图像分类(三)GoogLenet Inception_v3:Rethinking the Inception Architecture for Computer Vision
Inception V3网络(注意,不是module了,而是network,包含多种Inception modules)主要是在V2基础上进行的改进,特点如下:
- 将滤波器尺寸(Filter Size)较大的卷积分解成若干滤波器尺寸较小的卷积。根据作者在论文中提出的optimization ideas,大卷积总可以被分解成3*3卷积层序列,而且需要的话还可以进一步分解成更小的卷积,如n*1卷积,事实上,这比2*2卷积层更好。对大卷积层进行分解的好处显而易见,既可以加速计算(多余的计算能力可以用来加深网络的宽度等),又可以使网络的深度进一步增加,从而增加网络的非线性表达能力;
- 更加精细地设计了35*35/17*17/8*8模块(即Fig.5、Fig.6、Fig.7);
- 增加了网络的宽度(特征在H/W/C三个方向上的维度数)。网络输入从224*224变成了299*299
其实,主要的特点都在Fig.5、Fig.6以及Fig.7所示的3种改进的Inception modules上。
以下是论文的详细内容:
为了避免直接增加模型尺寸(虽然能增加模型的性能,但是会是计算量激增),作者在该论文中通过适度的分解卷积和主动正则化(aggressive regularization)来扩展网络。实验证明,这些方法能给模型带来可观的性能提升。
1. 背景
虽然VGGNet结构简单的特点引人注目,但是该网络的计算开销非常高。另一方面,GoogLeNet的Inception architectrue性能水平与VGGNet相近,但是参数量却少很多,甚至可以在内存和计算能力严格受限的情况下也能很好地运行。相比于AlexNet使用了60 million parameters,GoogLeNet仅有5 million parameters,减少12倍,而VGGNet的参数量是AlexNet的3倍
Inception及其继任者的计算代价比VGGNet低很多。这一点使得将Inception network(使用Inception module的网络)应用到需要以合理的代价预处理大量数据和内存与计算能力不足的场景中变得可能,比如在移动视觉设备中。显然,为了达到这一目的,我们需要以特别的方式来使用内存或通过一些计算技巧优化某些操作的执行,但是,这样做会带来额外的复杂性。不过,这些方法也可以被用来优化Inception architecture,再次扩大效率差距
Inception architecture复杂的结构使得很难对网络结构进行改进,如果单纯地放大网络结构,那么大部分计算性能可能失去。而且,GoogLeNet作者并没有对设计网络结构过程中考虑的影响因素进行清晰描述。这就使得GoogLeNet在应用于实例时很难保证它的高效性。因此,作者在该论文中按照一套合理的原则来优化Inception architecture。
在论文中,作者先介绍了一些已经被证实能有效地扩展卷积网络的通用原则(genral principles)和优化思想(optimization ideas),具体会在下面部分介绍。
2. 通用设计原则(General Design Principles)
以下的设计原则是基于各种卷积网络结构进行大规模实验总结得到的。虽然下列原则的使用具有投机性(也就是说使用这些原则时并不确定会发挥该有的作用,而是在进行尝试),并且未来需要额外的实验来评估其准确性和有效领域,但是,在实际中如果严重偏离这些原则的话会导致网络性能恶化,修复检测出的偏差后通常又会提升网络的性能。具体原则如下:
- 避免表征瓶颈(representational bottlenecks),尤其在网络的前面。在网络中应该避免使用极端压缩的瓶颈。通常在获得用于任务的最终表示(representation)之前,表示大小(representation size)应该从输入到输出缓慢减小。理论上,信息内容(information content)不能仅通过表示的维度来评估,因为它丢失了诸如相关结构等重要的因素;维度仅提供了对信息内容的粗略估计。(所谓表征瓶颈就是网络中间某层对特征在空间维度(维度一般指H*W*C的数值,而不是说严格意义上的3个维度)进行较大比例的压缩,比如使用pooling,导致很多特征丢失。虽然Pooling是CNN结构中必须的功能,但我们可以通过一些优化方法来减少Pooling造成的损失,比如下面会提到的先增加通道方向上的维度,后进行pooling)
- 更高维度的表示(representations)(就是尺寸更大的表示,也就是更大尺寸的特征,比如更大的feature maps等)在网络中更容易局部处理(将耦合的特征分开来处理)。增加卷积网络中每个tile(也就是每个patch)的激活值数目可以得到更多解耦的特征(相互独立的特征),这将使网络训练得更快(不是因为计算量减小,而是收敛加快)。(这段话我也不是太懂,看到网上的解释如下:特征的数目(我理解为神经元数目越多,w/h/c三个方向上的)越多收敛得越快。相互独立的特征越多,输入的信息就被分解得越彻底,分解的子特征间相关性低,子特征内部相关性高(很好理解,毕竟是子特征,相当于是cluster),把相关性强的聚集在一起会更容易收敛。原则1和原则2组合在一起理解:特征越多收敛速度越快,但是无法弥补pooling造成的特征损失(units减少),Pooling造成的表示瓶颈需要靠其它方法来解决(后面会提到))
- 空间聚合(我理解为表示的尺寸缩小,如feature maps经过卷积缩小尺寸)可以在较低的维度嵌入(即低维嵌入,指的是使用维度更低的表示替代目前的表示,但是重要的信息基本不会丢失)上完成,而不会在表示能力(representation power)上造成许多或任何损失。 比如,在执行更多展开的卷积(如3*3卷积)之前,我们可以在空间聚合之前降低输入表示的维度,而不用担心各种复杂的影响。如果降维的输出被用在空间聚合的上下文中,那么降维前后没有太大影响的原因可能是相连神经元之间的强相关导致丢失的信息非常少。鉴于空间聚合中的这些信号应该易于压缩,因此维度降低甚至会促使学习变得更快。(对这段话我也不是太理解,参考网上的解释:可以压缩特征维度数,来减少计算量。Inception V1中提出的用1*1卷积先降维再作特征提取就是利用这点。不同维度的信息有相关性,降维可以理解成一种无损或低损的压缩,即使维度降低了,仍然可以利用相关性恢复出原有的信息)
- 平衡网络的宽度(网络的宽度包括每一层的高度、宽度以及深度,即特征的H/W/C三个维度)和深度(指网络的层数)。通过平衡每个阶段的filters数量和网络的深度可以获得理想的网络性能。增加网络的宽度和深度可以有助于更高质量的网络,然而,如果二者同时增加,则网络可以在恒定计算量的情况下得到理想的提升。因此,计算开销(computation budget)应该以一种平衡的方式分配在网络的深度和宽度之间。(网上的解释如下:整个网络结构的深度和宽度(特征(包括featrue maps等)的各个维度数)要做到平衡。只有并行地增加深度和特征的维度才能最大限度的提升网络性能)
3. 优化思想(optimization ideas)
3. 1 分解Filters Size较大的卷积操作(Factorizing Convolutions with Large Filter Size)
GoogLeNet中的降维可以被视作以一种计算高效的方式分解卷积的特例。我们都知道,在视觉网络(vision network)中,临近的activations(或units)的输出应该是高度相关的。所以,我们可知,降维之所以会在GoogLeNet中发挥较大作用,是由于在降维前后表示能力相似,即表示能力基本没减弱。
既然如此,作者就思考还有没有其他分解卷积操作的方法。这自然是有的!如下:
3.1.1 将大卷积分解成更小的卷积(Factorization into smaller convolutions)
作者提出任何大于3*3的卷积都可以分解为3*3的卷积序列。如下Fig.1,使用Mini-network替代5*5卷积

