mongo 索引,速度
(如有打扰,请忽略)阿里云ECS大羊群,2U4G低至1.4折,限实名新用户,需要的点吧https://promotion.aliyun.com/ntms/act/vm/aliyun-group/team.html?group=YrliaeMVUn
数据库索引与书籍的索引类似,有了索引就不需要翻整本书,数据库可以直接在索引中查找,在索引中找到条目后,就可以直接跳到目标文档的位置,这可以让查找的速度提高几个数量级。
一、创建索引
我们在person这个集合的age键上创建一个索引,比较一下创建索引前后,一个查询的语句的性能区别。
创建索引:db.person.ensureIndex({"age":1})。这里我们使用了ensureIndex在age上建立了索引。“1”:表示按照age进行升序,“-1”:表示按照age进行降序。
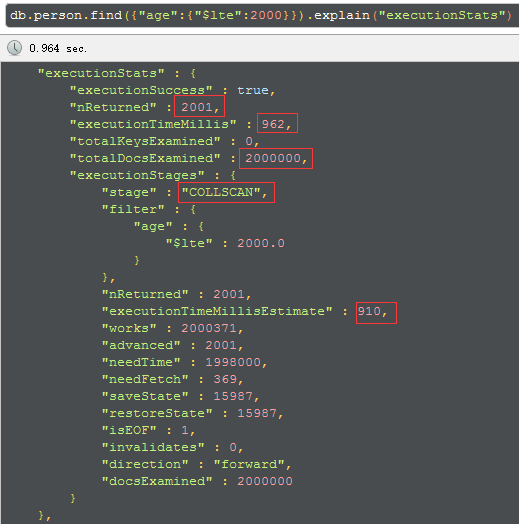
没有索引的查询性能:
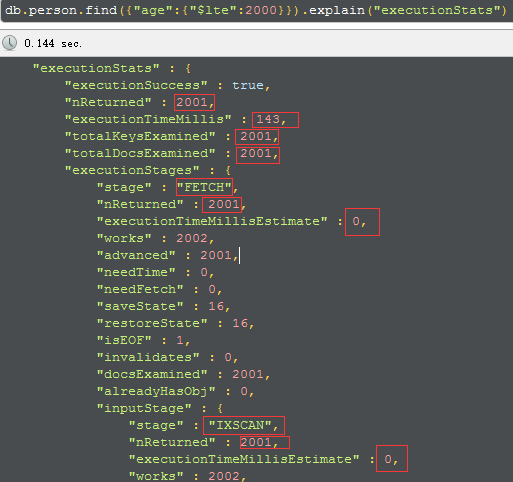
有索引的查询性能:
我们主要来看这几个参数,(参数说明,请看上一篇文章)
executionTimeMillis(这次query整体的耗时):无索引耗时962毫秒 ;有索引耗时143毫秒。
totalDocsExamined(文档扫描条目):无索引是200万条;有索引是2000条。
stage(查询的类型):无索引是COLLSCAN(全表扫描);有索引是FETCH+IXSCAN(索引扫描+根据索引去检索指定document)。
executionStages.executionTimeMillisEstimate(检索document获得数据的耗时):无索引耗时910毫秒;有索引耗时0毫秒。
建好索引后,这个query整体的速度提高了1个数量级 (1个数量级是10倍的意思)。根据查询语句的不同,索引可以使速度提高几个数量级。
二、复合索引
在多个键上建立的索引就是复合索引,有时候我们的查询不是单条件的,可能是多条件,比如查找年龄在20~30名字叫‘ryan1’的同学,那么我们可以建立“age”和“name”的联合索引来加速查询。
为了演示索引的效果,我们来重新生成插入一份200万个文档的集合。
按 Ctrl+C 复制代码 按 Ctrl+C 复制代码
我们可以用hint()方法来强制查询走哪个索引。
我们来看一下,当查询条件是多个的时候,复合索引相比单键索引的强大魅力。
db.person.find({"age":{"$gte":20,"$lte":30},"name":"ryan1"}).hint({"age":1}).explain("executionStats");

1 {
2 ...
3 "executionStats" : {
4 "executionSuccess" : true,
5 "nReturned" : 2000,
6 "executionTimeMillis" : 2031,
7 "totalKeysExamined" : 2000000,
8 "totalDocsExamined" : 2000000,
9 ...
