[原]OpenStreetMap数据瓦片服务性能篇
上文说到如何利用node-mapnik架设OpenStreetMap瓦片服务,解决了有没有的问题。然而这个服务还是比较孱弱,主要表现在以下几个方面:
1. Node.js只能使用CPU的一个核,不能有效发挥服务器的多核优势;
2. 前端使用了一台TileStrata服务器,即无法实现负载均衡,也无法实现服务主备冗余;
3. 后端使用了一台PostgreSQL,和前端一样,无法达到高性能和高可用性;
4. 在Node.js和PostgreSQL之间没有使用连接池,造成数据数性能低下;
针对这些问题,本文将给出解决方案。然而“调优性能”的关键是“调”,本文只是给出思路和一般性方法,可能无法真正在您的环境中能起到立竿见影的效果。针对具体的环境,可能需要采用具体的参数。接下来,我将从后端到前端来介绍。
一、PostgreSQL连接池
本文不打算提PostgreSQL性能调优,因为这一块太大、太深奥,我自已也没有什么好的心得体会,就不耽误大家了,接下来有工夫了我也要好好的学习下PostgreSQL性能调优技术。请大家自行Google,如果有好的方法记得留言分享哦:)
当应用程序直接访问PostgreSQL时,每次连接时PostgreSQL者会克隆出一个服务进程来为应用程序服务,在关闭连接后,PostgreSQL将自动把服务进程停掉。频繁的创建和销毁进程,会大大消耗服务器资源。要解决这个问题,就要引入数据库连接池,把连接缓存住,实现降低服务器资源消耗的目的。
PostgreSQL有两个知名的连接池: PgBouncer (官网)和 Pgpool-II (官网)。其中 PgBouncer比较单纯,仅作数据库连接池之用;而 Pgpool-II则功能较为强大,除可用于连接池外,还能用于PostgreSQL服务复制、负载均衡以及并行查询。然而貌似 Pgpool-II 在集群中的服务和并发连接较少时效果并不显著,甚至还要性能还要远低于单机性能,所以这里就不考虑使用 Pgpool-II 了。本文将选用 PgBouncer 作为PostgreSQL的连接池。下面将介绍安装及配置方法。
1. 从yum安装pgbouncer及工具的依赖项
yum install pgbouncer python-psycopg2 -y
2. 修改pgbouncer配置
vim /etc/pgbouncer/pgbouncer.ini
a. [databases] 节
#gis = 是PgBouncer公开给客户端的数据库名称,可以和实际数据库不一致
#connect_query=验证数据库是否正常连接
#此外没有指定user和password参数,将从下面的pgbouncer配置节中从auth_file中匹配 gis = host=127.0.0.1 port=5432 dbname=gis datestyle=ISO connect_query='SELECT 1'
b. [pgbouncer] 节
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
#*代表任意地址
listen_addr = *
listen_port = 6432 auth_type = md5
#auth_file是连接数据库的用户名和密码匹配文件
