PSO算法的改进(参数)
## 基本PSO的改进
虽然粒子群在求解优化函数时,表现了较好的寻优能力;通过迭代寻优计算,能够迅速找到近似解;
但基本的PSO容易陷入局部最优,导致结果误差较大。
两个方面:
1.将各种先进理论引入到PSO算法,研究各种改进和PSO算法;(混沌技术,神经网络技术,自适应技术)
2.将PSO算法和其它智能优化算法相结合,研究各种混合优化算法,
达到取长补短、改善算法某方面性能的效果。
近时期粒子群改进策略主要体现的方面:
1.PSO算法的惯性权重模型,通过惯性权重的引入,提高了算法的全局搜索能力;
2.带邻域操作的PSO模型,克服PSO模型在优化搜索后期随迭代次数增加搜索结果无明显改进的缺点;
3.协同PSO算法,用K个相互独立的粒子群分别在D维的目标搜索空问中的不同维度方向上进行搜索;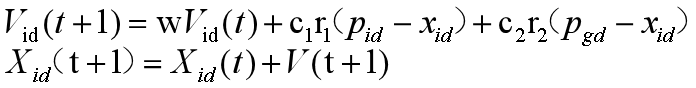
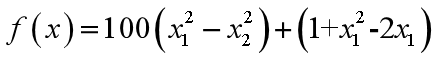
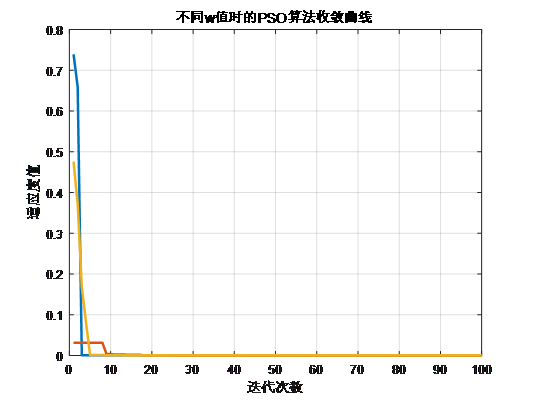
*蓝色的曲线:w=0.8,黄色的曲线:w=0.6红色的曲线:w=0.4*
从上式可以看出,w越大,微粒飞行速度越大,微粒将以较大的步长进行全局搜索;w越小,则微粒步长小,趋向于精细的局部搜索。
同时,从右图也可以看出w=0.8时,微粒以更少的迭代次数取得全局最优;w=0.6时,迭代次数其次,
w=0.4时,迭代次数相对较多。
虽然较大的权重因子有利于跳出局部最小值,便于全局搜索,而较小的惯性因子则有利于对当前的搜索区域进行精确局部搜索,以利于算法收敛;但是w过大容易导致“早熟收敛”与算法后期在全局最优解附近产生振荡的现象。
**w的改进**
一般方法是把Wmax逐渐变成Wmin;
**1.权重线性递减的PSO算法**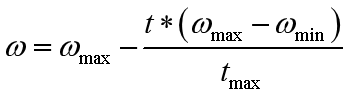
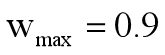
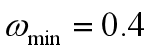
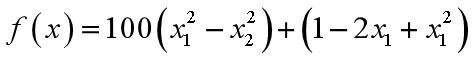
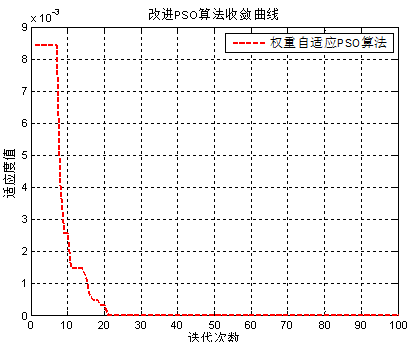
自适应权重粒子群优化算法适应度曲线
2.自适应权重的PSO算法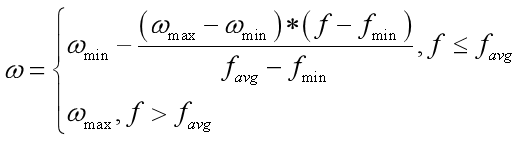
f表示微粒当前的目标函数值。
