Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)
本次此时是在SPARK2,3 structured streaming下测试,不过这种方案,在spark2.2 structured streaming下应该也可行(请自行测试)。以下是我测试结果:
成功测试结果:
准备工作:创建maven项目,并在pom.xml导入一下依赖配置:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.3.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<!--Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
第一步:LoadResourceManager.java是一个对broadcast类进行管理的类,
包含了以下方法:
1)unpersist()方法:对LoadResourceManager对象的broadcast属性进行清理;
2)load(SparkSession spark, LongAccumulator loadCountAccumulator)方法:实现对broadcast对象属性broadcast的初始化赋值;
3)get()方法:返回LoadResourceManager对象的broadcast属性值。
注意:该LoadResourceManager 类必须实现Serializable接口,否则会抛出不可序列化异常。
class LoadResourceManager implements Serializable {
private static final long serialVersionUID = 7896720904164793792L;
private volatile Broadcast<Map<String, String>> broadcast = null;
public Broadcast<Map<String, String>> get() {
return broadcast;
}
public void unpersist() {
broadcast.unpersist(true);
//broadcast.destory(); 不能调用该方法,否则会抛出异常:Attempted to use Broadcast(x) after it was destroyed
}
public void load(SparkSession spark, LongAccumulator loadCountAccumulator) {
loadCountAccumulator.add(1);
int val = new Random().nextInt(100);
// 这里可以添加时间判断是否重新加载
Map<String, String> innerMap = new HashMap<String, String>(10);
innerMap.put("1", "1," + val);
innerMap.put("2", "2," + val);
innerMap.put("3", "3," + val);
innerMap.put("4", "4," + val);
innerMap.put("5", "5," + val);
innerMap.put("6", "6," + val);
innerMap.put("7", "7," + val);
innerMap.put("8", "8," + val);
innerMap.put("9", "9," + val);
innerMap.put("10", "10," + val);
System.out.println("the value is :" + val);
JavaSparkContext jsc = JavaSparkContext.fromSparkContext(spark.sparkContext());
broadcast = jsc.broadcast(innerMap);
}
}
第二步:自定义StreamingQueryListener类MyStreamingQueryListener.java
该类是spark.streams().addListener(new MyStreamingQueryListener(...))使用,在structured streaming每次trigger触发结束时打印进度信息,另外调用更新broadcast代码。其中更新broadcast的功能包含两个步骤:
1)清空旧的broadcast,也就是调用LoadResourceManager 对象的unpersist()方法;
2)给broadcast管理对象的broacast属性赋新值,也就是调用LoadResourceManager 对象的load(...)方法。
注意:这个自定义的监听类的方法是在Driver端执行,也只有在Driver端修改broadcast,才能真正修改executor中的broadcast值。具体原因,请查阅broadcast的原理。
class MyStreamingQueryListener extends StreamingQueryListener {
private SparkSession spark = null;
private LoadResourceManager loadResourceManager = null;
private LongAccumulator triggerAccumulator = null;
private LongAccumulator loadCountAccumulator = null;
public MyStreamingQueryListener() {
}
public MyStreamingQueryListener(SparkSession spark, LoadResourceManager loadResourceManager,
LongAccumulator triggerAccumulator, LongAccumulator loadCountAccumulator) {
this.spark = spark;
this.loadResourceManager = loadResourceManager;
this.triggerAccumulator = triggerAccumulator;
this.loadCountAccumulator = loadCountAccumulator;
}
@Override
public void onQueryStarted(QueryStartedEvent queryStarted) {
System.out.println("Query started: " + queryStarted.id());
}
@Override
public void onQueryTerminated(QueryTerminatedEvent queryTerminated) {
System.out.println("Query terminated: " + queryTerminated.id());
}
@Override
public void onQueryProgress(QueryProgressEvent queryProgress) {
System.out.println("Query made progress: " + queryProgress.progress());
// sparkSession.sql("select * from " + queryProgress.progress().name()).show();
triggerAccumulator.add(1);
this.loadResourceManager.unpersist();
this.loadResourceManager.load(spark, loadCountAccumulator);
System.out.println("Trigger accumulator value: " + triggerAccumulator.value());
System.out.println("Load count accumulator value: " + loadCountAccumulator.value());
}
}
第三步:写structured streaming测试类
该测试类分为以下步骤:
1)初始化SparkSession对象spark;
2)给SparkSession对象的streams()添加监控事件:spark.streams().addListener(new MyStreamingQueryListener(...));
3)初始化broadcast管理类LoadResourceManager ,并初始化LoadResourceManager对象的broacast属性值;
4)使用Rate Source生成测试数据;
5)对测试数据进行map操作,并在MapFunction对象的call(...)方法中调用LoadResourceManager 对象的broacast属性值,使用该broacast属性值;
6)定义Sink:sourceDataset.writeStream().format("console").outputMode(OutputMode.Append()).trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS)).start();;
7)阻塞流,等待结束。
public class BroadcastTest {
public static void main(String[] args) {
LogManager.getLogger("org.apache.spark.sql.execution.streaming.RateSourceProvider").setLevel(Level.ERROR);
LogManager.getLogger("org.apache.spark").setLevel(Level.ERROR);
LogManager.getLogger("org.apache.spark.launcher.OutputRedirector").setLevel(Level.ERROR);
// 确定是yarn方式运行。
SparkSession spark = SparkSession.builder().master("yarn").appName("test_broadcast_app").getOrCreate();
LongAccumulator triggerAccumulator = spark.sparkContext().longAccumulator("triggerAccumulator");
LongAccumulator loadCountAccumulator = spark.sparkContext().longAccumulator("loadCountAccumulator");
LoadResourceManager loadResourceManager = new LoadResourceManager();
loadResourceManager.load(spark, loadCountAccumulator);
spark.streams().addListener(
new MyStreamingQueryListener(spark, loadResourceManager, triggerAccumulator, loadCountAccumulator));
Dataset<Row> sourceDataset = spark.readStream().format("rate").option("rowsPerSecond", 100).load();
UDF1<Long, Long> long_fomat_func = new UDF1<Long, Long>() {
private static final long serialVersionUID = 1L;
public Long call(final Long value) throws Exception {
return value % 15;
}
};
spark.udf().register("long_fomat_func", long_fomat_func, DataTypes.LongType);
sourceDataset = sourceDataset.withColumn("int_id",
functions.callUDF("long_fomat_func", functions.col("value")));
sourceDataset.printSchema();
StructType resulStructType = new StructType();
resulStructType = resulStructType.add("int_id", DataTypes.StringType, false);
resulStructType = resulStructType.add("job_result", DataTypes.StringType, true);
ExpressionEncoder<Row> resultEncoder = RowEncoder.apply(resulStructType);
sourceDataset = sourceDataset.map(new MapFunction<Row, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Row call(Row row) throws Exception {
int int_id_idx = row.schema().fieldIndex("int_id");
Object int_idObject = row.get(int_id_idx);
String int_id = int_idObject.toString();
Map<String, String> resources = loadResourceManager.get().getValue();
// 可能会涉及到当跨executor的情况下,依然会出现innerMap.size()返回的值为0的情况.
