celery入门
认识
这里有几个概念,task、worker、broker。
顾名思义,task 就是老板交给你的各种任务,worker 就是你手下干活的人员。
那什么是 Broker 呢?
老板给你下发任务时,你需要 把它记下来, 这个它 可以是你随身携带的本子,也可以是 电脑里地记事本或者excel,或者是你的 任何时间管理工具。
Broker 则是 Celery 记录task的地方。
作为一个任务管理者的你,将老板(前端程序)发给你的 安排的工作(Task) 记录到你的本子(Broker)里。接下来,你就安排你手下的IT程序猿们(Worker),都到你的本子(Broker)里来取走工作(Task)
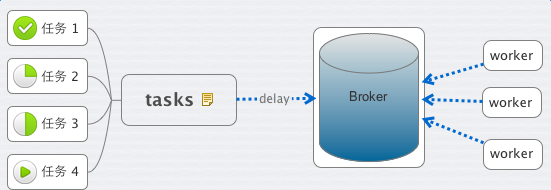
1. broker为rabbitmq
#tasks.py
from celery import Celery
app = Celery('tasks', broker='amqp://admin:admin@localhost:5672')
@app.task
def add(x, y):
return x + y
启动
celery -A tasks worker --loglevel=info
运行

>>> from tasks import add
>>> add(1, 3)
4
>>> add.delay(1,3)
<AsyncResult: 07614cef-f314-4c7b-a33f-92c080cadb83>
>>>
注:delay是使用异步的方式,会压入到消息队列。否则,不会使用消息队列。
文件名为tasks.py,则其中代码app = Celery('tasks', broker=),Celery第一个参数为文件名,启动时也是celery -A tasks worker --loglevel=info
2. 以python+文件名的方式启动
例1:
#test.py
from celery import Celery
import time
app = Celery('test', backend='amqp', broker='amqp://admin:admin@localhost:5672') @app.task
def add(x, y):
print "------>"
time.sleep(5)
print "<--------------"
return x + y if __name__ == "__main__":
app.start()
启动
python test.py worker
celery默认启动的worker数为内核个数,如果指定启动个数,用参数-c,例
python test.py worker -c 2
例2:
#test.py
from celery import Celery
import time
app = Celery('test', backend='amqp', broker='amqp://admin:admin@localhost:5672') @app.task
def add(x, y):
print "------>"
time.sleep(2)
print "<--------------"
return x + y if __name__ == "__main__":
app.start()
#eg.py
from test import *
import time rev = []
for i in range(3):
rev.append(add.delay(1,3)) print "len rev:", len(rev)
while 1:
tag = 1
for key in rev:
if not key.ready():
tag = 0
time.sleep(1)
print "sleep 1"
if tag:
break
print "_____________________>"
3. broker为redis
#test_redis.py
from celery import Celery
import time
#app = Celery('test_redis', backend='amqp', broker='redis://100.69.201.116:7000')
app = Celery('test_redis', backend='redis', broker='redis://100.69.201.116:7000') @app.task
def add(x, y):
print "------>"
time.sleep(5)
print "<--------------"
return x + y if __name__ == "__main__":
app.start()
启动
python test_redis.py worker -c 2
测试
from celery import group
from test_redis import *
g = group(add.s(2, 3)).apply_async()
g = group(add.s(2, 3)).apply_async()
g = group(add.s(2, 3)).apply_async()
g = group(add.s(2, 3)).apply_async()
g = group(add.s(2, 3)).apply_async()
for ret in g.get():
print ret
print "end-----------------------------------"
结果
5
end-----------------------------------
4. 两个队列(redis)
#test_redis.py
from celery import Celery
import time
#app = Celery('test_redis', backend='amqp', broker='redis://100.69.201.116:7000')
app = Celery('test_redis', backend='redis', broker='redis://100.69.201.116:7000') @app.task
def add(x, y):
print "------>"
time.sleep(5)
print "<--------------"
return x + y if __name__ == "__main__":
app.start()
#test_redis_2.py
from celery import Celery
import time
#app = Celery('test_redis', backend='amqp', broker='redis://100.69.201.116:7000')
app = Celery('test_redis_2', backend='redis', broker='redis://100.69.201.116:7001') @app.task
def add_2(x, y):
print "=======>"
time.sleep(5)
print "<================="
return x + y if __name__ == "__main__":
app.start()
测试
from celery import group