auth_file = /etc/pgbouncer/userlist.txt
#postgres是可以登录到虚拟的pgbouncer库的管理用户
admin_users = postgres
stats_users = stats, postgres pool_mode = session server_reset_query = DISCARD ALL max_client_conn = 100
default_pool_size = 20
3. 生成 auth_file 文件,该文件存储实际用于登录的用户名和密码。
cd /etc/pgbouncer
# 第二个参数将使用PostgreSQL的配置项
./mkauth.py "/etc/pgbouncer/userlist.txt" "dbname='postgres' user='postgres' password='111111' host='127.0.0.1'" chown pgbouncer:pgbouncer userlist.txt
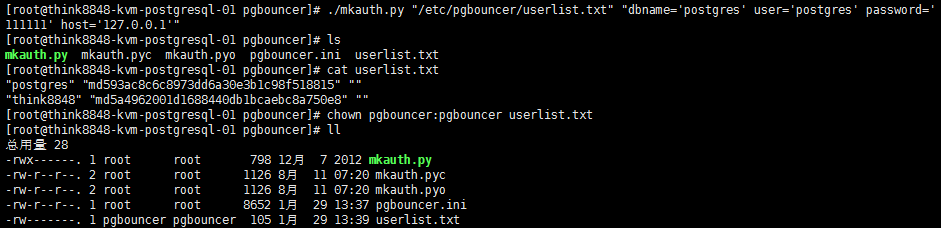
4. 启动并验证pgbouncer ,注意,此处不可使用 root 用户,请使用安装包自动创建的 pgbouncer 用户
su pgbouncer pgbouncer -d /etc/pgbouncer/pgbouncer.ini

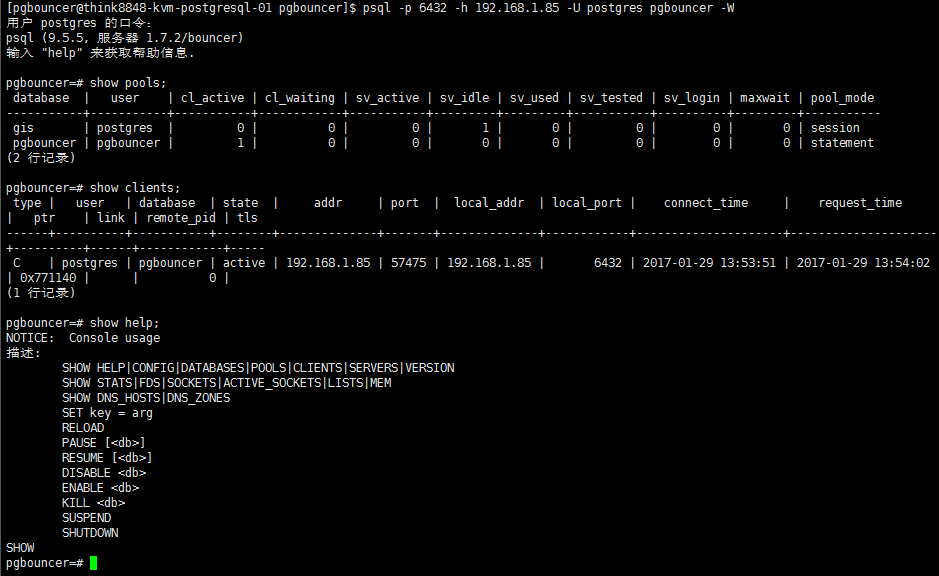
5. 查看pgbouncer连接池和客户端
#经实测,如果不使用-h参数将无法登录
psql -p 6432 -h 127.0.0.1 -U postgres -d pgbouncer -W show pools; show clients; show help;
6. 关闭pgbouncer
sudo pkill -9 -f 'pgbouncer'
二、PostgreSQL主备模式
PostgreSQL提供了Standby(主备)模式,用于实现一台主数据库、n台备数据库,达到高可用性的目的。该模式也顺便为实现多台只读数据库提供了条件。接下来将介绍如何实现Standby模式。
1. 安装PostgreSQL主库步骤(过程略),详情请参见《CentOS7下安装并简单设置PostgreSQL笔记》
2. 导入OpenStreetMap数据(过程略),详情请参见《CentOS7部署PostGis》、《CentOS7部署osm2pgsql》
3. 安装PostgreSQL备库(终于到主角上场了),咱就不再Step by Step了,直接一次性装上。
yum install http://yum.postgresql.org/9.5/redhat/rhel-7-x86_64/pgdg-redhat95-9.5-2.noarch.rpm -y yum install postgresql95-server postgresql95-contrib -y #安装PostGis
yum install postgis2_95 postgis2_95-client ogr_fdw95 pgrouting_95 -y
mkdir /home/postgresql_data