if (resources.size() == 0) {
throw new RuntimeException("the resources size is zero");
}
String job_result = resources.get(int_id);
Object[] values = new Object[2];
values[0] = int_id;
values[1] = job_result;
return RowFactory.create(values);
}
}, resultEncoder);
sourceDataset.printSchema();
sourceDataset.writeStream().format("console").outputMode(OutputMode.Append())
.trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS)).start();
try {
spark.streams().awaitAnyTermination();
} catch (StreamingQueryException e) {
e.printStackTrace();
}
}
}
第四步:测试。
测试脚本submit_test.sh:
#/bin/sh
jarspath='' for file in `ls /home/dx/tommy_duan/sparkjars/*.jar`
do
jarspath=${file},$jarspath
done
jarspath=${jarspath%?} echo $jarspath /home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2/bin/spark-submit \
--master yarn \
--deploy-mode client \
--class com.dx.test.BroadcastTest \
--properties-file ./conf/spark-properties.conf \
--jars $jarspath \
--num-executors 10 \
--executor-memory 3G \
--executor-cores 1 \
--driver-memory 2G \
--driver-java-options "-XX:+TraceClassPaths" \
./test.jar $1 $2 $3 $4
执行打印结果:
。。。。。。
19/03/27 20:01:18 INFO impl.YarnClientImpl: Submitted application application_1548381669007_0775
19/03/27 20:01:47 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3404e5c4{/metrics/json,null,AVAILABLE,@Spark}
the value is :80
19/03/27 20:01:48 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@66b0e207{/SQL,null,AVAILABLE,@Spark}
19/03/27 20:01:48 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5d601832{/SQL/json,null,AVAILABLE,@Spark}
19/03/27 20:01:48 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3e52ed5d{/SQL/execution,null,AVAILABLE,@Spark}
19/03/27 20:01:48 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3d40498a{/SQL/execution/json,null,AVAILABLE,@Spark}
19/03/27 20:01:48 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1de5cc88{/static/sql,null,AVAILABLE,@Spark}
19/03/27 20:01:49 INFO util.Version: Elasticsearch Hadoop v6.4.2 [54a631a014]
root
|-- timestamp: timestamp (nullable = true)
|-- value: long (nullable = true)
|-- int_id: long (nullable = true) root
|-- int_id: string (nullable = false)
|-- job_result: string (nullable = true) Query started: d4c76196-c874-4a09-ae2d-832c03a70ffb
-------------------------------------------
Batch: 0
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
+------+----------+ Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:01:51.686Z",
"batchId" : 0,
"numInputRows" : 0,
"processedRowsPerSecond" : 0.0,
"durationMs" : {
"addBatch" : 2312,
"getBatch" : 38,
"getOffset" : 0,
"queryPlanning" : 495,
"triggerExecution" : 3030,
"walCommit" : 131
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : null,
"endOffset" : 0,
"numInputRows" : 0,
"processedRowsPerSecond" : 0.0
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :26
Trigger accumulator value: 1
Load count accumulator value: 2
-------------------------------------------
Batch: 1
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 0| null|
| 1| 1,26|
| 2| 2,26|
| 3| 3,26|
| 4| 4,26|
| 5| 5,26|
| 6| 6,26|
| 7| 7,26|
| 8| 8,26|
| 9| 9,26|
| 10| 10,26|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,26|
| 2| 2,26|
| 3| 3,26|
| 4| 4,26|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:02:00.001Z",
"batchId" : 1,
"numInputRows" : 800,
"inputRowsPerSecond" : 96.21166566446182,
"processedRowsPerSecond" : 14.361625736033318,
"durationMs" : {
"addBatch" : 55166,
"getBatch" : 70,
"getOffset" : 0,
"queryPlanning" : 59,
"triggerExecution" : 55704,
"walCommit" : 402
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 0,
"endOffset" : 8,
"numInputRows" : 800,
"inputRowsPerSecond" : 96.21166566446182,
"processedRowsPerSecond" : 14.361625736033318
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :7
Trigger accumulator value: 2
Load count accumulator value: 3
-------------------------------------------
Batch: 2
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 5| 5,7|
| 6| 6,7|
| 7| 7,7|
| 8| 8,7|
| 9| 9,7|
| 10| 10,7|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,7|
| 2| 2,7|
| 3| 3,7|
| 4| 4,7|
| 5| 5,7|
| 6| 6,7|
| 7| 7,7|
| 8| 8,7|
| 9| 9,7|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:02:55.822Z",
"batchId" : 2,
"numInputRows" : 5600,
"inputRowsPerSecond" : 100.3206678490174,
"processedRowsPerSecond" : 378.45509224842874,
"durationMs" : {
"addBatch" : 14602,
"getBatch" : 24,
"getOffset" : 0,
"queryPlanning" : 61,
"triggerExecution" : 14797,
"walCommit" : 108
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 8,
"endOffset" : 64,
"numInputRows" : 5600,
"inputRowsPerSecond" : 100.3206678490174,
"processedRowsPerSecond" : 378.45509224842874
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :7
Trigger accumulator value: 3
Load count accumulator value: 4
-------------------------------------------
Batch: 3
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 10| 10,7|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,7|
| 2| 2,7|
| 3| 3,7|
| 4| 4,7|
| 5| 5,7|
| 6| 6,7|
| 7| 7,7|
| 8| 8,7|
| 9| 9,7|
| 10| 10,7|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:03:10.698Z",
"batchId" : 3,
"numInputRows" : 1500,
"inputRowsPerSecond" : 100.83355740790536,
"processedRowsPerSecond" : 437.4453193350831,
"durationMs" : {
"addBatch" : 3253,
"getBatch" : 18,
"getOffset" : 0,
"queryPlanning" : 42,
"triggerExecution" : 3429,
"walCommit" : 113
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 64,
"endOffset" : 79,
"numInputRows" : 1500,
