Node爬取简书首页文章
Node爬取简书首页文章
博主刚学node,打算写个爬虫练练手,这次的爬虫目标是简书的首页文章
流程分析
- 使用superagent发送http请求到服务端,获取HTML文本
- 用cheerio解析获得的HTML文本,本例将解析简书首页20篇文章的基本信息
- 使用mysql模块把解析出的数据写入本地数据库存储
第三方模块
superagent
superagent是一个优雅又轻量级的网络请求API,类似于Python中的requests。官方文档在这里
$ npm install superagent
基本用法
Post请求
request
.post('url')
.send({ name: 'Manny', species: 'cat' }) //发送的数据
.set('X-API-Key', 'foobar') // set用来设置http请求头
.set('Accept', 'application/json')
.end(function(err, res){ // 请求发送结束后监听服务器相应,注册回调函数
if (err || !res.ok) {
alert('Oh no! error');
} else {
alert('yay got ' + JSON.stringify(res.body));
}
});
// 链式写法
request.post('/user')
.send({ name: 'tj' })
.send({ pet: 'tobi' })
.end(callback)
Get请求
request
.get('url')
.query({ query: 'Manny', range: '1..5', order: 'desc' }) //加查询参数
.end(function(err, res){
// do something
});
// 链式写法
request
.get('/querystring')
.query('search=Manny')
.query('range=1..5')
.end(function(err, res){
});
cheerio
cheerio是一个快速优雅的node解析库,可以再服务器端使用jQuery的方法完成dom操作,官方文档在这里
在本爬虫中,用于完成html解析查询的工作
$ npm install cheerio
基本用法
const cheerio = require('cheerio')
const $ = cheerio.load('<h2 class="title">Hello world</h2>') //导入html
// 查询并修改dom树内容
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
mysql
mysql用于最后数据的写入,执行SQL插入工作,只执行sql插入
$ npm install mysql
目标分析
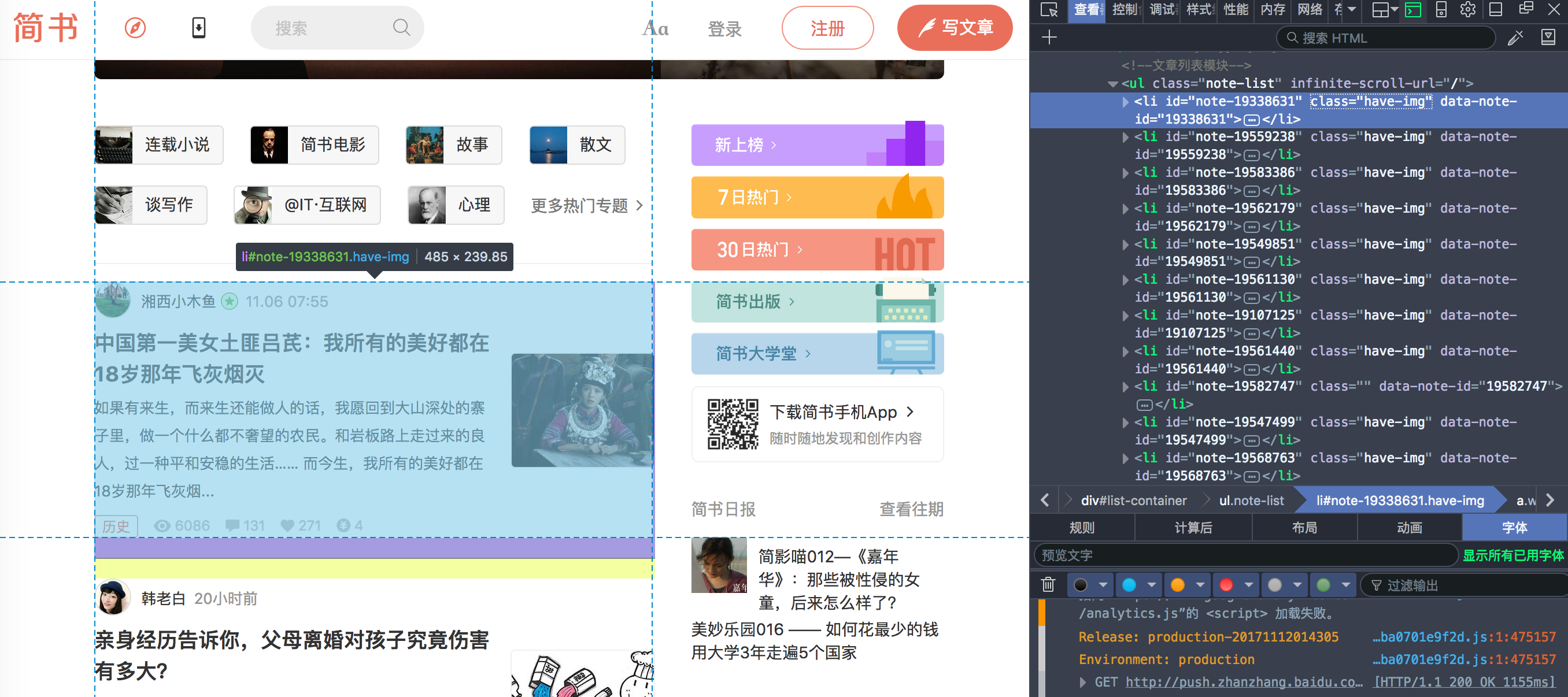
我们用firefox的开发者工具查看网页,目标是一个note-list下面的20个li,每个li是一篇文章,我们只要遍历20篇文章并且对于每个节点的内容进行解析即可
实现代码
const superagent = require('superagent')
const cheerio = require('cheerio')
const util =require('util')
const mysql = require('mysql')
// 定义爬取对象
const reptileUrl = 'http://www.jianshu.com/'
// 创建mysql数据库连接
