python3爬虫入门程序
适用于有且只有一点Python3和网页基础的朋友,大牛&路人请绕道
(本文很多废话,第一次在网上长篇大论,所以激动的停不下来,如果有大佬路过,也希望不要直接绕道,烦请指点一二)
感谢博客园给了我一个机会,我喜欢的id还没有被抢注,真的是太可怕了
*注:这是一段废话,正文请直接跳过这一段. 大二的时候因为爱好,自己学了点python(当初学主要是因为语法简洁美观,还没有大括号,代码对齐?反正java代码也要对齐啊~),还好我学python的时候py3已经流行起来了,没有学py2,不然又得好一阵折腾. *
写这个代码的背景:记得高二的时候逛骗子网站,出于好奇在网站上留下了同桌的手机号,结果这都过了大概大半年了吧,同桌还是接二连三的可以收到骗子的电话,但是原来的网址已经找不到了,于是就在百度随便搜索了关键词"牛股"挨个查看的,只找到了一个可以输入手机号的,剩下的都是让加微信的,本来想整整我们老师呢,想想还是免了,干脆往他们数据库填点东西玩吧,其实最终是否成功我也不能确定
- 操作环境
- win10 1803 64位
- Chrome 68.0.3440.106(正式版本) (64 位)
- pycharm-UI(pycharm专业版) 2018.2
- python-365
- 库(非自带库用pip直接安装就行):
- pymysql :import pymysql
- requests :import requests
- json(自带) :import json
- Faker: :from faker import Faker
首先选取目标
目标网站是这个,url为:http://gpyd.gp241.com/nyqpc/bd2.html?id=20110052,

1.首先肯定是抓取一下post/get地址
进入首页后点击"点击领取9月牛股"弹出对话框后,按F12弹出开发者工具
在开发者工具中选中"Network",随后点击网页中的点击领取,会看到network中多出来一条文件信息
然后提取一下我们需要的数据放到pycharm中,并整理成这种json格式:


2.这样我们就得到了这些数据:
url = r"https: // download.zslxt.com / tinterface.php"
headers = {
"Host": "download.zslxt.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "http:/gpyd.gp241.com/nyqpc/bd2.html?id=20110052",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Content-Length": "107",
"Origin": "http://gpyd.gp241.com",
"Connection": "keep-alive"
}
data = {
"bm": "gbk",
"gpdm": "",
"id": "20110052",
"phone": "15666668888",
"qudao": 98,
"remarks": "牛有圈百度2)"
}
这里看data的参数也应该明白了,这里就是我们刚才输入的手机号了,别的代码可以不动,我刚才切换浏览器发现并没有影响,不知道是怎么来的,可能是跟百度推广有关吧
然后,这样之后就可以向网站发送一条数据了
首先我们要使用requests库,这里就不介绍了,是一个可以用来请求get/post...还可以使用session保持登陆,用途很广
这里有一点需要注意,就是data数据不可以直接传送,需要用json.dumps()方法转为字符串
requests可以返回请求数据,这段代码并没有体现出来,但是请不要被误导
import requests
import json
url = r"https: // download.zslxt.com / tinterface.php"
headers = {
"Host": "download.zslxt.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "http:/gpyd.gp241.com/nyqpc/bd2.html?id=20110052",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Content-Length": "107",
"Origin": "http://gpyd.gp241.com",
"Connection": "keep-alive"
}
data = {
"bm": "gbk",
"gpdm": "",
"id": "20110052",
"phone": "15666668888",
"qudao": 98,
"remarks": "牛有圈百度2)"
}
requests.post(url=url, headers=headers, data=json.dumps(data))
可是,总不能只发送一次吧
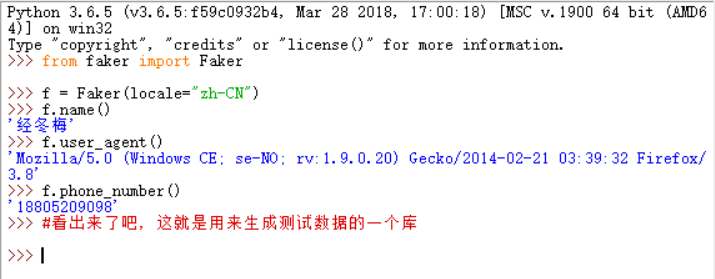
这里先介绍一下python中最假的库--Faker
其实这个库的"造假"功能出乎意料的强大,有兴趣的可以去了解一下
在这个例子中大概只需要两个功能:生成随机user-agent和手机号码(甚至这个网站也没必要随机user-agent,因为我没有使用代理ip提交了大概两千条数据,都没有被封)
这样之后,我们的代码就学会了一点伪装的皮毛
(这里插个题外话,那天在某论坛看到一个朋友问为什么一直在更换代理还是被封号了,,,当时我用的手机也没有哪个论坛的帐号因此不方便回复他,同一个账号一直在更换ip这种行为不正常吖)
这样之后我们的代码便成了如下代码:
import requests
import json
from faker import Faker
f = Faker(locale="zh-CN")
user_agent = f.user_agent()
phone = f.phone_number()
url = r"https: // download.zslxt.com / tinterface.php"
headers = {
"Host": "download.zslxt.com",
"User-Agent": user_agent,
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "http:/gpyd.gp241.com/nyqpc/bd2.html?id=20110052",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Content-Length": "107",
"Origin": "http://gpyd.gp241.com",
"Connection": "keep-alive"
}
data = {
"bm": "gbk",
"gpdm": "",
"id": "20110052",
"phone": phone,
"qudao": 98,
"remarks": "牛有圈百度2)"
}
req = requests.post(url=url, headers=headers, data=json.dumps(data))
然后就快要完成了,为了方便循环发送数据,我们再把它整理成一段函数:
其实我一开始学python真的不喜欢写函数,毕竟那么两行代码就能写完了,包装成一个函数简直就是在凑代码行数,毫无用途,但是我今天看到了一个故事:
为了检测空的奶盒子,博士后和农民用两种方式解决了这个问题:发明一台机器,使用了一台风扇
但是很多时候我们新学东西时遇到的问题都可以用以前就会的方法解决这个问题,但是随着问题的深入,有时候就只能使用新学的只是来解决以后遇到的问题了,写写函数(包装成类)总是没错的,前提是这个代码你是用来练手的,而不是用来应急的.
import requests
import json
from faker import Faker
f = Faker(locale="zh-CN")
def duang():
user_agent = f.user_agent()
phone = f.phone_number()
url = r"https: // download.zslxt.com / tinterface.php"
headers = {
"Host": "download.zslxt.com",
"User-Agent": user_agent,
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "http:/gpyd.gp241.com/nyqpc/bd2.html?id=20110052",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Content-Length": "107",
"Origin": "http://gpyd.gp241.com",
"Connection": "keep-alive"
}
data = {
"bm": "gbk",
"gpdm": "",
"id": "20110052",
"phone": phone,
"qudao": 98,
"remarks": "牛有圈百度2)"
}
req = requests.post(url=url, headers=headers, data=json.dumps(data))
return user_agent, phone, req
这样我们就可以方便的进行调用了,写个main函数来调用它
import requests
import json
from faker import Faker
f = Faker(locale="zh-CN")
def duang():
user_agent = f.user_agent()
phone = f.phone_number()
url = r"https: // download.zslxt.com / tinterface.php"
headers = {
"Host": "download.zslxt.com",
"User-Agent": user_agent,
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "http:/gpyd.gp241.com/nyqpc/bd2.html?id=20110052",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Content-Length": "107",
"Origin": "http://gpyd.gp241.com",
"Connection": "keep-alive"
}
data = {
"bm": "gbk",
"gpdm": "",
"id": "20110052",
"phone": phone,
"qudao": 98,
"remarks": "牛有圈百度2)"
}
req = requests.post(url=url, headers=headers, data=json.dumps(data))
return user_agent, phone, req
if __name__ == '__main__':
for i in range(100000):
user_agent, phone, req = duang()
print(i, '\t', phone, '\t', req.status_code, '\n', user_agent)
这里就是输出一下信息啦,刚才出去吃饭的时候断网了,只跑了3000多,这里就不截图了(如果真有用来练手的朋友可以尝试自己完善一下代码,断网后也可以等待并继续执行)
附上全部代码(写到mysql了):
import pymysql
import requests
import json
from faker import Faker
f = Faker(locale="zh-CN")
def duang():
user_agent = f.user_agent()
phone = f.phone_number()
url = r"https: // download.zslxt.com / tinterface.php"
headers = {
"Host": "download.zslxt.com",
"User-Agent": user_agent,
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "http:/gpyd.gp241.com/nyqpc/bd2.html?id=20110052",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Content-Length": "107",
"Origin": "http://gpyd.gp241.com",
"Connection": "keep-alive"
}
data = {
"bm": "gbk",
"gpdm": "",
"id": "20110052",
"phone": phone,
"qudao": 98,
"remarks": "牛有圈百度2)"
}
req = requests.post(url=url, headers=headers, data=json.dumps(data))
return user_agent, phone, req.status_code
if __name__ == '__main__':
for i in range(100000):
user_agent, phone, status_code = duang()
db = pymysql.connect("localhost", "root", "xiaoyan", "python")
cur = db.cursor()
cur.execute(f"INSERT INTO python1duang VALUES(default,'{user_agent}','{phone}','{status_code}')")
db.commit()
print(i, '\t', phone, '\t', status_code, '\n', user_agent)
db.close()python3爬虫入门程序的更多相关文章
- Python爬虫入门教程 37-100 云沃客项目外包网数据爬虫 scrapy
爬前叨叨 2019年开始了,今年计划写一整年的博客呢~,第一篇博客写一下 一个外包网站的爬虫,万一你从这个外包网站弄点外快呢,呵呵哒 数据分析 官方网址为 https://www.clouderwor ...
