sqluldr2 学习心得
前言
最近正在做一个项目,需要导出数据库中的表,单数数据库中有很多带有虚拟列的表,而且表中的数据非常的庞大,有些表中的数据上亿条,项目经理让我研究如何快速导出这些数据。
下面是我研究的一些经历:
(1)、我先使用plsql developer导出dmp(实际上是通过emp导出),但是不能导出带有虚拟列的表,导出的速度有点慢;
(2)、使用plsql developer自带的导出功能,如图所示:

该方法可以导出虚拟列,但是导出的速度很慢,比dmp还慢,大约是方法(1)的2倍时间。
(3)、使用数据泵 DataPump导出,该方法可以导出虚拟列,而且速度还可以,但是如果导出远程库数据的时候,需要用dblink,而且需要很高的权限(相当于dba的权限),所以该方法也被排除。
山重水复疑无路,柳暗花明又一村,我发现了sqluldr2这个神器,又能导出虚拟列,而且导入导出的速度非常快,下面我们就进入正题。
sqluldr2下载与安装
1、软件下载地址:最新软件下载地址:http://www.anysql.net/software/sqluldr.zip
下载完后并解压会生成4个文件
sqluldr2.exe 用于32位windows平台;
sqluldr2_linux32_10204.bin 适用于linux32位操作系统;
sqluldr2_linux64_10204.bin 适用于linux64位操作系统;
sqluldr264.exe 用于64位windows平台。
2、直接在cmd上运行(我的sqluldr文件放在H盘里,我电脑是64位,所以使用sqluldr264)
首先,你必须安装oracle,没有安装oracle,sqluldr2不能运行,运行完后出现如下的界面,这样就证明可以成功运行。
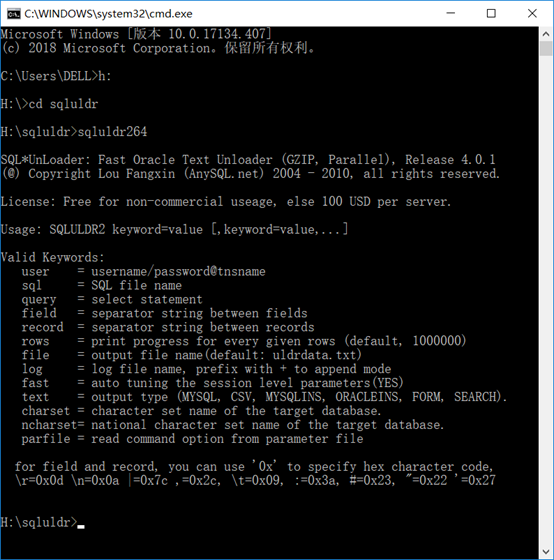
sqluldr2 导出
1、导出命令的主要参数
user=用户名/密码@ip地址:1521/服务 ,如果是本地库,可以只写 用户名和密码:eg:user=用户名/密码
query=”sql查询语句”
head=yes|no 是否导出表头
file=文件存放路径(该文件可以写很多后缀: .txt .csv .dmp 等等,我发现,导出.dmp文件速度快)
table=查询的表名 有这句话,sqluldr2会自动生成一个.ctl文件,导入的时候会用到();
Field:分隔符,指定字段分隔符,默认为逗号; 比如:field=# 在选择分隔符时,一定不能选择会在字段值中出现的字符组合,如常见的单词等,很多次导入时报错,回过头来找原因时,都发现是因为分隔符出现在字段值中了。
record:分隔符,指定记录分隔符,默认为回车换行,Windows下的换行;
quote:引号符,指定非数字字段前后的引号符;
charset:字符集,执行导出时的字符集,一般有UTF8、GBK等;
2、常规的命令
sqluldr264 user=zxx/zxx123@127.0.0.1:1521/orcl query="select * from mv_xlsymx1 where ysyddm='00001H'" head=yes file=h:\mx.csv log=+h:\tem.log
3、可以使用sql参数
可以使用sql参数代替query
sqluldr264 user=zxx/zxx sql=h:\test.sql head=yes file=h:\mx.csv
test.sql是提前维护好的一个文件,文件的内容为sql语句。
4、带有table参数的导出
sqluldr264 user=zxx/zxx query="select * from mv_xlsymx1 where ysyddm='00001H'" table=mv_xlsymx1 head=yes file=h:\mx.csv
它会生成一个.ctl文件(mv_xlsymx1_sqlldr.ctl,默认生成在sqluldr文件下,我的就生成在h:\sqluldr\ mv_xlsymx1_sqlldr.ctl)
5、指定.ctl文件生成的位置
sqluldr264 user=zxx/zxx query="select * from mv_xlsymx1 where ysyddm='00001H'" table=mv_xlsymx1 control=h:\mx.ctl head=yes file=h:\mx.csv
6、带有日志log参数
当集成sqluldr2在脚本中时,就希望屏蔽上不输出这些信息,但又希望这些信息能保留,这时可以用“LOG”选项来指定日志文件名。
sqluldr264 user=zxx/zxx query="select * from mv_xlsymx1 where ysyddm='00001H'" head=yes file=h:\mx.csv log=+h:\tmp.log