可以发现,5*5或7*7的卷积在计算量上很大,换成3*3卷积序列后计算量成倍的减少,此外,换成3*3卷积后还增加了网络的层数,从而增强了网络的非线性表达能力。
这样替换带来两个问题:一是,该替换是否会导致任何表达能力的丧失?二是,如果我们的主要目标是对计算的线性部分进行分解,那是不是建议在第一层保持线性激活?为此,作者进行了几个控制实验(Fig.2就是其中之一),并发现,在分解的过程中使用线性激活的效果总是次于使用修正线性单元(rectified linear units)。作者认为这是因为分解扩大了网络的变量空间,尤其当我们batch-normalize输出的激活值之后。

3.1.2 空间分解成不对称卷积(Spatial Factorization into Asymmetirc Convolutions)
在将大卷积分解为3*3卷积序列后,还可以将卷积进一步分解为不对称的卷积,形如n*1,事实证明,这种分解比更小的分解(如2*2)效果更好。例如,将3*3卷积分解成两个2*2卷积只节省11%的计算量,而使用不对称分解可以达到33%(见Fig.3,使用3*1和1*3卷积相当于滑动一个两层网络,且二者的感受野相同,都在3*3范围内)。

理论上,我们可以将任何一个n*n卷积替换成一个1*n卷积加一个n*1卷积,并且n越大,节省的计算量就越多(参见Fig.6)



