【Spark笔记】Windows10 本地搭建单机版Spark开发环境
0x00 环境及软件
1、系统环境
OS:Windows10_x64 专业版
2、所需软件或工具
- JDK1.8.0_131
- spark-2.3.0-bin-hadoop2.7.tgz
- hadoop-2.8.3.tar.gz
- scala-2.11.8.zip
- hadoop-common-2.2.0-bin-master.zip(主要使用里面的winutils.exe)
- IntelliJ IDEA(版本:2017.1.2 Build #IU-171.4249.32,built on April 21,2017)
- scala-intellij-bin-2017.1.20.zip(IntelliJ IDEA scala插件)
- apache-maven-3.5.0
0x01 搭建步骤
1、安装JDK
从http://www.oracle.com/technetwork/java/javase/downloads/index.html处下载相应版本的JDK安装文件,安装教程不再赘述,最终安装后的路径如下(由于之前就安装过JDK了,所以此处显示时间为2017年的):
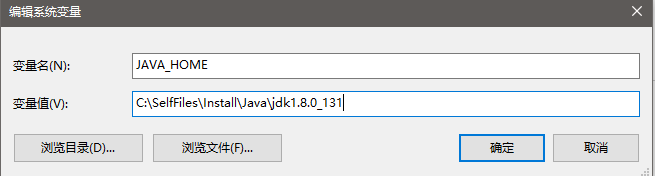
在环境变量中配置JDK信息,新建变量JAVA_HOME=C:\SelfFiles\Install\Java\jdk1.8.0_131,并在Path中添加JDK信息%JAVA_HOME%\bin,如下:
然后,打开一个命令行界面,验证JDK是否正确安装,如下:
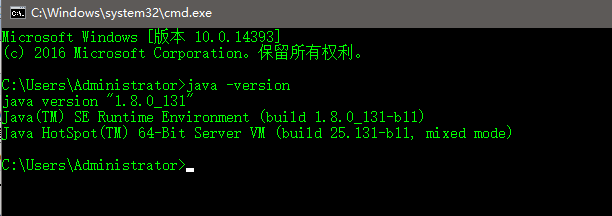
说明JDK已经正常安装。
