InnoDB体系架构(二)内存
InnoDB体系架构(二)内存
上篇文章 InnoDB体系架构(一)后台线程 介绍了MySQL InnoDB存储引擎后台线程:Master Thread、IO Thread、Purge Thread、Page Cleaner Thread 四种。
这篇文章将介绍 InnoDB体系架构中的内存,主要有四小结分别为:缓冲池、缓冲池的管理、重做日志缓冲、额外内存缓冲。
以下图为InnoDB存储引擎的内存结构。
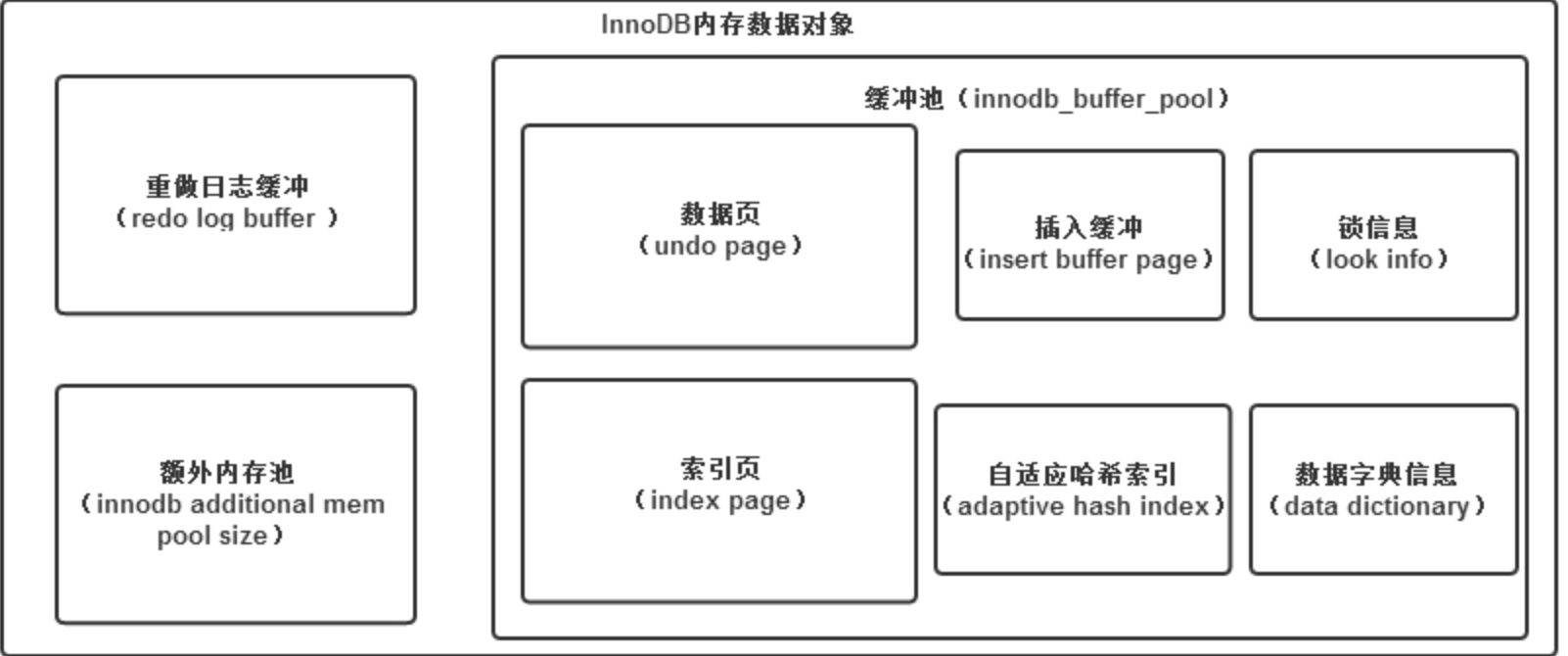
一、缓冲池
InnoDB存储引擎是基于磁盘存储的,按照页的方式进行管理的,理解为基于磁盘的数据库系统。在数据库系统中,由于CPU(快)与磁盘(慢)数据之间的差异,通常使用缓冲池技术来提高数据库的整体性能。
在数据库进行读取时,首先将磁盘读到的页放入缓冲池中,在下次读取相同页时候,如果该页存在于缓冲池,则优先读取。
对于数据库中页的修改操作,首先先操作缓冲池中的页,然后再通过一种名为Checkpoint的机制 按照一定的频率刷新到磁盘中。
查看InnoDB存储引擎缓冲池可以通过:
show variables like 'innodb_buffer_pool_size'\G
自InnoDB1.0+开始,缓冲池有多个,为了减少数据库内部的资源竞争,通过设置 innodb_buffer_pool_instance 来设置缓冲池数量。
二、缓冲池管理(LRU List、Free List 和 Flush List)
1. LRU List
上面说到缓冲池是一个内存区域,里面存放了各种类型的页,那么是如何管理的呢?