"inputRowsPerSecond" : 100.83355740790536,
"processedRowsPerSecond" : 437.4453193350831
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :21
Trigger accumulator value: 4
Load count accumulator value: 5
-------------------------------------------
Batch: 4
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 10| 10,21|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,21|
| 2| 2,21|
| 3| 3,21|
| 4| 4,21|
| 5| 5,21|
| 6| 6,21|
| 7| 7,21|
| 8| 8,21|
| 9| 9,21|
| 10| 10,21|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:03:20.000Z",
"batchId" : 4,
"numInputRows" : 900,
"inputRowsPerSecond" : 96.7533863685229,
"processedRowsPerSecond" : 664.2066420664207,
"durationMs" : {
"addBatch" : 599,
"getBatch" : 23,
"getOffset" : 0,
"queryPlanning" : 36,
"triggerExecution" : 1355,
"walCommit" : 692
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 79,
"endOffset" : 88,
"numInputRows" : 900,
"inputRowsPerSecond" : 96.7533863685229,
"processedRowsPerSecond" : 664.2066420664207
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :76
Trigger accumulator value: 5
Load count accumulator value: 6
-------------------------------------------
Batch: 5
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 10| 10,76|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,76|
| 2| 2,76|
| 3| 3,76|
| 4| 4,76|
| 5| 5,76|
| 6| 6,76|
| 7| 7,76|
| 8| 8,76|
| 9| 9,76|
| 10| 10,76|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:03:30.000Z",
"batchId" : 5,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1189.0606420927468,
"durationMs" : {
"addBatch" : 613,
"getBatch" : 21,
"getOffset" : 0,
"queryPlanning" : 40,
"triggerExecution" : 841,
"walCommit" : 164
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 88,
"endOffset" : 98,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1189.0606420927468
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :1
Trigger accumulator value: 6
Load count accumulator value: 7
-------------------------------------------
Batch: 6
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 5| 5,1|
| 6| 6,1|
| 7| 7,1|
| 8| 8,1|
| 9| 9,1|
| 10| 10,1|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,1|
| 2| 2,1|
| 3| 3,1|
| 4| 4,1|
| 5| 5,1|
| 6| 6,1|
| 7| 7,1|
| 8| 8,1|
| 9| 9,1|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:03:40.000Z",
"batchId" : 6,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1116.0714285714284,
"durationMs" : {
"addBatch" : 522,
"getBatch" : 18,
"getOffset" : 0,
"queryPlanning" : 27,
"triggerExecution" : 896,
"walCommit" : 325
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 98,
"endOffset" : 108,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1116.0714285714284
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :5
Trigger accumulator value: 7
Load count accumulator value: 8
-------------------------------------------
Batch: 7
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 0| null|
| 1| 1,5|
| 2| 2,5|
| 3| 3,5|
| 4| 4,5|
| 5| 5,5|
| 6| 6,5|
| 7| 7,5|
| 8| 8,5|
| 9| 9,5|
| 10| 10,5|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,5|
| 2| 2,5|
| 3| 3,5|
| 4| 4,5|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:03:50.000Z",
"batchId" : 7,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1605.1364365971108,
"durationMs" : {
"addBatch" : 454,
"getBatch" : 23,
"getOffset" : 0,
"queryPlanning" : 41,
"triggerExecution" : 623,
"walCommit" : 102
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 108,
"endOffset" : 118,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1605.1364365971108
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :49
Trigger accumulator value: 8
Load count accumulator value: 9
-------------------------------------------
Batch: 8
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 10| 10,49|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,49|
| 2| 2,49|
| 3| 3,49|
| 4| 4,49|
| 5| 5,49|
| 6| 6,49|
| 7| 7,49|
| 8| 8,49|
| 9| 9,49|
| 10| 10,49|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:04:00.000Z",
"batchId" : 8,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1436.7816091954023,
"durationMs" : {
"addBatch" : 543,
"getBatch" : 23,
"getOffset" : 0,
"queryPlanning" : 34,
"triggerExecution" : 696,
"walCommit" : 93
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 118,
"endOffset" : 128,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1436.7816091954023
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :62
Trigger accumulator value: 9
Load count accumulator value: 10
-------------------------------------------
Batch: 9
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 5| 5,62|
| 6| 6,62|
| 7| 7,62|
| 8| 8,62|
| 9| 9,62|
| 10| 10,62|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,62|
| 2| 2,62|
| 3| 3,62|
| 4| 4,62|
| 5| 5,62|
| 6| 6,62|
| 7| 7,62|
| 8| 8,62|
| 9| 9,62|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:04:10.001Z",
"batchId" : 9,
"numInputRows" : 1000,
"inputRowsPerSecond" : 99.99000099990002,
"processedRowsPerSecond" : 1519.756838905775,
"durationMs" : {
"addBatch" : 459,
"getBatch" : 21,
"getOffset" : 0,
"queryPlanning" : 45,
"triggerExecution" : 658,
"walCommit" : 130
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 128,
"endOffset" : 138,
"numInputRows" : 1000,
"inputRowsPerSecond" : 99.99000099990002,
"processedRowsPerSecond" : 1519.756838905775
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :58
Trigger accumulator value: 10
Load count accumulator value: 11
-------------------------------------------
Batch: 10
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 0| null|
