lucene 过滤结果
摘要: 关于过滤方面的知识,也就是Filter,如果了解Solr的朋友们,肯定都会知道Solr里面fq这个参数,这个参数的作用其实就是lucene里面的过滤,对一些q参数查询的结果集,做过滤或者限制返回一些我们需要的内容,可以理解成缩小搜索空间的一种策略。
先介绍下查询与过滤的区别和联系,其实查询(各种Query)和过滤(各种Filter)之间非常相似,可以这样说只要用Query能完成的事,用过滤也都可以完成,它们之间可以相互转换,最大的区别就是使用过滤返回的结果集不带评分操作,而使用Query返回的结果都是带相关性评分的,所以当我们如果有一些跟评分操作没有关系的业务,优先使用Filter操作,将会获取更好的性能,其实这也是Solr里面的q参数跟fq参数的区别。
下面,开始进入正题,在这之前,老生常谈的先来了解一下Lucene里面有关于Filter的整体知识
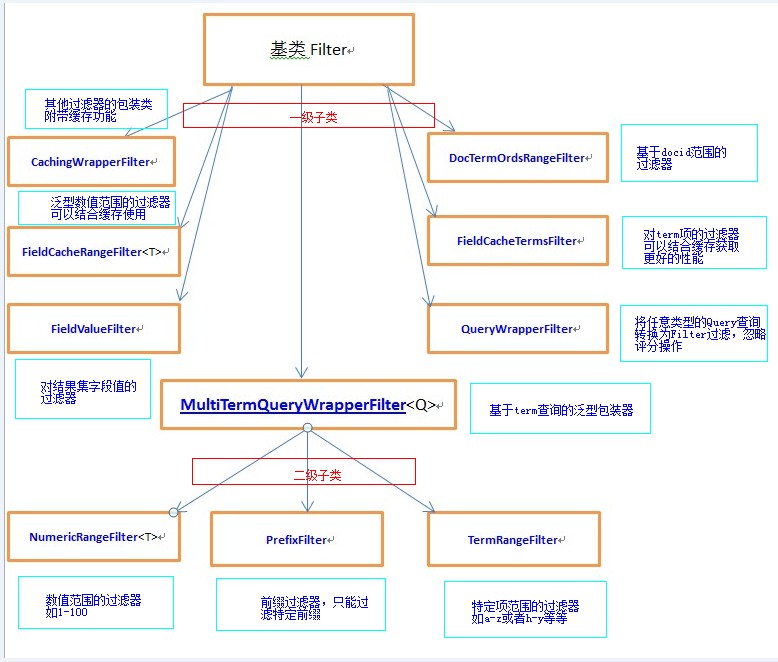
下面,我们来看下具体的在代码里怎么实现,先来看下我们的测试数据
id score bookname ename type price date
1 1 飘渺之旅 pmzl 小说 52.23 201005
2 1 三国演义 sgyy 小说 36.13 201207
3 1 数据库实战 sjksz 技术 77.13 200811
4 1 编程宝典 bcbd 技术 100.3 200501
5 1 职场关系论 zcgxl 职场 36.59 200501
6 1 健康生活 jksh 生活 20.47 200008
7 1 看清本质 kqbz 社会 10.37 201004
8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
//使用过滤器 最后一个为true时包含边界部分,为false时不包含边界部分
//倒数第二个为true时,包含查询边界,为false时不包含
TermRangeFilter filter=new TermRangeFilter("ename", new BytesRef("h"), new BytesRef("n"), true, true);
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
6 1 健康生活 jksh 生活 20.47 200008
7 1 看清本质 kqbz 社会 10.37 201004
核心代码
NumericRangeFilter<Double> filter=NumericRangeFilter.newDoubleRange("price", 10D, 40D, true, false);
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
2 1 三国演义 sgyy 小说 36.13 201207
5 1 职场关系论 zcgxl 职场 36.59 200501
6 1 健康生活 jksh 生活 20.47 200008
7 1 看清本质 kqbz 社会 10.37 201004
8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
//使用缓存过滤
Filter filter=FieldCacheRangeFilter.newDoubleRange("price", 20D, 50D, true, true);
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
2 1 三国演义 sgyy 小说 36.13 201207
5 1 职场关系论 zcgxl 职场 36.59 200501
6 1 健康生活 jksh 生活 20.47 200008
核心代码
// 缓存域过滤特定的类别
Filter filter=new FieldCacheTermsFilter("type", new String[]{"技术","社会"});
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
3 1 数据库实战 sjksz 技术 77.13 200811
4 1 编程宝典 bcbd 技术 100.3 200501
7 1 看清本质 kqbz 社会 10.37 201004
8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
//使用QueryWrapperFilter类包装一个Query
QueryWrapperFilter filter=new QueryWrapperFilter(new TermQuery(new Term("type", "技术")));
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
