FP-Growth算法
FP-Growth算法的目标是发现模式,其特点就是高效,因为可以通过设置发生频次直接过滤掉一些低频次的元素;而且秉承了和Apriori的思想,对于低频次的元素,其父级和子级的组合都是低频的。
FP-Growth利用的树结构;在发现模式的过程就是一个不断构建树的过程。其核心组成是两部分,一个就是FPTree,另外一个是headTable;我们首先来说一下HeadTable,HeadTable的数据结构是字典,key值是每个单元素(商品),value是一个二元组,分别是这个单品出现的次数以及商品树(FPTree)
下面是TreeNode的结构定义:
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.parent = parentNode # 上级树信息
self.children = {} # 下级(树枝)树信息
self.nodeLink = None
def inc(self, numOccur):
self.count += numOccur def disp(self, ind = 1):
print (' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind + 1)
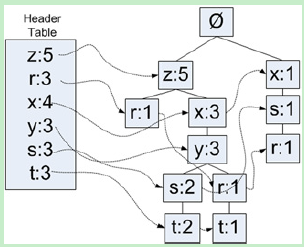
然后我们再来看一下FPTree,这个Header-FPTree里面将会记录信息和Pattern-FP树还要复杂一些,因为除了使用children字段来记录其孩子节点,还是用了nodeLink字段来记录相同单元的其他子树,也就是说这是一个链式结构,通过一个链,可以把所有的某个单元素的FPTree都串联起来了。如下图所示,S:3其实是两个S相关子树,第一个节点是S:2,第二个是S:1,带箭头的都nodeLink进行链接的;不带箭头(线段)的都是children/parent字段进行关联的。
这里有一个概念即使交易,交易的本质是一种商品组成。我们先来一组数据:
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
这里单个字符就是一个单品,比如'r', 'x'等等;交易,就是simpDat中国每个一维数组,['r', 'z', 'h', 'j', 'p']就被称之为一个交易;那么对于FPG而言,他的目标就是根据交易来进行模式识别。
那么怎么来进行呢?首先就是要构建一颗树。怎么构建,要经历两轮遍历,第一轮遍历是把所有单品的出现频次统计出来,完成第一轮的遍历后,把出现频次第的单品过滤掉,形成一个高频单品的集合;第二轮遍历,才是真正要构建FPTree,在遍历每一个交易的时候,首先把低频单品剔除掉(判断是否在高频单品集合中),这样生成了一个新的交易,只包含高频单品,然后对于新的交易中的单品进行排序;为什么要排序?因为在形成树的时候,z,y,r和r,y,z其实是一棵树,只有排序才可以识别为一棵树,排序的规则就是出现的频度。OK,剩下的事情就是对于新的排过序的交易构建FPTree了(交给updateTree)!在updateTree之前的操作,都是数据处理(清洗)的流程范围,只有到了updateTree才是机器学习的开始。
下面的代码就是创建树的python实现:
def createTree(dataset, minSup = 1):
# headTable用于保存各个单元素的指针;通过headTable里面的指定项,可以所用到以某个点为起点的路径(树路径)
headTable = {}
# 第一轮遍历,获取的所有单元素出现的次数
# 注意,dataset是一个字典;for语句遍历默认是第一个元素及下面for语句等价于for trans in data.keys()
print("开始第一轮遍历,找出发生频率")
for trans in dataset:
#print("trans:", trans)
for item in trans:
#print(" item:", item)
#print(" dataSet[trans]:", dataset[trans])
