OCR库Tesseract初探
1.Tesseract 安装及使用
一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
源码地址为:https://github.com/tesseract-ocr/tesseract;
tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
接下来,我们将在Windows环境下安装Tesseract并实现简单的转换和训练:
进入下载页面,可以看到有各种.exe文件的下载列表,这里可以选择下载3.0版本。
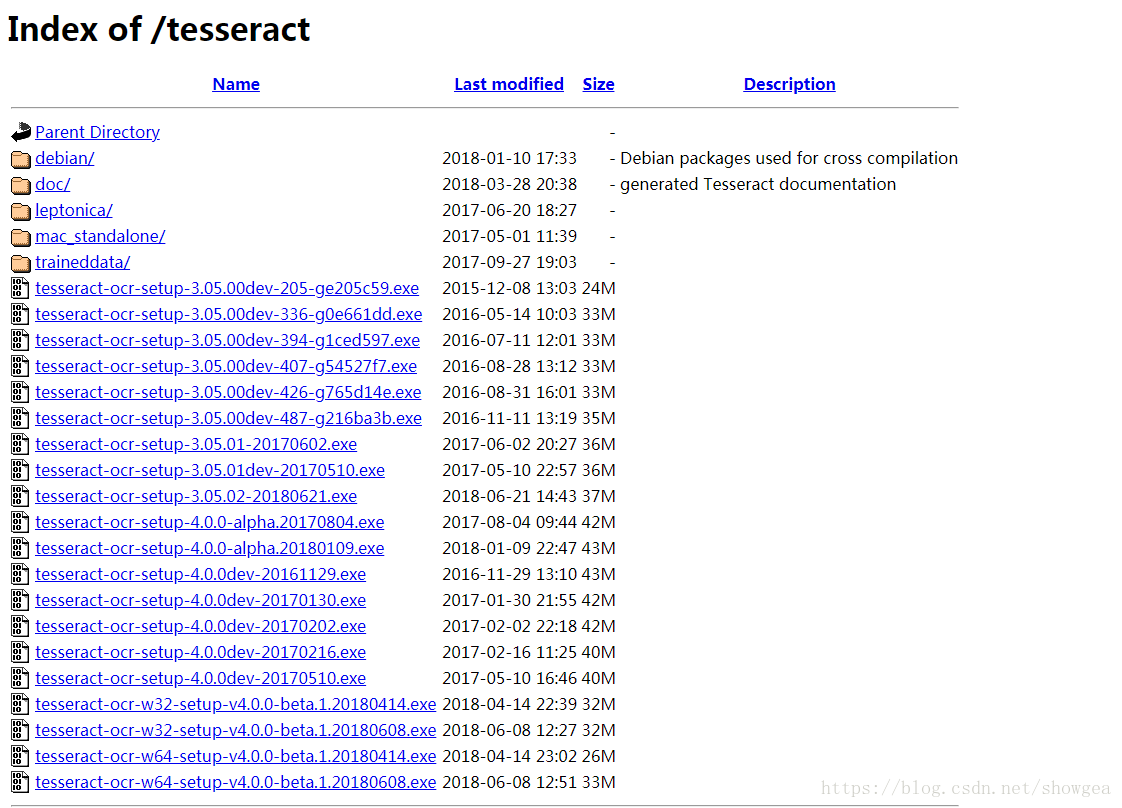
其中文件名中带有dev的为开发版本,不带dev的为稳定版本,可以选择下载不带dev的版本,例如可以选择下载tesseract-ocr-setup-3.05.02.exe。
下载完成后双击,此时会出现如下图所示的页面。
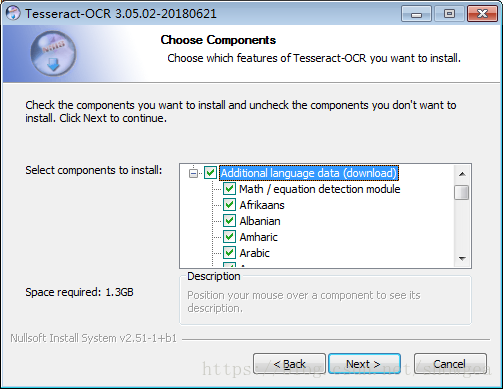
此时可以勾选Additional language data(download)选项来安装OCR识别支持的语言包,这样OCR便可以识别多国语言,默认只有英语。然后一路点击Next按钮即可。
配置环境变量
为了在全局使用方便,比如安装路径为C:\Program Files (x86)\Tesseract-OCR,将该路径添加到环境变量的Path中。
还有一个环境变量要添加:TESSDATA_PREFIX 指向C:\Program Files (x86)\Tesseract-OCR\tessdata 这个是用于语言包的。