| 1| 1,58|
| 2| 2,58|
| 3| 3,58|
| 4| 4,58|
| 5| 5,58|
| 6| 6,58|
| 7| 7,58|
| 8| 8,58|
| 9| 9,58|
| 10| 10,58|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,58|
| 2| 2,58|
| 3| 3,58|
| 4| 4,58|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:04:20.000Z",
"batchId" : 10,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0100010001,
"processedRowsPerSecond" : 1577.2870662460568,
"durationMs" : {
"addBatch" : 481,
"getBatch" : 21,
"getOffset" : 0,
"queryPlanning" : 32,
"triggerExecution" : 633,
"walCommit" : 98
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 138,
"endOffset" : 148,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0100010001,
"processedRowsPerSecond" : 1577.2870662460568
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :42
Trigger accumulator value: 11
Load count accumulator value: 12
-------------------------------------------
Batch: 11
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 10| 10,42|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,42|
| 2| 2,42|
| 3| 3,42|
| 4| 4,42|
| 5| 5,42|
| 6| 6,42|
| 7| 7,42|
| 8| 8,42|
| 9| 9,42|
| 10| 10,42|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:04:30.000Z",
"batchId" : 11,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1694.9152542372883,
"durationMs" : {
"addBatch" : 415,
"getBatch" : 18,
"getOffset" : 0,
"queryPlanning" : 38,
"triggerExecution" : 590,
"walCommit" : 118
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 148,
"endOffset" : 158,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1694.9152542372883
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :29
Trigger accumulator value: 12
Load count accumulator value: 13
-------------------------------------------
Batch: 12
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
| 5| 5,29|
| 6| 6,29|
| 7| 7,29|
| 8| 8,29|
| 9| 9,29|
| 10| 10,29|
| 11| null|
| 12| null|
| 13| null|
| 14| null|
| 0| null|
| 1| 1,29|
| 2| 2,29|
| 3| 3,29|
| 4| 4,29|
| 5| 5,29|
| 6| 6,29|
| 7| 7,29|
| 8| 8,29|
| 9| 9,29|
+------+----------+
only showing top 20 rows Query made progress: {
"id" : "d4c76196-c874-4a09-ae2d-832c03a70ffb",
"runId" : "0317a974-930f-47ae-99d8-3fa582383a65",
"name" : null,
"timestamp" : "2019-03-27T12:04:40.000Z",
"batchId" : 12,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1406.4697609001407,
"durationMs" : {
"addBatch" : 479,
"getBatch" : 25,
"getOffset" : 0,
"queryPlanning" : 34,
"triggerExecution" : 711,
"walCommit" : 171
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : 158,
"endOffset" : 168,
"numInputRows" : 1000,
"inputRowsPerSecond" : 100.0,
"processedRowsPerSecond" : 1406.4697609001407
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@3b5afcc"
}
}
the value is :11
Trigger accumulator value: 13
Load count accumulator value: 14
失败测试结果:
所有类如下:
package com.dx.test; import java.io.Serializable;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.TimeUnit; import org.apache.log4j.Level;
import org.apache.log4j.LogManager;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.functions;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder;
import org.apache.spark.sql.catalyst.encoders.RowEncoder;
import org.apache.spark.sql.streaming.OutputMode;
import org.apache.spark.sql.streaming.StreamingQueryException;
import org.apache.spark.sql.streaming.StreamingQueryListener;
import org.apache.spark.sql.streaming.Trigger;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.util.LongAccumulator; public class BroadcastTest2 {
public static void main(String[] args) {
LogManager.getLogger("org.apache.spark.sql.execution.streaming.RateSourceProvider").setLevel(Level.ERROR);
LogManager.getLogger("org.apache.spark").setLevel(Level.ERROR);
LogManager.getLogger("org.apache.spark.launcher.OutputRedirector").setLevel(Level.ERROR); // 确定是yarn方式运行。
SparkSession spark = SparkSession.builder().master("yarn").appName("test_broadcast_app").getOrCreate();
LongAccumulator triggerAccumulator = spark.sparkContext().longAccumulator("triggerAccumulator");
LongAccumulator loadCountAccumulator = spark.sparkContext().longAccumulator("loadCountAccumulator"); LoadResourceManager.load(spark, loadCountAccumulator); spark.streams().addListener(
new MyStreamingQueryListener(spark, triggerAccumulator, loadCountAccumulator)); Dataset<Row> sourceDataset = spark.readStream().format("rate").option("rowsPerSecond", 100).load(); UDF1<Long, Long> long_fomat_func = new UDF1<Long, Long>() {
private static final long serialVersionUID = 1L; public Long call(final Long value) throws Exception {
return value % 15;
}
}; spark.udf().register("long_fomat_func", long_fomat_func, DataTypes.LongType);
sourceDataset = sourceDataset
.withColumn("int_id", functions.callUDF("long_fomat_func", functions.col("value")));
sourceDataset.printSchema(); StructType resulStructType = new StructType();
resulStructType = resulStructType.add("int_id", DataTypes.StringType, false);
resulStructType = resulStructType.add("job_result", DataTypes.StringType, true);
ExpressionEncoder<Row> resultEncoder = RowEncoder.apply(resulStructType); sourceDataset = sourceDataset.map(new MapFunction<Row, Row>() {
private static final long serialVersionUID = 1L; @Override
public Row call(Row row) throws Exception {
int int_id_idx = row.schema().fieldIndex("int_id");
Object int_idObject = row.get(int_id_idx);
String int_id = int_idObject.toString();
Map<String, String> resources = LoadResourceManager.get().getValue(); // 可能会涉及到当跨executor的情况下,依然会出现innerMap.size()返回的值为0的情况.
