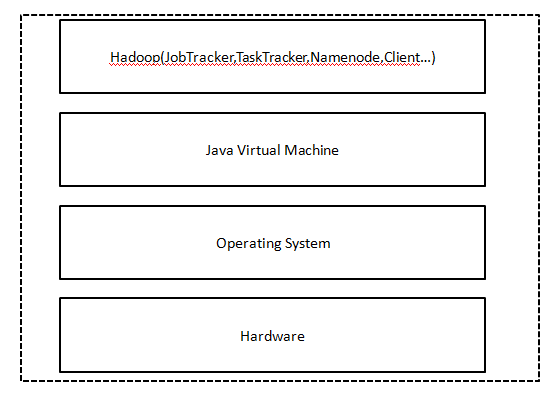
图1 Hadoop层次结构图
从管理员角度进行调优
1.硬件选择
master配置(可靠性,内存,CPU主频等)优于slave。
2.操作系统参数调优
1)增大同时打开的文件描述符和网络连接上限
ulimit 将允许同时打开的文件描述符数增大到一个合适的值。
net.core.somaxconn
定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128(通常要增加大1024或更多)。
关于这个参数,见这篇博文:http://blog.csdn.net/taolinke/article/details/6800979
2)关闭swap分区
避免使用swap分区。设置vm.swappiness
3)设置合理的预读取缓冲大小
blockdev命令
4)文件系统选择与配置
不同的文件系统会有一定的差别。
在Linux文件系统中,启动noatime属性。具体操作见这篇文章:http://www.cnblogs.com/allegro/archive/2011/04/18/2019466.html
5)I/O调度器选择
详情可参见AMD的白皮书《Hadoop performance tuning guide》
3.JVM参数调优
关键词:JVM FLAGS、垃圾回收机制。参见《Hadoop performance tuning guide》
4.Hadoop参数调优
1)合理规划资源
a设置合理的槽位数目
b编写健康监测脚本
2)调整心跳配置
a调整心跳间隔
b启用带外心跳
3)磁盘块配置
4)设置合理的RPCHandler和HTTP线程数目
a配置RPC Handler数目
b配置HTTP线程数目
5)慎用黑名单机制
黑名单节点数目越多,系统吞吐率和计算能力越低。
6)启用批量任务调度
7)选择合适的压缩算法
mapred.compress.map.output 设为true
设置mapred.map.output.compression.codec的值为合适的值。
8)启用预读取机制
从用户角度进行调优
1.应用程序编写规范
1)设置combiner,作用是减少map端的中间输出。
2)选择合适的Writable类型,Map Task和Reduce Task的输入输出都是Writable类型。
2.作业级别参数调优
1)规划合理的任务数目
2)增加输入文件副本数目
输入文件副本少,一个可能的后果是当多个任务并行读取一个副本时,会出现读取瓶颈。
在hdfs-site.xml中修改dfs.replication的值。
3)启动推测执行机制
将运行较慢的任务在另一个节点上启动,2个任务同时运行。其中1个提前完成后会将另一个杀死。
属性:mapred.map.tasks.speculative.execution 默认true
4)设置容忍度
分为作业级别和任务级别的失败容忍。
属性:mapred.max.map.failures.percent 默认0,如果是5表示5%
mapred.map.max.attempts 默认为4
5)适当打开JVM重用功能
当任务较小时,避免JVM重复启动占用很多时间。mapred.job.reuse.jvm.num.tasks 默认为1
6)设置任务超时时间
超时之后,TaskTracker将任务杀死,然后在另一个节点重新启动一个。
属性设置:
mapred.task.timeout 默认60 000(单位毫秒,也就是10分钟)
7)合理使用DistributedCache
了解下DistributedCache就知道该怎么用这个了。具体细节是:在调用任务前将文件上传到HDFS可以在作业运行期间将DistributedCache内的这些文件下载到public目录下,好处是:public目录下的文件是共享的,后续任务不必重新下载。
8)合理控制Reduce Task的启动时机
注意:启动过早会占用slot资源,造成slot Hoarding现象;启动过晚会造成资源获取较晚从而延长作业运行时间。
旧版 mapred.reduce.slowstart.completed.maps 默认值0.05
新版 mapreduce.job.reduce.slowstart.completed.maps 默认0.05
9)跳过坏记录
mapred.skip.attempts.to.start.skipping 当任务失败次数达到此值时,才会进入skip mode,即启用跳过坏记录功能。
mapred.skip.map.skip.records 最多允许跳过的坏记录的个数
mapred.skip.reduce.max.skip.groups
mapred.skip.out.dir 顾名思义
10)提高作业优先级
解释一下怎么设置作业的优先级:设置mapred.job.priority(默认NORMAL)或者mapreduce.job.priority(NORMAL)。总共有5个优先级可选:VERY_HIGH,HIGH,NORMAL,LOW,VERY_LOW。
优先级主要作用在于作业调度器会根据优先级分配资源(slot数目或者在YARN中更加灵活的内存容量)。
3.任务级别参数调优
1)Map Task调优
高效利用环形缓冲区。具体方法是设置合适的io.sort.record.percent,这个属性的含义是索引占buffer的比例。索引或者数据达到了缓冲区的io.sort.spill.percent时,就会触发flush,将数据读入磁盘。根据索引大小(一般为16B)和key/value大小,设置合适的io.sort.record.percent值=16/(16+R)(R为key/value大小),这样就可以最大限度利用圆形缓冲区了。
2)Reduce Task调优
主要目的是减少磁盘的写入。
写入磁盘的条件为:
a内存使用率超过heapsize*(mapred.job.shuffle.input.buffer.percent)达到mapred.job.shuffle.merge.percent(默认为0.66);
b内存中文件数目超过mapred.inmem.merge.percent.threshold(默认是1000);
c文件大小超过阈值heapsize*(mapred.job.shuffle.input.buffer.percent)*0.25。
通过调整这些属性值,可以控制磁盘的写入。
MapReduce调优总结与拓展的更多相关文章
- Hadoop Mapreduce 调优
- MapReduce 调优-Combiner
下图是演示了Combiner的好处 因为我们知道Hadoop的好处在于集群中有很多小的机器,组成了一个庞大的集群,把一个大的计算任务后者说复杂的计算过程分发到了一个个小的机器上面.但是这个集群一个致命 ...