4. 修改主库配置,请注意,这里不是修改刚安装好的数据库,而是修改第1步中主库的配置文件
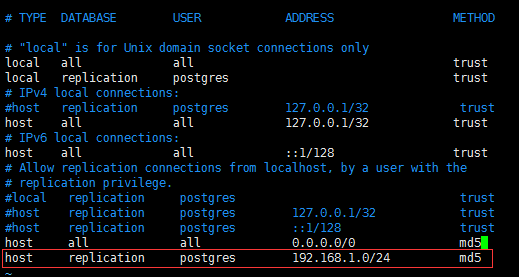
a. $PGPATH下的 pg_hba.conf 文件
在文件最下面添加如下配置
host replication postgres 192.168.1.0/24 md5
b. $PGPATH下 postgresql.conf 文件,确保有三处配置如下:
i. listen_address = '*'
ii. wal_level = hot_standby
iii. max_wal_senders = 5
c. 为postgres数据库帐号设置密码
ALTER USER postgres WITH PASSWORD '111111'
d. 重启Postgresql服务,使配置生效 systemctl restart postgresql-9.5
5. 在备库服务器上生成基础备份,请注意,此处回到备库的服务器进行操作
# -D参数是你要把主库备份出来的目的目录
# -l参数是你备份的标签,请随意 pg_basebackup -h 192.168.1.99 -U postgres -F p -P -x -R -D /home/postgresql_data -l pgbak201701291308
6. 修改备库配置文件, vim /home/postgresql_data/postgresql.conf
hot_standby = on
7. 设置备库数据目录的所有者和权限
chown -R postgres:postgres /home/postgresql_data chmod -R 700 /home/postgresql_data
8. 设置备库postgresql服务启动选项 vim /usr/lib/systemd/system/postgresql-9.5.service
Environment=PGDATA=/home/postgresql_data
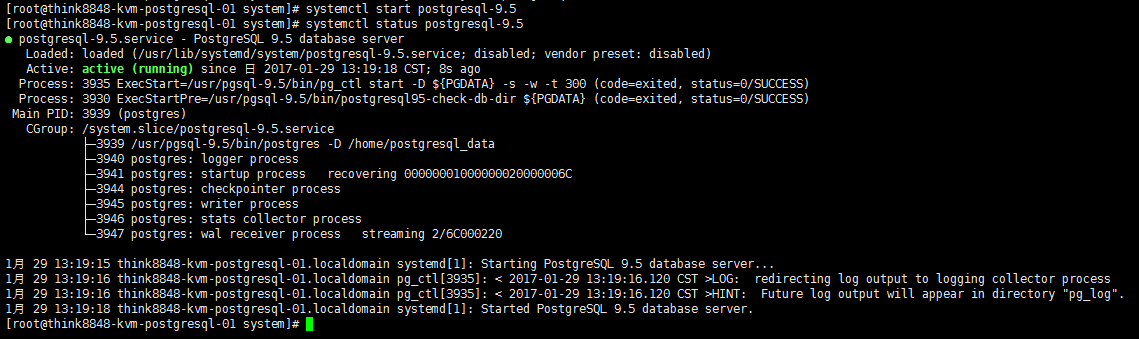
9. 启动备库并查看状态
systemctl start postgresql-9.5 systemctl status postgresql-9.5
10. 查看备库状态:
11. 验证主备模式是否有效,当前主库的测试表数据是:
select * from tetst01;
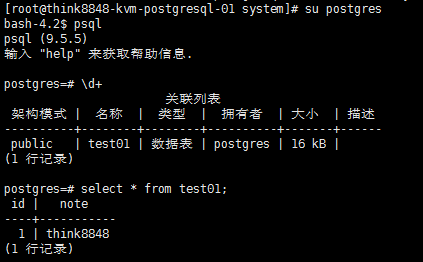
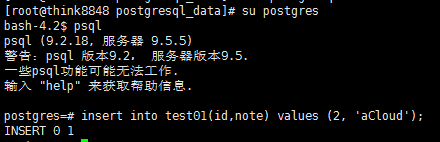
在主库中添加一行数据
insert into test01(id,note) values (2, 'aCloud');
再在备库中查询
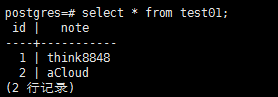
至此,PostgreSQL的主备模式构建完成。
三、使用HAProxy 实现PostgreSQL负载均衡
上一节中我们通过建立Standby模式,在一台主数据库和n台备数据库之间实现了数据同步。虽然备数据库只能提供只读服务,然而对于存储地理空间数据的应用而言,90%的情况下就够用了,因为我们要修改数据的时机还是比较少的,因此采用负载均衡技术将应用程序对数据库的请求分摊到几台数据库服务器上,将有助于性能提升。
