Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf
第六节: page级别的内存分配
前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进行内存分配的呢?这一小节带大家进行剖析:
剖析之前首先简单介绍netty内存分配的大概数据结构:
之前我们介绍过, netty内存分配的单位是chunk, 一个chunk的大小是16MB, 实际上每个chunk, 都以双向链表的形式保存在一个chunkList中, 而多个chunkList, 同样也是双向链表进行关联的, 大概结构如下所示:
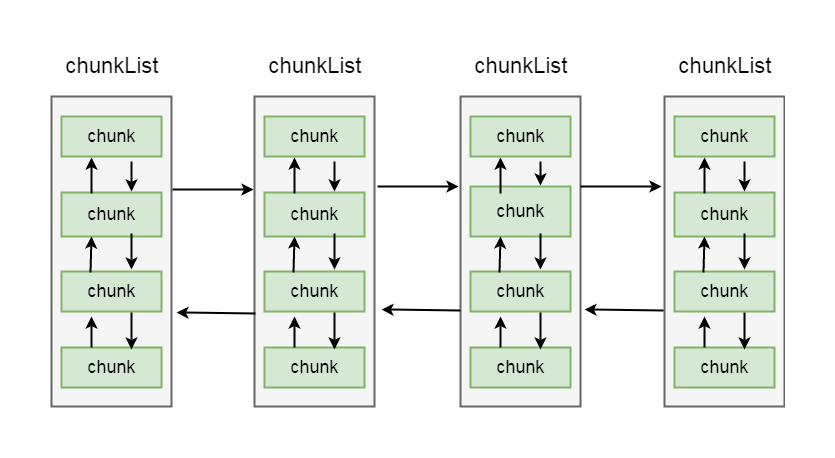
5-7-1
在chunkList中, 是根据chunk的内存使用率归到一个chunkList中, 这样, 在内存分配时, 会根据百分比找到相应的chunkList, 在chunkList中选择一个chunk进行内存分配
我们看PoolArena中有关chunkList的成员变量:
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;
这里总共定义了6个chunkList, 并在构造方法将其进行初始化
跟到其构造方法中:
protected PoolArena(PooledByteBufAllocator parent, int pageSize, int maxOrder, int pageShifts, int chunkSize) {
//代码省略
q100 = new PoolChunkList<T>(null, 100, Integer.MAX_VALUE, chunkSize);
q075 = new PoolChunkList<T>(q100, 75, 100, chunkSize);
q050 = new PoolChunkList<T>(q075, 50, 100, chunkSize);
q025 = new PoolChunkList<T>(q050, 25, 75, chunkSize);
q000 = new PoolChunkList<T>(q025, 1, 50, chunkSize);
qInit = new PoolChunkList<T>(q000, Integer.MIN_VALUE, 25, chunkSize);
//用双向链表的方式进行连接
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
//代码省略
}
首先通过new PoolChunkList()这种方式将每个chunkList进行创建, 我们以 q050 = new PoolChunkList<T>(q075, 50, 100, chunkSize) 为例进行简单的介绍
q075表示当前q50的下一个节点是q075, 刚才我们讲过ChunkList是通过双向链表进行关联的, 所以这里不难理解
参数50和100表示当前chunkList中存储的chunk的内存使用率都在50%到100%之间, 最后chunkSize为其设置大小
创建完ChunkList之后, 再设置其上一个节点, q050.prevList(q025)为例, 这里代表当前chunkList的上一个节点是q025
以这种方式创建完成之后, chunkList的节点关系变成了如下图所示:
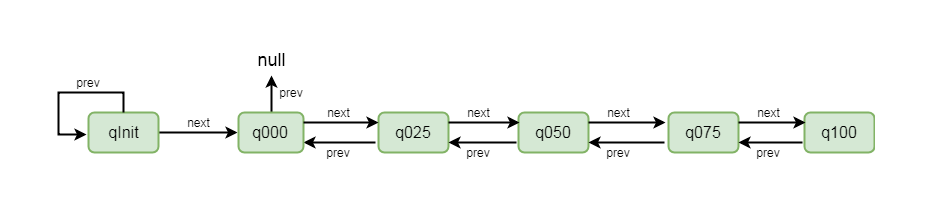
5-7-2
netty中, chunk又包含了多个page, 每个page的大小为8k, 如果要分配16k的内存, 则在在chunk中找到连续的两个page就可以分配, 对应关系如下:
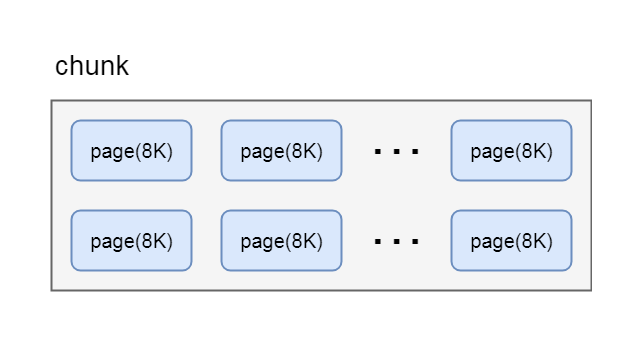
5-7-3
很多场景下, 为缓冲区分配8k的内存也是一种浪费, 比如只需要分配2k的缓冲区, 如果使用8k会造成6k的浪费, 这种情况, netty又会将page切分成多个subpage, 每个subpage大小要根据分配的缓冲区大小而指定, 比如要分配2k的内存, 就会将一个page切分成4个subpage, 每个subpage的大小为2k, 如图:

5-7-4
我们看PoolSubpage的属性:
final PoolChunk<T> chunk;
private final int memoryMapIdx;
private final int runOffset;
private final int pageSize;
private final long[] bitmap;
PoolSubpage<T> prev;
PoolSubpage<T> next;
boolean doNotDestroy;
int elemSize;
chunk代表其子页属于哪个chunk
bitmap用于记录子页的内存分配情况
prev和next, 代表子页是按照双向链表进行关联的, 这里分别指向上一个和下一个节点
elemSize属性, 代表的就是这个子页是按照多大内存进行划分的, 如果按照1k划分, 则可以划分出8个子页
简单介绍了内存分配的数据结构, 我们开始剖析netty在page级别上分配内存的流程:
我们回到PoolArena的allocate方法:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
//规格化
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) {
int tableIdx;
PoolSubpage<T>[] table;