if (resources.size() == 0) {
throw new RuntimeException("the resources size is zero");
}
String job_result = resources.get(int_id); Object[] values = new Object[2];
values[0] = int_id;
values[1] = job_result; return RowFactory.create(values);
}
}, resultEncoder);
sourceDataset.printSchema(); sourceDataset.writeStream().format("console").outputMode(OutputMode.Append())
.trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS)).start(); try {
spark.streams().awaitAnyTermination();
} catch (StreamingQueryException e) {
e.printStackTrace();
}
}
} class LoadResourceManager implements Serializable{
private static final long serialVersionUID = 7896720904164793792L;
private static volatile Broadcast<Map<String, String>> broadcast = null; public static Broadcast<Map<String, String>> get() {
return broadcast;
} public static void unpersist() {
broadcast.unpersist(true);
// broadcast.destory();不能调用该方法,否则会抛出:Attempted to use Broadcast(x) after it was destroyed
}
public static void load(SparkSession spark, LongAccumulator loadCountAccumulator) {
loadCountAccumulator.add(1);
int val = new Random().nextInt(100);
// 这里可以添加时间判断是否重新加载
Map<String, String> innerMap = new HashMap<String, String>(10);
innerMap.put("1", "1," + val);
innerMap.put("2", "2," + val);
innerMap.put("3", "3," + val);
innerMap.put("4", "4," + val);
innerMap.put("5", "5," + val);
innerMap.put("6", "6," + val);
innerMap.put("7", "7," + val);
innerMap.put("8", "8," + val);
innerMap.put("9", "9," + val);
innerMap.put("10", "10," + val);
System.out.println("the value is :" + val);
JavaSparkContext jsc = JavaSparkContext.fromSparkContext(spark.sparkContext());
broadcast = jsc.broadcast(innerMap);
}
}
class MyStreamingQueryListener extends StreamingQueryListener {
private SparkSession spark = null;
private LongAccumulator triggerAccumulator = null;
private LongAccumulator loadCountAccumulator = null;
public MyStreamingQueryListener() {
}
public MyStreamingQueryListener(SparkSession spark,
LongAccumulator triggerAccumulator, LongAccumulator loadCountAccumulator) {
this.spark = spark;
this.triggerAccumulator = triggerAccumulator;
this.loadCountAccumulator = loadCountAccumulator;
}
@Override
public void onQueryStarted(QueryStartedEvent queryStarted) {
System.out.println("Query started: " + queryStarted.id());
}
@Override
public void onQueryTerminated(QueryTerminatedEvent queryTerminated) {
System.out.println("Query terminated: " + queryTerminated.id());
}
@Override
public void onQueryProgress(QueryProgressEvent queryProgress) {
System.out.println("Query made progress: " + queryProgress.progress());
// sparkSession.sql("select * from " +
// queryProgress.progress().name()).show();
triggerAccumulator.add(1);
LoadResourceManager.unpersist();
LoadResourceManager.load(spark, loadCountAccumulator);
System.out.println("Trigger accumulator value: " + triggerAccumulator.value());
System.out.println("Load count accumulator value: " + loadCountAccumulator.value());
}
}
测试打印如下:
[Opened /usr/java/jdk1.8.0_152/jre/lib/charsets.jar]
19/03/27 20:25:41 INFO impl.YarnClientImpl: Submitted application application_1548381669007_0777
19/03/27 20:26:19 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@42d9e8d2{/metrics/json,null,AVAILABLE,@Spark}
the value is :1
19/03/27 20:26:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7308c820{/SQL,null,AVAILABLE,@Spark}
19/03/27 20:26:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@640c216b{/SQL/json,null,AVAILABLE,@Spark}
19/03/27 20:26:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@28e94c2{/SQL/execution,null,AVAILABLE,@Spark}
19/03/27 20:26:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@482a58c7{/SQL/execution/json,null,AVAILABLE,@Spark}
19/03/27 20:26:38 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2d4fb0d8{/static/sql,null,AVAILABLE,@Spark}
19/03/27 20:26:39 INFO util.Version: Elasticsearch Hadoop v6.4.2 [54a631a014]
root
|-- timestamp: timestamp (nullable = true)
|-- value: long (nullable = true)
|-- int_id: long (nullable = true) root
|-- int_id: string (nullable = false)
|-- job_result: string (nullable = true) Query started: 53290edb-bfca-4de3-9686-719ffece7fc0
-------------------------------------------
Batch: 0
-------------------------------------------
+------+----------+
|int_id|job_result|
+------+----------+
+------+----------+ Query made progress: {
"id" : "53290edb-bfca-4de3-9686-719ffece7fc0",
"runId" : "cf449470-f377-4270-b5ea-25230c49add2",
"name" : null,
"timestamp" : "2019-03-27T12:26:41.980Z",
"batchId" : 0,
"numInputRows" : 0,
"processedRowsPerSecond" : 0.0,
"durationMs" : {
"addBatch" : 2383,
"getBatch" : 38,
"getOffset" : 0,
"queryPlanning" : 554,
"triggerExecution" : 3170,
"walCommit" : 140
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]",
"startOffset" : null,
"endOffset" : 0,
"numInputRows" : 0,
"processedRowsPerSecond" : 0.0
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSinkProvider@511c2d85"
}
}
the value is :43
Trigger accumulator value: 1
Load count accumulator value: 2
19/03/27 20:27:00 ERROR scheduler.TaskSetManager: Task 0 in stage 0.0 failed 4 times; aborting job
19/03/27 20:27:01 ERROR v2.WriteToDataSourceV2Exec: Data source writer org.apache.spark.sql.execution.streaming.sources.MicroBatchWriter@e074fee is aborting.