2、安装Scala
从https://www.scala-lang.org/download/all.html处下载scala-2.11.8,然后解压并存放在本地电脑C:\SelfFiles\Install\scala-2.11.8处,然后配置环境变量并添加到Path变量中(%SCALA_HOME%\bin),类似于JDK的环境变量配置,如下:

然后,打开一个命令行界面验证是否安装成功,如下:
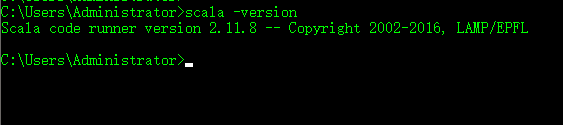
说明安装成功。
3、安装Hadoop
在http://hadoop.apache.org/releases.html下载hadoop-2.8.3,其实下一步“安装Spark”中我们选择下载的Spark版本为spark-2.3.0-bin-hadoop2.7,该版本Spark要求对应的Hadoop要在2.7及以上版本,所以此处我们选择Hadoop-2.8.3,选择其他更高的版本也是可以的。然后解压并存放在C:\SelfFiles\Spark\hadoop-2.8.3,并添加环境变量并添加到Path变量中(%HADOOP_HOME%和%HADOOP_HOME%\bin):
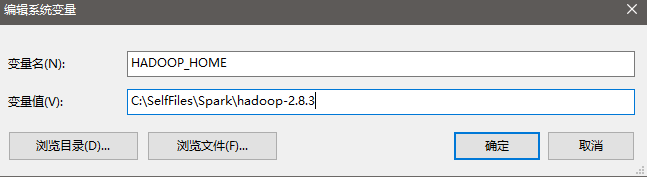
4、安装Spark
在http://spark.apache.org/downloads.html下载对应版本的Spark,此处我们下载的Spark版本信息如下:

下载到本地之后解压,并存放在目录C:\SelfFiles\Spark\spark-2.3.0-bin-hadoop2.7,然后添加环境变量和Path变量中(%SPARK_HOME%和%SPARK_HOME%\bin):