测试是否安装成功:在cmd中输入tesseract ,将出现以下界面代表成功:

2.Tesseract的使用
方式一:直接在命令行调用:
tesseract d:\6.png d:\result

第一个参数为图片路径,第二个参数为输出结果路径。6.png的图片如下:

识别结果result.txt的内容为:

有2个数字误识别。
而使用比较标准的文字,如:

是可以完全识别的。大家可以自己试试。
方式二:在Python中调用
要在python中使用,需要安装:
Python :官网安装地址:https://www.python.org/downloads/
PIL :用于python图像格式处理,安装完python之后执行一下命令即可安装:pip install Pillow
Pytesser3: python开源项目,封装了tesseract库,也是在python安装完后使用pip命令安装:pip install pytesser3
然后新建一个记事本文件改名为orc.py,内容如下:
from pytesser3 import image_to_string
from PIL import Image
text = image_to_string(Image.open(r'D:\6.png'))
print(text)
用python执行一下:(我用PyCharm执行的)

3.Tesseract训练:
大体流程为:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的traineddata放入tessdata中
安装jTessBoxEditor
下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/;解压后得到jTessBoxEditor,由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)。
获取样本文件
我们可以用画图工具绘制样本文件,数量越多越好,我自己画了5张图,如图:
【注意】:样本图像文件格式必须为tif\tiff格式,否则在Merge样本文件的过程中会出现 Couldn’t Seek 的错误。
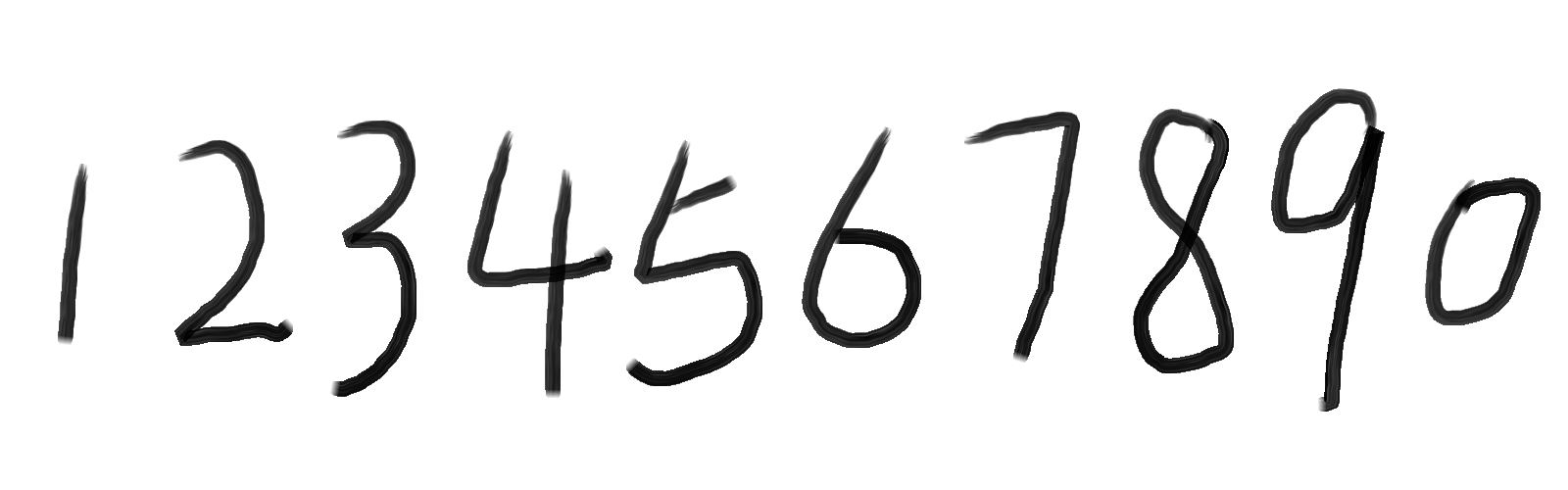


