Apache kylin进阶——元数据篇
一、Apache kylin元数据的存储
Apache kylin的元数据包括 立方体描述(cube description),立方体实例(cube instances)项目(project)、作业(job)、表(table)、字典(dictionary),参见: Apache kylin 核心概念。在kylin集群中至关重要,假如元数据丢失,kylin集群将无法工作。
在kylin 的设计中,元数据存储的类图如下:
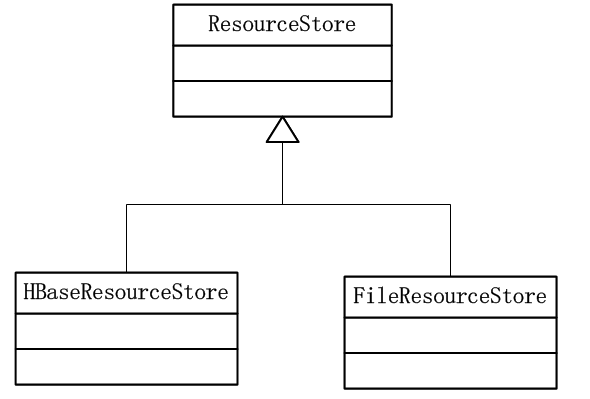
可见kylin提供了两种方式存储元数据,一般而言,集群模式的元数据都选择在hbase中存储。在${KYLIN_HOME}/conf/kylin.properties中,元数据的默认配置如下:
kylin.metadata.url=kylin_metadata@hbase
kylin_metadata@hbase表示,元数据存储在hbase中的kylin_metadata表中。HBaseResourceStore#HBaseResourceStore的参考代码如下:
public HBaseResourceStore(KylinConfig kylinConfig) throws IOException {
super(kylinConfig); String metadataUrl = kylinConfig.getMetadataUrl();
// split TABLE@HBASE_URL
int cut = metadataUrl.indexOf('@');
tableNameBase = cut < 0 ? DEFAULT_TABLE_NAME : metadataUrl.substring(0, cut);
hbaseUrl = cut < 0 ? metadataUrl : metadataUrl.substring(cut + 1); createHTableIfNeeded(getAllInOneTableName());
}
如若存储kylin元数据在本地文件系统中,需将kylin.metadata.url 指向本地文件系统的一个绝对路径, 如:可在${KYLIN_HOME}/conf/kylin.properties中配置如下:
kylin.metadata.url=/home/${username}/${kylin_home}/kylin_metada
注意,一定要是绝对路径,否则会出现错误。
当选择元数据存储在hbase中时,并非所有的数据都在hbase中,当待存储的记录(通常是key-value pairs)的value大于一个最大值kvSizeLimit时,数据将被保存在HDFS中,默认路径为:/kylin/kylin_metadata/,相关配置项在${KYLIN_HOME}/conf/kylin.properties中,如下:
- kylin.hdfs.working.dir=/kylin
- kylin.metadata.url=kylin_metadata@hbase
HBaseResourceStore#buildPut的参考代码如下:
private Put buildPut(String resPath, long ts, byte[] row, byte[] content, HTableInterface table) throws IOException {
int kvSizeLimit = this.kylinConfig.getHBaseKeyValueSize();
if (content.length > kvSizeLimit) {
writeLargeCellToHdfs(resPath, content, table);
content = BytesUtil.EMPTY_BYTE_ARRAY;
} Put put = new Put(row);
put.add(B_FAMILY, B_COLUMN, content);
put.add(B_FAMILY, B_COLUMN_TS, Bytes.toBytes(ts)); return put;
}
kvSizeLimit 的获取代码如下:
public int getHBaseKeyValueSize() {
return Integer.parseInt(this.getOptional("kylin.hbase.client.keyvalue.maxsize", "10485760"));
}
默认值为10M,可在在${KYLIN_HOME}/conf/kylin.properties中配置:
kylin.hbase.client.keyvalue.maxsize=10485760
注意,该值的大小十分重要,因为kylin为了提高整体性能将hbase中的元数据缓存在hbase内存中,如下图:

随着每天 cube的增量build,该表会越来越大。假如不及时清理历史数据,将会使hbase的进程发生 OutOfMemoryError错误!这里kvSizeLimit需在性能和内存大小之间做一个权衡。
二、Apache kylin元数据的运维
当前kylin的元数据只提供了冷备份的方式。
可利用crontab 在${KYLIN_HOME}下,每天定时执行./bin/metastore.sh backup命令,kylin会将元数据信息保存如下目录:
${KYLIN_HOME}/meta_backups/meta_year_month_day_hour_minute_second
当kylin元数据损坏或不一致,可采用如下命令恢复:
- cd ${KYLIN_HOME}
- sh ./bin/metastore.sh reset
- sh ./bin/metastore.sh restore ./meta_backups/meta_xxxx_xx_xx_xx_xx_xx
参考文档:
[1].http://kylin.apache.org/docs15/howto/howto_backup_metadata.html
Apache kylin进阶——元数据篇的更多相关文章
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- Apache Kylin高级部分之使用Hive视图
本章节我们将介绍为什么须要在Kylin创建Cube过程中使用Hive视图.而假设使用Hive视图.能够带来什么优点.解决什么样的问题.以及须要学会怎样使用视图.使用视图有什么限制等等. 1. ...
