spider autohome (1)
Code:
#!/usr/bin/python
# -*- coding: UTF-8 -*- import re
import urllib
import time
def getHtml(url):
""" This function just simply get all the data
by the url you get.and then decode and code
to utf-8 which you need.
"""
page = urllib.urlopen(url)
html=page.read()
uni_str = html.decode('gb2312')
utf_str = uni_str.encode('utf-8')
return utf_str def getInfo(html):
"""
This function just simply get the data from the html
and filter some data which we are interest,and then
return a list.
"""
reg = r'config = {(.+?)};'
config_re = re.compile(reg)
config_list = re.findall(config_re,html)
return config_list def getEachCar(config_lists):
""" This function will parse the data,and
then return a list include the all
information of each car,the each item
of the car's information split by '|'.
"""
each_car={}
for sp in config_lists:
config_str='{'+sp+'}'
config_str=config_str.replace("null","None")
regx=r'{"specid":\d{5},"value":.+?}'
cc=re.compile(regx)
xx=re.findall(regx,config_str)
for x in xx:
x=eval(x)
akey=repr(x['specid'])
if each_car.has_key(akey):
each_car[akey]=each_car[akey]+x["value"]+"|"
else:
each_car[akey]=x['value']
jobs=[]
for each in each_car:
ter_data="|"+each_car[each]
jobs.append(ter_data)
return jobs
if __name__ == '__main__':
# html = getHtml("http://car.autohome.com.cn/config/spec/21308.html#pvareaid=100679")
html = getHtml("http://car.autohome.com.cn/config/spec/18239.html")
config_lists=getInfo(html)
each_car=getEachCar(config_lists)
for acar in each_car:
print acar
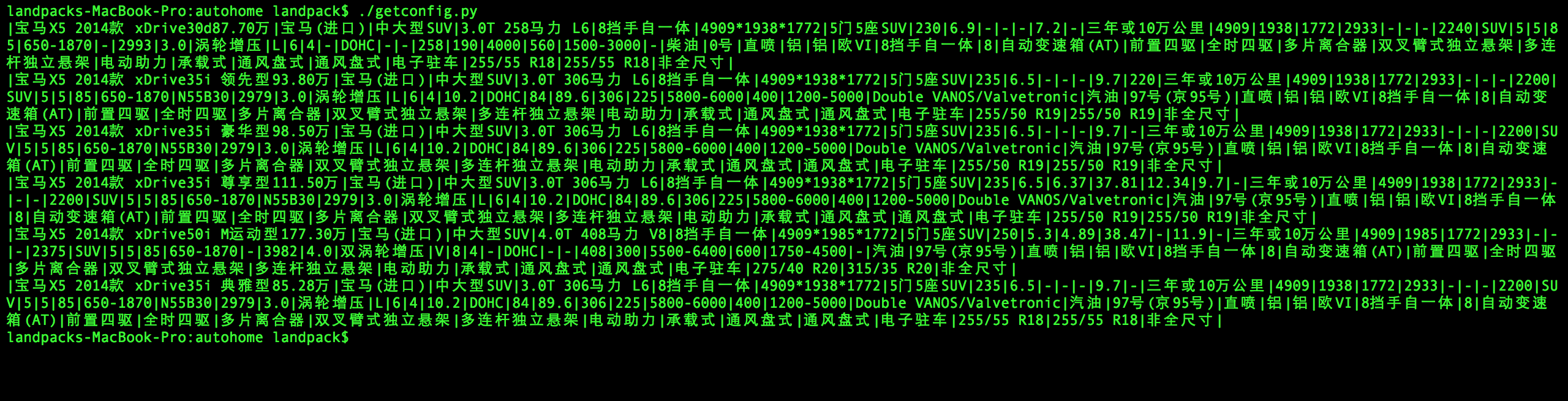
Result:
spider autohome (1)的更多相关文章
- spider RPC入门指南
本部分将介绍使用spider RPC开发分布式应用的客户端和服务端. spider RPC中间件基于J2SE 8开发,因此需要确保服务器上安装了JDK 8及以上版本,不依赖于任何额外需要独立安装和配置 ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- spider RPC过滤器
spider支持在请求执行前或完成后进行特殊处理,比如安全性检查.敏感字段混淆等等.为此,spider提供了BeforeFilter和AfterFilter.其执行位置如下图所示: 流水线插件配置在s ...
