python study - 正则表达式
第 7 章 正则表达式
正则表达式是搜索、替换和解析复杂字符模式的一种强大而标准的方法。如果你曾经在其他语言 (如 Perl) 中使用过它,由于它们的语法非常相似,你仅仅阅读一下 re 模块的摘要,大致了解其中可用的函数和参数就可以了。
7.1. 概览
字符串也有很多方法,可以进行搜索 (index、find 和 count)、替换 (replace) 和解析 (split),但它们仅限于处理最简单的情况。搜索方法查找单个和固定编码的子串,并且它们总是大小写敏感的。对一个字符串s,如果要进行大小写不敏感的搜索,则你必须调用 s.lower() 或 s.upper() 将 s 转换成全小写或者全大写,然后确保搜索串有着相匹配的大小写。replace 和 split方法有着类似的限制。
如果你要解决的问题利用字符串函数能够完成,你应该使用它们。它们快速、简单且容易阅读,而快速、简单、可读性强的代码可以说出很多好处。但是,如果你发现你使用了许多不同的字符串函数和 if 语句来处理一个特殊情况,或者你组合使用了 split、join 等函数而导致用一种奇怪的甚至读不下去的方式理解列表,此时,你也许需要转到正则表达式了。
尽管正则表达式语法较之普通代码相对麻烦一些,但是却可以得到更可读的结果,与用一长串字符串函数的解决方案相比要好很多。在正则表达式内部有多种方法嵌入注释,从而使之具有自文档化 (self-documenting) 的能力。
7.2. 个案研究:街道地址
这一系列的例子是由我几年前日常工作中的现实问题启发而来的,当时我需要从一个老化系统中导出街道地址,在将它们导入新的系统之前,进行清理和标准化。(看,我不是只将这些东西堆到一起,它有实际的用处。)这个例子展示我如何处理这个问题。
例 7.1. 在字符串的结尾匹配
>>> s = '100 NORTH MAIN ROAD'
>>> s.replace('ROAD', 'RD.') 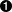 '100 NORTH MAIN RD.'
>>> s = '100 NORTH BROAD ROAD'
>>> s.replace('ROAD', 'RD.')
'100 NORTH MAIN RD.'
>>> s = '100 NORTH BROAD ROAD'
>>> s.replace('ROAD', 'RD.') 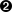 '100 NORTH BRD. RD.'
>>> s[:-4] + s[-4:].replace('ROAD', 'RD.')
'100 NORTH BRD. RD.'
>>> s[:-4] + s[-4:].replace('ROAD', 'RD.')  '100 NORTH BROAD RD.'
>>> import re
'100 NORTH BROAD RD.'
>>> import re  >>> re.sub('ROAD$', 'RD.', s)
>>> re.sub('ROAD$', 'RD.', s) 
 '100 NORTH BROAD RD.'
'100 NORTH BROAD RD.'
|
我的目标是将街道地址标准化,'ROAD' 通常被略写为 'RD.'。乍看起来,我以为这个太简单了,只用字符串的方法 replace 就可以了。毕竟,所有的数据都已经是大写的了,因此大小写不匹配将不是问题。并且,要搜索的串'ROAD'是一个常量,在这个迷惑的简单例子中,s.replace 的确能够胜任。 |
|
不幸的是,生活充满了特例,并且我很快就意识到这个问题。比如:'ROAD' 在地址中出现两次,一次是作为街道名称 'BROAD' 的一部分,一次是作为 'ROAD' 本身。replace 方法遇到这两处的'ROAD'并没有区别,因此都进行了替换,而我发现地址被破坏掉了。 |
|
为了解决在地址中出现多次'ROAD'子串的问题,有可能采用类似这样的方法:只在地址的最后四个字符中搜索替换 'ROAD' (s[-4:]),忽略字符串的其他部分 (s[:-4])。但是,你可能发现这已经变得不方便了。例如,该模式依赖于你要替换的字符串的长度了 (如果你要把 'STREET' 替换为 'ST.',你需要利用 s[:-6] 和 s[-6:].replace(...))。你愿意在六月个期间回来调试它们么?我本人是不愿意的。 |
|
是时候转到正则表达式了。在 Python 中,所有和正则表达式相关的功能都包含在 re 模块中。 |
|
来看第一个参数:'ROAD$'。这个正则表达式非常简单,只有当 'ROAD' 出现在一个字符串的尾部时才会匹配。字符$表示“字符串的末尾”(还有一个对应的字符,尖号^,表示“字符串的开始”)。 |
|
利用 re.sub 函数,对字符串 s 进行搜索,满足正则表达式 'ROAD$' 的用 'RD.' 替换。这样将匹配字符串 s 末尾的 'ROAD',而不会匹配属于单词 'ROAD' 一部分的 'ROAD',这是因为它是出现在 s 的中间。 |
继续我的清理地址的故事。很快我发现,在上面的例子中,仅仅匹配地址末尾的 'ROAD' 不是很好,因为不是所有的地址都包括表示街道的单词 ('ROAD');有一些直接以街道名结尾。大部分情况下,不会遇到这种情况,但是,如果街道名称为 'BROAD',那么正则表达式将会匹配 'BROAD' 的一部分为 'ROAD',而这并不是我想要的。
例 7.2. 匹配整个单词
>>> s = '100 BROAD'
>>> re.sub('ROAD$', 'RD.', s)
'100 BRD.'