10 }
db.person.find({"age":{"$gte":20,"$lte":30},"name":"ryan1"}).hint({"age":1,"name":1}).explain("executionStats");
1 {
2 ...
3 "executionStats" : {
4 "executionSuccess" : true,
5 "nReturned" : 2000,
6 "executionTimeMillis" : 8,
7 "totalKeysExamined" : 2010,
8 "totalDocsExamined" : 2000,
9 ...
10 }
从executionTimeMillis的值上,一眼就可以看出却别。单间索引耗费了2031毫秒,复合索引用了8毫秒。 由此我们可以看出,根据查询语句的不同,建立正确的索引是非常重要的,对于查询语句中是多条件的,应多考虑复合索引的应用。
下面,我们再说一种复合索引的重要应用情况。有对一个键排序并只要前100个结果的情景(实际项目中经常都是这种情景)。对于这种情况,索引应该这样建{"sortKey":1,"queryCriteria":1},排序的键应该放在复合索引的第一位。
db.person.find({"age":{"$gte":21.0,"$lte":30.0}}).sort({"name":1}).limit(100).hint({"age":1,"name":1}).explain("executionStats");
1 {
2 ...
3 "executionStats" : {
4 "executionSuccess" : true,
5 "nReturned" : 100,
6 "executionTimeMillis" : 6882,
7 "totalKeysExamined" : 1800000,
8 "totalDocsExamined" : 1800000,
9 ...
10 }
db.person.find({"age":{"$gte":21.0,"$lte":30.0}}).sort({"name":1}).limit(100).hint({"name":1,"age":1}).explain("executionStats");
1 {
2 ...
3 "executionStats" : {
4 "executionSuccess" : true,
5 "nReturned" : 100,
6 "executionTimeMillis" : 3,
7 "totalKeysExamined" : 2100,
8 "totalDocsExamined" : 2100,
9 ...
10 }
从上面的结果,我们很容易看出,基于排序键的索引,效果非常好。
分析:第一种索引,需要找到所有复合查询条件的值(依据索引,键和文档可以快速找到),但是找到后,需要对文档在内存中进行排序,这个步骤消耗了非常多的时间。第二种索引,效果非常好,因为不需要在内存中对大量数据进行排序。但是,MongoDB不得不扫描整个索引以便找到所有文档。因此,如果对查询结果的范围做了限制,那么MongoDB在几次匹配之后就可以不再扫描索引,在这种情况下,将排序键放在第一位是一个非常好的策略。
三、唯一索引
唯一索引可以确保集合的每个文档的指定键都有唯一值。如果想保证不同文档的“name”键拥有不同的值,在“name”键上创建一个唯一索引就可以了。
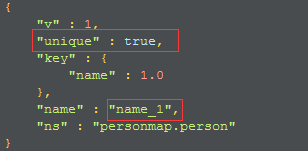
db.person.ensureIndex({"name":1},{"unique":true});
然后用db.person.getIndexes()命令,查看目前person集合所有的索引。
也可以创建复合的唯一索引。创建复合唯一索引时,单个键的值可以相同,但所有键的组合值必须是唯一的。
db.person.ensureIndex({"name":1,"age":1},{"unique":true});

四、稀疏索引
唯一索引会把null看作值,所以无法将多个缺少唯一索引中的键的文档插入到集合中。然而,在有些情况下,你可能希望唯一索引只对包含相应键的文档生效。这个时候我们可以用到MongoDB中的稀疏索引。该索引与关系型数据库中的稀疏索引是完全不同的概念。MongoDB中的稀疏索引只是不需要将每个文档都作为索引条目。
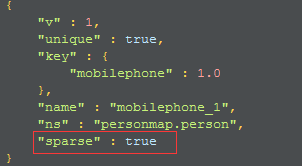
比如,如果有一个可选的mobilephone字段,但是,如果提供了这个字段,那么它的值必须是唯一的:
db.person.ensureIndex({"mobilephone":1}{"unique":true,"sparse":true});
稀疏索引不必是唯一的。只要去掉unique选项,就可以创建一个非唯一的稀疏索引。
五、索引管理
如第一小节所述,可以使用ensureIndex方法创建新的索引,也可以使用createIndex方法。
创建一个索引之后,可以利用getIndexes()方法来查看给定集合上的所有索引的信息。
db.person.getIndexes();
随着业务的不断变化,你可能会发现数据或者查询已经发生了改变,原来的索引也不那么好用了。这时可以使用dropIndex()方法删除不需要的索引:
db.person.dropIndex("name_1");//删除索引名为name_1的索引。
mongo 索引,速度的更多相关文章
- 使用Mongo索引需要注意的几个点
1.正则表达式和取反运算符不适合建立索引 正则表达式:$regex 取反运算符:$ne ,$nin 2.backgroud建立索引速度缓慢 前台创建是会有阻塞,backgroud效率缓慢,实际情况实际 ...