InnoDB存储引擎的缓冲池是通过LRU算法来进行管理的,即最频繁使用的页在LRU列表的前端,最少使用的页在LRU列表的尾端。
缓冲池中页的大小默认为16KB,与普通的LRU算法稍有不同的是,InnoDB使用LRU算法进行管理时加入了 midpoint(默认将新读取到的页存放到列表长度为5/8出)可以通过innodb_old_blocks_pct控制。为什么这么做呢? 主要是为了防止某些SQL操作,可能会访问大量的页(超过了原本LRU列表的数量)从而原本热点数据被移除,引起性能问题。
至于mid中的数据多久会加入到LRU的热端呢? 可以通过 set global innodb_old_blocks_time=1000 进行设置。
2. Free List
在数据库刚启动的时候,LRU是空的(没有页),这时候页都存放在一个叫Free List中,当需要从缓冲池中分页时,会从Free列表中查找可用的空闲页,若有,将页从Free List中删除,放入LRU List中,否则根据LRU List 淘汰算法,淘汰LRU List的末尾页。
InnoDB1.0+开始支持压缩页功能,将原本16KB的页压缩为1KB、2KB、4KB、8KB。对于非16KB的页,通过unzip_LRU列表进行管理。 其中LRU列表包含了uzip_LRU列表。
如果需要从缓冲池中申请页大小为4KB的页时,有以下步骤:
1) 检查4KB的unzip_LRU 列表是否有空闲页
2) 有,则使用。
3) 否则,检查8KB的unzip_LRU 列表
4) 有则将页分为 2个 4KB的页,存放到4KB的unzip_LRU列表中。
5) 若不能是,则拆16KB的。
3. Flush List
在LRU列表中页被修改后,该页被称为了脏页,因为缓冲池中的页和磁盘页数据不一致,这时候数据库会通过Checkpoint机制将脏页刷新到磁盘。脏页存在于LRU和Flush列表中,LRU列表用来管理缓冲池中页到可用性,FLush列表用来管理将页刷新回磁盘,两者互不影响。
三、重做日志缓冲
InnoDB存储引擎会首先将重做日志缓冲放到重做日志缓冲区,然后按照一定频率刷新到重做日志文件。一般默认8M(满足绝大部分应用)
以下三种情况都会将重做日志缓冲刷新到日志文件中:
1)Master Thread 每秒刷新一次至日志文件中;
2)每个事务提交会将重做日志缓冲刷新到重做日志文件中。
3)当重做日志缓冲剩余空间小于1/2时。
四、额外的内存池
在innoDB存储引擎中,对内存的管理是通过一种称为内存堆(heap)的方式进行。在对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域的内存不够时,需要从缓冲池中申请。
例如L:分配了缓冲池,但是每个缓冲池中的帧缓冲(frame buffer)还有对应的缓冲控制对象(buffer control block),这些记录了一些诸如LRU、锁、等待等信息,而这个对象的内存就需要从额外内存池中申请。因此在申请了很大的缓冲池是也要考虑相应增加这个值。
InnoDB体系架构(二)内存的更多相关文章
- InnoDB体系架构(三)Checkpoint技术
Checkpoint技术 前篇 InnoDB体系架构(二)内存 从缓冲池.缓冲池的管理.重做日志缓冲.额外内存缓冲这四个点介绍了InnoDB存储引擎的内存结构,而在将缓冲池的数据刷新到磁盘的过程中使用 ...