//使用QueryWrapperFilter类包装一个Query
QueryWrapperFilter filter=new QueryWrapperFilter(new TermQuery(new Term("type", "技术")));
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
最后我来看下,如何继承Filter基类,来定制我们自己的filter,自定义的Filter,虽然某些时候,功能很强大灵活,但是有几个缺点,我们的了解1,保证是内容不重复的字段,例如主键,如果重复,默认返回第一个作为结果集显示2,保证不能被分词的内容,如果是分词的字段,则可能会出现一些不正确的结果。
自定义Filter类
package com.sanjiesanxian.test; import java.io.IOException;
import java.util.BitSet; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.index.AtomicReaderContext;
import org.apache.lucene.index.DocsEnum;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.DocIdSet;
import org.apache.lucene.search.Filter;
import org.apache.lucene.util.AttributeSource;
import org.apache.lucene.util.Bits;
import org.apache.lucene.util.DocIdBitSet;
import org.apache.lucene.util.FixedBitSet;
import org.apache.lucene.util.OpenBitSet; /***
*^_^ ^_^ ^_^
* QQ交流探讨群:324714439
* 自定义过滤器
* @author 三劫散仙
* */
public class MyCustomFilter extends Filter{ public MyCustomFilter() {
// TODO Auto-generated constructor stub
} private String[] terms;//限制返回的数据字典
public MyCustomFilter(String ...terms) {
// TODO Auto-generated constructor stub
this.terms=terms;
}
@Override
public DocIdSet getDocIdSet(AtomicReaderContext arg0, Bits arg1)
throws IOException {
FixedBitSet bits=new FixedBitSet(arg0.reader().maxDoc()) ;//获取没有所有的docid包括未删除的
int base=arg0.docBase;//段的相对基数,保证多个段时相对位置正确
//int limit=base+arg0.reader().maxDoc();//计算最大限制值
for(String s:terms){
DocsEnum doc=arg0.reader().termDocsEnum(new Term("id", s));//必须是唯一的不重复
//保证是单个不重复的term,如果重复的话,默认会取第一个作为返回结果集,分词后的term也不适用自定义term
if(doc.nextDoc()!=-1){
bits.set(doc.docID());//对付符合条件约束的docid循环添加到bits里面
}
}
return bits;
}
}
测试查询代码
MyCustomFilter filter=new MyCustomFilter("3","5","2");//随意指定1之多个需要过滤的项
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);
输出结果
2 1 三国演义 sgyy 小说 36.13 201207
3 1 数据库实战 sjksz 技术 77.13 200811
5 1 职场关系论 zcgxl 职场 36.59 200501
自定义过滤器虽然有缺点,但是某些场景下却能发挥很灵活的作用,特别是对没有分词的字段进行过滤操作。
lucene 过滤结果的更多相关文章
- 1.7.4 Query Syntax and Parsing
1. 查询语法和解析 这部分主要说明了如何指定被使用的查询解析器.同样描述了主查询解析器的支持的语法和功能.同时还描述了在特定环境下使用的其他查询解析器.这里有一些普通查询解析器都能使用的参数,将会在 ...