//判断是不是tinty
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
//缓存分配
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
return;
}
//通过tinyIdx拿到tableIdx
tableIdx = tinyIdx(normCapacity);
//subpage的数组
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
//拿到对应的节点
final PoolSubpage<T> head = table[tableIdx];
synchronized (head) {
final PoolSubpage<T> s = head.next;
//默认情况下, head的next也是自身
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
if (tiny) {
allocationsTiny.increment();
} else {
allocationsSmall.increment();
}
return;
}
}
allocateNormal(buf, reqCapacity, normCapacity);
return;
}
if (normCapacity <= chunkSize) {
//首先在缓存上进行内存分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
//分配成功, 返回
return;
}
//分配不成功, 做实际的内存分配
allocateNormal(buf, reqCapacity, normCapacity);
} else {
//大于这个值, 就不在缓存上分配
allocateHuge(buf, reqCapacity);
}
}
我们之前讲过, 如果在缓存中分配不成功, 则会开辟一块连续的内存进行缓冲区分配, 这里我们先跳过isTinyOrSmall(normCapacity)往后的代码, 下一小节进行分析
首先 if (normCapacity <= chunkSize) 说明其小于16MB, 然后首先在缓存中分配, 因为最初缓存中没有值, 所以会走到allocateNormal(buf, reqCapacity, normCapacity), 这里实际上就是在page级别上进行分配, 分配一个或者多个page的空间
我们跟进allocateNormal:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//首先在原来的chunk上进行内存分配(1)
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
//创建chunk进行内存分配(2)
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > 0;
//初始化byteBuf(3)
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}
这里主要拆解了如下步骤
1. 在原有的chunk中进行分配
2. 创建chunk进行分配
3. 初始化ByteBuf
首先我们看第一步, 在原有的chunk中进行分配:
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
我们之前讲过, chunkList是存储不同内存使用量的chunk集合, 每个chunkList通过双向链表的形式进行关联, 这里的q050.allocate(buf, reqCapacity, normCapacity)就代表首先在q050这个chunkList上进行内存分配
我们以q050为例进行分析, 跟到q050.allocate(buf, reqCapacity, normCapacity)方法中:
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (head == null || normCapacity > maxCapacity) {
return false;
}
//从head节点往下遍历
for (PoolChunk<T> cur = head;;) {
long handle = cur.allocate(normCapacity);
if (handle < 0) {
cur = cur.next;
if (cur == null) {
return false;
}
} else {
cur.initBuf(buf, handle, reqCapacity);
if (cur.usage() >= maxUsage) {
remove(cur);
nextList.add(cur);
}
return true;
}
}
}
首先会从head节点往下遍历
long handle = cur.allocate(normCapacity) 表示对于每个chunk, 都尝试去分配
if (handle < 0) 说明没有分配到, 则通过cur = cur.next找到下一个节点继续进行分配, 我们讲过chunk也是通过双向链表进行关联的, 所以对这块逻辑应该不会陌生
如果handle大于0说明已经分配到了内存, 则通过cur.initBuf(buf, handle, reqCapacity)对byteBuf进行初始化