- Apache kylin 入门
本篇文章就概念.工作机制.数据备份.优势与不足4个方面详细介绍了Apache Kylin. Apache Kylin 简介 1. Apache kylin 是一个开源的海量数据分布式预处理引擎.它通过 ...
- 【转】Apache Kylin 2.0为大数据带来交互式的BI
本文转载自:[技术帖]Apache Kylin 2.0为大数据带来交互式的BI 编者注:Kyligence的联合创始人兼CEO Luke Han在上做题为“”的演讲. 基于Hadoop的SQL一直在被 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- Apache kylin的基础环境
一.Apache kylin的基础环境 由于Apache kylin上的OLAP(wiki:OLAP)是构建在hadoop生态环境上的,所以hadoop环境的稳定性和健壮性对kylin的稳定运行至关重 ...
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- APACHE KYLIN™ 概览
APACHE KYLIN™ 概览 Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发 ...
- APACHE KYLIN™ 概览(分布式分析引擎)
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区.它能 ...
随机推荐
- 微信小程序-添加手机联系人
仅供参考 1,wxml: <view bindlongtap="phoneNumTap">{{phoneNum}}</view> 2,js: data = ...
- ABAP WB01 BDC ”No batch input data for screen & &“ ”没有屏幕 & & 的批输入数据“
公司今年计划大批扩建门店,需要自动化维护相关主数据,其中就有一步通过调用 WB01的BDC录屏来自动创建地点,前台跑没有问题,但后台JOB死活不行,屏幕是以前同事录好的,只能硬着头皮修改. 后台任务日 ...
- C# 枚举类型 enum
我个人感觉平日用到的enum应该是非常简单的,无非就是枚举和整数.字符串之间的转换.最近工作发现一些同事居然不太会用这个东东,于是就整理一下. 枚举类型是定义了一组“符号名称/值”配对.枚举类型是强类 ...
- AsyncHttpSupport并发发送请求
public class AsyncHttpSupportTest { @InjectMocks private AsyncHttpSupport asyncHttpSupport; @Mock pr ...
- gstreamer如何查看相关插件信息(src/sink)?
gstreamer及相关插件编译完成后,会输出gst-inspect可执行文件,相关信息如下: drwxrwxr-x yingc yingc 6月 : glib-/ drwxrwxr-x yingc ...
- 在django中怎么解决没有MySQLdb库的问题
1.安装:pymysql模块 2.在app文件目录下,找到__init__.py文件,在文件中写入下面的代码 #解决django中的MySQLdb模块在python3中没有的问题 import pym ...
- 【html+css3】在一张jpg图片上,显示多张透明的png图片
1.需求:在一个div布局里面放置整张jpg图片,然后在jpg图片上显示三张水平展示的透明png图片,且png外层用a标签包含菜单 2.效果图: 3.上图,底层使用蓝色jpg图片,[首页].[购物车] ...
- corda
账本:corda 从每个节点的视角看待账本都是不一样的.并不是所有节点有所有账本信息的.valut视为SQL数据库,只保存 两两节点之间的数据库 状态:状态是不变的对象,代表共享的事实,比如特定时间的 ...
- CSS3制作图形大全——碉堡了
为方便观看效果图,请移步原文:https://www.jqhtml.com/8045.html Square #square { width: 100px; height: 100 ...
- IsDebuggerPresent原理及其 c++实现
在IsDebuggerPresent下断,步入得到如下代码: 75 A1 | ] | eax:std::cout 75 | ] | eax:std::cout 75 | ] | eax:std::co ...