- InnoDB体系架构(一)后台线程
InnoDB体系架构——后台线程 上一篇已经了解了MySQL数据库的体系结构 这一篇除了介绍InnoDB存储引擎的体系架构外,同时进一步了解InnoDB的后台线程. InnoDB存储引擎是多线程的模型 ...
- InnoDB体系架构(四)Master Thread工作方式
Master Thread工作方式 在前面的文章:InnoDB体系架构——后台线程 说到:InnoDB存储引擎的主要工作都是在一个单独的后台线程Master Thread中完成.这篇具体介绍该线程的具 ...
- InnoDB体系架构
MySQL支持插件式存储引擎,常用的存储引擎则是MyISAM和InnoDB,通常在OLTP(Online Transaction Processing 在线事务处理)中,我们选择使用InnoDB,所以 ...
- 2.3 InnoDB 体系架构
下图简单显示了InnoDB的存储引擎的体系架构,从图可见,InnoDB储存引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作: 维护所有进程/线程需要访问的多个内部数据结构 缓存磁 ...
- PostgreSQL体系架构与内存结构
PostgreSQL体系架构 PostgreSQL的内存结构
- InnoDB体系架构总结(二)
事务 确保事务内的SQL都可以同步执行 要么一起成功 要么一起失败.事务有四个特性原子性 一致性,隔离性,持久性 实现方式 开始事务的时候回家记录记录一个LSN日志序列 当事务执行的时候 会首先在In ...
- InnoDB体系架构总结(一)
缓冲池: 是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响.在数据库中读取的页数据会存放到缓冲池中,下次再读取相同页的时候,会首先判断该页是否在缓冲池中.对于数据库中页的修改操 ...
- GPU体系架构(二):GPU存储体系
GPU是一个外围设备,本来是专门作为图形渲染使用的,但是随着其功能的越来越强大,GPU也逐渐成为继CPU之后的又一计算核心.但不同于CPU的架构设计,GPU的架构从一开始就更倾向于图形渲染和大规模数据 ...
随机推荐
- tensorflow-serving-gpu 本地编译并使用
因为要部署,模型比较大,所以通常官网的pip install 和bazel 教程编译的都是cpu版本的代码, 所以为了感受下gpu就尝试自己编译了,首先,下载源码: git clone --recur ...
- java文件转发
实际开发情景中,有时会遇到文件需要从一台服务器发到另一台服务器的情况,比如外网发到内网,服务器之间文件同步的情况. 就可以用文件转发. 转发端代码: /** * * @param fileName 保 ...
- 亿级 ELK 日志平台构建部署实践
本篇主要讲工作中的真实经历,我们怎么打造亿级日志平台,同时手把手教大家建立起这样一套亿级 ELK 系统.日志平台具体发展历程可以参考上篇 「从 ELK 到 EFK 演进」 废话不多说,老司机们座好了, ...
- object references an unsaved transient instance save the transient instance before flushing
object references an unsaved transient instance save the transient instance before flushing 对象引用未保存的 ...
- 【c++】内存检查工具Valgrind介绍,安装及使用以及内存泄漏的常见原因
转自:https://www.cnblogs.com/LyndonYoung/articles/5320277.html Valgrind是运行在Linux上一套基于仿真技术的程序调试和分析工具,它包 ...
- RHCS(概念篇)
一. 什么是RHCS RHCS是Red Hat Cluster Suite的缩写,也就是红帽子集群套件,RHCS是一个能够提供高可用性.高可靠性.负载均衡.存储共享且经济廉价的集群工具集合,它将集群系 ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
- adc指令
adc是带进位加法指令,它利用了CF位上记录的进位值. 指令格式: adc 操作对象1,操作对象2 功能:操作对象1 = 操作对象1 + 操作对象2 + CF 例如指令 adc ax,bx实现的功能 ...
- easyui Tree树形控件的异步加载
Tree控件 $('#partyOrgTree').tree({ checkbox: false, url: getDataUrl, onClick: function (node) { getDiv ...
- 学习Hibernate的体会
这个学期老师让我们做一个系统(服务器和客户端),语言自选,我也随大家开始学习java web 和android . 下面是我自学的一些体会和遇到的问题. 关于jar包. jsds.jar javasi ...