当各微粒的目标值趋于一致或趋于局部最优时,将使惯性权重增大,而各微粒的目标值比较分散时,使惯性权重减小,同时对于目标函数值优于平均目标值的微粒,其对应的惯性权重因子较小,从而保留了该微粒,反之对于目标函数值差于平均目标值的微粒,其对应的惯性权重因子较大,使得该微粒向较好的搜索区域靠拢。(附图)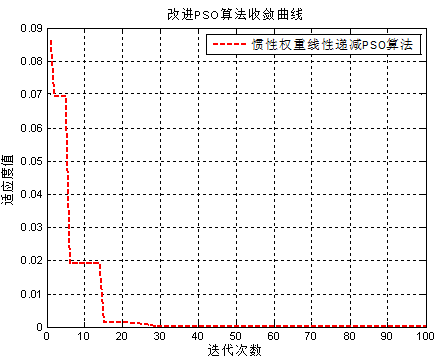
惯性权重线性递减PSO算法适应度曲线
3.随机权重策略的PSO算法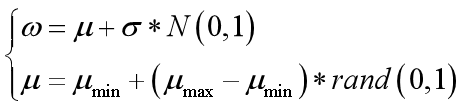
随机地选取值,使得微粒历史速度对当前速度的影响是随机的。
为服从某种随机分布的随机数,从一定程度上可从两方面克服 w的线性递减所带来的不足。
随机权重策略的PSO算法对于多峰函数,能在一定程度上避免陷入局部最优。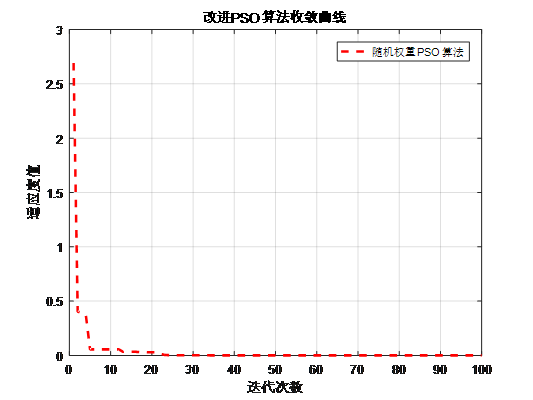
[随机权重策略的PSO适应度曲线]
4.增加收缩因子的PSO算法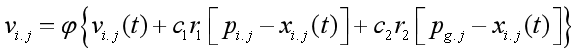
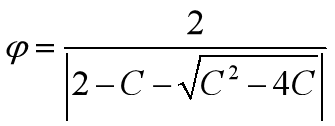
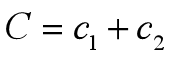
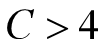
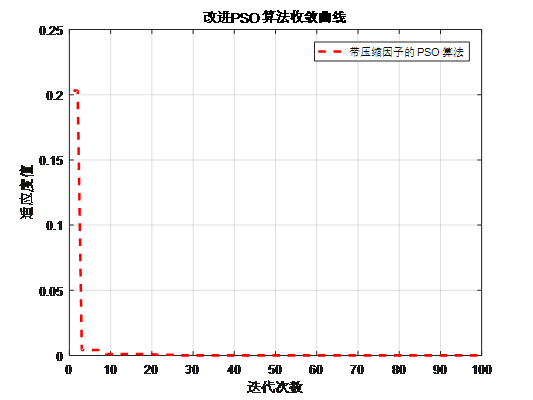
压缩因子 比惯性权重系数w更能有效地控制与约束微粒的飞行速度,同时也增强了算法的局部搜索能力。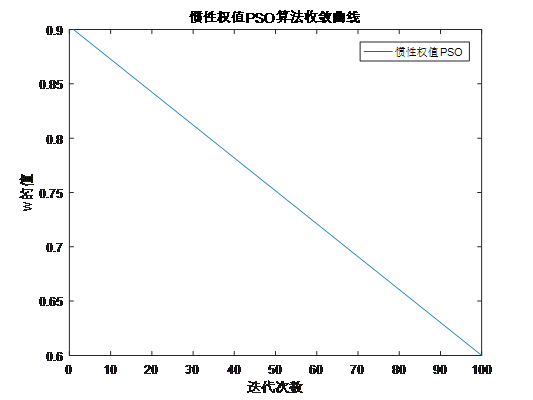
带压缩因子的的PSO算法适应度曲线
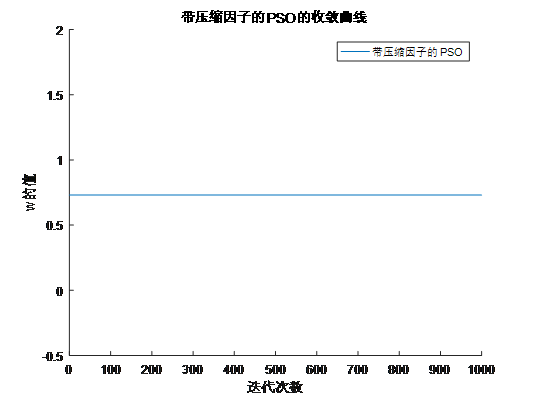
由上面两个图,可以看出惯性常数方法通常采用惯性权值随更新代数增加而递减的策略,在算法后期由于惯性权值过小,会失去微粒的探索新区域的能力,而压缩因子方法则不存在此不足。
**CONCLUTIONS**
PSO算法的搜索性能取决于其全局搜索与局部改良能力的平衡,这很大程度上依赖于算法的参数控制,包括N,Vmax,M,w,c1,c2等;
**微粒种群数目N**:N设置较小时,算法收敛速度快,但是容易陷入局部最优;N设置较大时,算法收敛速度相对较慢;导致计算时间大幅增加,而且群体数目N增至一定的水平时,再增加微粒数目不再有显著的效果。
参考取值:一般设N为10~50之间,对于比较复杂的问题,微粒数目N可以取100以上;