注意:这里的log路径要写上“+”
sqlldr 导入
1、我们先查看sqlldr的帮助文档

2、导入之前,我们需要先熟悉一下.ctl文件
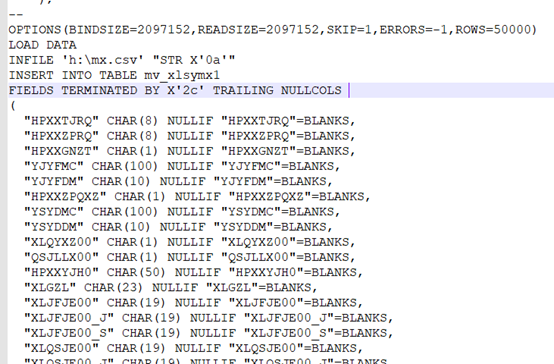
characterset :字符集, 一般使用字符集 AL32UTF8,如果出现中文字符集乱码时,改成 ZHS16GBK。
fields terminated by 'string':文本列分隔符。当为tab键时,改成'\t',或者 X'09';空格分隔符 whitespace,换行分隔符 '\n' 或者 X'0A';回车分隔符 '\r' 或者 X'0D';默认为'\t'。
optionally enclosed by 'char':字段包括符。当为 ' ' 时,不把字段包括在任何引号符号中;当为 "'" 时,字段包括在单引号中;当为'"'时,字段在包括双引号中;默认不使用引用符。
fields escaped by 'char':转义字符,默认为'\'。
trailing nullcols:表字段没有对应的值时,允许为空。
append into table "T_USER_CTRL" -- 操作类型
-- 1) insert into --为缺省方式,在数据装载开始时要求表为空
-- 2) append into --在表中追加新记录
-- 3) replace into --删除旧记录(相当于delete from table 语句),替换成新装载的记录
-- 4) truncate into --删除旧记录(相当于 truncate table 语句),替换成新装载的记录skip=1 :表示插入数据时,跳过第一行(标题),从第二行开始导入;
3、sqluldr 导入处理
3.1、基本的导入语句
sqlldr userid=hxj/hxj control=h:\sqluldr\mv_xlsymx1_sqlldr.ctl data=h:\mx.csv rows=1000
如果是本地库,可以直接只用 用户名/密码;
如果是远程库,需要将userid写全 userid=用户名/密码@ip:1521/服务名
比如:userid=zxx/zxx123@10.3.36.110:1521/orcl,填写自己远程库地址
3.2、带有日志log参数
sqlldr userid=hxj/hxj control=h:\sqluldr\mv_xlsymx1_sqlldr.ctl data=h:\mx.csv log=h:\log\mx.log rows=1000
注意:这里的log的路径不能写“+”;
4、虚拟列处理
sqluldr2导出数据的时候,如果该表中含有虚拟列,你导出的时候没有过滤掉虚拟列,比如:select * from 带有虚拟列的表,那么你要对这些虚拟列进行处理,否则导入的时候回报错。
我发现了三种处理方法:
4.1、在虚拟列后面加上filler,将这一列过滤掉。
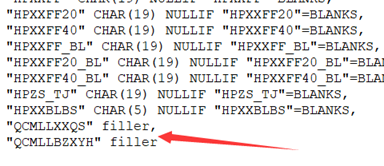
4.2、将.ctl文件中的虚拟列删除掉就可以了

4.3、在导出的时候,不导出虚拟列
比如,不写select * from 表名
直接将不是虚拟列的列名写出来 select id,name from 表名
5、使用并行处理
5.1 未使用并行处理
sqlldr userid=hxj/hxj control=h:\ctl\qsddlqymx1_cyqs.ctl data=h:\qsddlqymx1_cyqs.dmp log=h:\log\qsddlqymx1_cyqs.log
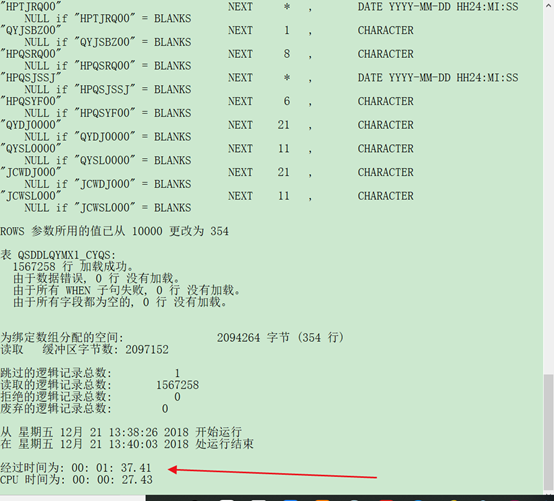
1567258条数据大概需要 一分半
5.2、使用并行处理数据
需要在导入语句中加入 direct=true parallel=true,如下所示:
sqlldr userid=hxj/hxj control=h:\ctl\qsddlqymx1_cyqs.ctl data=h:\qsddlqymx1_cyqs.dmp log=h:\log\qsddlqymx1_cyqs.log direct=true parallel=true
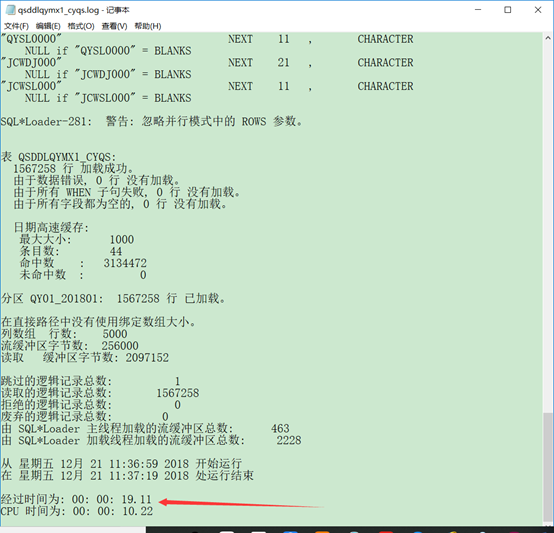
并行能更快的导入数据,1567258条数据大概20秒,但是有缺点(我测试的时候发现的,可能有别的解决方法)
(1):首先.ctl文件必须是append into table 表名;
(2):需要导入的表不能有索引。
这是我写的第一篇博客,望看客老爷们多多指教。
sqluldr2 学习心得的更多相关文章
- 我的MYSQL学习心得(一) 简单语法