- 【lucene系列学习四】使用IKAnalyzer分词器实现敏感词和停用词过滤
Lucene自带的中文分词器SmartChineseAnalyzer不太好扩展,于是我用了IKAnalyzer来进行敏感词和停用词的过滤. 首先,下载IKAnalyzer,我下载了 然后,由于IKAn ...
- lucene整理3 -- 排序、过滤、分词器
1. 排序 1.1. Sort类 public Sort() public Sort(String field) public Sort(String field,Boolean reverse ...
- lucene 范围过滤
Lucene里面有关于Filter的整体知识 下面,我们来看下具体的在代码里怎么实现,先来看下我们的测试数据 Java代码 id score bookname ena ...
- lucene查询索引库、分页、过滤、排序、高亮
2.查询索引库 插入测试数据 xx.xx. index. ArticleIndex @Test public void testCreateIndexBatch() throws Exception{ ...
- lucene自定义过滤器
先介绍下查询与过滤的区别和联系,其实查询(各种Query)和过滤(各种Filter)之间非常相似,可以这样说只要用Query能完成的事,用过滤也都可以完成,它们之间可以相互转换,最大的区别就是使用过滤 ...
- MySQL和Lucene索引对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过 ...
- Lucene系列-FieldCache
域缓存,加载所有文档中某个特定域的值到内存,便于随机存取该域值. 用途及使用场景 当用户需要访问各文档中某个域的值时,IndexSearcher.doc(docId)获得Document的所有域值,但 ...
- Apache Lucene(全文检索引擎)—分词器
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
随机推荐
- Vim优化
写python代码时,希望缩进是4个空格,而不是制表符tab, 在vim中,我们只需要简单配置一下就ok了,打开~/.vimrc加上下面的几行(如果已经有了,修改一下数值就行了). set tabst ...
- (八)C语言结构体和指针
指针也可以指向一个结构体变量.定义的一般形式为: struct 结构体名 *变量名; 前面已经定义了一个结构体 stu: struct stu { char *name; int num; char ...
- Android自动接听&挂断电话(包含怎么应对4.1以上版本的权限检
一 前言 这两天要研究类似白名单黑名单以及手势自动接听的一些功能,所以呢,自然而然的涉及到怎么自动接听/挂断电话的功能了.对于自动接听这一块,android4.1版本及其以上的版本和之前的版本处理逻 ...
- 简析 addToBackStack使用和Fragment执行流程
在使用Fragment的时候我们一般会这样写: FragmentTransaction transaction = getSupportFragmentManager().beginTransacti ...
- D3.js 弦图的制作
这是一种用于描述节点之间联系的图表. 1. 弦图是什么 弦图(Chord),主要用于表示两个节点之间的联系. 两点之间的连线,表示谁和谁具有联系: 线的粗细表示权重: 2. 数据 初始数据为: var ...
- python语法笔记(三)
1. 动态类型 python的变量不需要声明,在赋值时,变量可以赋值为任意的值.这和Python的动态类型语言相关. python对象是存在于内存中的实体,代码中写对象名,只是指向该对象的引用.引用和 ...
- Python开发者须知 —— Bottle框架常见的几个坑
Bottle是一个小巧实用的python框架,整个框架只有一个几十K的文件,但却包含了路径映射.模板.简单的数据库访问等web框架组件,而且语法简单,部署方便,很受python开发者的青睐.Pytho ...
- ubuntu12.04 安装配置jdk1.7
第一步:下载jdk-7-linux-i586.tar.gz wget -c http://download.oracle.com/otn-pub/java/jdk/7/jdk-7-linux-i586 ...
- 如何开发 Sublime Text 2 的插件
Sublime Text 2是一个高度可定制的文本编辑器,一直以来对希望有一个快速强大现代的编辑工具的的程序员保持着持续的吸引力.现在,我们将创建自己的一个Sublime plugin,实现用Nett ...
- [backbone] Getting Started with Backbone.js
一.简介 Backbone 是一个 JavaScript MVC 框架,它属于轻量级框架,且易于学习掌握.模型.视图.集合和路由器从不同的层面划分了应用程序,并负责处理几种特定事件.处理 Ajax 应 ...