if (cur.usage() >= maxUsage) 代表当前chunk的内存使用率大于其最大使用率, 则通过remove(cur)从当前的chunkList中移除, 再通过nextList.add(cur)添加到下一个chunkList中
我们再回到PoolArena的allocateNormal方法中:
我们看第二步PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize)
这里的参数pageSize是8192, 也就是8k
maxOrder为11
pageShifts为13, 2的13次方正好是8192, 也就是8k
chunkSize为16777216, 也就是16MB
这里的参数值可以通过debug的方式跟踪到
因为我们的示例是堆外内存, newChunk(pageSize, maxOrder, pageShifts, chunkSize)所以会走到DirectArena的newChunk方法中:
protected PoolChunk<ByteBuffer> newChunk(int pageSize, int maxOrder, int pageShifts, int chunkSize) {
return new PoolChunk<ByteBuffer>(
this, allocateDirect(chunkSize),
pageSize, maxOrder, pageShifts, chunkSize);
}
这里直接通过构造函数创建了一个chunk
allocateDirect(chunkSize)这里是通过jdk的api的申请了一块直接内存, 我们跟到PoolChunk的构造函数中:
PoolChunk(PoolArena<T> arena, T memory, int pageSize, int maxOrder, int pageShifts, int chunkSize) {
unpooled = false;
this.arena = arena;
//memeory为一个ByteBuf
this.memory = memory;
//8k
this.pageSize = pageSize;
//
this.pageShifts = pageShifts;
//
this.maxOrder = maxOrder;
this.chunkSize = chunkSize;
unusable = (byte) (maxOrder + 1);
log2ChunkSize = log2(chunkSize);
subpageOverflowMask = ~(pageSize - 1);
freeBytes = chunkSize;
assert maxOrder < 30 : "maxOrder should be < 30, but is: " + maxOrder;
maxSubpageAllocs = 1 << maxOrder;
//节点数量为4096
memoryMap = new byte[maxSubpageAllocs << 1];
//也是4096个节点
depthMap = new byte[memoryMap.length];
int memoryMapIndex = 1;
//d相当于一个深度, 赋值的内容代表当前节点的深度
for (int d = 0; d <= maxOrder; ++ d) {
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
subpages = newSubpageArray(maxSubpageAllocs);
}
首先将参数传入的值进行赋值
this.memory = memory 就是将参数中创建的堆外内存进行保存, 就是chunk所指向的那块连续的内存, 在这个chunk中所分配的ByteBuf, 都会在这块内存中进行读写
我们重点关注 memoryMap = new byte[maxSubpageAllocs << 1] 和 depthMap = new byte[memoryMap.length] 这两步
首先看 memoryMap = new byte[maxSubpageAllocs << 1]
这里初始化了一个字节数组memoryMap, 大小为maxSubpageAllocs << 1, 也就是4096
depthMap = new byte[memoryMap.length] 同样也是初始化了一个字节数组, 大小为memoryMap的大小, 也就是4096
继续往下分析之前, 我们看chunk的一个层级关系

5-7-5
这是一个二叉树的结构, 左侧的数字代表层级, 右侧代表一块连续的内存, 每个父节点下又拆分成多个子节点, 最顶层表示的内存范围为0-16MB, 其又下分为两层, 范围为0-8MB, 8-16MB, 以此类推, 最后到11层, 以8k的大小划分, 也就是一个page的大小
如果我们分配一个8mb的缓冲区, 则会将第二层的第一个节点, 也就是0-8这个连续的内存进行分配, 分配完成之后, 会将这个节点设置为不可用, 具体逻辑后面会讲解
结合上面的图, 我们再看构造方法中的for循环:
for (int d = 0; d <= maxOrder; ++ d) {
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
实际上这个for循环就是将上面的结构包装成一个字节数组memoryMap, 外层循环用于控制层数, 内层循环用于控制里面每层的节点, 这里经过循环之后, memoryMap和depthMap内容为以下表现形式:
[0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4...........]