const connection = mysql.createConnection({
host:'localhost',
user:'***',
password:'***',
database:'jianshu'
})
connection.connect()
//发送请求
superagent.get(reptileUrl).end(function (err, res) {
// 错误拦截
if (err){
throw err
}
else{
// res.text是响应的原始html
var $ = cheerio.load(res.text)
var articleList = $("#list-container .note-list li")
articleList.each(function(_, item){
//获取当前item
var _this = $(item)
// 文章名
var title = _this.find('.title').text().trim()
// 作者
var nickname = _this.find('.nickname').text().trim()
// 摘要
var abstract = _this.find('.abstract').text().trim()
// 分类, 有些未分类的就分到『其他』
var tag = _this.find('.collection-tag').text().trim()||"其他"
// 阅读量
var read = _this.find('.ic-list-read').parent().text().trim()
// 评论数
var comment = _this.find('.ic-list-comments').parent().text().trim()
// 点赞数
var like = _this.find('.ic-list-like').parent().text().trim()
// 解析后把数据写入数据库
var base = "insert into articles " +
"(title, nickname, abstract, tag, readNum, commentNum, likeNum)" +
"values(%s,%s,%s,%s,%s,%s,%s)"
var sql = util.format(base,
"'"+title+"'",
"'"+nickname+"'",
"'"+abstract+"'",
"'"+tag+"'",
"'"+read+"'",
"'"+comment+"'",
"'"+like+"'")
connection.query(sql, function (error, results) {
if (error){
console.error(error)
}
else{
console.log(sql)
}
})
})
// 关闭数据库连接
connection.end()
}
})
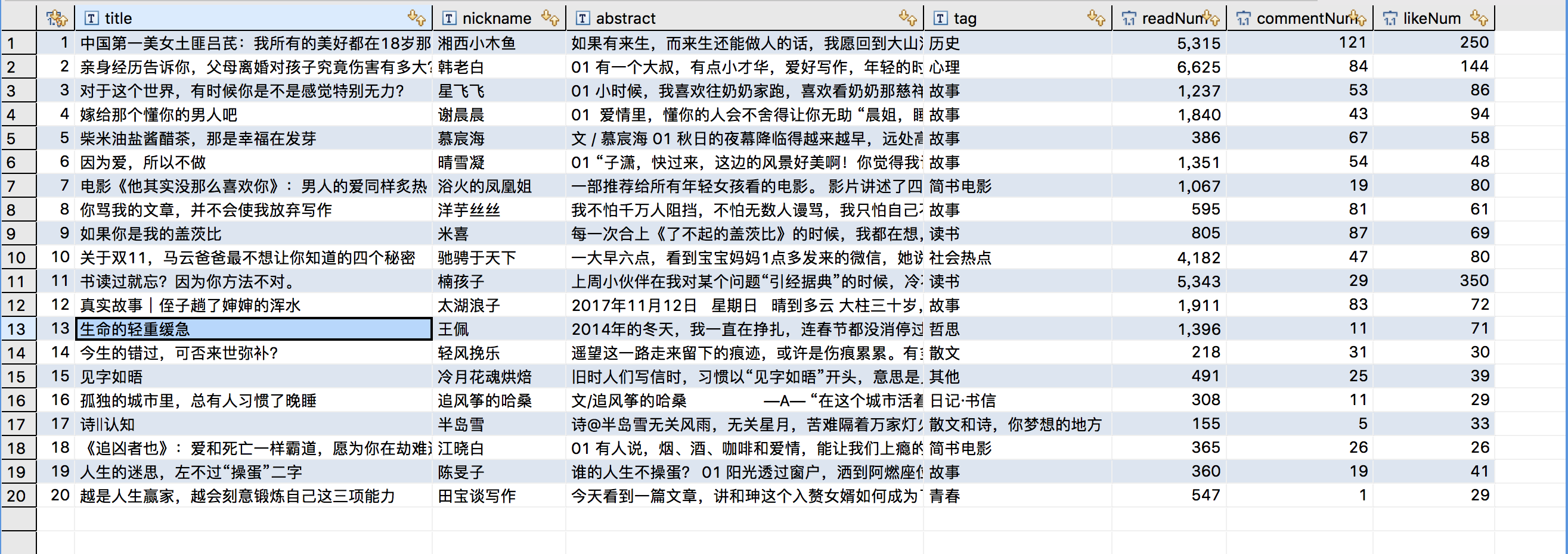
运行结果
小结
感觉node编程就要经常考虑异步和回调,思维方式与Python,Java不同。例如get是一个异步的行为,之前博主按照惯例在最后关闭数据库连接,结果竟然在服务器响应之前数据库连接已经断开,导致后面数据写入出错。
填node的坑还是任重道远啊……
Node爬取简书首页文章的更多相关文章
- Python爬取简书主页信息
主要学习如何通过抓包工具分析简书的Ajax加载,有时间再写一个Multithread proxy spider提升效率. 1. 关键点: 使用单线程爬取,未登录,爬取简书主页Ajax加载的内容.主要有 ...