>>> re.sub('\\bROAD$', 'RD.', s)
'100 BROAD'
>>> re.sub(r'\bROAD$', 'RD.', s)
'100 BROAD'
>>> s = '100 BROAD ROAD APT. 3'
>>> re.sub(r'\bROAD$', 'RD.', s)
'100 BROAD ROAD APT. 3'
>>> re.sub(r'\bROAD\b', 'RD.', s)
'100 BROAD RD. APT 3'
|
我真正想要做的是,当 'ROAD' 出现在字符串的末尾,并且是作为一个独立的单词时,而不是一些长单词的一部分,才对他进行匹配。为了在正则表达式中表达这个意思,你利用 \b,它的含义是“单词的边界必须在这里”。在 Python 中,由于字符 '\' 在一个字符串中必须转义,这会变得非常麻烦。有时候,这类问题被称为“反斜线灾难”,这也是 Perl 中正则表达式比 Python 的正则表达式要相对容易的原因之一。另一方面,Perl 也混淆了正则表达式和其他语法,因此,如果你发现一个 bug,很难弄清楚究竟是一个语法错误,还是一个正则表达式错误。 |
|
为了避免反斜线灾难,你可以利用所谓的“原始字符串”,只要为字符串添加一个前缀 r 就可以了。这将告诉 Python,字符串中的所有字符都不转义;'\t' 是一个制表符,而 r'\t' 是一个真正的反斜线字符 '\',紧跟着一个字母 't'。我推荐只要处理正则表达式,就使用原始字符串;否则,事情会很快变得混乱 (并且正则表达式自己也会很快被自己搞乱了)。 |
|
(一声叹息) 很不幸,我很快发现更多的与我的逻辑相矛盾的例子。在这个例子中,街道地址包含有作为整个单词的'ROAD',但是它不是在末尾,因为地址在街道命名后会有一个房间号。由于 'ROAD' 不是在每一个字符串的末尾,没有匹配上,因此调用 re.sub 没有替换任何东西,你获得的只是初始字符串,这也不是我们想要的。 |
|
为了解决这个问题,我去掉了 $ 字符,加上另一个 \b。现在,正则表达式“匹配字符串中作为整个单词出现的'ROAD'”了,不论是在末尾、开始还是中间。 |
7.3. 个案研究:罗马字母
你可能经常看到罗马数字,即使你没有意识到它们。你可能曾经在老电影或者电视中看到它们 (“版权所有 MCMXLVI” 而不是 “版权所有1946”),或者在某图书馆或某大学的贡献墙上看到它们 (“成立于 MDCCCLXXXVIII”而不是“成立于1888”)。你也可能在某些文献的大纲或者目录上看到它们。这是一个表示数字的系统,它实际上能够追溯到远古的罗马帝国 (因此而得名)。
在罗马数字中,利用7个不同字母进行重复或者组合来表达各式各样的数字。
- I = 1
- V = 5
- X = 10
- L = 50
- C = 100
- D = 500
- M = 1000
下面是关于构造罗马数字的一些通用的规则的介绍:
- 字符是叠加的。I 表示 1,II 表示 2,而 III 表示 3。VI 表示 6 (字面上为逐字符相加,“5 加 1”),VII 表示 7,VIII 表示 8。
- 含十字符 (I、X、C 和 M) 至多可以重复三次。对于 4,你则需要利用下一个最大的含五字符进行减操作得到:你不能把 4 表示成 IIII,而应表示为 IV (“比 5 小 1”)。数字 40 写成 XL (比 50 小 10),41 写成 XLI,42 写成 XLII,43 写成 XLIII,而 44 写成 XLIV (比 50 小 10,然后比 5 小1)。
- 类似地,对于数字 9,你必须利用下一个含十字符进行减操作得到:8 表示为 VIII,而 9 则表示为 IX (比 10 小 1),而不是 VIIII (因为字符 I 不能连续重复四次)。数字 90 表示为 XC,900 表示为 CM。
- 含五字符不能重复。数字 10 常表示为X,而从来不用VV来表示。数字 100 常表示为C,也从来不表示为 LL。
- 罗马数字一般从高位到低位书写,从左到右阅读,因此不同顺序的字符意义大不相同。DC 表示 600;而 CD 是一个完全不同的数字 (为 400,也就是比 500 小100)。CI 表示 101;而IC 甚至不是一个合法的罗马字母 (因为你不能直接从数字100减去1;这需要写成 XCIX,意思是比 100 小 10,然后加上数字 9,也就是比 10 小 1的数字)。
7.3.1. 校验千位数
怎样校验任意一个字符串是否为一个有效的罗马数字呢?我们每次只看一位数字,由于罗马数字一般是从高位到低位书写。我们从高位开始:千位。对于大于或等于 1000 的数字,千位由一系列的字符 M 表示。
例 7.3. 校验千位数
>>> import re >>> pattern = '^M?M?M?$'
|
这个模式有三部分:
|
|
re 模块的关键是一个 search 函数,该函数有两个参数,一个是正则表达式 (pattern),一个是字符串 ('M'),函数试图匹配正则表达式。如果发现一个匹配,search 函数返回一个拥有多种方法可以描述这个匹配的对象,如果没有发现匹配,search 函数返回一个 None,一个 Python 空值 (null value)。你此刻关注的唯一事情,就是模式是否匹配上,于是我们利用 search 函数的返回值了解这个事实。字符串'M' 匹配上这个正则表达式,因为第一个可选的 M 匹配上,而第二个和第三个 M 被忽略掉了。 |