19/03/27 20:27:01 ERROR v2.WriteToDataSourceV2Exec: Data source writer org.apache.spark.sql.execution.streaming.sources.MicroBatchWriter@e074fee aborted.
19/03/27 20:27:01 ERROR streaming.MicroBatchExecution: Query [id = 53290edb-bfca-4de3-9686-719ffece7fc0, runId = cf449470-f377-4270-b5ea-25230c49add2] terminated with error
org.apache.spark.SparkException: Writing job aborted.
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.doExecute(WriteToDataSourceV2.scala:112)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan.getByteArrayRdd(SparkPlan.scala:247)
at org.apache.spark.sql.execution.SparkPlan.executeCollect(SparkPlan.scala:294)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3273)
at org.apache.spark.sql.Dataset$$anonfun$collect$1.apply(Dataset.scala:2722)
at org.apache.spark.sql.Dataset$$anonfun$collect$1.apply(Dataset.scala:2722)
at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3254)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3253)
at org.apache.spark.sql.Dataset.collect(Dataset.scala:2722)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$org$apache$spark$sql$execution$streaming$MicroBatchExecution$$runBatch$3$$anonfun$apply$16.apply(MicroBatchExecution.scala:478)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$org$apache$spark$sql$execution$streaming$MicroBatchExecution$$runBatch$3.apply(MicroBatchExecution.scala:473)
at org.apache.spark.sql.execution.streaming.ProgressReporter$class.reportTimeTaken(ProgressReporter.scala:271)
at org.apache.spark.sql.execution.streaming.StreamExecution.reportTimeTaken(StreamExecution.scala:58)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.org$apache$spark$sql$execution$streaming$MicroBatchExecution$$runBatch(MicroBatchExecution.scala:472)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1$$anonfun$apply$mcZ$sp$1.apply$mcV$sp(MicroBatchExecution.scala:133)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1$$anonfun$apply$mcZ$sp$1.apply(MicroBatchExecution.scala:121)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1$$anonfun$apply$mcZ$sp$1.apply(MicroBatchExecution.scala:121)
at org.apache.spark.sql.execution.streaming.ProgressReporter$class.reportTimeTaken(ProgressReporter.scala:271)
at org.apache.spark.sql.execution.streaming.StreamExecution.reportTimeTaken(StreamExecution.scala:58)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1.apply$mcZ$sp(MicroBatchExecution.scala:121)
at org.apache.spark.sql.execution.streaming.ProcessingTimeExecutor.execute(TriggerExecutor.scala:56)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.runActivatedStream(MicroBatchExecution.scala:117)
at org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:279)
at org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.run(StreamExecution.scala:189)
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 12, vm10.60.0.8.com.cn, executor 6): java.lang.NullPointerException
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:74)
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:1)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.mapelements_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.deserializetoobject_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.hasNext(WholeStageCodegenExec.scala:614)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.foreach(WholeStageCodegenExec.scala:612)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:133)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:132)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1415)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2.scala:138)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:79)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:78)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748) Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1609)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1597)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1596)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1596)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1830)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1779)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1768)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:642)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2034)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.doExecute(WriteToDataSourceV2.scala:82)
... 31 more
Caused by: java.lang.NullPointerException
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:74)
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:1)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.mapelements_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.deserializetoobject_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.hasNext(WholeStageCodegenExec.scala:614)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.foreach(WholeStageCodegenExec.scala:612)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:133)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:132)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1415)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2.scala:138)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:79)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:78)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
org.apache.spark.sql.streaming.StreamingQueryException: Writing job aborted.
=== Streaming Query ===
Identifier: [id = 53290edb-bfca-4de3-9686-719ffece7fc0, runId = cf449470-f377-4270-b5ea-25230c49add2]
Current Committed Offsets: {RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]: 0}
Current Available Offsets: {RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64]: 8} Current State: ACTIVE
Thread State: RUNNABLE Logical Plan:
SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 0, int_id), StringType), true, false) AS int_id#14, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 1, job_result), StringType), true, false) AS job_result#15]
+- MapElements com.dx.test.BroadcastTest$2@3a907688, interface org.apache.spark.sql.Row, [StructField(timestamp,TimestampType,true), StructField(value,LongType,true), StructField(int_id,LongType,true)], obj#13: org.apache.spark.sql.Row
+- DeserializeToObject createexternalrow(staticinvoke(class org.apache.spark.sql.catalyst.util.DateTimeUtils$, ObjectType(class java.sql.Timestamp), toJavaTimestamp, timestamp#2, true, false), value#3L, int_id#6L, StructField(timestamp,TimestampType,true), StructField(value,LongType,true), StructField(int_id,LongType,true)), obj#12: org.apache.spark.sql.Row
+- Project [timestamp#2, value#3L, UDF:long_fomat_func(value#3L) AS int_id#6L]
+- StreamingExecutionRelation RateSource[rowsPerSecond=100, rampUpTimeSeconds=0, numPartitions=64], [timestamp#2, value#3L] at org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:295)
at org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.run(StreamExecution.scala:189)
Caused by: org.apache.spark.SparkException: Writing job aborted.