**最大速度Vmax**:决定搜索的力度;Vmax过大,粒子运动速度快,微粒探索能力强,但容易越过最优的搜索空间,错过最优解;如果Vmax较小,微粒的开发能力强,容易进入局部最优,可能会使微粒无法运动足够远的距离以跳出局部最优,从而也可能找不到解空间的最佳位置。(跟w的取值规则一样)。
**惯性权值w**:w越大,微粒飞行速度越大,微粒将会以更长的步长进行全局搜索;w较小,则微粒步长小,趋向于精细的局部搜索;因此,我们采用动态改变w的值;在搜索初期设w取一个较大值,然后随着迭代次数的不断增加,逐渐降低w的值;从而达到全局最优。
**ways**:随机调整,线性递减,非线性递减,模糊自适应。
**学习因子c1,c2**:c1,c2具有自我总结和向优秀个体学习的能力,从而使微粒向群体内或领域内的最优点靠近。c1,c2分别调节微粒向个体最优或者群体最优方向飞行的最大步长,决定微粒个体经验和群体经验对微粒自身运行轨迹的影响。学习因子较小时,可能使微粒在远离目标区域内徘徊;学习因子较大时,可使微粒迅速向目标区域移动,甚至超过目标区域。因此,c1和c2的搭配不同,将会影响到PSO算法的性能。
**ways**:一般令c1+c2=4;其实c1=2附近的迭代次数较小,在两个端点0和4附近的迭代次数较大,大致呈现出对称性;在俩端点处搜索失败率较大;通常,越接近端点,失败率越高。但并不是所有情况都是c1=c2=2时才有最优解。
r1,r2是[0,1]之间的随机数。
**最大迭代次数M**:算法停止迭代条件。
另外,随着变量范围和维数的增加,搜索空间呈几何级扩张,迭代次数相应增加,优化函数越复杂,所需的计算量越大,迭代次数也越多。
参数的选择影响算法的性能和效率,也是一个值得优化的问题。在实际应用中,没有选择参数的通用方法,只能凭经验选取。大量的仿真实验发现,参数对算法性能的影响有一定的规律可寻。例如:w=0.7298,c1=c2=1.49618是一组较为出色的参数组合。
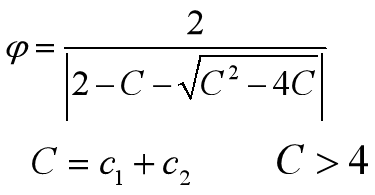
谢谢大家~~~~~~
欢迎大家和我一起讨论,一起进步。
有需求可联系本人邮箱qinwei1005@foxmail.com
PSO算法的改进(参数)的更多相关文章
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:非hash方法
http://blog.csdn.net/pipisorry/article/details/48914067 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- PSO算法
1.简介粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由Eberhart 博士和kennedy 博士提出,源于对鸟群捕食的行为研究 .该算 ...