|
'MM' 能匹配上是因为第一和第二个可选的 M 匹配上,而忽略掉第三个 M。 |
|
'MMM' 能匹配上因为三个 M 都匹配上了。 |
|
'MMMM' 没有匹配上。因为所有的三个 M 都匹配完了,但是正则表达式还有字符串尾部的限制 (由于字符 $),而字符串又没有结束 (因为还有第四个 M 字符),因此 search 函数返回一个 None。 |
|
有趣的是,一个空字符串也能够匹配这个正则表达式,因为所有的字符 M 都是可选的。 |
7.3.2. 校验百位数
与千位数相比,百位数识别起来要困难得多,这是因为有多种相互独立的表达方式都可以表达百位数,而具体用那种方式表达和具体的数值有关。
- 100 = C
- 200 = CC
- 300 = CCC
- 400 = CD
- 500 = D
- 600 = DC
- 700 = DCC
- 800 = DCCC
- 900 = CM
因此有四种可能的模式:
- CM
- CD
- 零到三次出现 C 字符 (出现零次表示百位数为 0)
- D,后面跟零个到三个 C 字符
后面两个模式可以结合到一起:
- 一个可选的字符 D,加上零到 3 个 C 字符。
这个例子显示如何有效地识别罗马数字的百位数。
例 7.4. 检验百位数
>>> import re >>> pattern = '^M?M?M?(CM|CD|D?C?C?C?)$'
|
这个模式的首部和上一个模式相同,检查字符串的开始 (^),接着匹配千位数 (M?M?M?),然后才是这个模式的新内容。在括号内,定义了包含有三个互相独立的模式集合,由垂直线隔开:CM、CD 和 D?C?C?C? (D是可选字符,接着是 0 到 3 个可选的 C 字符)。正则表达式解析器依次检查这些模式 (从左到右),如果匹配上第一个模式,则忽略剩下的模式。 |
|
'MCM' 匹配上,因为第一个 M 字符匹配,第二和第三个 M 字符被忽略掉,而 CM 匹配上 (因此 CD 和 D?C?C?C? 两个模式不再考虑)。MCM 表示罗马数字1900。 |
|
'MD' 匹配上,因为第一个字符 M 匹配上,第二第三个 M 字符忽略,而模式 D?C?C?C? 匹配上 D (模式中的三个可选的字符 C 都被忽略掉了)。MD 表示罗马数字 1500。 |
|
'MMMCCC' 匹配上,因为三个 M 字符都匹配上,而模式 D?C?C?C? 匹配上 CCC (字符D是可选的,此处忽略)。MMMCCC 表示罗马数字 3300。 |
|
'MCMC' 没有匹配上。第一个 M 字符匹配上,第二第三个 M 字符忽略,接着是 CM 匹配上,但是接着是 $ 字符没有匹配,因为字符串还没有结束 (你仍然还有一个没有匹配的C字符)。C 字符也不 匹配模式 D?C?C?C? 的一部分,因为与之相互独立的模式 CM 已经匹配上。 |
|
有趣的是,一个空字符串也可以匹配这个模式,因为所有的 M 字符都是可选的,它们都被忽略,并且一个空字符串可以匹配 D?C?C?C? 模式,此处所有的字符也都是可选的,并且都被忽略。 |
哎呀!看看正则表达式能够多快变得难以理解?你仅仅表示了罗马数字的千位和百位上的数字。如果你根据类似的方法,十位数和各位数就非常简单了,因为是完全相同的模式。让我们来看表达这个模式的另一种方式吧。
7.4. 使用 {n,m} 语法
在前面的章节,你处理了相同字符可以重复三次的情况。在正则表达式中,有另外一个方式来表达这种情况,并且能提高代码的可读性。首先看看我们在前面的例子中使用的方法。
例 7.5. 老方法:每一个字符都是可选的
>>> import re >>> pattern = '^M?M?M?$' >>> re.search(pattern, 'M')
|
这个模式匹配串的开始,接着是第一个可选的字符 M,第二第三个 M 字符则被忽略 (这是可行的,因为它们都是可选的),最后是字符串的结尾。 |
|
这个模式匹配串的开始,接着是第一和第二个可选字符 M,而第三个 M 字符被忽略 (这是可行的,因为它们都是可选的),最后匹配字符串的结尾。 |
|
这个模式匹配字符串的开始,接着匹配所有的三个可选字符 M,最后匹配字符串的结尾。 |
|
这个模式匹配字符串的开始,接着匹配所有的三个可选字符 M,但是不能够匹配字符串的结尾 (因为还有一个未匹配的字符 M),因此不能够匹配而返回一个 None。 |
例 7.6. 一个新的方法:从 n 到 m
>>> pattern = '^M{0,3}$'
>>> re.search(pattern, 'M')
<_sre.SRE_Match object at 0x008EEB48>
>>> re.search(pattern, 'MM')
<_sre.SRE_Match object at 0x008EE090>
>>> re.search(pattern, 'MMM')
<_sre.SRE_Match object at 0x008EEDA8>
>>> re.search(pattern, 'MMMM')
>>>
|
这个模式意思是说:“匹配字符串的开始,接着匹配 0 到 3 个 M 字符,然后匹配字符串的结尾。”这里的 0 和 3 可以改成其它任何数字;如果你想要匹配至少 1 次,至多 3 次字符 M,则可以写成 M{1,3}。 |
|
这个模式匹配字符串的开始,接着匹配三个可选 M 字符中的一个,最后是字符串的结尾。 |
|