# 其实不是很明白为什么要+dataset[trans]?
# 首先要明白dataset是干什么的,它是一个商品组合以及一个商品组合的数量,这里就是当前该单品的数量+dataset的数量
headTable[item] = headTable.get(item, 0) + dataset[trans]
print("第一轮扫描完毕,headTable: ", headTable)
# 删除出现次数小于下限的元素
for key in list(headTable):
if(headTable[key] < minSup):
del(headTable[key])
freqItems = list(headTable.keys())
print("第一轮低频次项清理完毕,headTable: ", headTable)
print('freqItemSet: ',freqItems)
if(len(freqItems) == 0):
return None, None
# 其实不明白为什么要添加这个None,组成二维数组?第二个元素其实是头结点为该item的树节点(treeNode)
# 初始化设置为None,在第二轮处理中会为每个元素创建一个树节点,填充到headTable中来
for key in headTable:
headTable[key] = [headTable[key], None]
retTree = treeNode("Null Set", 1, None)
print("开始第二轮遍历,构建FP树(只针对高频元素进行构建FP树)")
# 下面开始第二轮遍历,主要是对于高频出现的trans元素进行排序
for trans, count in dataset.items():
print(" trans: %s, count: %d" % (trans, count))
localD = {}
for item in trans:
# 只处理高频元素,低频元素被抛弃;headTable[item][0]是单品,headTable[item][1]则是单品对应的树指针
if(item in freqItems):
localD[item] = headTable[item][0]
if(len(localD) > 0):
print(" localD: ", localD)
# 前方高能,为什么是p:p[1]?这里p[0]是key,单品名称,p[1]是value,单品的发生的次数;
# 这里排序按照单品的发生的次数来进行排序,所以是p[1]
orderedItems = [v[0] for v in sorted(localD.items(), key = lambda p:p[1], reverse = True)]
print(" 排序后的LocalD: ", orderedItems)
# 第一次调用updateTree的时候,传进去的inTree就是根节点:NullSet
updateTree(orderedItems, retTree, headTable, count) return retTree, headTable
那么,如何连构建FP树呢?首先创建一个树的根节点,Null Set,这个在数据处理环节已经创建了;我们拿三组数据来剖析一下:
['z']
['z', 'x', 'y', 'r', 't']
['x', 's', 'r']
Z节点在是第一个单品毫无疑问,直接在NullSet节点下面创建创建树节点z;headTable也没有z树记录(数据处理节点只是在headTable中创建了key以及出现频次,tree信息是None),于是在headTable对应的key值上填充一下创建的树信息;下面就是第一个交易走完之后,FPTree的样子
Null Set 1
z 1
第二个交易还是z开头,z已经在NullSet中存在,OK,那么直接z+1即可(如下图所示);
Null Set 1
z 2
然后是x节点,x是z节点的下级节点,z子树是新创建的,也是没有x节点,所以直接创建,后续的y,r,t都是类似的,所以第二个交易处理完成后,形成了如下的FP树:
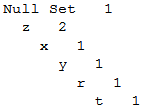
再看第三个交易(['x', 's', 'r']),x节点,FPTree的NullSet节点中没有,创建之;x节点在headTable中已经有了定义,所以需要在headTable中ke=x的树的叶子结点添加一个nodeLink,Link到这个树。注意,回看第二个交易中,z也是二次出现,却并没有更新headTable,这是肿么回事?这是因为该z节点并没有创建新的子树,因为第一轮NullSet根节点已经创建了z树,所以z2没有创建子树,而是重用了z1的树,故不需要更新headTable的数据;然后x的父级节点是z树,z树并没有x节点,所以创建了一个新的x树节点,有新的树节点创建就需要更新headTable中的树信息了。
如果未来有一个交易是z,x....那么同样的不需要更新headTable数据,已经z树节点已经有了x树节点,直接+1即可;明白了这个逻辑,你就会明白FPG是如何来构建"模式"了。
我们继续看第三个交易,第二个节点是s,在x节点下创建s树节点,同时将创建的s树节点同步到headTable中;第三个节点是"r",s树节点下创建r节点,但是r已经在headTable中r的树信息了(第二个交易中),所以需要为headTable中的r树追加一个该新建树的nodeLink。
以此类推。
下面就是实现:
# 更新树信息
# items是一次商品组合,或者说一种模式
def updateTree(items, inTree, headerTable, count):
print("组合模式为:", items, "inTree_name: %s, inTress: %s" %(inTree.name,inTree.disp()))
# 如果单项已经存在于树中,那么直接添加数量即可
if(items[0] in inTree.children):
print(" 元素:%s已经在树中,直接添加数量即可" % (items[0]))
inTree.children[items[0]].inc(count)
# 如果FP树中并没有指定的单元素,那么就创建一个并作为该树的子节点
else:
inTree.children[items[0]] = treeNode(items[0], count, inTree) # 创建树节点
print(" 元素:%s没有在树中...为树创建子节点: %s" % (items[0], inTree.disp()))
# 如果头结点记录表中没有该节点的子树信息(children),那么就将创建的treeNode(子树)赋值过去
if(headerTable[items[0]][1] == None):
print(" headTable中没有节点%s的记录,创建子树" % items[0])
headerTable[items[0]][1] = inTree.children[items[0]]
# 如果之前的遍历过程中已经创建了该节点的children信息,则对children进行遍历到叶子结点,增加了子树(linkNode)几点
else:
print(" headTable中已经有了该节点:%s的记录信息,更新headerTable中树信息" % items[0])
updateHeaderTable(headerTable[items[0]][1], inTree.children[items[0]])
# 逐个元素进行树的“生长”和“创建”
if(len(items) > 1):
print(" 模式(%s)中还剩余单个素树 > 1,去掉items[0](%s)继续更新" % (items, items[0]))
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
# 遍历树一直到叶子结点,然后为叶子节点增加一个“子树”(叶子节点将不再是叶子节点) # 更新headTable中的树信息,即在叶子结点中增加一个nodeLink指向targetNode
def updateHeaderTable(nodeToTest, targetNode):
while(nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink nodeToTest.linkNode = targetNode
FP-Growth算法的更多相关文章
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
- FP Tree算法原理总结(转载)
FP Tree算法原理总结 在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题 ...
- FP - growth 发现频繁项集
FP - growth是一种比Apriori更高效的发现频繁项集的方法.FP是frequent pattern的简称,即常在一块儿出现的元素项的集合的模型.通过将数据集存储在一个特定的FP树上,然后发 ...
- Fp关联规则算法计算置信度及MapReduce实现思路
说明:參考Mahout FP算法相关相关源代码. 算法project能够在FP关联规则计算置信度下载:(仅仅是单机版的实现,并没有MapReduce的代码) 使用FP关联规则算法计算置信度基于以下的思 ...
随机推荐
- AngularJS服务及注入--Provider
Provider简介 在AngularJS中,app中的大多数对象通过injector服务初始化和连接在一起. Injector创建两种类型的对象,service对象和特别对象. Service对象由 ...
- 使用pm2 管理node服务后台运行
npm run dev的服务想放在服务器上,但是putty一断服务就没了. 网上差了下forever和pm2用的比较多,尤其是pm2 简直太好用了.. 具体操作如下 安装 npm install -g ...
- 《HTTP 权威指南》笔记:第十四章 安全 HTTP
 HTTPS 与 HTTP 不同,其在传输层与应用层之间添加了一个 SSL/TLS 的安全层.机制:所有的 HTTP 请求与响应都要通过 SSL/TLS 先进行加密,再进行传输. 基础知识 密码 c ...
- android -------- OkGo (让网络请求更简单的框架)
项目地址:https://github.com/jeasonlzy 该库是封装了okhttp的网络框架,可以与RxJava完美结合,比Retrofit更简单易用.支持大文件上传下载,上传进度回调,下载 ...
- xml字符串,xml对象,数组之间的相互转化
<?phpnamespace Home\Controller;use Think\Controller;class IndexController extends Controller { pu ...
- sparse_tensor feed_dict的时候十分不方便。
假如说,你再处理文本的时候,写tfrecord的时候用的变长的类型, example = tf.train.Example(features=tf.train.Features(feature={ ' ...
- vue教程自学笔记(三)
五.Class与Style绑定 可以用v-bind用于class和style,表达式结果类型除了字符串,还可以是对象或数组. 1.绑定HTML Class 对象语法:给v-bind:class传递一个 ...
- Python *Mix_w4
1.什么是列表(list) 列表是一个可变的数据类型 列表由[ ]来表示,每一项元素使用逗号隔开.列表什么都能装,能装对象的对象. 列表可以装大量的数据,列表能装所有数据类型 2.列表的索引和切片 列 ...
- LeetCode Rotatelmage
---恢复内容开始--- You are given an n x n 2D matrix representing an image. Ratate the image by 90 degrees( ...
- Python3版本中的filter函数,map函数和reduce函数
一.filter函数: filter()为已知的序列的每个元素调用给定的布尔函数,调用中,返回值为非零的元素将被添加至一个列表中 def f1(x): if x>20: return True ...