通常而言,负载均衡服务软件有三种:Nginx、HAProxy和LVS。Nginx在网络的第7层、LVS在网络的第4层,而HAProxy在4、7层都可以工作,而且有文章指出,HAProxy在虚拟机上能较好的工作,So,不费劲了,直接选HAProxy吧。
1. 安装HAProxy
yum install haproxy -y
2. 配置HAProxy, vim /etc/haproxy/haproxy.cfg ,配置文件中超时时间和网络检查时间设置的偏大,这是因为如果这些值设置的太小的话,postgresql在进行运算时,旧的查询还没有完成,新的请求或检查就来了,就造成超时了。这个问题在以后有时间了再好好的研究下,看是否有更好的办法。目前使用这个方法也能解决问题。
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode tcp
log global
option redispatch
option httplog
retries 10
timeout queue 5m
timeout connect 5m
timeout client 5m
timeout server 5m
timeout http-keep-alive 20m
timeout check 1m
maxconn 3000
listen webservers
bind 0.0.0.0:808
mode http
log global
stats refresh 30s
stats realm Private lands
stats uri /admin?stats
stats auth admin:111111
listen postgres
bind 0.0.0.0:7432
mode tcp
balance roundrobin
server pg1 192.168.1.99:6432 weight 1 maxconn 1000 check inter 5m
server pg2 192.168.1.80:6432 weight 1 maxconn 1000 check inter 5m
server pg3 192.168.1.85:6432 weight 1 maxconn 1000 check inter 5m
server pg4 192.168.1.86:6432 weight 1 maxconn 1000 check inter 5m
3. 防火墙打洞
firewall-cmd --zone=public --add-port=7432/tcp --permanent firewall-cmd --reload
4. 关闭SELinux(规则太难配,干脆关了), vim /etc/selinux/config
SELinux=disabled
5. 启动HAProxy
systemctl start haproxy systemctl enable haproxy
6. 使用 http://haproxyaddr:port/admin?stats 可对HAProxy状态进行监控。这里我们可以看到目前状态正常。