这个模式匹配字符串的开始,接着匹配三个可选 M 字符中的两个,最后是字符串的结尾。 |
|
这个模式匹配字符串的开始,接着匹配三个可选 M 字符中的三个,最后是字符串的结尾。 |
|
这个模式匹配字符串的开始,接着匹配三个可选 M 字符中的三个,但是没有匹配上 字符串的结尾。正则表达式在字符串结尾之前最多只允许匹配三次 M 字符,但是实际上有四个 M 字符,因此模式没有匹配上这个字符串,返回一个 None。 |
 |
|
| 没有一个轻松的方法来确定两个正则表达式是否等价。你能采用的最好的办法就是列出很多的测试样例,确定这两个正则表达式对所有的相关输入都有相同的输出。在本书后面的章节,将更多地讨论如何编写测试样例。 | |
7.4.1. 校验十位数和个位数
现在我们来扩展一下关于罗马数字的正则表达式,以匹配十位数和个位数,下面的例子展示十位数的校验方法。
例 7.7. 校验十位数
>>> pattern = '^M?M?M?(CM|CD|D?C?C?C?)(XC|XL|L?X?X?X?)$' >>> re.search(pattern, 'MCMXL')
|
这个模式匹配字符串的开始,接着是第一个可选字符 M,接着是 CM,接着 XL,接着是字符串的结尾。请记住,(A|B|C) 这个语法的含义是“精确匹配 A、B 或者 C 其中的一个”。此处匹配了 XL,因此不再匹配 XC 和 L?X?X?X?,接着就匹配到字符串的结尾。MCML 表示罗马数字 1940。 |
|
这个模式匹配字符串的开始,接着是第一个可选字符 M,接着是 CM,接着 L?X?X?X?。在模式 L?X?X?X? 中,它匹配 L 字符并且跳过所有可选的 X 字符,接着匹配字符串的结尾。MCML 表示罗马数字 1950。 |
|
这个模式匹配字符串的开始,接着是第一个可选字符 M,接着是 CM,接着是可选的 L 字符和可选的第一个 X 字符,并且跳过第二第三个可选的 X 字符,接着是字符串的结尾。MCMLX 表示罗马数字 1960。 |
|
这个模式匹配字符串的开始,接着是第一个可选字符 M,接着是 CM,接着是可选的 L 字符和所有的三个可选的 X 字符,接着匹配字符串的结尾。MCMLXXX 表示罗马数字 1980。 |
|
这个模式匹配字符串的开始,接着是第一个可选字符M,接着是CM,接着是可选的 L字符和所有的三个可选的X字符,接着就未能匹配 字符串的结尾ie,因为还有一个未匹配的X 字符。所以整个模式匹配失败并返回一个 None. MCMLXXXX 不是一个有效的罗马数字。 |
对于个位数的正则表达式有类似的表达方式,我将省略细节,直接展示结果。
>>> pattern = '^M?M?M?(CM|CD|D?C?C?C?)(XC|XL|L?X?X?X?)(IX|IV|V?I?I?I?)$'
用另一种 {n,m} 语法表达这个正则表达式会如何呢?这个例子展示新的语法。
例 7.8. 用 {n,m} 语法确认罗马数字
>>> pattern = '^M{0,3}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$'
>>> re.search(pattern, 'MDLV')
<_sre.SRE_Match object at 0x008EEB48>
>>> re.search(pattern, 'MMDCLXVI')
<_sre.SRE_Match object at 0x008EEB48>
>>> re.search(pattern, 'MMMDCCCLXXXVIII')
<_sre.SRE_Match object at 0x008EEB48>
>>> re.search(pattern, 'I')
<_sre.SRE_Match object at 0x008EEB48>
|
这个模式匹配字符串的开始,接着匹配三个可选的 M 字符的一个,接着匹配 D?C{0,3},此处,仅仅匹配可选的字符 D 和 0 个可选字符 C。继续向前匹配,匹配 L?X{0,3},此处,匹配可选的 L 字符和 0 个可选字符 X,接着匹配 V?I{0,3},此处,匹配可选的 V 和 0 个可选字符 I,最后匹配字符串的结尾。MDLV 表示罗马数字 1555。 |
|
这个模式匹配字符串的开始,接着是三个可选的 M 字符的两个,接着匹配 D?C{0,3},此处为一个字符 D 和三个可选 C 字符中的一个,接着匹配 L?X{0,3},此处为一个 L 字符和三个可选 X 字符中的一个,接着匹配 V?I{0,3},此处为一个字符 V 和三个可选 I 字符中的一个,接着匹配字符串的结尾。MMDCLXVI 表示罗马数字 2666。 |
|
这个模式匹配字符串的开始,接着是三个可选的 M 字符的所有字符,接着匹配 D?C{0,3},此处为一个字符 D 和三个可选 C 字符中所有字符,接着匹配 L?X{0,3},此处为一个 L 字符和三个可选 X 字符中所有字符,接着匹配 V?I{0,3},此处为一个字符 V 和三个可选 I 字符中所有字符,接着匹配字符串的结尾。MMMDCCCLXXXVIII 表示罗马数字3888,这个数字是不用扩展语法可以写出的最大的罗马数字。 |
|