- python3 爬取简书30日热门,同时存储到txt与mongodb中
初学python,记录学习过程. 新上榜,七日热门等同理. 此次主要为了学习python中对mongodb的操作,顺便巩固requests与BeautifulSoup. 点击,得到URL https: ...
- Scrapy+selenium爬取简书全站
Scrapy+selenium爬取简书全站 环境 Ubuntu 18.04 Python 3.8 Scrapy 2.1 爬取内容 文字标题 作者 作者头像 发布日期 内容 文章连接 文章ID 思路 分 ...
- python2.7 爬取简书30日热门专题文章之简单分析_20170207
昨天在简书上写了用Scrapy抓取简书30日热门文章,对scrapy是刚接触,跨页面抓取以及在pipelines里调用settings,连接mysql等还不是很熟悉,今天依旧以单独的py文件区去抓取数 ...
- 【python3】爬取简书评论生成词云
一.起因: 昨天在简书上看到这么一篇文章<中国的父母,大都有毛病>,看完之后个人是比较认同作者的观点. 不过,翻了下评论,发现评论区争议颇大,基本两极化.好奇,想看看整体的评论是个什么样, ...
- scrapy爬取简书整站文章
在这里我们使用CrawlSpider爬虫模板, 通过其过滤规则进行抓取, 并将抓取后的结果存入mysql中,下面直接上代码: jianshu_spider.py # -*- coding: utf-8 ...
- 爬取简书图片(使用BeautifulSoup)
import requests from bs4 import BeautifulSoup url_list = [] kv = {'User-Agent':'Mozilla/5.0'} r = re ...
- python 爬取简书评论
import json import requests from lxml import etree from time import sleep url = "https://www.ji ...
- jsoup爬虫简书首页数据做个小Demo
代码地址如下:http://www.demodashi.com/demo/11643.html 昨天LZ去面试,遇到一个大牛,被血虐一番,发现自己基础还是很薄弱,对java一些原理掌握的还是不够稳固, ...
随机推荐
- Ubuntu16.04安装配置和使用ctags
Ubuntu16.04安装配置和使用ctags by ChrisZZ ctags可以用于在vim中的函数定义跳转.在ubuntu16.04下默认提供的ctags是很老很旧的ctags,快要发霉的版本( ...
- python虚拟环境搭建
1.安装python环境 2.检查pip 3.pip install virtualenv 4.创建测试:virtualenv testvir 5.pip install virtualenvwra ...
- KnockOut -- 快速入门
简单示例 <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf- ...
- Top 查看某些或者某个进程(top -p pid)
https://blog.csdn.net/zhangfn2011/article/details/7488746?utm_source=blogxgwz5
- 关于SQL Server中的系统表之一 sysobjects
微软Sql Server数据库是企业开发管理中最常用的数据库系统之一.其功能强大而且使用简单.方便.我们在数据库中创建数据库.表.视图.触发器.存储过程.函数等信息. 最常用的功能之一,查询数据,例如 ...
- Filebeat6.31整合Kafka集群消息队列(三)
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-linux-x86_64.tar.gz [root@ ...
- nginx限制单个IP的最大连接数量限制下载速度
今天seafile服务因为测试在下载文件的时候,带宽占用过大,导致seafile客户端无法登陆的问题. 我们公司的seafile是通过nginx代理的8000端口,因此我这边通过修改nginx配置来解 ...
- bug管理
BUG提交规范 1.标题 2.步骤描述 ①.步骤使用序号编排 ②.在特定情况下发生的问题,还需提供准确的前提条件 ③.精准的描述bug产生的路径后,再描述现象 如: >打开客户端进行首页-> ...
- BZOJ3862 Little Devil I 树链剖分
原文链接http://www.cnblogs.com/zhouzhendong/p/8081514.html 题目传送门 - BZOJ3862 题意概括 一棵树,n个点,边权为黑或者白,支持3重操作: ...
- {}动态规划}记忆化dp
先搞个模板 #include<stdio.h> #include<string.h> using namespace std; typedef long long ll; ]; ...