我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(二) 数据类型宽度
我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(三) 查看字段长度
我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(四) 数据类型
我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(五) 运算符
我的MYSQL学习心得(五) 运算符 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...
- 我的MYSQL学习心得(六) 函数
我的MYSQL学习心得(六) 函数 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
- 我的MYSQL学习心得(七) 查询
我的MYSQL学习心得(七) 查询 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
- 我的MYSQL学习心得(八) 插入 更新 删除
我的MYSQL学习心得(八) 插入 更新 删除 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得( ...
- 我的MYSQL学习心得(九) 索引
我的MYSQL学习心得(九) 索引 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
随机推荐
- Could not process inbound connection: Client [/rostopic_18439_1555659423249] wants topic , ROS md5sums do not match
报错如下: [WARN] [WallTime: ', 'md5sum': '0d0edf749cdde9f3dc5639668f40e90b', 'topic': '/bp_update_feedba ...
- python 字符串与16进制 转化
def str_to_hex(s): return r"/x"+r'/x'.join([hex(ord(c)).replace('0x', '') for c in s]) def ...
- 用jQuery实现参数自定义的文字跑马灯效果
一,明确需求 基本需求:最近在工作中接到一个新需求,简单来说就是实现一行文字从右到左跑马灯的效果,并且以固定的时间间隔进行循环. 原本这是一个很容易实现的需求,但是难点是要求很多参数得是用户可自行设置 ...
- App自动更新(DownloadManager下载器)
一.开门见山 代码: object AppUpdateManager { const val APP_UPDATE_APK = "update.apk" private var b ...
- memory.h
1.功能:提供内存操作函数 2.函数: extern void *memchr(const void *buffer, int ch, size_t count); extern void *memc ...
- 基于c#的windows基础设计(学习日记2)【关于多态】
这次的多态很简单,没什么知识点 . 直接贴代码了: public abstract class Animal //建立一个抽象类 { private bool m_sex; private strin ...
- webstorm激活教程
虽然webStorm,phpStorm以及jetbrains系列的很好用,但是每隔一段时间就需要激活一下,这样太费劲了,今天军哥给大家推荐一个永久激活的办法 此教程适用于jetbrains 的所有系列 ...
- CopyOnWriteArrayList&Collections.synchronizedList()
1.ArrayList ArrayList是非线性安全,此类的 iterator() 和 listIterator() 方法返回的迭代器是快速失败的:在创建迭代器之后,除非通过迭代器自身的 remov ...
- virtural machine eth1
DEVICE=eth1HWADDR=00:50:56:33:EF:21TYPE=EthernetUUID=f35bd21c-9636-4e3f-a05c-bd4382c352bfONBOOT=yesN ...
- python安装pyMysql
python2和python3是不兼容的,在python2中,链接数据库使用的是mysqldb,但在python3中是是pyMysql. 1.首先dos进入python安装目录,找到并进入Script ...