仔细看哪!(我像一个魔术师一样,“看仔细喽,孩子们,我将要从我的帽子中拽出一只兔子来啦!”) 这个模式匹配字符串的开始,接着匹配 3 个可选 M 字符的 0 个,接着匹配 D?C{0,3},此处,跳过可选字符 D 并匹配三个可选 C 字符的 0 个,接着匹配 L?X{0,3},此处,跳过可选字符 L 并匹配三个可选 X 字符的 0 个,接着匹配 V?I{0,3},此处跳过可选字符 V 并匹配三个可选 I 字符的一个,最后匹配字符串的结尾。哇赛! |
如果你在第一遍就跟上并理解了所讲的这些,那么你做的比我还要好。现在,你可以尝试着理解别人大规模程序里关键函数中的正则表达式了。或者想象着几个月后回头理解你自己的正则表达式。我曾经做过这样的事情,但是它并不是那么有趣。
在下一节里,你将会研究另外一种正则表达式语法,它可以使你的表达式具有更好的可维持性。
7.5. 松散正则表达式
迄今为止,你只是处理过被我称之为“紧凑”类型的正则表达式。正如你曾看到的,它们难以阅读,即使你清楚正则表达式的含义,你也不能保证六个月以后你还能理解它。你真正所需的就是利用内联文档 (inline documentation)。
Python 允许用户利用所谓的松散正则表达式 来完成这个任务。一个松散正则表达式和一个紧凑正则表达式主要区别表现在两个方面:
- 忽略空白符。空格符,制表符,回车符不匹配它们自身,它们根本不参与匹配。(如果你想在松散正则表达式中匹配一个空格符,你必须在它前面添加一个反斜线符号对它进行转义。)
- 忽略注释。在松散正则表达式中的注释和在普通 Python 代码中的一样:开始于一个#符号,结束于行尾。这种情况下,采用在一个多行字符串中注释,而不是在源代码中注释,它们以相同的方式工作。
用一个例子可以解释得更清楚。让我们重新来看前面的紧凑正则表达式,利用松散正则表达式重新表达。下面的例子显示实现方法。
例 7.9. 带有内联注释 (Inline Comments) 的正则表达式
>>> pattern = """
^ # beginning of string
M{0,3} # thousands - 0 to 3 M's
(CM|CD|D?C{0,3}) # hundreds - 900 (CM), 400 (CD), 0-300 (0 to 3 C's),
# or 500-800 (D, followed by 0 to 3 C's)
(XC|XL|L?X{0,3}) # tens - 90 (XC), 40 (XL), 0-30 (0 to 3 X's),
# or 50-80 (L, followed by 0 to 3 X's)
(IX|IV|V?I{0,3}) # ones - 9 (IX), 4 (IV), 0-3 (0 to 3 I's),
# or 5-8 (V, followed by 0 to 3 I's)
$ # end of string
"""
>>> re.search(pattern, 'M', re.VERBOSE)
<_sre.SRE_Match object at 0x008EEB48>
>>> re.search(pattern, 'MCMLXXXIX', re.VERBOSE)
<_sre.SRE_Match object at 0x008EEB48>
>>> re.search(pattern, 'MMMDCCCLXXXVIII', re.VERBOSE)
<_sre.SRE_Match object at 0x008EEB48>
>>> re.search(pattern, 'M')
|
当使用松散正则表达式时,最重要的一件事情就是:必须传递一个额外的参数 re.VERBOSE,该参数是定义在 re 模块中的一个常量,标志着待匹配的正则表达式是一个松散正则表达式。正如你看到的,这个模式中,有很多空格 (所有的空格都被忽略),和几个注释 (所有的注释也被忽略)。如果忽略所有的空格和注释,它就和前面章节里的正则表达式完全相同,但是具有更好的可读性。 |
|
这个模式匹配字符串的开始,接着匹配三个可选 M 字符中的一个,接着匹配 CM,接着是字符 L 和三个可选 X 字符的所有字符,接着是 IX,然后是字符串的结尾。 |
|
这个模式匹配字符串的开始,接着是三个可选的 M 字符的所有字符,接着匹配 D?C{0,3},此处为一个字符 D 和三个可选 C 字符中所有字符,接着匹配 L?X{0,3},此处为一个 L 字符和三个可选 X 字符中所有字符,接着匹配 V?I{0,3},此处为一个字符 V 和三个可选 I 字符中所有字符,接着匹配字符串的结尾。 |
|
这个没有匹配。为什么呢?因为没有 re.VERBOSE 标记,所以 re.search 函数把模式作为一个紧凑正则表达式进行匹配。Python 不能自动检测一个正则表达式是为松散类型还是紧凑类型。Python 默认每一个正则表达式都是紧凑类型的,除非你显式地标明一个正则表达式为松散类型。 |
7.6. 个案研究:解析电话号码
迄今为止,你主要是匹配整个模式,不论是匹配上,还是没有匹配上。但是正则表达式还有比这更为强大的功能。当一个模式确实 匹配上时,你可以获取模式中特定的片断,你可以发现具体匹配的位置。
这个例子来源于我遇到的另一个现实世界的问题,也是在以前的工作中遇到的。问题是:解析一个美国电话号码。客户要能 (在一个单一的区域中) 输入任何数字,然后存储区号、干线号、电话号和一个可选的独立的分机号到公司数据库里。为此,我通过网络找了很多正则表达式的例子,但是没有一个能够完全 满足我的要求。
这里列举了我必须能够接受的电话号码:
- 800-555-1212
- 800 555 1212
- 800.555.1212