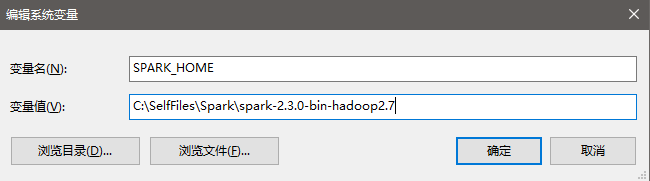
到此,单机版的Spark环境应该安装好了,此时我们在命令行界面中运行spark-shell来验证是否成功:
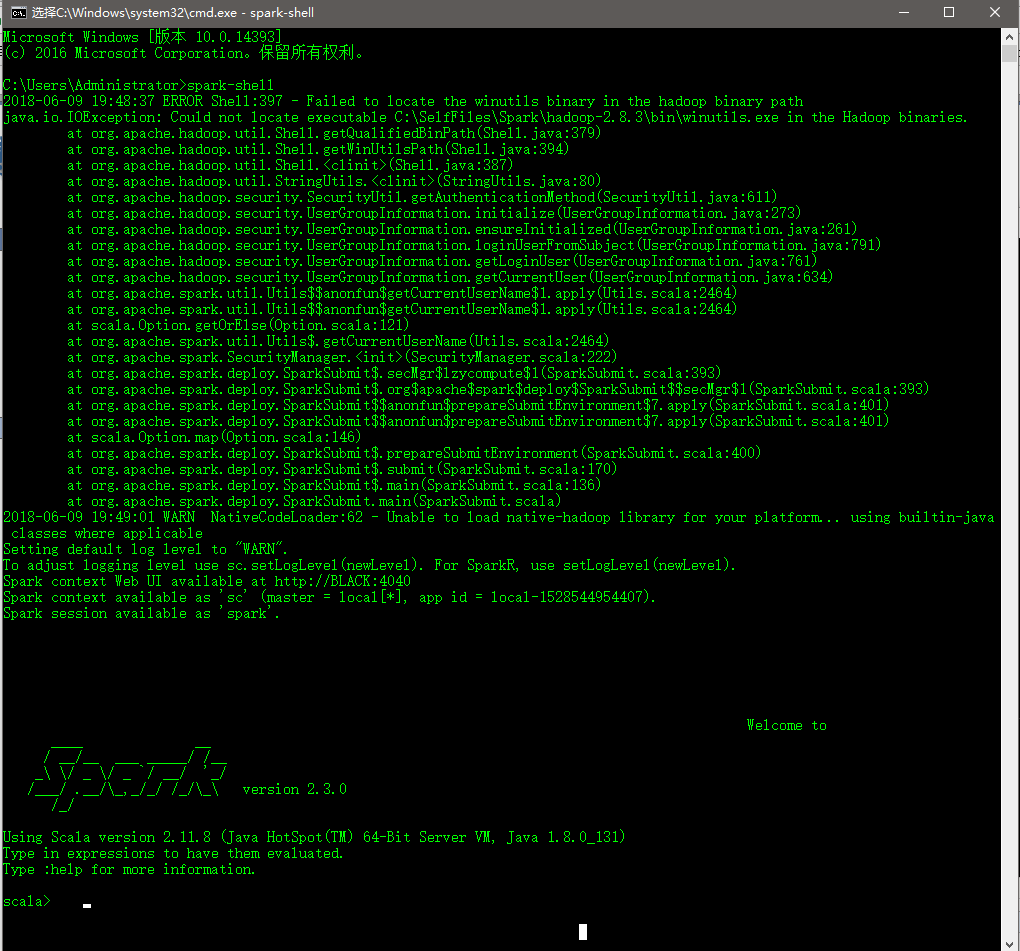
虽然最终进入到了spark shell中,但是中间报了一个错误,提示找不到C:\SelfFiles\Spark\hadoop-2.8.3\bin\winutils.exe文件,通过查看发现确实不存在该文件,此时我们需要从https://github.com/srccodes/hadoop-common-2.2.0-bin/tree/master/bin此处下载winutils.exe文件,并保存到本地C:\SelfFiles\Spark\hadoop-2.8.3\bin\目录下。然后再次运行spark-shell,结果如下:

可以发现,已经不再报找不到winutils.exe文件的错误了,至于提示“WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform...”的错误,尝试了网上大多数的方法,都未解决,此处暂时未解决。
至此,Spark的环境算是基本搭建完成了。下面就开始搭建使用Scala的开发环境。
5、安装IDEA及scala插件
至于IDEA的下载和安装,此处不再赘述,读者可以去https://www.jetbrains.com/自行下载并安装。此处主要记录下scala插件的安装,IDEA的插件安装支持在线安装和离线安装,我们此处采用的是离线安装,即手动下载将要安装的scala插件,然后在IDEA中加载安装。
首先,我们从JetBrains官网上的插件库(http://plugins.jetbrains.com/)搜索scala插件,如下所示:
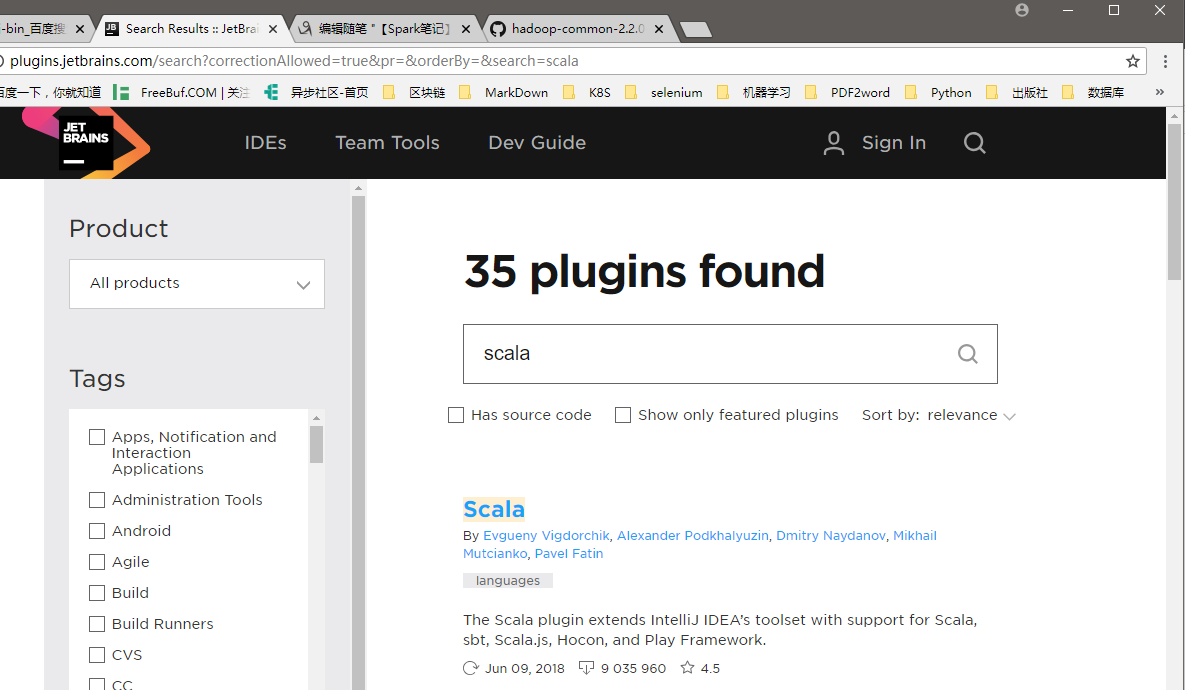
然后,点击第一个Scala进入下载界面,如下:
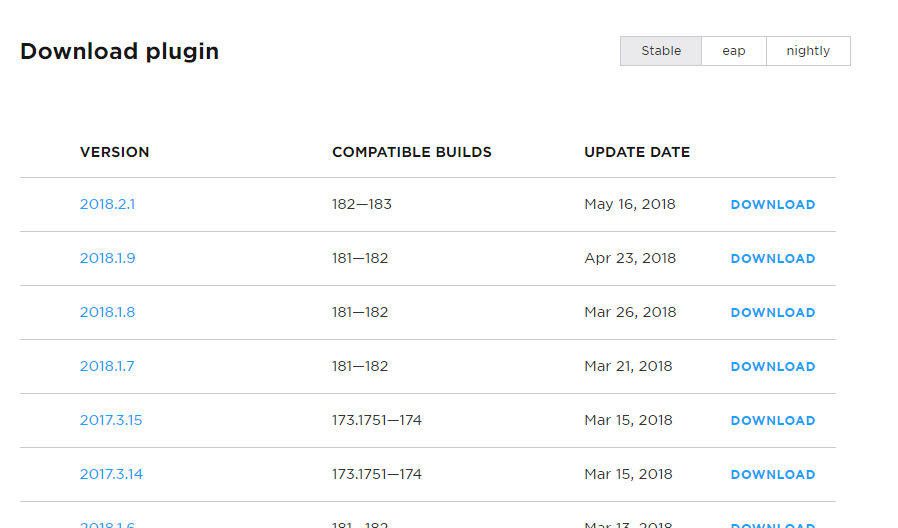
上面列举了兼容不同IDEA构建版本的scala插件,所以此处我们应该选择兼容自己所用IDEA版本的scala插件。从从前面的0x00一节知道,我这里使用的IDEA版本为2017.1.2 Build #IU-171.4249.32,built on April 21,2017,所以此时我们应该选择COMPATIBLE BUILDS一列的值范围包括171.4249.32的版本,可选择的比较多,我们随便选择一个下载即可,然后保存到本地的某个路径下,最好是保存在IDEA安装目录里的plugins目录下,我的保存路径为:C:\SelfFiles\Install\IntelliJIDEA\plugins\Scala\scala-intellij-bin-2017.1.20.zip。
接着,打开IDEA,选择File-->Settings...,可见如下界面:
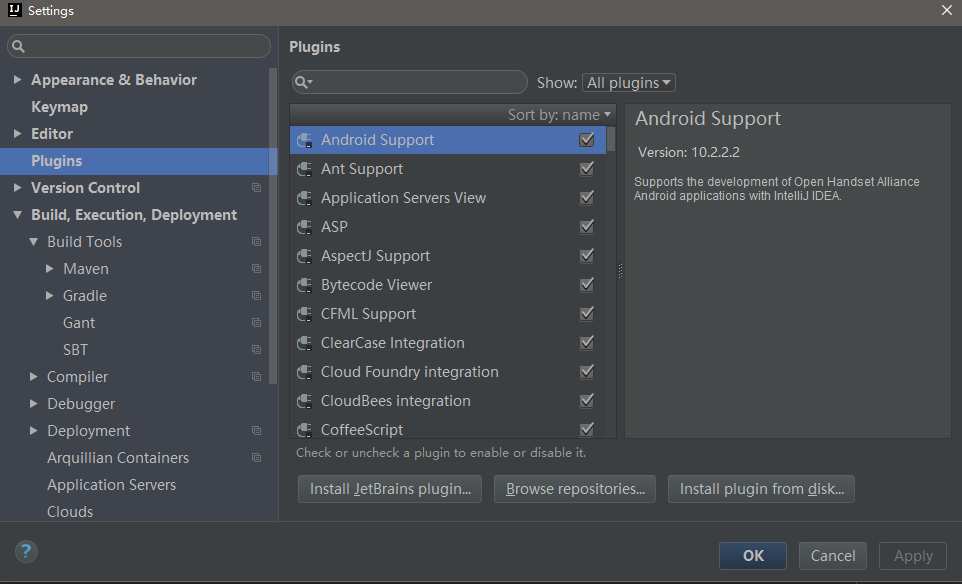
然后单击右下角的“Install plugin from disk...”,选择刚刚我们保存的scala插件文件即可,安装成功后重启IDEA即可使用。
其实,如果网络比较好的话,使用在线安装更方便,此处也提一下在线安装的方法:在上面界面中,点击“Install JetBrains plugin...”或“Browse repositories...”,出现以下界面:
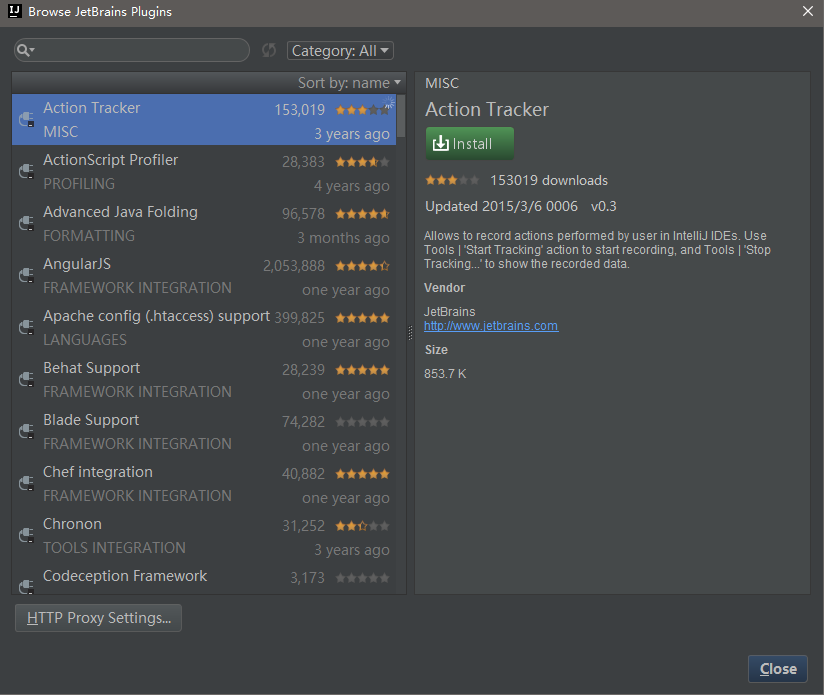
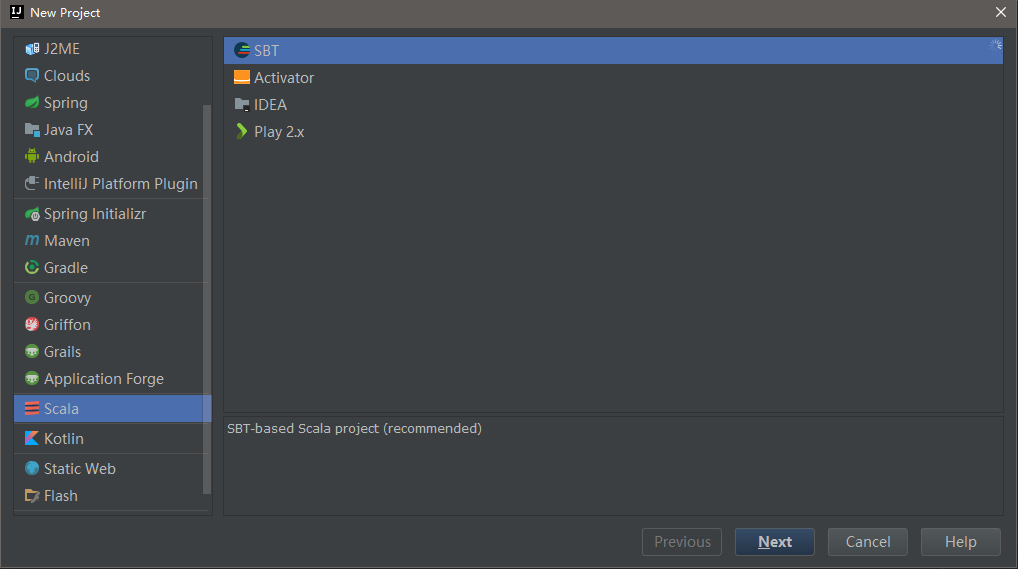
在上述界面搜索框中输入scala即可找到scala插件,然后点击右侧的“Install”安装即可。然后,我们可以通过新建项目来验证scala插件是否安装成功,如下:
6、配置maven
maven的下载和配置网络上面已经有很多教程,此处不再赘述。
7、编写测试代码
下面我们就是用IDEA来编写一个使用Spark进行数据处理的简单示例,该例子来自https://my.oschina.net/orrin/blog/1812035,并根据自己项目的名称做轻微修改,创建maven工程,项目结构如下所示:

pom.xml文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.hackhan.demo</groupId>
<artifactId>jacklee</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<spark.version>2.3.0</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins> <plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build> </project>
WordCount.scala文件内容如下:
package com.hackhan.demo
import org.apache.spark.{SparkConf, SparkContext}
/**
*
* @author migu-orrin on 2018/5/3.