这里注意一下, 因为程序中数组的下标是从1开始设置的, 所以第零个节点元素为默认值0
这里数字代表层级, 同时也代表了当前层级的节点, 相同的数字个数就是这一层级的节点数
其中0为2个(因为这里分配时下标是从1开始的, 所以第0个位置是默认值0, 实际上第零层元素只有一个, 就是头结点), 1为2个, 2为4个, 3为8个, 4为16个, n为2的n次方个, 直到11, 也就是11有2的11次方个
我们再回到PoolArena的allocateNormal方法中:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//首先在原来的chunk上进行内存分配(1)
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
//创建chunk进行内存分配(2)
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > 0;
//初始化byteBuf(3)
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}
我们继续剖析 long handle = c.allocate(normCapacity) 这步
跟到allocate(normCapacity)中:
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) {
return allocateRun(normCapacity);
} else {
return allocateSubpage(normCapacity);
}
}
如果分配是以page为单位, 则走到allocateRun(normCapacity)方法中, 跟进去:
private long allocateRun(int normCapacity) {
int d = maxOrder - (log2(normCapacity) - pageShifts);
int id = allocateNode(d);
if (id < 0) {
return id;
}
freeBytes -= runLength(id);
return id;
}
int d = maxOrder - (log2(normCapacity) - pageShifts) 表示根据normCapacity计算出图5-8-5中的第几层
int id = allocateNode(d) 表示根据层级关系, 去分配一个节点, 其中id代表memoryMap中的下标
我们跟到allocateNode方法中:
private int allocateNode(int d) {
//下标初始值为1
int id = 1;
//代表当前层级第一个节点的初始下标
int initial = - (1 << d);
//获取第一个节点的值
byte val = value(id);
//如果值大于层级, 说明chunk不可用
if (val > d) {
return -1;
}
//当前下标对应的节点值如果小于层级, 或者当前下标小于层级的初始下标
while (val < d || (id & initial) == 0) {
//当前下标乘以2, 代表下当前节点的子节点的起始位置
id <<= 1;
//获得id位置的值
val = value(id);
//如果当前节点值大于层数(节点不可用)
if (val > d) {
//id为偶数则+1, id为奇数则-1(拿的是其兄弟节点)
id ^= 1;
//获取id的值
val = value(id);
}
}
byte value = value(id);
assert value == d && (id & initial) == 1 << d : String.format("val = %d, id & initial = %d, d = %d",
value, id & initial, d);
//将找到的节点设置为不可用
setValue(id, unusable);
//逐层往上标记被使用
updateParentsAlloc(id);
return id;
}
这里是实际上是从第一个节点往下找, 找到层级为d未被使用的节点, 我们可以通过注释体会其逻辑