from test_redis import *
from test_redis_2 import *
ll = [(1,2), (3,4), (5,6)]
g = group(add.s(key[0], key[1]) for key in ll).apply_async()
for ret in g.get():
print ret
print "end redis_1 -----------------------------------" ll = [(1,2), (3,4), (5,6)]
g = group(add_2.s(key[0], key[1]) for key in ll).apply_async()
for ret in g.get():
print ":", ret
print "end redis_2 -----------------------------------"
结果
3
7
11
end redis_1 -----------------------------------
: 3
: 7
: 11
end redis_2 -----------------------------------
5. 两个队列(同一个rabbitmq)
注释:需要提前设置下队列
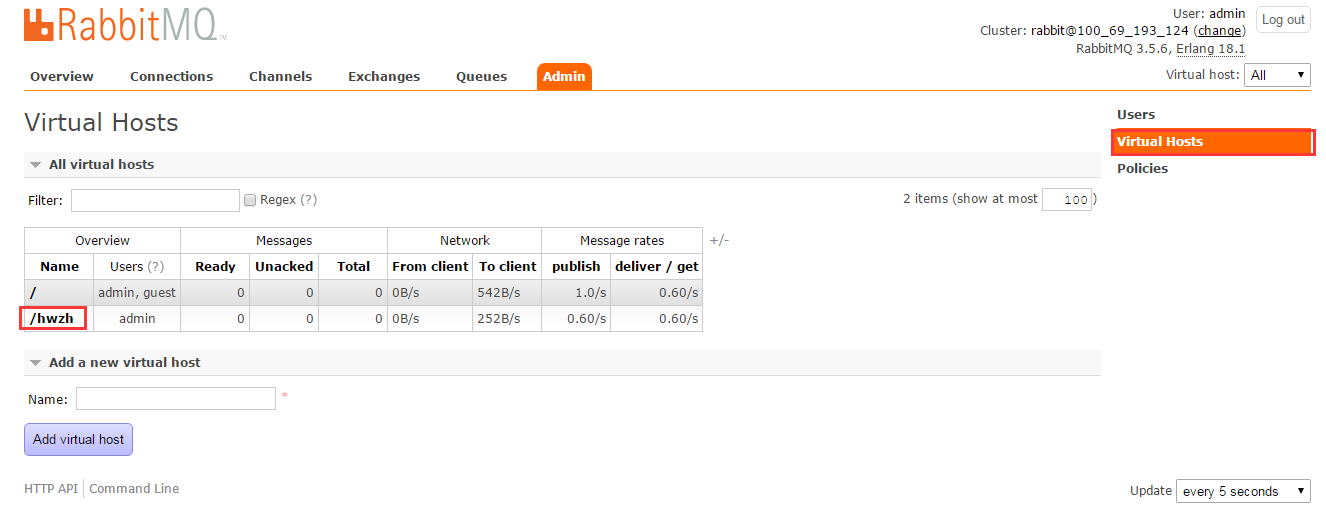
##例1
#test.py
from celery import Celery
import time
app = Celery('test', backend='amqp', broker='amqp://admin:admin@localhost:5672//') @app.task
def add(x, y):
print "------>"
time.sleep(5)
print "<--------------"
return x + y if __name__ == "__main__":
app.start()
#test_2.py
from celery import Celery
import time
app = Celery('test_2', backend='amqp', broker='amqp://admin:admin@localhost:5672//hwzh') @app.task
def add_2(x, y):
print "=====>"
time.sleep(5)
print "<=========="
return x + y if __name__ == "__main__":
app.start()
测试
from celery import group
from test import *
from test_2 import * ll = [(1,2), (3,4), (7,8)]
g = group(add.s(key[0], key[1]) for key in ll).apply_async()
for ret in g.get():
print ret ll = [(1,2), (3,4), (7,8)]
g = group(add_2.s(key[0], key[1]) for key in ll).apply_async()
for ret in g.get():
print ret
结果
3
7
15
3
7
15
##例2
#test.py
from celery import Celery
import time
app = Celery('test', backend='amqp', broker='amqp://admin:admin@localhost:5672//mq4') @app.task
def add(x, y):
print "------>"
time.sleep(2)
print "<--------------"
return x + y @app.task
def sum(x, y):
print "------>"
time.sleep(2)
print "<--------------"
return x + y if __name__ == "__main__":
app.start()
#eg2.py
from test import *
import time rev = []
for i in range(3):
rev.append(add.delay(1,3)) for i in range(3):
rev.append(sum.delay(1,3)) print "len rev:", len(rev)
while 1:
tag = 1
for key in rev:
if not key.ready():
tag = 0
time.sleep(1)
print "sleep 1"
if tag:
break
print "_____________________>"
6. 保存结果
from celery import Celery
app = Celery('tasks', backend='amqp', broker='amqp://admin:admin@localhost')
@app.task
def add(x, y):
return x + y
启动
celery -A tasks_1 worker --loglevel=info
与前例不同:
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7f8057931810
- ** ---------- .> transport: amqp://admin:**@localhost:5672//
- ** ---------- .> results: amqp
运行
>>> from tasks_1 import add
>>> result = add.delay(1, 3)
>>> result.ready()
True
>>> result.get()
4
7. 多个队列
from celery import Celery
from kombu import Exchange, Queue
BROKER_URL = 'amqp://admin:admin@localhost//'
app = Celery('tasks', backend='amqp',broker=BROKER_URL)
app.conf.update(
CELERY_ROUTES={
"add1":{"queue":"queue_add1"},
"add2":{"queue":"queue_add2"},
"add3":{"queue":"queue_add3"},
"add4":{"queue":"queue_add4"},
},
)
@app.task
def add1(x, y):
return x + y @app.task
def add2(x, y):
return x + y @app.task
def add3(x, y):
return x + y @app.task
def add4(x, y):
return x + y
celery入门的更多相关文章
- Celery入门指北
Celery入门指北 其实本文就是我看完Celery的官方文档指南的读书笔记.然后由于我的懒,只看完了那些入门指南,原文地址:First Steps with Celery,Next Steps,Us ...