- spider RPC插件化体系
为了满足灵活扩展的需要,spider支持灵活的自定义插件扩展,从功能上来说,插件和过滤器的差别在于过滤器不会阻止请求的执行同时对于主程序不会有API上的影响(比如servlet 过滤器和监听器)(最多 ...
- spider RPC管理接口
为了在独立管理模式下尽可能的容易运行时排查问题,spider中间件提供了一系列restful api用于动态管理当前节点的路由,下游节点等.目前支持的RESTFUL API如下所示: 功能 服务号 R ...
- spider RPC高级特性
多租户 spider原生支持多租户部署,spider报文头对外开放了机构号.系统号两个属性用于支持多租户场景下的路由. 多租户场景下的路由可以支持下述几种模式: n 系统号: n 系统号+服务号( ...
- spider RPC安全性
spider提供了多重安全保障机制,目前主要支持接入握手校验,报文完整性校验,报文加密,报文长度检查四种机制. 接入认证 spider使用两次握手校验,其握手流程如下: 签名AES加密的方式实现. l ...
- spider RPC开发指南
协议与兼容性 spider使用java语言开发,使用Spring作为IoC容器,采用TCP/IP协议,在此基础上,结合SaaS系统模式的特性进行针对性和重点设计,以更加灵活和高效的满足多租户系统.高可 ...
- spider 配置文件参考
spider有一个配置文件spider.xml,为xml格式,spider.xml采用DTD进行管理,用于管理spider的所有特性.路由.高可用等. 配置文件支持三种不同的方式进行指定: 1. 通过 ...
随机推荐
- linux下(Ubuntu、centos)添加永久静态路由的方法
项目中经常遇到多网卡的服务器,但是一个服务器的默认网关只有一个,当需要在多个网络中访问的时候(特别是在公安.交警等政府项目中),就需要添加静态路由了. 添加静态路由的方法有很多种,下面介绍2种比较常见 ...
- Hosting static website on AWS
http://docs.aws.amazon.com/AmazonS3/latest/dev/website-hosting-custom-domain-walkthrough.html#root-d ...
- Python-dict与set
dict(字典):用空间换取时间,占据空间大,但查询速度快,键值对(key:value),key唯一 d = {'Michael': 95, 'Bob': 75, 'Tracy': 85} 由于一个k ...
- 纯手工打造(不使用IDE)java web 项目
必备环境 1.编译器:jdk 2.web服务器:tomcat 3.文本编辑器:sublime,编写java文件和jsp文件,没有的话用记事本也行. 一.建立工程目录结构,如下图 在操作系统下完成即可, ...
- count distinct 多个字段 或者 count(*) 统计group by 结果
SELECT COUNT(*) FROM( SELECT 列名 FROM 表名 where ( 条件 )GROUP BY 多字段)临时表名 例如: SELECT COUNT(*) FROM(SELEC ...
- java代码性能优化总结(转载)
原文链接:http://developer.51cto.com/art/201511/496263.htm 前言 代码优化,一个很重要的课题.可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改 ...
- 使用dynamic动态设置属性值与反射设置属性值性能对比
static void Main(string[] args) { int times = 1000000; string value = "Dynamic VS Reflection&qu ...
- oracle 多级菜单查询 。start with connect by prior
select * from S_dept where CODE in(select sd.code from s_dept sd start with sd.code='GDKB' connect b ...
- load-on-startup在web.xml中的含义
在servlet的配置当中,<load-on-startup>1</load-on-startup>的含义是: 标记容器是否在启动的时候就加载这个servlet. 当值为0或者 ...
- Attributes:文本属性 和NSAttributedString
前言: 有一些控件无法直接设置文本大小,需要使用方法 setTitleTextAttributes 来设置文本属性 UIFont 字体样式 [UIFont fontWithName~]; iOS- 详 ...