找到相关节点后通过setValue将当前节点设置为不可用, 其中id是当前节点的下标, unusable代表一个不可用的值, 这里是12, 因为我们的层级只有12层, 所以设置为12之后就相当于标记不可用
设置成不可用之后, 通过updateParentsAlloc(id)逐层设置为被使用
我们跟进updateParentsAlloc方法:
private void updateParentsAlloc(int id) {
while (id > 1) {
//取到当前节点的父节点的id
int parentId = id >>> 1;
//获取当前节点的值
byte val1 = value(id);
//找到当前节点的兄弟节点
byte val2 = value(id ^ 1);
//如果当前节点值小于兄弟节点, 则保存当前节点值到val, 否则, 保存兄弟节点值到val
//如果当前节点是不可用, 则当前节点值是12, 大于兄弟节点的值, 所以这里将兄弟节点的值进行保存
byte val = val1 < val2 ? val1 : val2;
//将val的值设置为父节点下标所对应的值
setValue(parentId, val);
//id设置为父节点id, 继续循环
id = parentId;
}
}
这里其实是将循环将兄弟节点的值替换成父节点的值, 我们可以通过注释仔细的进行逻辑分析
如果实在理解有困难, 我通过画图帮助大家理解:
简单起见, 我们这里只设置三层:

5-7-6
这里我们模拟其分配场景, 假设只有三层, 其中index代表数组memoryMap的下标, value代表其值, memoryMap中的值就为[0, 0, 1, 1, 2, 2, 2, 2]
我们要分配一个4MB的byteBuf, 在我们调用allocateNode(int d)中传入的d是2, 也就是第二层
根据我们上面分分析的逻辑这里会找到第二层的第一个节点, 也就是0-4mb这个节点, 找到之后将其设置为不可用, 这样memoryMap中的值就为[0, 0, 1, 1, 12, 2, 2, 2]
二叉树的结构就会变为:

5-7-7
注意标红部分, 将index为4的节点设置为了不可用
将这个节点设置为不可用之后, 则会将进行向上设置不可用, 循环将兄弟节点数值较小的节点替换到父节点, 也就是将index为2的节点的值替换成了index的为5的节点的值, 这样数组的值就会变为[0, 1, 2, 1, 12, 2, 2, 2]
二叉树的结构变为:
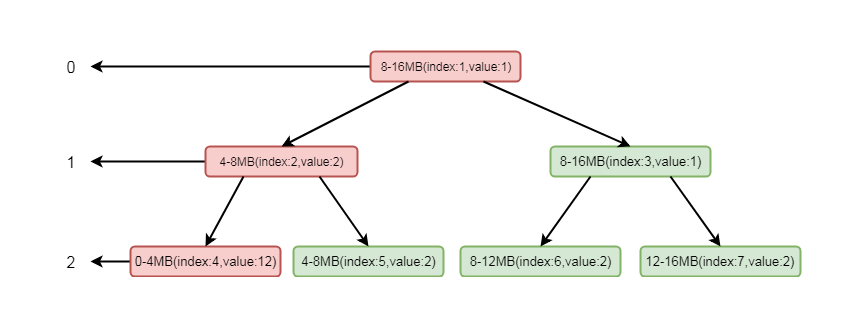
5-7-8
注意, 这里节点标红仅仅代表节点变化, 并不是当前节点为不可用状态, 真正不可用状态的判断依据是value值为12
这样, 如果再次分配一个4MB内存的ByteBuf, 根据其逻辑, 则会找到第二层的第二个节点, 也就是4-8MB
再根据我们的逻辑, 通过向上设置不可用, index为2就会设置成不可用状态, 将value的值设置为12, 数组数值变为[0, 1, 12, 1, 12, 12, 2, 2]二叉树如下图所示:
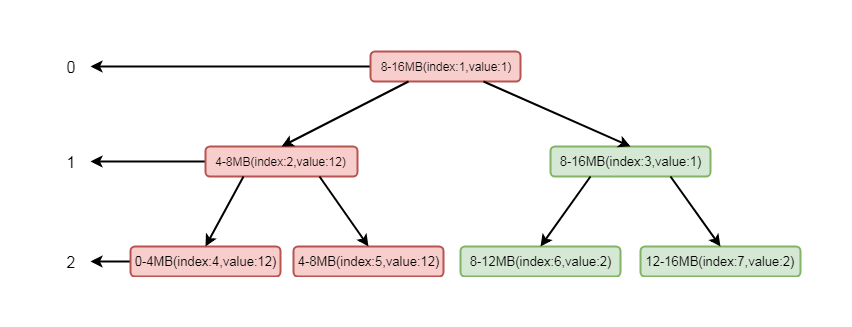
5-7-9
这样我们看到, 通过分配两个4mb的byteBuf之后, 当前节点和其父节点都会设置成不可用状态, 当index=2的节点设置为不可用之后, 将不会再找这个节点下的子节点
以此类推, 直到所有的内存分配完毕的时候, index为1的节点, 也会变成不可用状态, 这样所有的page就分配完毕, chunk中再无可用节点
我们再回到PoolArena的allocateNormal方法中:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//首先在原来的chunk上进行内存分配(1)
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
//创建chunk进行内存分配(2)
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > 0;
//初始化byteBuf(3)
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}
通过以上逻辑我们知道, long handle = c.allocate(normCapacity)这一步, 其实返回的就是memoryMap的一个下标, 通过这个下标, 我们能唯一的定位一块内存