- MapReduce shuffle过程剖析及调优
MapReduce简介 在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的.数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问 ...
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- CM记录-Hadoop参数调优
1.HDFS调优 a.设置合理的块大小(dfs.block.size) b.将中间结果目录设置为分布在多个磁盘以提升写入速度(mapred.local.dir) c.设置DataNode处理RPC的线 ...
- Hive on MR调优
当HiveQL跑不出来时,基本上是数据倾斜了,比如出现count(distinct),groupby,join等情况,理解 MR 底层原理,同时结合实际的业务,数据的类型,分布,质量状况等来实际的考虑 ...
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- [大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码
6.4.5 优化MapReduce用户JAVA代码 MapReduce执行代码的方式和普通JAVA应用不同.这是由于MapReduce框架为了能够高效地处理海量数据,需要成百万次调用map和reduc ...
- [大牛翻译系列]Hadoop(11)MapReduce 性能调优:诊断一般性能瓶颈
6.2.4 任务一般性能问题 这部分将介绍那些对map和reduce任务都有影响的性能问题. 技术37 作业竞争和调度器限制 即便map任务和reduce任务都进行了调优,但整个作业仍然会因为环境原因 ...
随机推荐
- Mysql-表关系
表关系分为三种:一对一,一对多,多对多 一对多:一个学院对应多个学生,而一个学生只对应一个学院 -- 这儿classroom 是代表的学院. -- 一对多 - A表的一条记录 对应 B 表多条记 ...
- OpenACC 云水参数化方案
▶ 书上第十三章,用一系列步骤优化一个云水参数化方案.用于熟悉 Fortran 以及 OpenACC 在旗下的表现 ● 代码,文件较多,放在一起了 ! main.f90 PROGRAM main US ...
- 0_Simple__simpleCubemapTexture
立方体纹理贴图 ▶ 源代码.用纹理方法把元素按原顺序从 CUDA3D 数组中取出来,求个相反数放入全局内存,输出. #include <stdio.h> #include "cu ...
- SqlServer——触发器
一:触发器基本知识 1.首先必须明确以下几点: 触发器是一种特殊的存储过程,但没有接口(输入输出参数),在用户执行Inserted.Update.Deleted 等操作时被自动触发: 当触发的SQL ...
- leetcode227
class Solution { public: stack<int> OPD; stack<char> OPR; int calculate(int num1, int nu ...
- 机器学习入门-线性判别分析(LDA)1.LabelEncoder(进行标签的数字映射) 2.LinearDiscriminantAnalysis (sklearn的LDA模块)
1.from sklearn.processing import LabelEncoder 进行标签的代码编译 首先需要通过model.fit 进行预编译,然后使用transform进行实际编译 2. ...
- Unknown column in 'field list'
好久都没有亲手写数据库的连接以及操作了,近期一直都是用ejb,直接就映射到数据库了,所以关于jdbc的知识都忘得差不多了.不过吧,为了学习struts2,还是重新将jdbc知识捡起来.找了一上午的错误 ...
- 向oracle中的表插入数据的方法
向oracle中的表插入数据的方法有以下几种: 假设表名为User 第一种方法:select t.*,rowid from User t;-->点击钥匙那个标记就可向表中添加数据 第二种方法:s ...
- form表单重置、清空方法记录
myform 是form的id属性值 1.调用reset()方法 function fomrReset() { document.getElementById("myform"). ...
- destoon 分页
php: global $pagesize,$page; $pagesize = 10;//分页改为10条一页 $offset or $offset = ($page-1)*$pagesize; $t ...