7. 至此,我们已经有了四个PostgreSQL数据库,并且使用HAProxy进行负载均衡,下面就可以配置mapnik,使用HAProxy。打开 OpenStreetMap-Carto 文件夹(不知道这个文件夹在什么地方?请参考《使用node-mapnik生成openstreetmap-carto风格的瓦片》一文中的设置),修改 project.mml ,将其中的 host 、 port 修改为HAProxy的地址和侦听端口,将 dbname 修改为 pgbouncer.ini 中 [databases] 的值。将 user 、 password 修改为 pgbouncer.ini 中 auth_file 文件中的相应用户名和密码信息。

8. 重新生成mapnik配置
carto project.mml > mapnik.xml
此时, node-mapnik 就可以使用HAProxy提供的服务了。
四、TileStrata实现瓦片服务负载均衡
1. 《使用node-mapnik和openstreetmap数据初步搭建瓦片服务》的第四节,已经讲了TileStrata提供的 TileStrata-Balancer 组件实现瓦片服务负载均衡,本文继续使用该节内容,有需要的筒子们请参考。效果如下:
tilestrata-balancer --hostname=192.168.1.51 --port=8083 --private-port=8081 --check-interval=5000 --unhealthy-count=1
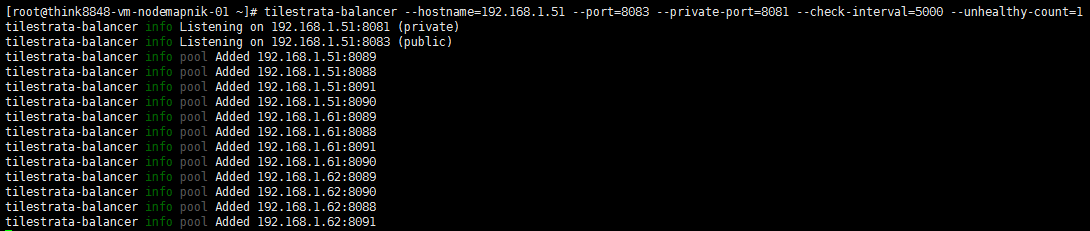
注意:记得在提供瓦片服务的服务器上打开相应的防火墙端口。为了省事,最好把SELinux关闭掉。最后,不要把tilestrata-balancer的private端口公布到公网上。
五、Node.js的单机集群
Node.js应用程序一般情况下仅能使用CPU的一个核,要充分利用CPU,最好是每个核上跑一个Node.js的程序。简单点来说,Node.js内置了这一实现,看下面代码:
1. tileserver/server/cluster.js ,在这个文件中,Node.js将在每一个CPU的核心上执行一个 ./server.js 文件。为了能成功加入到 tilestrata-balancer ,我给每一个fork指定一个单独的端口号
var cluster = require('cluster');
var cpus = require('os').cpus();
cluster.setupMaster({
exec: './server.js'
});
for(var i = 0; i < cpus.length; i++){
var port = 8088 + i;
cluster.fork({port : port});
}
2. tileserver/server/server.js ,在 cluster.js 传来的端口上进行侦听
var tilestrata = require('tilestrata');
var disk = require('tilestrata-disk');
var mapnik = require('tilestrata-mapnik');