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.doExecute(WriteToDataSourceV2.scala:112)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan.getByteArrayRdd(SparkPlan.scala:247)
at org.apache.spark.sql.execution.SparkPlan.executeCollect(SparkPlan.scala:294)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3273)
at org.apache.spark.sql.Dataset$$anonfun$collect$1.apply(Dataset.scala:2722)
at org.apache.spark.sql.Dataset$$anonfun$collect$1.apply(Dataset.scala:2722)
at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3254)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3253)
at org.apache.spark.sql.Dataset.collect(Dataset.scala:2722)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$org$apache$spark$sql$execution$streaming$MicroBatchExecution$$runBatch$3$$anonfun$apply$16.apply(MicroBatchExecution.scala:478)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$org$apache$spark$sql$execution$streaming$MicroBatchExecution$$runBatch$3.apply(MicroBatchExecution.scala:473)
at org.apache.spark.sql.execution.streaming.ProgressReporter$class.reportTimeTaken(ProgressReporter.scala:271)
at org.apache.spark.sql.execution.streaming.StreamExecution.reportTimeTaken(StreamExecution.scala:58)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.org$apache$spark$sql$execution$streaming$MicroBatchExecution$$runBatch(MicroBatchExecution.scala:472)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1$$anonfun$apply$mcZ$sp$1.apply$mcV$sp(MicroBatchExecution.scala:133)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1$$anonfun$apply$mcZ$sp$1.apply(MicroBatchExecution.scala:121)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1$$anonfun$apply$mcZ$sp$1.apply(MicroBatchExecution.scala:121)
at org.apache.spark.sql.execution.streaming.ProgressReporter$class.reportTimeTaken(ProgressReporter.scala:271)
at org.apache.spark.sql.execution.streaming.StreamExecution.reportTimeTaken(StreamExecution.scala:58)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$runActivatedStream$1.apply$mcZ$sp(MicroBatchExecution.scala:121)
at org.apache.spark.sql.execution.streaming.ProcessingTimeExecutor.execute(TriggerExecutor.scala:56)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.runActivatedStream(MicroBatchExecution.scala:117)
at org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:279)
... 1 more
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 12, vm10.60.0.8.com.cn, executor 6): java.lang.NullPointerException
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:74)
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:1)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.mapelements_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.deserializetoobject_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.hasNext(WholeStageCodegenExec.scala:614)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.foreach(WholeStageCodegenExec.scala:612)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:133)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:132)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1415)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2.scala:138)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:79)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:78)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748) Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1609)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1597)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1596)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1596)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1830)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1779)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1768)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:642)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2034)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.doExecute(WriteToDataSourceV2.scala:82)
... 31 more
Caused by: java.lang.NullPointerException
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:74)
at com.dx.test.BroadcastTest$2.call(BroadcastTest.java:1)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.mapelements_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.deserializetoobject_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.hasNext(WholeStageCodegenExec.scala:614)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$10$$anon$1.foreach(WholeStageCodegenExec.scala:612)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:133)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2.scala:132)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1415)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2.scala:138)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:79)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$2.apply(WriteToDataSourceV2.scala:78)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Query terminated: 53290edb-bfca-4de3-9686-719ffece7fc0
19/03/27 20:27:01 INFO server.AbstractConnector: Stopped Spark@af78c87{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
bash-4.1$
两个测试主要不同之处对比:
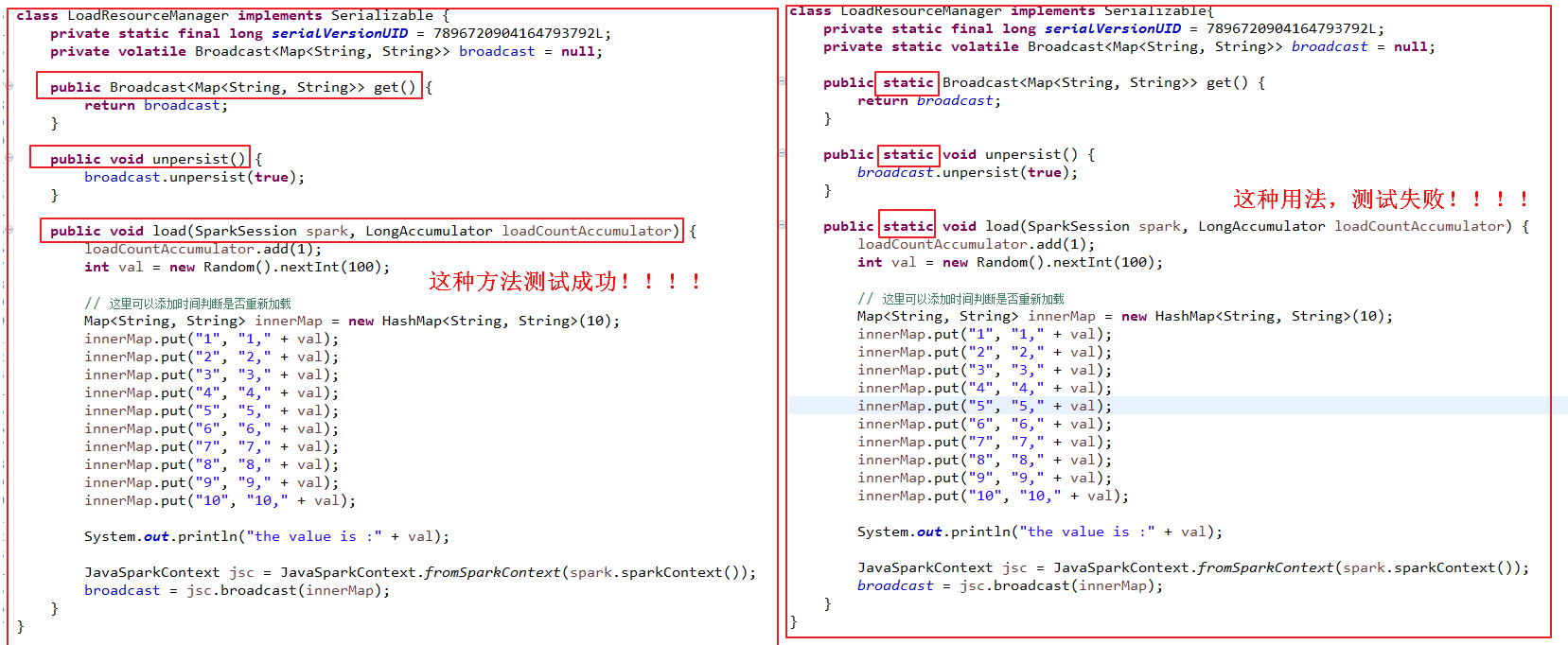
关于这两个类测试结果不同,希望读者可以发表自己的看法:为什么使用静态方法就测试失败呢?
Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)的更多相关文章
- SpringCloud微服务实战——搭建企业级开发框架(四十五):【微服务监控告警实现方式二】使用Actuator(Micrometer)+Prometheus+Grafana实现完整的微服务监控
无论是使用SpringBootAdmin还是使用Prometheus+Grafana都离不开SpringBoot提供的核心组件Actuator.提到Actuator,又不得不提Micrometer ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十九):推送avro格式数据到topic,并使用spark structured streaming接收topic解析avro数据
推送avro格式数据到topic 源代码:https://github.com/Neuw84/structured-streaming-avro-demo/blob/master/src/main/j ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- 程序员与年龄:四十岁普通开发、三十五岁首席架构、三十岁基层Leader
最近,有一个词儿特别热门--躺平.有没有人跟你说过:"躺平说起来容易,做起来更容易." 和躺平相对的是另外一个词--内卷,群聊的时候,已经很多次看过草卷起来了.jpg表情包.某些节 ...
- Structured Streaming Programming Guide结构化流编程指南
目录 Overview Quick Example Programming Model Basic Concepts Handling Event-time and Late Data Fault T ...
- Structured streaming
Structured streaming是spark 2.0以后新增的用于实时处理的技术.与spark streaming不同的是,Structured streaming打开了数据源到数据落地之间的 ...
- Structured Streaming编程 Programming Guide
Structured Streaming编程 Programming Guide Overview Quick Example Programming Model Basic Concepts Han ...
- Spark2.3(三十四):Spark Structured Streaming之withWaterMark和windows窗口是否可以实现最近一小时统计
WaterMark除了可以限定来迟数据范围,是否可以实现最近一小时统计? WaterMark目的用来限定参数计算数据的范围:比如当前计算数据内max timestamp是12::00,waterMar ...
- Spark2.3(三十五)Spark Structured Streaming源代码剖析(从CSDN和Github中看到别人分析的源代码的文章值得收藏)
从CSDN中读取到关于spark structured streaming源代码分析不错的几篇文章 spark源码分析--事件总线LiveListenerBus spark事件总线的核心是LiveLi ...
随机推荐
- 将xml 写到内存中再已string类型读出来
System.IO.MemoryStream ms = new System.IO.MemoryStream(); xmlDoc.Save(ms); System.IO.StreamReader sr ...
- P2577 [ZJOI2005]午餐 状压DP
题目描述 上午的训练结束了,THU ACM小组集体去吃午餐,他们一行N人来到了著名的十食堂.这里有两个打饭的窗口,每个窗口同一时刻只能给一个人打饭.由于每个人的口味(以及胃口)不同,所以他们要吃的菜各 ...
- oracle 中可以用 case when then else end来处理除数是0的情况
case when a.ZJXJE != 0 then to_char(round((a.YFZK-b.YFZK)/a.ZJXJE,2)) else '本期总进项金额为零' end then和else ...
- TF:Tensorflor之session会话的使用,定义两个矩阵,两种方法输出2个矩阵相乘的结果—Jason niu
import tensorflow as tf matrix1 = tf.constant([[3, 20]]) matrix2 = tf.constant([[6], [100]]) product ...
- UVA136 Ugly Numbers【set】【优先队列】
丑数 丑数是指不能被2,3,5以外的其他素数整除的数.把丑数从小到大排列起来,结果如下: 1,2,3,4,5,6,8,9,10,12,15,… 求第1500个丑数. 提示:从小到大生成各个丑数.最小的 ...
- Shell学习之环境变量配置文件(三)
Shell学习之环境变量配置文件 目录 环境变量配置文件简介 环境变量配置文件作用 其他配置文件和登录信息 环境变量配置文件简介 环境变量配置文件简介 环境变量配置文件中主要是定义对系统操作环境生效的 ...
- linux学习笔记 apache php mysql +linux
1 #yum remove httpd 2 #yum -y install httpd php-common php-devel php-gd php-mcrypt php-mbstring php- ...
- scrapy 命令行
关于命令详细使用 命令的使用范围 这里的命令分为全局的命令和项目的命令,全局的命令表示可以在任何地方使用,而项目的命令只能在项目目录下使用 全局的命令有:startprojectgenspiderse ...
- 大数据环境完全分布式搭建 hadoop2.4.1
(如果想要安装视频及相关软件可以博私聊我 qq 731487514) hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA.YARN等.最新的hadoop-2.4.1又增加了YA ...
- JS运算符问题
以下代码是否报错,如果不报错输出什么,为什么 var x = !!"Hello" + (!"world", !!"from here!!") ...