*/
object WordCount {
def main(args: Array[String]) {
/**
* SparkContext 的初始化需要一个SparkConf对象
* SparkConf包含了Spark集群的配置的各种参数
*/
val conf=new SparkConf()
.setMaster("local")//启动本地化计算
.setAppName("WordCount")//设置本程序名称
//Spark程序的编写都是从SparkContext开始的
val sc=new SparkContext(conf)
//以上的语句等价与val sc=new SparkContext("local","testRdd")
val data=sc.textFile("C:/SelfFiles/Spark/test/wordcount.txt")//读取本地文件
var result = data.flatMap(_.split(" "))//下划线是占位符,flatMap是对行操作的方法,对读入的数据进行分割
.map((_,1))//将每一项转换为key-value,数据是key,value是1
.reduceByKey(_+_)//将具有相同key的项相加合并成一个
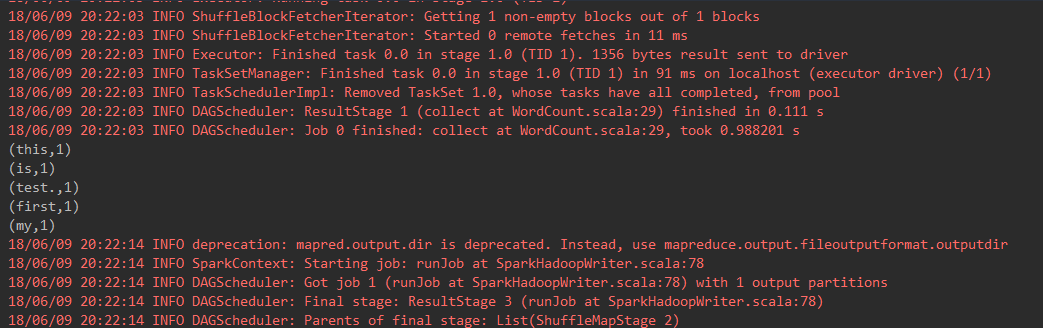
result.collect()//将分布式的RDD返回一个单机的scala array,在这个数组上运用scala的函数操作,并返回结果到驱动程序
.foreach(println)//循环打印
Thread.sleep(10000)
result.saveAsTextFile("C:/SelfFiles/Spark/test/wordcountres")
println("OK,over!")
}
}
其中处理的目标文件C:/SelfFiles/Spark/test/wordcount.txt的内容为(你也可以自己随意填写):
this is my first test.
运行结果如下:
IDEA打印结果:
0x02 总结
因本人也是刚刚接触Spark,对其中的一些原理还不是很了解,此处写此博文只为搭建环境的一个记录,后面随着学习的深入,可以逐渐了解其中的原理。以后也许会考虑搭建集群环境!
在此,感谢网友为知识和技术传播做出的贡献!
0x03 参考内容
- https://my.oschina.net/orrin/blog/1812035
- https://blog.csdn.net/songhaifengshuaige/article/details/79480491
【Spark笔记】Windows10 本地搭建单机版Spark开发环境的更多相关文章
- Windows10上搭建Kinect 2 开发环境
因为Visual Studio 2017的应用最低只能面向windows10,而Kinect SDK 2.0的系统版本要求是windows 8,所以不得不下载Visual Studio 2013 co ...
- 搭建智能合约开发环境Remix IDE及使用
目前开发智能的IDE, 首推还是Remix, 而Remix官网, 总是由于各种各样的(网络)原因无法使用,本文就来介绍一下如何在本地搭建智能合约开发环境remix-ide并介绍Remix的使用. 写在 ...