- 分布式队列Celery入门
Celery 是一个简单.灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具.它是一个专注于实时处理的任务队列,同时也支持任务调度.Celery 是语言无关的,虽然它是用 Py ...
- celery 入门
认识 这里有几个概念,task.worker.broker.顾名思义,task 就是老板交给你的各种任务,worker 就是你手下干活的人员. 那什么是 Broker 呢? 老板给你下发任务时,你需要 ...
- 分布式任务队列Celery入门与进阶
一.简介 Celery是由Python开发.简单.灵活.可靠的分布式任务队列,其本质是生产者消费者模型,生产者发送任务到消息队列,消费者负责处理任务.Celery侧重于实时操作,但对调度支持也很好,其 ...
- 异步任务神器 Celery-入门
一.Celery入门介绍 在程序的运行过程中,我们经常会碰到一些耗时耗资源的操作,为了避免它们阻塞主程序的运行,我们经常会采用多线程或异步任务.比如,在 Web 开发中,对新用户的注册,我们通常会给他 ...
- 初识Celery
本系列文章的开发环境: window + python2. + pycharm5 + celery3.1.25 + django1.9.4 在我们日常的开发工作中,经常会遇到这几种情况: 1.在web ...
- Celery异步调度框架(一)基本使用
介绍 之前部门开发一个项目我们需要实现一个定时任务用于收集每天DUBBO接口.域名以及TOMCAT(核心应用)的访问量,这个后面的逻辑就是使用定时任务去ES接口抓取数据存储在数据库中然后前台进行展示. ...
- Django中使用Celery
一.前言 Celery是一个基于python开发的分布式任务队列,如果不了解请阅读笔者上一篇博文Celery入门与进阶,而做python WEB开发最为流行的框架莫属Django,但是Django的请 ...
- 转 Celery 使用
http://www.mamicode.com/info-detail-1798782.html https://blog.csdn.net/lu1005287365/article/details/ ...
随机推荐
- 【crunch bang】安装firefox,删除iceweasel
首先,移除iceweasel: apt-get remove iceweasel Then, download the latest Linux build of Firefox directly f ...
- $("label + input") 匹配所有紧接在 prev 元素后的 next 元素
描述: 匹配所有跟在 label 后面的 input 元素 HTML 代码: <form> <label>Name:</label> <input name= ...
- resultMap / resultType
===================resultMap:实体类的属性和通过resultMap映射后的property属性一致 <resultMap id="workerSelect& ...
- laravel 目录结构
图 1.1 显示了 Laravel 项目目录结构是什么样子: 图1.1 Laravel 项目目录结构 就如你看到这样,laravel下面只包含了4个文件夹,这4个文件夹下面有一些子文件夹,这种丰富的子 ...
- Pascal's Triangle
class Solution { public: vector<vector<int>> generate(int numRows) { vector<vector< ...
- php中引用和赋值的区别主要在哪里
php中引用和赋值的区别 <pphp 的引用允许用两个变量来指向同一个内容. 相当于他们可以是 不同的名字,却可以指向 同一个 物理空间. 赋值,它实际上意味着把右边表达式的值赋给左边的运算数. ...
- Asp.net Vnext api CORS( 跨域)
概述 跨域资源共享(CORS )是一种网络浏览器的技术规范,它为Web服务器定义了一种方式,允许网页从不同的域访问其资源.而这种访问是被同源策略所禁止的.CORS系统定义了一种浏览器和服务器交互的方式 ...
- java当中的定时器的几种使用方式
这几天做的项目有个功能,就是定时执行一项服务,以下几种方法比较高效.不说了 直接撸代码: import java.util.Calendar; import java.util.Date; impo ...
- API判断网站IP地址,国家区域
直接访问http://api.wipmania.com/jsonp 还有经纬度
- 动态规划之LCS(最大公共子序列)
#include <stdio.h> #include <string.h> int b[50][50]; int c[50][50]; int length = 0; voi ...