剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充
原文链接:http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-why-its-so-fast_22.html 需翻墙
计算机入门
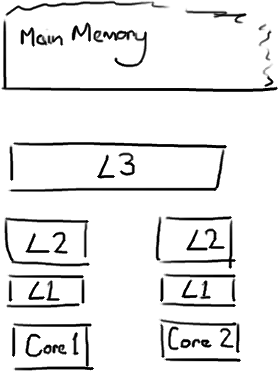
Martin 和 Mike 的 QCon presentation演讲中给出了一些缓存未命中的消耗数据:
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
| 主存 | 约60-80纳秒 | |
| QPI 总线传输 (between sockets, not drawn) |
约20ns | |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
缓存行
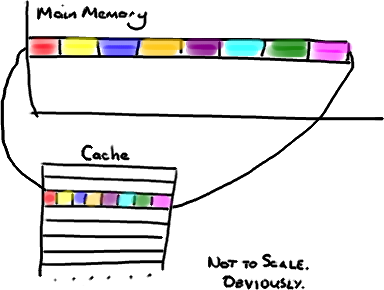
head;同时你的类中有另一个变量紧挨着它,暂时称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。
head中保存的内容也正被消费者(译注:和生产者不在同一个内核中)消费。这两个变量并无直接联系,但需要被这两个线程使用,且这两个线程运行在不同的内核(译注:这里是指物理上的内核,即多核CPU)中。head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。而我们必须以整个缓存行作为单位来处理,不能只把head标记为无效。
head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。解决方案-神奇的缓存行填充
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
(译注:前后各七位填充字段,保证cursor[1]在缓冲行中任意位置,其周围都有足够的填充字段)
Entry类中也值得这样做,如果你有不同的消费者往不同的字段写入,你需要确保各个字段间不会出现伪共享。剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充的更多相关文章
- 从缓存行出发理解volatile变量、伪共享False sharing、disruptor
volatilekeyword 当变量被某个线程A改动值之后.其他线程比方B若读取此变量的话,立马能够看到原来线程A改动后的值 注:普通变量与volatile变量的差别是volatile的特殊规则保证 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - Guava Cache
文章目录 1. Guava Cache 集成 2. 个性化配置 3. 源代码 本文,讲解 Spring Boot 如何集成 Guava Cache,实现缓存. 在阅读「Spring Boot 揭秘与实 ...
- 二、Memcached缓存穿透、缓存雪崩
二.Memcached缓存穿透.缓存雪崩 1. 缓存雪崩 可能是数据魏加载到缓存中,或者缓存同一时间大面积失效,导致大量请求去数据库查询的过程,数据库过载,崩溃. 解决方法: 1 采用加锁计数,使用合 ...
- 使用本地缓存快还是使用redis缓存好?
使用本地缓存快还是使用redis缓存好? Redis早已家喻户晓,其性能自不必多说. 但是总有些时候,我们想把性能再提升一点,想着redis是个远程服务,性能也许不够,于是想用本地缓存试试!想法是不错 ...
- 一.rest-framework之版本控制 二、Django缓存 三、跨域问题 四、drf分页器 五、响应器 六、url控制器
一.rest-framework之版本控制 1.作用 用于版本的控制 2.内置的版本控制 from rest_framework.versioning import QueryParameterVer ...
- {MySQL的库、表的详细操作}一 库操作 二 表操作 三 行操作
MySQL的库.表的详细操作 MySQL数据库 本节目录 一 库操作 二 表操作 三 行操作 一 库操作 1.创建数据库 1.1 语法 CREATE DATABASE 数据库名 charset utf ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - Redis Cache
文章目录 1. Redis Cache 集成 2. 源代码 本文,讲解 Spring Boot 如何集成 Redis Cache,实现缓存. 在阅读「Spring Boot 揭秘与实战(二) 数据缓存 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - EhCache
文章目录 1. EhCache 集成 2. 源代码 本文,讲解 Spring Boot 如何集成 EhCache,实现缓存. 在阅读「Spring Boot 揭秘与实战(二) 数据缓存篇 - 快速入门 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - 快速入门
文章目录 1. 声明式缓存 2. Spring Boot默认集成CacheManager 3. 默认的 ConcurrenMapCacheManager 4. 实战演练5. 扩展阅读 4.1. Mav ...
随机推荐
- 【虚拟化】支持IDE/SATA/SCSI
驱动说明 IDE :IDE和SATA是最常用的两种磁盘格式,基本每个系统上都会有: SATA:同IDE: SCSI :系统上一般缺少此驱动,需要手动安装: Linux下的名称 IDE硬盘:hd[ ...
- Shiro权限控制框架
Subject:主体,可以看到主体可以是任何可以与应用交互的"用户": SecurityManager:相当于SpringMVC中的DispatcherServlet或者Strut ...
- ASP.NET地址栏form提交安全验证
以下类可以在web.config中直接配置,可以防范地址栏.表单提交的恶意数据. 安全模块作用: a.针对URL参数验证的功能,防止sql注入 b.针对form表单XSS漏洞的防护功能 c.针对上传文 ...
- 在 Perl 中使用 Getopt::Long 模块来接收用户命令行参数
我们在linux常常用到一个程序需要加入参数,现在了解一下 perl 中的有关控制参数的模块 Getopt::Long ,比直接使用 @ARGV 的数组强大多了.我想大家知道在 Linux 中有的参数 ...
- DBA_Oracle DBA常用SQL汇总(概念)
2014-06-20 Created By BaoXinjian
- 一起刑事案件法庭辩护 z
[案件地位] 这是一起各方争议很大的刑事案件.侦查机关曾将该案以非法拘禁罪立案侦查,以故意杀人罪移送检察机关审查起诉,公诉机关以非法拘禁形成故意伤害(致死)起诉,而法院最终以故意伤害罪判决,并且排除 ...
- 那些不能错过的Xcode插件
来源:http://www.cocoachina.com/applenews/devnews/2013/0918/7022.html 古人云“工欲善其事必先利其器”,打造一个强大的开发环境,是立即 ...
- iOS应用开发:什么是ARC
ARC是什么 ARC是iOS 5推出的新功能,全称叫 ARC(Automatic Reference Counting).简单地说,就是代码中自动加入了retain/release,原先需要手动添加的 ...
- Citrix 服务器虚拟化之二十一 桌面虚拟化之部署Provisioning Services
Citrix 服务器虚拟化之二十一 桌面虚拟化之部署Provisioning Services Provisioning Services 是Citrix 出品的一系列虚拟化产品中最核心的一个组件, ...
- T450设置插入USB鼠标时自动禁用触摸板
刚入手T450,打字时经常碰到触摸板,很是恼火,于是求助万能的度娘,找了卡饭基佬的教程,实测可行,大家可以试试.<win7下如何设置插入USB鼠标时自动禁用触摸板>,地址:www.kafa ...