00、Word Count
1、开发环境
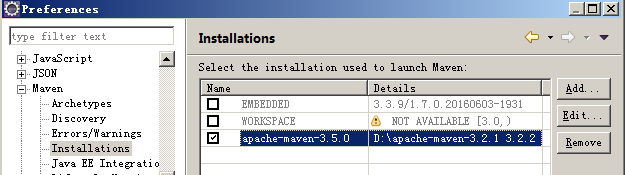
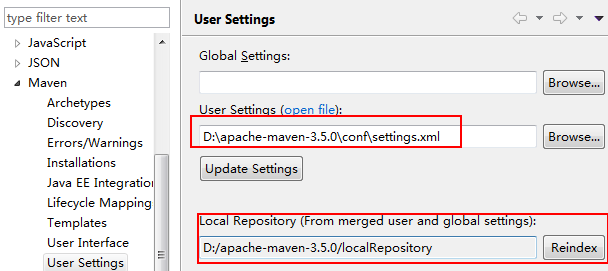
2、本地Local模拟运行

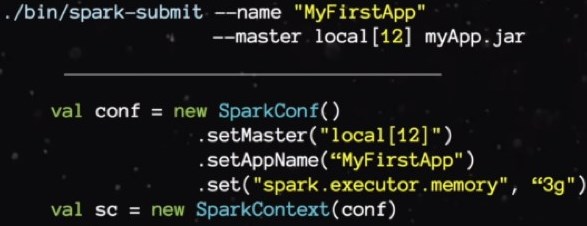
2.1、Java版
</project>
}
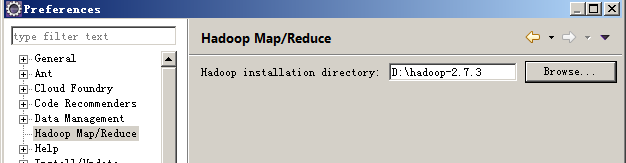
2.2、配置Hadoop客户端


2.3、Scala版:
}
4、在spark-shell中运行
00、Word Count的更多相关文章
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- Word Count
Word Count 一.个人Gitee地址:https://gitee.com/godcoder979/(该项目完整代码在这里) 二.项目简介: 该项目是一个统计文件字符.单词.行数等数目的应用程序 ...
- Mac下hadoop运行word count的坑
Mac下hadoop运行word count的坑 Word count体现了Map Reduce的经典思想,是分布式计算中中的hello world.然而博主很幸运地遇到了Mac下特有的问题Mkdir ...
- 软件工程第三个程序:“WC项目” —— 文件信息统计(Word Count ) 命令行程序
软件工程第三个程序:“WC项目” —— 文件信息统计(Word Count ) 命令行程序 格式:wc.exe [parameter][filename] 在[parameter]中,用户通过输入参数 ...
- word count程序,以及困扰人的宽字符与字符
一个Word Count程序,由c++完成,有行数.词数.能完成路径下文件的遍历. 遍历文件部分的代码如下: void FindeFile(wchar_t *pFilePath) { CFileFin ...
- Spark的word count
word count package com.spark.app import org.apache.spark.{SparkContext, SparkConf} /** * Created by ...
- 无插件,无com组件,利用EXCEL、WORD模板做数据导出(一)
本次随笔主要讲述着工作中是如何解决数据导出的,对于数据导出到excel在日常工作中大家还是比较常用的,那导出到word呢,改如何处理呢,简单的页面导出问题应该不大,但是如果是标准的公文导出呢,要保证其 ...
- C# 读写xml、excel、word、ppt、access
C# 读写xml.excel.word.access 这里只是起个头,不做深入展开,方便以后用到参考 读写xml,主要使用.net 的xml下的document using System;using ...
- Java --本地提交MapReduce作业至集群☞实现 Word Count
还是那句话,看别人写的的总是觉得心累,代码一贴,一打包,扔到Hadoop上跑一遍就完事了????写个测试样例程序(MapReduce中的Hello World)还要这么麻烦!!!?,还本地打Jar包, ...
随机推荐
- python__int 部分内部功能介绍
查看创建的对象的类型: age=18 print(type(age)) 结果: <class 'int'> x.bit_length():返回二进制的位数 Python中进制的转换: Py ...
- linux下在root用户登陆状态下,以指定用户运行脚本程序实现方式
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAMcAAABKCAIAAACASdeXAAAEoUlEQVR4nO2dy7WlIBBFTYIoSIIkmD ...
- JMeter执行压测输出HTML图形化报表(一)
一.应用场景 1.无需交互界面或受环境限制(linux text model) 2.远程或分布式执行 3.持续集成,通过shell脚本或批处理命令均可执行,生成的测试结果可被报表生成模块直接使用,便于 ...
- Kudu-压缩
随着时间的推移,tablet会积累许多DiskRowSets,并且会在行更新时累积很多增量重做(REDO)文件.当插入一个关键字时,为了强制执行主关键字唯一性,Kudu会针对RowSets查询一组布隆 ...
- jenkins(5): jenkins邮件报警配置
参考: https://blog.csdn.net/u013066244/article/details/78665075 1. 使用 增强版的邮件通知 1.1 安装插件 1.2. 系统配置 ...
- python---列表、元祖、字典的区别和常用方法
列表(list) 1.定义: resList=[];----->列表是一种有序的集合 resLIst=[1,2,"嘻嘻",'你好',['内嵌1','内嵌2']]; 2.访问- ...
- UOJ#351. 新年的叶子 概率期望
原文链接https://www.cnblogs.com/zhouzhendong/p/UOJ351.html 题目传送门 - UOJ351 题意 有一个 n 个节点的树,每次涂黑一个叶子节点(度为 1 ...
- BZOJ3772 精神污染 主席树 dfs序
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ3772 题意概括 给出一个树,共n个节点. 有m条互不相同的树上路径. 现在让你随机选择2条路径,问 ...
- 如何在不使用try语句的情况下查看文件是否存在
如果你要确定文件存在的话然后做些什么,那么使用try是最好不过的 如果您不打算立即打开文件,则可以使用os.path.isfile检查文件 如果path是现有常规文件,则返回true.对于相同的路径, ...
- RBM:深度学习之Restricted Boltzmann Machine的BRBM学习+LR分类—Jason niu
from __future__ import print_function print(__doc__) import numpy as np import matplotlib.pyplot as ...