- ISAP算法对 Dinic算法的改进
ISAP算法对 Dinic算法的改进: 在刘汝佳图论的开头引言里面,就指出了,算法的本身细节优化,是比较复杂的,这些高质量的图论算法是无数优秀算法设计师的智慧结晶. 如果一时半会理解不清楚,也是正常的 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- md5是哈希算法的改进加强,因为不同原始值可能hash结果一样,但md5则改善了用于验证消息完整性,不同md5值原始值也必将不一样
md5是哈希算法的改进加强,因为不同原始值可能hash结果一样,但md5则改善了用于验证消息完整性,不同md5值原始值也必将不一样
- 基本PSO算法实现(Java)
一.算法流程 Step1:初始化一群粒子(粒子个数为50个),包括随即位置和速度: Step2:计算每个粒子的适应度fitness: Step3:对每个粒子,将其适应度与其进过的最好位置(局部)pbe ...
- KMP算法的改进
KMP算法的改进 KMP算法已经在极大程度上提高了子符串的匹配效率,但是仍然有改进的余地. 1. 引入的情景 下面我们就其中的一种情况进行分析: 主串T为"aaaabcde-" 子 ...
- KMP算法(改进的模式匹配算法)——next函数
KMP算法简介 KMP算法是在基础的模式匹配算法的基础上进行改进得到的算法,改进之处在于:每当匹配过程中出现相比较的字符不相等时,不需要回退主串的字符位置指针,而是利用已经得到的部分匹配结果将模式串向 ...
随机推荐
- mac 安装secureCRT
下载 http://www.xue51.com/mac/1632.html 会得到下面的文件: 打开dmg文件: 将SecureCRT移到Applications中,然后点击打开一次(重要): 然后打 ...
- 鴻雁 Anser cygnoides
鴻雁 Anser cygnoides,其中 Anser 是屬名.雁屬的模式種是 Anser anser 灰雁,在中國也有分佈,但不如鴻雁和中國人關係密切.中國人所說的「大雁」一般指鴻雁,偶爾指灰雁或是 ...
- Kubernetes介绍
Kubernetes介绍 一.Kubernetes起源 Kubernetes (K8s) 是 Google 在 2014 年发布的一个开源项目. 据说 Google 的数据中心里运行着超过 20 ...
- SRcnn:神经网络重建图片的开山之作
% ========================================================================= % Test code for Super-Re ...
- Ext4文件系统架构分析(二)
接着上一篇博文,继续分析Ext4磁盘布局中的元数据. 1.7 超级块 超级块记录整个文件系统的大量信息,如数据块个数.inode个数.支持的特性.管理信息,等待. 如果设置sparse_super特性 ...
- 学习笔记——OS——引论
学习笔记--OS--引论 操作系统的定义 操作系统是一组管理计算机硬件资源的软件集合: 用户和计算机硬件之间的接口 控制和管理硬件资源 实现对计算机资源的抽象 计算机系统硬件 冯诺依曼体系结构和哈佛结 ...
- 修改通达oa数据库root密码
第一步: 打开通达oamysql远程网页地址:如http://127.0.0.1/mysql,点击修改密码功能按钮,根据提示修改,不要生成加密密码,执行即可! 第二步:修改service.php文件的 ...
- JavaScript中的数据属性和访问器属性
在学习JavaScript原型(prototype)和原型链(prototype chain)知识的时候,发现数据属性和访问器属性的重要性,通过不断的查找相关知识,浅显理解如下,若有差错,希望不吝赐教 ...
- SAP函数PREPARE_STRING:提取字符串中的数字
今天调整一个同事的需求时,要计算一个含税金额.报表内已经取到税率,但存在的形式是字符串格式:16%. 正好SAP内有一个标准函数:PREPARE_STRING 可以处理字符串,将特别标志替换为有效标志 ...
- #leetcode刷题之路18-四数之和
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满 ...