- Python爬虫入门教程 36-100 酷安网全站应用爬虫 scrapy
爬前叨叨 2018年就要结束了,还有4天,就要开始写2019年的教程了,没啥感动的,一年就这么过去了,今天要爬取一个网站叫做酷安,是一个应用商店,大家可以尝试从手机APP爬取,不过爬取APP的博客,我 ...
- python3爬虫之入门和正则表达式
前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享:爬虫说的简单,就是去抓取网路的数据进行分析处理:这章主要入门,了解几个爬虫的小测 ...
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
- Python2.x爬虫入门之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: (1)网络无连接,即本机无法上网 (2)连 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- 【爬虫入门01】我第一只由Reuests和BeautifulSoup4供养的Spider
[爬虫入门01]我第一只由Reuests和BeautifulSoup4供养的Spider 广东职业技术学院 欧浩源 1.引言 网络爬虫可以完成传统搜索引擎不能做的事情,利用爬虫程序在网络上取得数据 ...
随机推荐
- C#实现焦点变色
Form1.cs using System;using System.Collections.Generic;using System.ComponentModel;using System.Data ...
- linux之创建用户
用户 useradd xxx 创建用户 默认是普通用户 useradd -u666 web 创建新用户 设置id号 groupadd -g 777 ...
- Sql Server索引重建
公司线上数据有几千万数据,有时候索引碎片会导致索引达不到我们的预期查询效率,这个时候将索引重建将会提升一定效率,不过重建的时候一定得晚上用户少的时候,索引重建需要一定时间. 直接贴自动重建索引脚本吧 ...
- JAVA002标识符的命名规则、关键字
标志符命名规则: 1.标志符可以由字母.数字.下划线(_)和美元符号($)组成,不能以数字开头($sen.Void) 2.标志符严格区分大小写 3.标志符不能是Java的关键字和保留字(eg:publ ...
- 使用selenium爬取网站动态数据
处理页面动态加载的爬取 selenium selenium是python的一个第三方库,可以实现让浏览器完成自动化的操作,比如说点击按钮拖动滚轮等 环境搭建: 安装:pip install selen ...
- freeswitch黑名单mod_blacklist使用
freeswitch自带黑名单模块"mod_blacklist",此文只是对该模块简单使用的实例. 最近接到客户投诉有大量骚扰电话,而从源头查不太容易,因此想到的笨方法是将投诉人加 ...
- Restful架构学习
Restful规范的架构是一种简洁并且面向资源的规范方式,其概念和起源大家google一下就好. 以下记录认识和搭建Restful规范的技术架构过程(入门级别),在网上发现了一张技术架构图很接近最初想 ...
- 在IDEA中实战Git-branch
工作中多人使用版本控制软件协作开发,常见的应用场景归纳如下: 假设小组中有两个人,组长小张,组员小袁 场景一:小张创建项目并提交到远程Git仓库 场景二:小袁从远程Git仓库上获取项目源码 场景三:小 ...
- python中的copy.copy和copy.deepcopy
一个例子就搞清楚 import copy a = [1, 2, 3, 4, ['a', 'b']] #原始对象 b = a #赋值,传对象的引用 c = copy.copy(a) #对象拷贝,浅拷贝 ...
- DevExpress.XtraGrid.GridControl中数据源的绑定问题
在利用DevExpress.XtraGrid.GridControl作为一个可编辑的表格控件时,在利用控件之前,先将一个初始化的DataTable对象作为GridControl的数据源进行绑定.可是在 ...