- (800) 555-1212
- 1-800-555-1212
- 800-555-1212-1234
- 800-555-1212x1234
- 800-555-1212 ext. 1234
- work 1-(800) 555.1212 #1234
格式可真够多的!我需要知道区号是 800,干线号是 555,电话号的其他数字为 1212。对于那些有分机号的,我需要知道分机号为 1234。
让我们完成电话号码解析这个工作,这个例子展示第一步。
例 7.10. 发现数字
>>> phonePattern = re.compile(r'^(\d{3})-(\d{3})-(\d{4})$')
>>> phonePattern.search('800-555-1212').groups()
('800', '555', '1212')
>>> phonePattern.search('800-555-1212-1234')
>>>
|
我们通常从左到右阅读正则表达式。这个正则表达式匹配字符串的开始,接着匹配 (\d{3})。\d{3} 是什么呢?好吧,{3} 的含义是“精确匹配三个数字”;这是曾在前面见到过的 {n,m} 语法的一种变形。\d 的含义是 “任何一个数字” (0 到 9)。把它们放大括号中意味着要“精确匹配三个数字位,接着把它们作为一个组保存下来,以便后面的调用”。接着匹配一个连字符,接着是另外一个精确匹配三个数字位的组,接着另外一个连字符,接着另外一个精确匹配四个数字为的组,接着匹配字符串的结尾。 |
|
为了访问正则表达式解析过程中记忆下来的多个组,我们使用 search 函数返回对象的 groups() 函数。这个函数将返回一个元组,元组中的元素就是正则表达式中定义的组。在这个例子中,定义了三个组,第一个组有三个数字位,第二个组有三个数字位,第三个组有四个数字位。 |
|
这个正则表达式不是最终的答案,因为它不能处理在电话号码结尾有分机号的情况,为此,我们需要扩展这个正则表达式。 |
例 7.11. 发现分机号
>>> phonePattern = re.compile(r'^(\d{3})-(\d{3})-(\d{4})-(\d+)$')
>>> phonePattern.search('800-555-1212-1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800 555 1212 1234')
>>>
>>> phonePattern.search('800-555-1212')
>>>
|
这个正则表达式和上一个几乎相同,正像前面的那样,匹配字符串的开始,接着匹配一个有三个数字位的组并记忆下来,接着是一个连字符,接着是一个有三个数字位的组并记忆下来,接着是一个连字符,接着是一个有四个数字位的组并记忆下来。不同的地方是你接着又匹配了另一个连字符,然后是一个有一个或者多个数字位的组并记忆下来,最后是字符串的结尾。 |
|
函数 groups() 现在返回一个有四个元素的元组,由于正则表达式中定义了四个记忆的组。 |
|
不幸的是,这个正则表达式也不是最终的答案,因为它假设电话号码的不同部分是由连字符分割的。如果一个电话号码是由空格符、逗号或者点号分割呢?你需要一个更一般的解决方案来匹配几种不同的分割类型。 |
|
啊呀!这个正则表达式不仅不能解决你想要的任何问题,反而性能更弱了,因为现在你甚至不能解析一个没有分机号的电话号码了。这根本不是你想要的,如果有分机号,你要知道分机号是什么,如果没有分机号,你仍然想要知道主电话号码的其他部分是什么。 |
下一个例子展示正则表达式处理一个电话号码内部,采用不同分隔符的情况。
例 7.12. 处理不同分隔符
>>> phonePattern = re.compile(r'^(\d{3})\D+(\d{3})\D+(\d{4})\D+(\d+)$')
>>> phonePattern.search('800 555 1212 1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212-1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('80055512121234')
>>>
>>> phonePattern.search('800-555-1212')
>>>
|
当心啦!你首先匹配字符串的开始,接着是一个三个数字位的组,接着是 \D+,这是个什么东西?好吧,\D 匹配任意字符,除了 数字位,+ 表示“1 个或者多个”,因此 \D+ 匹配一个或者多个不是数字位的字符。这就是你替换连字符为了匹配不同分隔符所用的方法。 |
|
使用 \D+ 代替 - 意味着现在你可以匹配中间是空格符分割的电话号码了。 |
|
当然,用连字符分割的电话号码也能够被识别。 |
|
不幸的是,这个正则表达式仍然不是最终答案,因为它假设电话号码一定有分隔符。如果电话号码中间没有空格符或者连字符的情况会怎样哪? |
|
我的天!这个正则表达式也没有达到我们对于分机号识别的要求。现在你共有两个问题,但是你可以利用相同的技术来解决它们。 |
下一个例子展示正则表达式处理没有 分隔符的电话号码的情况。
例 7.13. 处理没有分隔符的数字
>>> phonePattern = re.compile(r'^(\d{3})\D*(\d{3})\D*(\d{4})\D*(\d*)$')