在实践中,作者发现在early layers应用不对称分解效果不好,但是在中等大小的grid-size(grid即表示,如feature maps;在feature maps上,m的范围在12-20之间)上有非常好的效果。实验时,作者在17*17的网格上使用1*7和7*1卷积取得了非常好的效果
3.2 辅助分类器的作用(Utility of Auxiliary Classifiers)
GoogLeNet中已经介绍了辅助分类器的概念,其主要作用是在非常深的网络中解决梯度消失问题。同时,Lee认为辅助分类器还能促进更稳定的学习和更好的收敛。
可是,作者发现,辅助分类器在训练的早期并不会改善收敛速度:在网络取得较高精度之前,带辅助分类器与不带辅助分类器的网络的训练过程基本一致。训练快结束时,带辅助分支(auxiliary branches)的网络在精度上才开始稍微超过不带辅助分类器的网络。
同时,作者还发现,将GoogLeNet中前面那个辅助分类器删除并不会对网络的质量产生影响。结合前一个发现,作者认为GoogLeNet中branches(辅助分类器)能演变低级特征的假设是不适当的。相反,作者认为辅助分类器起着正则化项的作用,因为作者在实践中发现,如果side branch(侧分支,如辅助分类器)经过了batch-normalized或者有dropout层的话,网络的主分类器(main classifier)的性能会有所提升。


3.3 有效的减小Grid Size(Efficient Grid Size Reduction)
通常,卷积网络使用一些Pooling操作减小feature maps的网格尺寸(grid size of the feature maps),而且为了避免表示瓶颈,在应用最大池化或平均池化之前,需要扩展网络滤波器(filters)的激活维度(即增加filters的数量)。比如,我们想将一个通道数为k、尺寸为d*d的 grid 转换成通道数为2k、尺寸为d/2*d/2的 grid ,那么我们第一步需要步长为1、filters数量为2k的卷积,然后再进行池化。可见,这一过程中计算量主要落在卷积上,为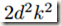 。而如果先Pooling再卷积的话那么计算量会减少1/4,变为
。而如果先Pooling再卷积的话那么计算量会减少1/4,变为 。但是,先池化后卷积会带来表示瓶颈,减弱网络的表示能力,如Fig.9所示。
。但是,先池化后卷积会带来表示瓶颈,减弱网络的表示能力,如Fig.9所示。

如上可知,采用传统的方法无法兼顾计算量和表示能力。在这里,作者提出了另一种变体,可以在降低计算量的同时避免表示瓶颈(参见Fig.10)。作者使用了两个并行的stride为2的模块(blocks):P和C。P只有一层Pooling层,且P和C的步长都是2,P和C的输出会被拼接在一起,具体如Fig.10所示:

3.4 使用Label Smoothing来对网络输出进行正则化(Model Regularization via Label Smoothing)
Softmax层的输出可以用下面的公式表示

损失loss如下

如果分类的标签是one-hot码表示的,那么从输出公式可以反推出训练过程中网络收敛时Softmax的正确分类的输入Zk (logit)是无穷大的(因为输出概率需要是1或接近1的数值),这是一种极其理想的情况。如果让所有的训练输入都产生这种极其理想的输出,就会造成overfitting。为了克服overfitting,作者将 q(k) 换成 q’(k) 来计算loss,如下:

式中, 。可见,上式是原始真实分布 q(k|x) 和固定分布 u(k) 的加权和。可以视为按如下方式获得的标签k 的分布:首先,设真实标签 k=y;然后,以
。可见,上式是原始真实分布 q(k|x) 和固定分布 u(k) 的加权和。可以视为按如下方式获得的标签k 的分布:首先,设真实标签 k=y;然后,以 的概率用从固定分布u(k) 中提取的样本替代k
的概率用从固定分布u(k) 中提取的样本替代k
作者提出使用标签的先验分布作为u(k)(训练集中标签的分布)。实验中,作者使用均匀分布u(k)=1/K,所以

作者将这种对真实分布的改变称为 label-smoothing regularization 或 LSR。由上面的内容可知,LSR的作用是防止最大的 logit 变得比其它 logits 大很多。
作者在ImageNet实验中,根据1000个classes将K取为1000,所以u(k)=1/1000。另外, 取为0.1。使用LSR后给网络带来的性能提升如Table 3所示:
取为0.1。使用LSR后给网络带来的性能提升如Table 3所示:

4. Inception-v2
综合上述4种优化思想,就有了如下的Inception-v2网络,该网络的具体结构参见Table 1:

需要注意的是,作者将传统的7*7卷积分解成了3个3*3卷积;网络中Inception部分,作者使用了3个传统的 inception modules(如Fig.4所示,使用了3.3中描述的grid reduction技术)来处理尺寸为35*35、通道数为288的输入,然后输出17*17*768的 grid;接着是5个如Fig.5所示的分解的 inception modules,输出为8*8*1280的grid,并且使用的是Fig.10中描述的 grid reduction技术;在最粗糙的8*8级别,作者使用了2个Fig.6中展示的 inception modules,输出尺寸为8*8*2048。
作者也注意到,只要网络的设计遵守了前面所述的4个原则,对于各种变化,网络的性能都会相对稳定。此外,虽然该网络的深度达到了42层,但计算量仅比GoogLeNet高约2.5倍,这仍比VGGNet高效得多。
5. 训练方法(Training Methodology)
不对这一部分进行介绍,详细内容见论文,但是记录一些在该部分出现的名词。
RMSProp:RMSProp是Geoff Hinton提出的一种自适应学习率方法,Adagrad会累加之前所有的梯度平方,而RMSProp仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题

gradient clipping 梯度裁剪
6. 更低分辨率输入上的性能(Performance on Lower Resolution Input)
一般我们认为,感受野更大的模型在识别性能上会有显著提升。但是,区分这是增加第一层感受野的效果还是使用更大的模型容量和计算量的效果很重要。如果我们仅仅改变输入分辨率而不进一步调整模型,那么我们将会使用一个简单的模型解决困难得多的任务。为了做出准确的评估,模型需要分析模糊的提示,以便能够“幻化”细节。这样做计算量很大。因此问题依然存在:在计算量保持不变的情况下,更高的输入分辨率会有多少帮助。一种简单确保模型能不断改善的方法是,在更低的输入分辨率下,减少前两层的strides,或者移除网络中的第一层池化层。
为此,作者进行了下面三个实验:
- 299*299的感受野(即输入分辨率),步长为2,并且在第一层之后进行最大池化;
- 151*151的感受野,步长为1,并且在第一层之后进行最大池化;
- 79*79的感受野,步长为1,并且在第一层之后不进行池化
上述三个实验几乎有相同的计算量。在每个实验中,网络都会被训练至收敛,精度会在ImageNet ILSVRC 2012的验证集上测量,结果如 Table 2 所示

可见,虽然输入分辨率较低的网络需要更长的时间来训练,但它们的最终性能都与更高分辨率的网络相当接近。不过,如果简单地根据输入分辨率缩减网络尺寸,那网络的性能相比就会差很多(三个实验基本都没有缩减网络的尺寸,仅仅改变输入部分)。显然,缩减网络尺寸后进行的比较不公平,因为我们在用一个简单16倍的模型解决一个更复杂的任务
综上,模型在使用更大的感受野后带来的性能提升主要来自于增大的模型容量和计算量。因此,在计算量保持基本不变的情况下,即网络的尺寸基本不变,我们可以适当地降低输入分辨率或者删去池化层(参照上述3个实验),这对网络的性能不会造成太大的影响。比如,在实践中,如果待检测图像的分辨率较低,那我们可以对R-CNN输入部分的结构进行适度修改后再使用,理论上性能并不会降低太多。
7. 实验结果和比较(Experimental Results and Comparisons)
Table 3展示了作者提出的网络结构的识别性能,其中每个 Inception-v2 line(即表格中显示有Inception-v2的行)记录的是前一个网络加上下方的修改之后的实验结果,如Inception-v2 Label Smoothing就是Inception-v2 RMSProp加上Label Smoothing之后的网络。
表中,Factorized 7 × 7包括将第一个7*7卷积层分解成3*3卷积层序列;BN-auxiliary指的是网络中辅助分类器的全连接网络也进行了batch-normalized,而不是仅有卷积层采用了该处理;作者将Table 3中最后一行的模型称为“Inception-v3”,并且在multi-crop和ensemble setting中对它进行评估。
下面的Table 4记录的是对多种模型进行single-model,multi-crop evaluation的结果