继续往下跟, 通过c.initBuf(buf, handle, reqCapacity)初始化ByteBuf之后, 通过qInit.add(c)将新创建的chunk添加到chunkList中
我们跟到initBuf方法中去:
void initBuf(PooledByteBuf<T> buf, long handle, int reqCapacity) {
int memoryMapIdx = memoryMapIdx(handle);
int bitmapIdx = bitmapIdx(handle);
if (bitmapIdx == 0) {
byte val = value(memoryMapIdx);
assert val == unusable : String.valueOf(val);
buf.init(this, handle, runOffset(memoryMapIdx), reqCapacity, runLength(memoryMapIdx),
arena.parent.threadCache());
} else {
initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity);
}
}
这里通过memoryMapIdx(handle)找到memoryMap的下标, 其实就是handle的值
bitmapIdx(handle)是有关subPage中使用到的逻辑, 如果是page级别的分配, 这里只返回0, 所以进入到if块中
if中首先断言当前节点是不是不可用状态, 然后通过init方法进行初始化
其中runOffset(memoryMapIdx)表示偏移量, 偏移量相当于分配给缓冲区的这块内存相对于chunk中申请的内存的首地址偏移了多少
参数runLength(memoryMapIdx), 表示根据下标获取可分配的最大长度
我们跟到init中, 这里会走到PooledByteBuf的init方法中:
void init(PoolChunk<T> chunk, long handle, int offset, int length, int maxLength, PoolThreadCache cache) {
//初始化
assert handle >= 0;
assert chunk != null;
//在哪一块内存上进行分配的
this.chunk = chunk;
//这一块内存上的哪一块连续内存
this.handle = handle;
memory = chunk.memory;
this.offset = offset;
this.length = length;
this.maxLength = maxLength;
tmpNioBuf = null;
this.cache = cache;
}
这里又是我们熟悉的部分, 将属性进行了初始化
以上就是完整的DirectUnsafePooledByteBuf在page级别的完整分配的流程, 逻辑也是非常的复杂, 想真正的掌握熟练, 也需要多下功夫进行调试和剖析
Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配的更多相关文章
- Netty源码分析第5章(ByteBuf)---->第8节: subPage级别的内存分配
Netty源码分析第五章: ByteBuf 第八节: subPage级别的内存分配 上一小节我们剖析了page级别的内存分配逻辑, 这一小节带大家剖析有关subPage级别的内存分配 通过之前的学习我 ...
- Netty源码分析第5章(ByteBuf)---->第4节: PooledByteBufAllocator简述
Netty源码分析第五章: ByteBuf 第四节: PooledByteBufAllocator简述 上一小节简单介绍了ByteBufAllocator以及其子类UnPooledByteBufAll ...
- Netty源码分析第5章(ByteBuf)---->第5节: directArena分配缓冲区概述
Netty源码分析第五章: ByteBuf 第五节: directArena分配缓冲区概述 上一小节简单分析了PooledByteBufAllocator中, 线程局部缓存和arean的相关逻辑, 这 ...