>>> phonePattern.search('80055512121234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800.555.1212 x1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212').groups()
('800', '555', '1212', '')
>>> phonePattern.search('(800)5551212 x1234')
>>>
|
和上一步相比,你所做的唯一变化就是把所有的 + 变成 *。在电话号码的不同部分之间不再匹配 \D+,而是匹配 \D* 了。还记得 + 的含义是“1 或者多个”吗? 好的,* 的含义是“0 或者多个”。因此,现在你应该能够解析没有分隔符的电话号码了。 |
|
你瞧,它真的可以胜任。为什么?首先匹配字符串的开始,接着是一个有三个数字位 (800) 的组,接着是 0 个非数字字符,接着是一个有三个数字位 (555) 的组,接着是 0 个非数字字符,接着是一个有四个数字位 (1212) 的组,接着是 0 个非数字字符,接着是一个有任意数字位 (1234) 的组,最后是字符串的结尾。 |
|
对于其他的变化也能够匹配:比如点号分隔符,在分机号前面既有空格符又有 x 符号的情况也能够匹配。 |
|
最后,你已经解决了长期存在的一个问题:现在分机号是可选的了。如果没有发现分机号,groups() 函数仍然返回一个有四个元素的元组,但是第四个元素只是一个空字符串。 |
|
我不喜欢做一个坏消息的传递人,此时你还没有完全结束这个问题。还有什么问题呢?当在区号前面还有一个额外的字符时,而正则表达式假设区号是一个字符串的开始,因此不能匹配。这个不是问题,你可以利用相同的技术“0或者多个非数字字符”来跳过区号前面的字符。 |
下一个例子展示如何解决电话号码前面有其他字符的情况。
例 7.14. 处理开始字符
>>> phonePattern = re.compile(r'^\D*(\d{3})\D*(\d{3})\D*(\d{4})\D*(\d*)$')
>>> phonePattern.search('(800)5551212 ext. 1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212').groups()
('800', '555', '1212', '')
>>> phonePattern.search('work 1-(800) 555.1212 #1234')
>>>
|
这个正则表达式和前面的几乎相同,但它在第一个记忆组 (区号) 前面匹配 \D*,0 或者多个非数字字符。注意,此处你没有记忆这些非数字字符 (它们没有被括号括起来)。如果你发现它们,只是跳过它们,接着只要匹配上就开始记忆区号。 |
|
你可以成功地解析电话号码,即使在区号前面有一个左括号。(在区号后面的右括号也已经被处理,它被看成非数字字符分隔符,由第一个记忆组后面的 \D* 匹配。) |
|
进行仔细的检查,保证你没有破坏前面能够匹配的任何情况。由于首字符是完全可选的,这个模式匹配字符串的开始,接着是 0 个非数字字符,接着是一个有三个数字字符的记忆组 (800),接着是 1 个非数字字符 (连字符),接着是一个有三个数字字符的记忆组 (555),接着是 1 个非数字字符 (连字符),接着是一个有四个数字字符的记忆组 (1212),接着是 0 个非数字字符,接着是一个有 0 个数字位的记忆组,最后是字符串的结尾。 |
|
此处是正则表达式让我产生了找一个硬东西挖出自己的眼睛的冲动。为什么这个电话号码没有匹配上?因为在它的区号前面有一个 1,但是你认为在区号前面的所有字符都是非数字字符 (\D*)。唉! |
让我们往回看一下。迄今为止,正则表达式总是从一个字符串的开始匹配。但是现在你看到了,有很多不确定的情况需要你忽略。与其尽力全部匹配它们,还不如全部跳过它们,让我们采用一个不同的方法:根本不显式地匹配字符串的开始。下面的这个例子展示这个方法。
例 7.15. 电话号码,无论何时我都要找到它
>>> phonePattern = re.compile(r'(\d{3})\D*(\d{3})\D*(\d{4})\D*(\d*)$')
>>> phonePattern.search('work 1-(800) 555.1212 #1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212')
('800', '555', '1212', '')
>>> phonePattern.search('80055512121234')
('800', '555', '1212', '1234')
|
注意,在这个正则表达式的开始少了一个 ^ 字符。你不再匹配字符串的开始了,也就是说,你需要用你的正则表达式匹配整个输入字符串,除此之外没有别的意思了。正则表达式引擎将要努力计算出开始匹配输入字符串的位置,并且从这个位置开始匹配。 |
|
现在你可以成功解析一个电话号码了,无论这个电话号码的首字符是不是数字,无论在电话号码各部分之间有多少任意类型的分隔符。 |
|
仔细检查,这个正则表达式仍然工作的很好。 |
|
还是能够工作。 |
看看一个正则表达式能够失控得多快?回头看看前面的例子,你还能区别它们么?