下面的Table 5记录的是对多种模型进行multi-model,multi-crop evaluation的结果

multi-crop evaluation:即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均。比如,只在图像中心裁剪;在图像四个角裁剪;在四个角以及中心裁剪;更一般的就
是随机裁剪
multi-model evaluation:使用训练出的多个不同模型同时进行评估,然后使用投票或者平均等方法确定最终的评估结果
8. 结论(Conclusions)
略,详细内容参考论文
参考文章:
- 优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
- TensorFlow教程——梯度爆炸与梯度裁剪
- 在VGG网络中dense evaluation 与multi-crop evaluation两种预测方法的区别以及效果
- Inception-V3论文翻译——中英文对照
- Inception-v2/v3结构解析
- GoogLeNet
- Deep Learning-TensorFlow (13) CNN卷积神经网络_ GoogLeNet 之 Inception(V1-V4)
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2,ShuffleNetV2
图像分类(三)GoogLenet Inception_v3:Rethinking the Inception Architecture for Computer Vision的更多相关文章
- inception_v2版本《Rethinking the Inception Architecture for Computer Vision》(转载)
转载链接:https://www.jianshu.com/p/4e5b3e652639 Szegedy在2015年发表了论文Rethinking the Inception Architecture ...
- Rethinking the inception architecture for computer vision的 paper 相关知识
这一篇论文很不错,也很有价值;它重新思考了googLeNet的网络结构--Inception architecture,在此基础上提出了新的改进方法; 文章的一个主导目的就是:充分有效地利用compu ...
- 【Network architecture】Rethinking the Inception Architecture for Computer Vision(inception-v3)论文解析
目录 0. paper link 1. Overview 2. Four General Design Principles 3. Factorizing Convolutions with Larg ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- Rethinking the Inception Architecture for Computer Vision
https://arxiv.org/abs/1512.00567 Convolutional networks are at the core of most state-of-the-art com ...
- DCI:The DCI Architecture: A New Vision of Object-Oriented Programming
SummaryObject-oriented programming was supposed to unify the perspectives of the programmer and the ...
- 图像分类丨Inception家族进化史「GoogleNet、Inception、Xception」
引言 Google提出的Inception系列是分类任务中的代表性工作,不同于VGG简单地堆叠卷积层,Inception重视网络的拓扑结构.本文关注Inception系列方法的演变,并加入了Xcept ...
- GoogLeNet 之 Inception v1 v2 v3 v4
论文地址 Inception V1 :Going Deeper with Convolutions Inception-v2 :Batch Normalization: Accelerating De ...
- 【转】CNN卷积神经网络_ GoogLeNet 之 Inception(V1-V4)
http://blog.csdn.net/diamonjoy_zone/article/details/70576775 参考: 1. Inception[V1]: Going Deeper with ...
随机推荐
- 配置logback
相关组件] Logback是由log4j创始人设计的又一个开源日志组件. logback当前分成三个模块:logback-core.logback- classic和logback-access. l ...
- 深入理解Linux内存分配
深入理解Linux内存分配 为了写一个用户层程序,你也许会声明一个全局变量,这个全局变量可能是一个int类型也可能是一个数组,而声明之后你有可能会先初始化它,也有可能放在之后用到它的时候再初始化.除此 ...
- 17.翻译系列:将Fluent API的配置迁移到单独的类中【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/move-configurations-to-seperate-class-in-cod ...
- lombok自带的slfj使用方法
1.pom.xml <dependency> <groupId>org.projectlombok</groupId> <artifactId>lomb ...
- CentOS 7下PXE+Kickstart无人值守安装操作系统
1.简介 1.1. 什么是PXE PXE(Pre-boot Execution Environment,预启动执行环境)是由Intel公司开发的最新技术,工作于Client/Server的网络模式,支 ...
- 【iCore4 双核心板_ARM】例程二十九:SD_IAP_FPGA实验——更新升级FPGA
实验现象及操作说明: 1.烧写程序成功,绿色ARM·LED灯点亮,三色FPGA·LED灯循环点亮,烧写失败,如果挂载SD卡失败,红灯快闪,如果打开文件失败,蓝灯快闪,读取文件指针移动失败,白灯点亮,升 ...
- node踩坑之This is probably not a problem with npm. There is likely additional logging output above.错误
可能由于种种版本更新的原因需要执行 npm install重新安装一次,如果还是不可以的话,在把之前装的都清空 rm -rf node_modulesrm package-lock.jsonnpm c ...
- JS保留两位小数的几种方法
四舍五入 以下处理结果会四舍五入: var num =2.446242342; num = num.toFixed(2); // 输出结果为 2.45 不四舍五入 以下处理结果不会四舍五入: 第一种, ...
- 第四百一十三节,python面向对象,组合、类创建的本质、依赖注入
组合 组合举例组合就是多个类,或者若干类联合起来完成一个任务下面举例两个类联合起来完成一个任务为了降低代码的耦合度,我们一般不会在一个类里实例化另外一个类,都是将一个类在外面实例化后传参到另外一个来这 ...
- 第四百零二节,Django+Xadmin打造上线标准的在线教育平台—生产环境部署,uwsgi安装和启动,nginx的安装与启动,uwsgi与nginx的配置文件+虚拟主机配置
第四百零二节,Django+Xadmin打造上线标准的在线教育平台—生产环境部署,uwsgi安装和启动,nginx的安装与启动,uwsgi与nginx的配置文件+虚拟主机配置 软件版本 uwsgi- ...