var strata = tilestrata({
balancer: {
host: '192.168.1.51:8081'
}
});
strata.layer('map')
.route('tile.png')
.use(disk.cache({dir: './tilecache'}))
.use(mapnik({
pathname: '/home/openstreetmap/openstreetmap-carto/mapnik.xml'
}));
var port = process.env['port'];
strata.listen(port);
3. 进入服务端程序目录,启动程序
cd projectdir/tileserver/server node cluster
可以看到四核CPU,就起了四个端口,效果如下:
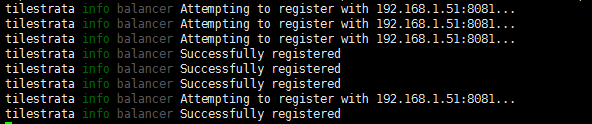
六、OpenLayers使用多个瓦片服务器
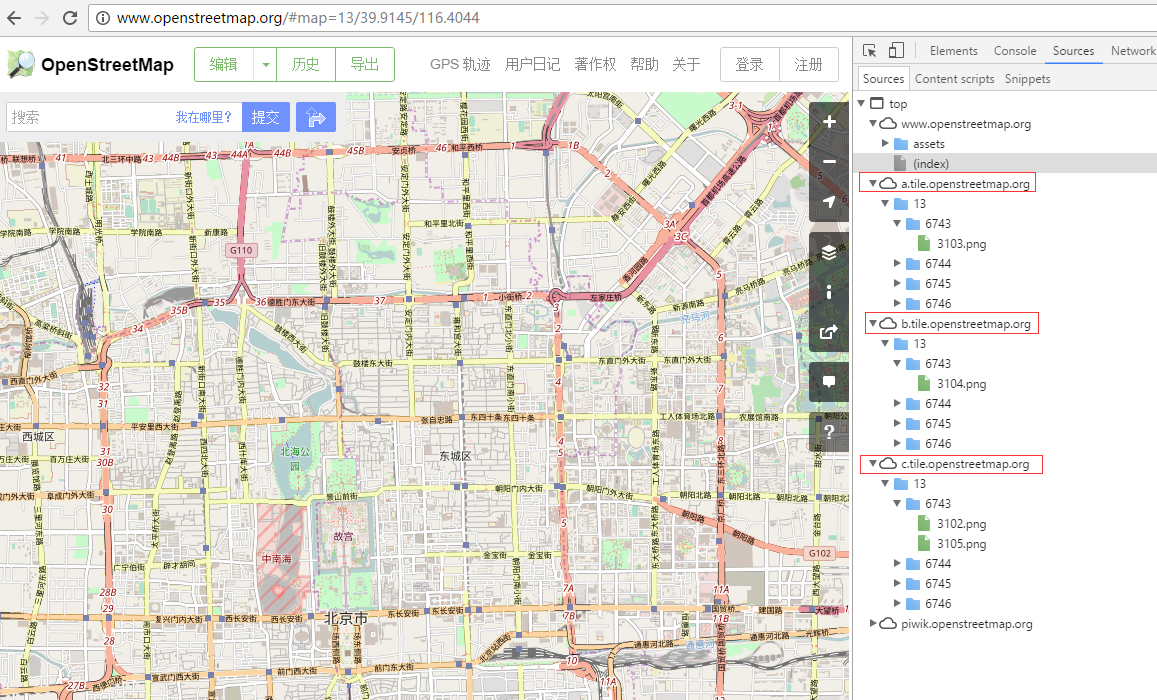
如果我们看OpenStreetMap官网,就可以发现它使用的瓦片服务器可不止一台,下面我们看如何使用OpenStreetMap来实现类似效果(OpenStreetMap使用的是Leaflet)
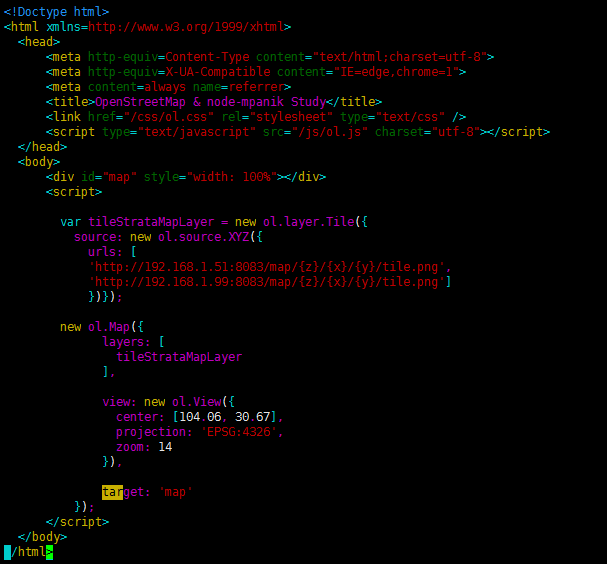
只需要定义Tile时,指定 ulrs 属性为一个瓦片服务Url的数组就行了
var tileStrataMapLayer = new ol.layer.Tile({
source: new ol.source.XYZ({
urls: [
'http://192.168.1.51:8083/map/{z}/{x}/{y}/tile.png',
'http://192.168.1.99:8083/map/{z}/{x}/{y}/tile.png']
})});
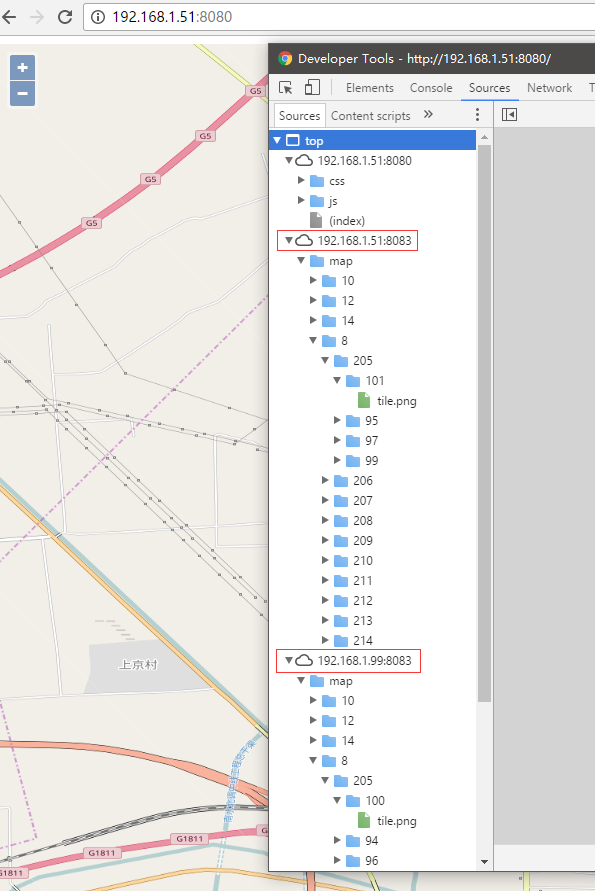
效果如下:
后记:
前前后后好长时间了,主要还是时间严重不足,导致这个系列进度过于缓慢,而且每一篇都只能草草的讲讲过程,对于其中的原理讲的很少。但这也没有办法,过完春节后可能工作要更忙了,所以OpenStreetMap、node-mapnik这个系列很可能不会再做深入的学习了。未来主要是想办法将这些技术应用到工作中,以及提升这些技术的高性能、高可用性。欢迎有相同兴趣的兄弟一起研讨。每次写文章,都是趁着休息时间弄,文字上面也不太讲究,不太通顺的地方请谅解。
如果非得让我学点新的,我希望能实现Docker下的OpenStreetMap数据服务和OpenStreetMap数据的WMS服务。
转载请注明原作者(think8848)和出处(http://think8848.cnblogs.com)
[原]OpenStreetMap数据瓦片服务性能篇的更多相关文章
- [原]使用node-mapnik和openstreetmap数据初步搭建瓦片服务
最近依然还是有点小忙,只能挤点时间来学习点,先解决有没有的问题,再解决好不好的问题:) 本文将承接上文<使用node-mapnik生成openstreetmap-carto风格的瓦片>的内 ...