- 在MAC上搭建python数据分析开发环境
最近工作转型到数据开发领域,想在本地搭建一个数据开发环境.自己有三年python开发经验,马上想到使用numpy.scipy.sklearn.pandas搭建一套数据开发环境. ubuntu的环境,百 ...
- ES6 学习笔记 (2)-- Liunx环境安装Node.js 与 搭建 Node.js 开发环境
笔记参考来源:廖雪峰老师的javascript全栈教程 一.安装Node.js 目前Node.js的最新版本是6.2.x.首先,从Node.js官网下载对应平台的安装程序. 1.下载 选择对应的Liu ...
- Android群英传神兵利器读书笔记——第一章:程序员小窝——搭建高效的开发环境
1.1 搭建高效的开发环境之操作系统 1.2 搭建开发环境之高效配置 基本环境配置 基本开发工具 1.3 搭建程序员的博客平台 开发者为什么要写作 写作平台 第三方博客平台 自建博客平台 开发论坛 1 ...
- 搭建centos7的开发环境3-Spark安装配置
说起大数据开发,必然就会提到Spark,在这片博文中,我们就介绍一下Spark的安装和配置. 这是Centos7开发环境系列的第三篇,本篇的安装会基于之前的配置进行,有需要的请回复搭建centos7的 ...
- React Native开发 - 搭建React Native开发环境
移动开发以前一般都是原生的语言来开发,Android开发是用Java语言,IOS的开发是Object-C或者Swift.那么对于开发一个App,至少需要两套代码.两个团队.对于公司来说,成本还是有的. ...
- 使用IntelliJ IDEA 13搭建Android集成开发环境(图文教程)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/ ...
- 【转】windows和linux中搭建python集成开发环境IDE
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
随机推荐
- C++静态库与动态库(比较透彻)
这次分享的宗旨是——让大家学会创建与使用静态库.动态库,知道静态库与动态库的区别,知道使用的时候如何选择.这里不深入介绍静态库.动态库的底层格式,内存布局等,有兴趣的同学,推荐一本书<程序员的自 ...
- 【转】最近用Timer踩了一个坑,分享一下避免别人继续踩
[转]最近用Timer踩了一个坑,分享一下避免别人继续踩 最近做一个小项目,项目中有一个定时服务,需要向对方定时发送数据,时间间隔是1.5s,然后就想到了用C#的Timer类,我们知道Timer 确实 ...
- maven解决omitted for duplicate(依赖冲突)
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring- ...
- TensorFlow数据读取
TensorFlow高效读取数据的方法 TF Boys (TensorFlow Boys ) 养成记(二): TensorFlow 数据读取 Tensorflow从文件读取数据 极客学院-数据读取 十 ...
- 2019.02.11 bzoj4818: [Sdoi2017]序列计数(矩阵快速幂优化dp)
传送门 题意简述:问有多少长度为n的序列,序列中的数都是不超过m的正整数,而且这n个数的和是p的倍数,且其中至少有一个数是质数,答案对201704082017040820170408取模(n≤1e9, ...
- visual studio 2017使用技巧
visual studio 2017使用技巧 批量删除代码中的空白行 Ctrl + H, 查找: ^(?([^\r\n])\s)*\r?$\r?\n 替换: 使用正则表达式 当前文档 常用快捷键 注释 ...
- Oracle 异常 中文乱码
环境变量 NLS_LANG SIMPLIFIED CHINESE_CHINA.ZHS16GBK
- Delphi fmx控件在手机滑动与单击的问题
Delphi fmx控件在手机滑动与单击的问题 (2016-03-08 10:52:00) 转载▼ 标签: it delphi 分类: Delphi10 众所周知,fmx制作的app,对于象TEdit ...
- 数据结构(一): 键值对 Map
Map基本介绍 Map 也称为:映射表/关联数组,基本思想就是键值对的关联,可以用键来查找值. Java标准的类库包含了Map的几种基本的实现,包括:HashMap,TreeMap,LinkedHas ...
- java中的io系统详解
相关读书笔记.心得文章列表 Java 流在处理上分为字符流和字节流.字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符.字符数组或字符串,而字节流处理单元为 1 个字节,操作字节和字 ...