- Netty源码分析第5章(ByteBuf)---->第6节: 命中缓存的分配
Netty源码分析第6章: ByteBuf 第六节: 命中缓存的分配 上一小节简单分析了directArena内存分配大概流程, 知道其先命中缓存, 如果命中不到, 则区分配一款连续内存, 这一小节带 ...
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- Netty源码分析第5章(ByteBuf)---->第1节: AbstractByteBuf
Netty源码分析第五章: ByteBuf 概述: 熟悉Nio的小伙伴应该对jdk底层byteBuffer不会陌生, 也就是字节缓冲区, 主要用于对网络底层io进行读写, 当channel中有数据时, ...
- Netty源码分析第5章(ByteBuf)---->第2节: ByteBuf的分类
Netty源码分析第五章: ByteBuf 第二节: ByteBuf的分类 上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍 ByteBuf根据不同 ...
- Netty源码分析第5章(ByteBuf)---->第3节: 缓冲区分配器
Netty源码分析第五章: ByteBuf 第三节: 缓冲区分配器 缓冲区分配器, 顾明思议就是分配缓冲区的工具, 在netty中, 缓冲区分配器的顶级抽象是接口ByteBufAllocator, 里 ...
- Netty源码分析第5章(ByteBuf)---->第9节: ByteBuf回收
Netty源码分析第五章: ByteBuf 第九节: ByteBuf回收 之前的章节我们提到过, 堆外内存是不受jvm垃圾回收机制控制的, 所以我们分配一块堆外内存进行ByteBuf操作时, 使用完毕 ...
随机推荐
- libextobjc 实现的 defer
算法沉思录:分而治之(复用): 分而治之是指把大而复杂的问题分解成若干个简单的小问题,然后逐个解决.这种朴素的思想来源于人们生活与工作的经验,也完全适合于技术领域. 要崩溃的节奏: 要崩溃的节奏: V ...
- [SDOI2010]Hide and Seek
题目 非常显然就是求一下距离每一个点曼哈顿距离最近的点和最远的点就好了 最远点非常好算,我们建完\(kd-tree\)之后直接暴力就好了 找最近点的时候会有这样一个问题,就是自己找到了自己 所以我们需 ...
- ResultJsonInfo<T>
using System; using System.Collections.Generic; using System.Linq; using System.Web; namespace QY.We ...
- Java反射学习四
利用反射调用私有方法.访问私有属性 利用反射,首先是Class对象的获取,之后是Method和Field对象的获取. 以Method为例,从文档中可以看到: getMethod()方法返回的是publ ...
- Python中乘法
1.numpy乘法运算中"*"或multiply(),是数组元素逐个计算,具体代码如下: import numpy as np # 2-D array: 2 x 3 two_dim ...
- C语言程序设计I—第八周教学
第八周教学总结(21/10-27/10) 教学内容 第三章 分支结构 3.1 简单的猜数游戏 3.2 四则运算 课前准备 在蓝墨云班课发布资源:chap03_分支结构.pptx PTA:2018秋第八 ...
- cloudstack 添加新网卡使其能上网
由于虚拟机使用了默认的网络套餐,是不能上网的.现在的需求是使其能上网. 操作步骤: 1.添加一个在能上网的网络里的网卡,使其成为默认网卡 2.复制网卡配置文件,修改网卡名称等,重启network(可能 ...
- 洛谷P4245 【模板】MTT(任意模数NTT)
题目背景 模板题,无背景 题目描述 给定 22 个多项式 F(x), G(x)F(x),G(x) ,请求出 F(x) * G(x)F(x)∗G(x) . 系数对 pp 取模,且不保证 pp 可以分解成 ...
- [外观] Firemonkey Windows Hint 气球样式
Firemonkey 在 Windows 平台下的 Hint 默认为距形,有些单调,现在只要加入一行代码,就可以有气球箭头样式的 Hint. 修改代码: 请将 FMX.Controls.Win.pas ...
- Ubuntu18.04编译S3的Linux SDK(Zeta)
按照S3官方Wiki(http://www.sochip.com.cn/s3)的陈述,推荐使用Ubuntu16.04作为Host端系统,笔者是一名乐于并热衷于尝鲜的搬砖工,于是,尝试在最新的18.04 ...