- [原]在GeoServer中为OpenStreetMap数据设置OSM样式
转载请注明作者think8848和出处(http://think8848.cnblogs.com) 在前面几篇文章中,我们讲到了部署Postgresql,部署PostGis,部署GeoServer以及 ...
- 阿里云大数据计算服务 - MaxCompute (原名 ODPS)
MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务.去年MaxCompute 做了哪些工作,这些工作背后的原因是什么?大数据市场进入 ...
- 【朝花夕拾】Android性能篇之(六)Android进程管理机制
前言 Android系统与其他操作系统有个很不一样的地方,就是其他操作系统尽可能移除不再活动的进程,从而尽可能保证多的内存空间,而Android系统却是反其道而行之,尽可能保留进程.An ...
- 【朝花夕拾】Android性能篇之(五)Android虚拟机
前言 Android虚拟机的使用,使得android应用和Linux内核分离,这样做使得android系统更稳定可靠,比如程序中即使包含恶意代码,也不会直接影响系统文件:也提高了跨平台兼容性.在And ...
- 【朝花夕拾】Android性能篇之(一)序言及JVM
序言 笔者从事Anroid开发有些年头了,深知掌握Anroid性能优化方面的知识的必要性,这是一个程序员必须修炼的内功.在面试中,它是面试官的挚爱,在工作中,它是代码质量的拦路虎,其重要 ...
- 基于APNs最新HTTP/2接口实现iOS的高性能消息推送(服务端篇)
1.前言 本文要分享的消息推送指的是当iOS端APP被关闭或者处于后台时,还能收到消息/信息/指令的能力. 这种在APP处于后台或关闭情况下的消息推送能力,通常在以下场景下非常有用: 1)IM即时通讯 ...
- 后Hadoop时代的大数据技术思考:数据即服务
1. Hadoop 的神话正在破灭 IBM leads BigInsights for Hadoop out behind barn. Shots heard IBM has announced th ...
- 打造H5动感影集的爱恨情仇–动画性能篇
“你听说过动感影集么?” 动感影集是QQ空间新功能,可以将静态的图片轻松转变为动态的视频集,且载体是HTML5(简称H5)页面,意味着可以随时分享到空间或朋友圈给好友欣赏! 移动端区别于PC年代的相册 ...
随机推荐
- Python调用ffpmeg和ffprobe处理视频文件
需求: 运营有若干批次的视频.有上千个,视频文件,有mp4格式的,有ts格式的 现在有需要去掉视频文件片头和片尾的批量操作需求. 比如 文件夹A下面的视频去掉片尾10秒 文件夹B下面的视频去掉片头6秒 ...
- 18.4 #if 0…endif的用途
#if 0 ... #endif的作用跟/*...*/的作用是一样的,就是注释! 可是为什么不用注释符号/*? 答:为了解决嵌套注释.如下: #include“stdio.h” int mai ...
- java fail-fast和fail-safe
快速失败(fail—fast) 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(如增加.删除等),则会抛出Concurrent Modification Exception. ...
- https://api.highcharts.com/gantt/
<a href="https://api.highcharts.com/gantt/">https://api.highcharts.com/gantt/</a& ...
- 关于Java流
- # 20175227 2018-2019-2 《Java程序设计》第二周学习总结
20175227 2018-2019-2 <Java程序设计>第二周学习总结 教材学习内容总结 1. 根据蓝墨云上的学习视频,自学第二.三章知识,并自行编译调试书上程序. 2. 第二章主要 ...
- redis总结问题
简单回顾了redis,在这过程中 首先得了解redis是什么,redis的运用场景,redis支持哪些数据格式,redis如何操作数据,redis如何实现高可用 redis是什么: Redis 是一个 ...
- [SQL]T-Sql 递归查询(给定节点查所有父节点、所有子节点的方法)
T-Sql 递归查询(给定节点查所有父节点.所有子节点的方法) -- 查找所有父节点with tab as( select Type_Id,ParentId,Type_Name from Sys_ ...
- Java笔记Spring(三)
spring-beans和spring-context 一.注解 1.自定义一个注解 @Target({ElementType.METHOD}) @Retention(RetentionPolicy. ...
- linux服务samba与ftp篇
samba复习: 1.下载samba:yum -y install samba 2.打开配置文件/etc/samba/smb.conf输入: [共享文件名] path = 目录名 (事先创建) pub ...