当你还能够理解这个最终答案的时候 (这个正则表达式就是最终答案,即使你发现一种它不能处理的情况,我也真的不想知道它了),在你忘记为什么你这么选择之前,让我们把它写成松散正则表达式的形式。
例 7.16. 解析电话号码 (最终版本)
>>> phonePattern = re.compile(r'''
# don't match beginning of string, number can start anywhere
(\d{3}) # area code is 3 digits (e.g. '800')
\D* # optional separator is any number of non-digits
(\d{3}) # trunk is 3 digits (e.g. '555')
\D* # optional separator
(\d{4}) # rest of number is 4 digits (e.g. '1212')
\D* # optional separator
(\d*) # extension is optional and can be any number of digits
$ # end of string
''', re.VERBOSE)
>>> phonePattern.search('work 1-(800) 555.1212 #1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212')
('800', '555', '1212', '')
|
除了被分成多行,这个正则表达式和最后一步的那个完全相同,因此它能够解析相同的输入一点也不奇怪。 |
|
进行最后的仔细检查。很好,仍然工作。你终于完成了这件任务。 |
关于正则表达式的进一步阅读
- Regular Expression HOWTO 讲解正则表达式和如何在 Python 中使用正则表达式。
- Python Library Reference 概述了 re module。
7.7. 小结
这只是正则表达式能够完成工作的很少一部分。换句话说,即使你现在备受打击,相信我,你也不是什么也没见过了。
现在,你应该熟悉下列技巧:
- ^ 匹配字符串的开始。
- $ 匹配字符串的结尾。
- \b 匹配一个单词的边界。
- \d 匹配任意数字。
- \D 匹配任意非数字字符。
- x? 匹配一个可选的 x 字符 (换言之,它匹配 1 次或者 0 次 x 字符)。
- x* 匹配0次或者多次 x 字符。
- x+ 匹配1次或者多次 x 字符。
- x{n,m} 匹配 x 字符,至少 n 次,至多 m 次。
- (a|b|c) 要么匹配 a,要么匹配 b,要么匹配 c。
- (x) 一般情况下表示一个记忆组 (remembered group)。你可以利用 re.search 函数返回对象的 groups() 函数获取它的值。
正则表达式非常强大,但是它并不能为每一个问题提供正确的解决方案。你应该学习足够多的知识,以辨别什么时候它们是合适的,什么时候它们会解决你的问题,什么时候它们产生的问题比要解决的问题还要多。
|
一些人,遇到一个问题时就想:“我知道,我将使用正则表达式。”现在他有两个问题了。 |
python study - 正则表达式的更多相关文章
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- Python 进阶 - 正则表达式
1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十 ...
- python使用正则表达式文本替换
2D客户端编程从某种意义上来讲就是素材组织,所以,图片素材组织经常需要批量处理,python一定是最佳选择,不管是win/linux/mac都有一个简单的运行环境 举两个应用场景: 如果不是在某个文件 ...
- python的正则表达式 re
python的正则表达式 re 本模块提供了和Perl里的正则表达式类似的功能,不关是正则表达式本身还是被搜索的字符串,都可以是Unicode字符,这点不用担心,python会处理地和Ascii字符一 ...
- Python之正则表达式(re模块)
本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 正则表达式(Regluar Expressions)又称规则 ...
- Python:正则表达式详解
正则表达式是一个很强大的字符串处理工具,几乎任何关于字符串的操作都可以使用正则表达式来完成,作为一个爬虫工作者,每天和字符串打交道,正则表达式更是不可或缺的技能,正则表达式的在不同的语言中使用方式可能 ...
- 【Python】正则表达式纯代码极简教程
<Python3正则表达式>文字版详细教程链接:https://www.cnblogs.com/leejack/p/9189796.html ''' 内容:Python3正则表达式 日期: ...
- 【Python】正则表达式简单教程
说明:本文主要是根据廖雪峰网站的正则表达式教程学习,并根据需要做了少许修改,此处记录下来以备后续查看. <Python正则表达式纯代码极简教程>链接:https://www.cnblogs ...
- 【转】Python之正则表达式(re模块)
[转]Python之正则表达式(re模块) 本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 参考文档 提示: ...
随机推荐
- java基础之 http
HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则.计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求 ...
- matlab:clear,close,clc
clear 删除工作空间中的项目,释放系统内存 语法: clear clear name clear name1 name2 name3... clear global name clear -reg ...
- vs2012 .netFramwork2.0发布到xp
开发环境 windows server2008R2 VS2012 .net Framwork2.0 开发的winform程序 在有的xp系统下不能运行 选择 项目属性=>编译 Build=&g ...
- jQuery 自定义扩展,与$冲突处理
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- MySQL数据类型(四)
一.数据类型 二.整型类型 tinyInt: 1个字节:-128-127(有符号) 是否有符号,可以定义时,使用unsign标识,表示无符号的,不写表示有符号的 Create table studen ...
- uva11059
除法(Division,uva725) 输入整数n,按从小到大的顺序输出所有形如abcde/fghij=n的表达式,其中a~j恰好为数字0~9的一个排列(可以有前导0),2<=n<=79. ...
- Notification通知栏
Notification通知栏 首先实现的功能就是通知栏显示Notification,Notification是显示在系统的通知栏上面的,所以Notification 是属于进程之前的通讯.进程之间的 ...
- hdu4597 区间dp
//Accepted 1784 KB 78 ms //区间dp //dp[l1][r1][l2][r2] 表示a数列从l1到r1,b数列从l2到r2能得到的最大分值 // #include <c ...
- TPLink 备份文件bin文件解析
TPLink 路由器备份文件bin文件 测试路由器 WR885,备份文件加密方式DES,密钥:478DA50BF9E3D2CF linux端: openssl enc -d -des-ecb -nop ...
- MATLAB里的正则表达式 [转]
正则表达式在处理字符串及文本时显得十分方便,在perl, python等脚本语言,以及java, .net等平台上都支援正则表达式.事实上,在MATLAB中也提供了正则表达式的支持.主要包含三个常用的 ...