- IDEA 出现 updating indices 卡进度条问题的解决方案并加快索引速度
缺点: 这样的话,前端的接口(也就是字符串)就搜索不到了. C:\Users\Administrator\.IntelliJIdea2017.3\system 删除里面的caches文件夹(这里的 ...
- mongo: 索引
索引创建 在学习索引之前,我们先看一下,如果没有添加索引时,我们用explain()函数,查看查询计划是什么样的. 发现使用的是BasicCursor,那么就代表我们没有索引,当我们查某一个数据的时候 ...
- Lucene.net(4.8.0) 学习问题记录三: 索引的创建 IndexWriter 和索引速度的优化
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- mongo 索引 安全、备份与恢复
一.索引 创建大量数据 for(i=0;i<100000;i++){ db.t1.insert({name:"test"+i,age:i}) } 数据查找性能分析 db.t1 ...
- Mongo索引学习笔记
索引使用场景 优:加快查询速度 劣:增删改会产生额外的开销.占用空间 tips: 返回集合中一半以上的数据,全表扫描的效率高 索引基础 基础操作 查看索引:db.test.getIndexes() 创 ...
- mongo索引
索引自动创建和手工创建 db.stu.drop(); db.stu.insert({"name":"张三","sex":"男&qu ...
- python 【pandas】读取excel、csv数据,提高索引速度
问题描述:数据处理,尤其是遇到大量数据且需要for循环处理时,需要消耗大量时间,如代码1所示.通过data['trip_time'][i]的方式会占用大量的时间 代码1 import time t0= ...
- mongo索引命令
http://blog.csdn.net/salmonellavaccine/article/details/53907535 1. 创建/重建索引 MongoDB全新创建索引使用ensureInde ...
随机推荐
- Unicode UTF-8 UTF-16的关系
以下仅为个人学习的记录,如有疏漏不妥之处,还请不吝赐教. 关系 Unicode是一个字符集.顾名思义,字符的集合.GBK,BIG5,ISO8859-1,ASCII都是字符集. 有一点不同的是,Unic ...
- shadows
http://blog.51cto.com/11975865/2308030 https://www.jianshu.com/p/247cdbabf389 https://baijiahao.baid ...
- CSDN不登录阅读全文(最新更新
CSDN真的烦...然而没卵用 用stylus加两行css就行了: .article_content{height:auto!important} .hide-article-box{display: ...
- Learning-Python【2】:简单介绍Python基本数据类型及程序交互
人类可以很容易的分清数字与字符的区别,但是计算机并不能,计算机虽然很强大,但在某些方面很笨,你得明确的告诉它,“1”是数字,“我”是文字.否则计算机是分不清的.因此,在每个编程语言中都会有数据类型的概 ...
- FI 创建资产接口AS01
FUNCTION ZREIP_CREATE_AS01TSET. *"------------------------------------------------------------- ...
- _pet
可以控制各职业召唤物的属性.用于增强BB `comment` 备注 `classIndex` 职业序号 `DmgAddPct` 宠物伤害倍率 `SpAddPct` 法术伤害 `HpAddPct`血量倍 ...
- sqlserver数据库中sql的使用
目录: 1. 分组排序更新 2. 将查询结果插入到新的表中 3. 创建/更新存储过程 4. 创建/更新视图 5. 插入数据 6. 增加表格的列 7. 创建表格 8. 创建索引 9. 递归查询 1. 分 ...
- C#时间戳的简单实现
Introduction: 在项目开发中,我们都经常会用到时间戳来进行时间的存储和传递,最常用的Unix时间戳(TimeStamp)是指格林尼治时间1970年1月1日0时(北京时间1970年1月1日8 ...
- spring整合junit报错
1.Could not autowire field: private javax.servlet.http.HttpServletRequest 参考:https://www.cnblogs.com ...
- 在win上配置linux虚拟机图解
首先,先下载安装vmware,cpu的类型不支持AMD. 一直点下一步完成安装.