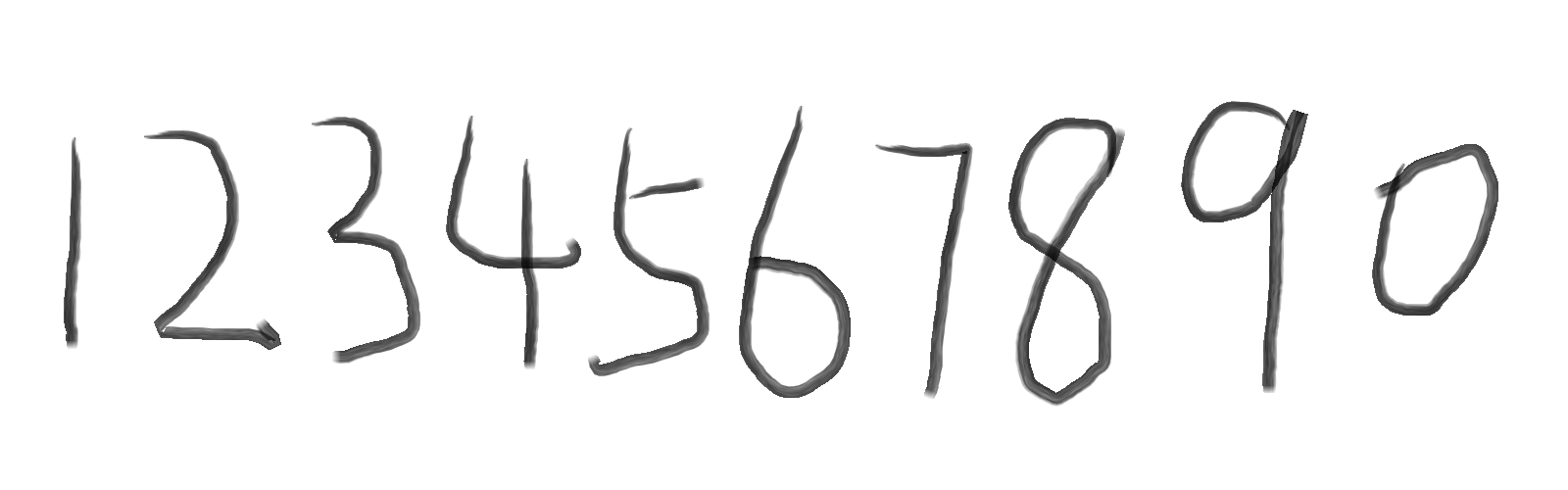

Merge样本文件
打开jTessBoxEditor,Tools->Merge TIFF,将样本文件全部选上,并将合并文件保存为num.font.exp0.tif
生成BOX文件
打开命令行并切换至num.font.exp0.tif所在目录,输入,生成文件名为num.font.exp0.box
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式。
定义字符配置文件
在目标文件夹内生成一个名为font_properties的文本文件,内容为
font 0 0 0 0 0
【语法】:<fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
字符矫正
打开jTessBoxEditor,BOX Editor -> Open,打开num.font.exp0.tif;矫正<Char>上的字符,记得<Page>有好多页噢!

修改后记得保存。
执行批处理文件
在目标目录下生成一个批处理文件

rem 执行改批处理前先要目录下创建font_properties文件
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr echo Clustering..
cntraining.exe num.font.exp0.tr echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
保存后执行即可,执行结果如图:

最终文件夹内会有以下文件,如图:

将生成的traineddata放入tessdata中
最后将num.trainddata复制到Tesseract-OCR中tessdata文件夹即可。
4.最后的测试
按照之前步骤,使用命令行输入
tesseract test.png output_2 -l num
我们可以看到新生成的文件output_2的内容为762408,内容完全正确。细心的人会发现,最后一句指令,我们使用了指令[-l num]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的num语言的匹配库而不是默认的eng语言匹配库。

我们可以看到,经过简单的训练,我们对于数字数据的转换准确率提高了很多。Tesseract的优点除了可以不断学习以外,还因为是使用C++写的开源程序,可以使用C#或者C++调用以及修改,很关键!
Tesseract已经有多个语言的版本:
C#版本:https://github.com/charlesw/tesseract
Java版本:https://github.com/bytedeco/javacpp-presets/tree/master/tesseract
Python版本:https://github.com/sirfz/tesserocr
PHP版本:https://github.com/thiagoalessio/tesseract-ocr-for-php
Tesseract的其他语言版本见:https://github.com/tesseract-ocr/tesseract/wiki/AddOns#tesseract-wrappers
OCR库Tesseract初探的更多相关文章
- Tesseract–OCR 库原理探索
一,简介: Tesseract is probably the most accurate open source OCR engine available. Combined with the Le ...
- 孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境
孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境 (完整学习过程屏幕记录视频地址在文末) 学习Python我肯定不会错过图片文字的识别,当然更重要的是简单的验证码识别了,今天 ...
- Pyocr 0.2 发布,Python 的 OCR 库 - 开源中国社区
Pyocr 0.2 发布,Python 的 OCR 库 - 开源中国社区 Pyocr 0.2 发布,Python 的 OCR 库
- 开源OCR识别库-Tesseract介绍
最近在github上面看到一个开源的ocr文字识别库,感觉效果还可以,所以在这里介绍一下,这个项目的原地址在:https://github.com/tesseract-ocr/tesseract. t ...
- python ocr中文识别库 tesseract安装及问题处理
这个破东西,折腾了快1个小时,网上的教材太乱了. 我解决的主要是windows的问题 先下载exe.(一看到这个,我就有种预感,不妙) https://digi.bib.uni-mannheim.de ...
- [PyImageSearch] Ubuntu16.04下针对OCR安装Tesseract
今天的博文是安装和使用光学字符识别(OCR)的Tesseract库的两部分系列的第一部分. 本系列的第一部分将着重于在您的机器上安装和配置Tesseract,然后使用tesseract命令将OCR应用 ...
- R+OCR︱借助tesseract包实现图片文本提取功能
2016年11月,Jeroen Ooms在CRAN发布了tesseract包,实现了R语言对简单图片的文本提取.分析功能. 利用开源OCR引擎进行图片处理,目前可以识别超过100种语言,R语言可以借助 ...
- 浅谈OCR之Tesseract
光 学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程.OCR技术非常专业,一般多是印刷.打印 ...
- 文字识别的google的库 tesseract
https://github.com/tesseract-ocr/tesseract https://github.com/tesseract-ocr/tessdata 字体识 ...
随机推荐
- JS如何监听动画结束
场景描述 在使用JS控制动画时一般需要在动画结束后执行回调去进行DOM的相关操作,所以需要监听动画结束进行回调.JS提供了以下事件用于监听动画的结束,简单总结学习下. CSS3动画监听事件 trans ...
- Windows系统下MySQL添加到系统服务方法(mysql解压版)
MySQL软件版本:64位 5.7.12 1.首先配置MySQL的环境变量,在系统环境变量Path的开头添加MySQL的bin目录的路径,以“;”结束,我的路径配置如下: 2.修改MySQL根目录下的 ...
- zabbix实操随笔
vmware 9.0安装,vmware tools安装 fedora 15.0安装1G内存以上fedora上基本操作指令1.vmtools 共享文件在linux上安装有问题,出现找不到**.so.1之 ...
- Java程序编译和运行过程之 一个对象的生命之旅(类加载和类加载器)
Java程序从创建到运行要经过两个大步骤 1:源文件(.java)由编译器编译成字节码ByteCode(.class) 2:字节码由Java虚拟机解释并运行 源文件编译成字节码,主要分成两个部分: 1 ...
- python对象、引用
1.python对象 python中 所有的python对象都有3个特征: 身份,类型和值 身份: 每个对象有一个唯一的身份标识自己,这个值可以被认为是该对象内存地址.id()查看. 类型 type( ...
- python3对于时间的处理
1.获取当前时间戳 float_time = time.time() 2.格式化当前时间 #格式化当前时区时间 now_time = time.strftime('%Y-%m-%d %H:%M:%S' ...
- 2018-03-11 20165235 祁瑛 Java第二周考试总结
20165235 祁瑛 Java第二周考试总结 课后习题p16 代码编写 class Person { void speakHello (){ System.out.print("nin h ...
- day27 软件开发规范,以及面相对象回顾
面向对象所有内容回顾: # 面向对象 # 类 :一类具有相同属性和方法的事物 #类的定义:class #类中可以定义的方法种类: #普通方法 self 对象 #类方法 cls @classmethod ...
- React前端框架路由跳转,前端回车事件、禁止空格、提交方式等方法
react router - historyhistory.push() 方法用于在JS中实现页面跳转history.go(-1) 用来实现页面的前进(1)和后退(-1) 访问js连接后+?v1清缓存 ...
- ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
%ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu load spectra_data.mat temp = randperm(size(NIR,1)); P_tra ...