SURF算法与源码分析、下
上一篇文章 SURF算法与源码分析、上 中主要分析的是SURF特征点定位的算法原理与相关OpenCV中的源码分析,这篇文章接着上篇文章对已经定位到的SURF特征点进行特征描述。这一步至关重要,这是SURF特征点匹配的基础。总体来说算法思路和SIFT相似,只是每一步都做了不同程度的近似与简化,提高了效率。
1. SURF特征点方向分配
为了保证特征矢量具有旋转不变性,与SIFT特征一样,需要对每个特征点分配一个主方向。为些,我们需要以特征点为中心,以$6s$($s = 1.2 *L /9$为特征点的尺度)为半径的圆形区域,对图像进行Haar小波响应运算。这样做实际就是对图像进行梯度运算只不过是我们需要利用积分图像,提高计算图像梯度的效率。在SIFT特征描述子中我们在求取特征点主方向时,以是特征点为中心,在以4.5$\sigma$为半径的邻域内计算梯度方向直方图。事实上,两种方法在求取特征点主方向时,考虑到Haar小波的模板带宽,实际计算梯度的图像区域是相同的。用于计算梯度的Harr小波的尺度为4s。
与SIFT类似,使用$\sigma = 2s$的高斯加权函数对Harr小波的响应值进行高斯加权。为了求取主方向值,需要设计一个以特征点为中心,张角为$\pi/3$的扇形滑动窗口。以步长为0.2弧度左右,旋转这个滑动窗口,并对滑动窗口内的图像Harr小波响应值dx、dy进行累加,得到一个矢量$(m_w,\theta_w)$:
$$m_w = \sum _w dx + \sum_w dy$$
$$\theta_w = arctan(\sum_w dx / \sum_w dy)$$
主方向为最大Harr响应累加值所对应的方向,也就是最长矢量所对应的方向,即
$$\theta = \theta_w|max\{m_w\}$$
可以依照SIFT求方方向时策略,当存在另一个相当于主峰值80%能量的峰值时,则将这个方向认为是该特征点的辅方向。一个特征点可能会被指定具有多个方向(一个主方向,一个以上辅方向),这可以增强匹配的鲁棒性。和SIFT的描述子类似,如果在$m_w$中出现另一个大于主峰能量$max\{m_w\} 80%$时的次峰,可以将该特征点复制成两个特征点。一个主的方向为最大响应能量所对应的方向,另一个主方向为次大响应能量所对应的方向。

图 1 求取主方向时扇形滑动窗口围绕特征点转动,统计Haar小波响应值,并计算方向角
2. 特征点特征矢量生成
生成特征点描述子与确定特征点方向有些类似,它需要计算图像的Haar小波响应。不过,与主方向的确定不同的是,这次我们不是使用一个圆形区域,而是在一个矩形区域来计算Haar小波响应。以特征点为中心,沿上一节讨论得到的主方向,沿主方向将$s20s\times20s$的图像划分为$4\times4$个子块,每个子块利用尺寸$2s$的Harr模板进行响应值进行响应值计算,然后对响应值进行统计$\sum dx$、$\sum |dx|$、$\sum dy$、$\sum |dy|$形成特征矢量。如下图2所示。图中,以特征点为中心,以20s为边长的矩形窗口为特征描述子计算使用的窗口,特征点到矩形边框的线段表示特征点的主方向。
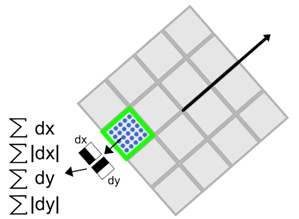
图2 特征描述子表示
将$20s$的窗口划分成$4\times4$子窗口,每个子窗口有$5s\times5s$个像素。使用尺寸为$2s$的Harr小波对子窗口图像进行其响应值计算,共进行25次采样,分别得到沿主方向的dy和垂直于主方向的dx。然后,以特征点为中心,对dy和dx进行高斯加权计算,高斯核的参数为$\sigma = 3.3s (即20s/6)$。最后,分别对每个子块的响应值进行统计,得到每个子块的矢量:
$$V_{子块}=\left[\sum dx,\sum |dx|,\sum dy,\sum |dy|\right]$$
由于共有$4\times4$个子块,因此,特征描述子共由$4\times4\times4 = 64$维特征矢量组成。SURF描述子不仅具有尺度和旋转不变性,而且对光照的变化也具有不变性。使小波响应本身就具有亮度不变性,而对比度的不变性则是通过将特征矢量进行归一化来实现。图3 给出了三种不同图像模式的子块得到的不同结果。对于实际图像的描述子,我们可以认为它们是由这三种不同模式图像的描述子组合而成的。
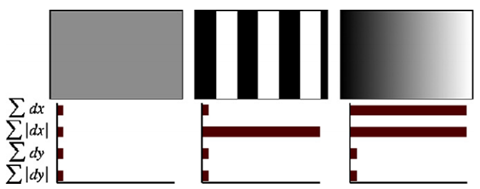
图3 不同的图像密度模式得到的不同的描述子结果
为了充分利用积分图像进行Haar小波的响应计算,我们并不直接旋转Haar小波模板求得其响应值,而是在积图像上先使用水平和垂直的Haar模板求得响应值dy和dx,然后根据主方向旋转dx和dy与主方向操持一致,如下图4所示。为了求得旋转后Haar小波响应值,首先要得到旋转前图像的位置。旋转前后图偈的位置关系,可以通过点的旋转公式得到:
$$x = x_0 –j\times scale\times sin(\theta)+i\times scale\times cos(\theta)$$
$$y = y_0 –j\times scale\times cos(\theta)+i\times scale\times sin(\theta)$$
在得到点$(j,i)$在旋转前对应积分图像的位置$(x,y)$后,利用积分图像与水平、垂直Harr小波,求得水平与垂直两个方向的响应值dx和dy。对dx和dy进行高斯加权处理,并根据主方向的角度,对dx和dy进行旋转变换,从而,得到旋转后的dx’和dy’。其计算公式如下:
$$dx’ = w(-dx\times sin(\theta)+dy\times cos(\theta))$$
$$dy’ = w(-dx\times cos(\theta)+dy\times sin(\theta))$$
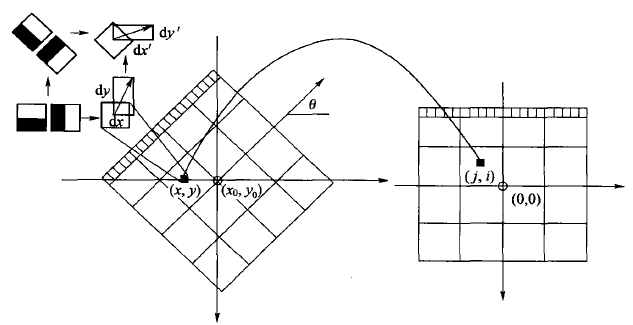
图4 利用积分图像进行Haar小波响应计算示意图,左边为旋转后的图像,右边为旋转前的图像
3. 特征描述子的维数
一般而言,特征矢量的长度越长,特征矢量所承载的信息量就越大,特征描述子的独特性就越好,但匹配时所付出的时间代价就越大。对于SURF描述子,可以将它扩展到用128维矢量来表示。具体方法是在求$\sum dx$、$\sum |dx|$时区分$dy<0$和$dy\ge 0$情况。同时,在求取$\sum dy$、$\sum |dy|$时区分$dx<0$和$dx\ge 0$情况。这样,每个子块就产生了8个梯度统计值,从而使描述子特征矢量的长度增加到$8\times4\times4=128$维。
为了实现快速匹配,SURF在特征矢量中增加了一个新的变量,即特征点的拉普拉斯响应正负号。在特征点检测时,将Hessian矩阵的迹的正负号记录下来,作为特征矢量中的一个变量。这样做并不增加运算量,因为特征点检测进已经对Hessian矩阵的迹进行了计算。在特征匹配时,这个变量可以有效地节省搜索的时间,因为只有两个具有相同正负号的特征点才有可能匹配,对于正负号不同的特征点就不进行相似性计算。
简单地说,我们可以根据特征点的响应值符号,将特征点分成两组,一组是具有拉普拉斯正响应的特征点,一组是具有拉普拉斯负响应的特征点,匹配时,只有符号相同组中的特征点才能进行相互匹配。显然,这样可以节省特征点匹配的时间。如下图5所示。

图5 黑背景下的亮斑和白背景下的黑斑 因为它们的拉普拉斯响应正负号不同,不会对它们进行匹配
4. 源码解析
特征点描述子的生成这一部分的代码主要是通过SURFInvoker这个类来实现。在主流程中,通过一个parallel_for_()函数来并发计算。
struct SURFInvoker
{
enum{ORI_RADIUS = , ORI_WIN = , PATCH_SZ = };
// Parameters
const Mat* img;
const Mat* sum;
vector<KeyPoint>* keypoints;
Mat* descriptors;
bool extended;
bool upright; // Pre-calculated values
int nOriSamples;
vector<Point> apt; // 特征点周围用于描述方向的邻域的点
vector<float> aptw; // 描述 方向时的 高斯 权
vector<float> DW; SURFInvoker(const Mat& _img, const Mat& _sum,
vector<KeyPoint>& _keypoints, Mat& _descriptors,
bool _extended, bool _upright)
{
keypoints = &_keypoints;
descriptors = &_descriptors;
img = &_img;
sum = &_sum;
extended = _extended;
upright = _upright; // 用于描述特征点的 方向的 邻域大小: 12*sigma+1 (sigma =1.2) 因为高斯加权的核的参数为2sigma
// nOriSampleBound为 矩形框内点的个数
const int nOriSampleBound = ( * ORI_RADIUS + )*( * ORI_RADIUS + ); // 这里把s近似为1 ORI_DADIUS = 6s // 分配大小
apt.resize(nOriSampleBound);
aptw.resize(nOriSampleBound);
DW.resize(PATCH_SZ*PATCH_SZ); // PATHC_SZ为特征描述子的 区域大小 20s(s 这里初始为1了) /* 计算特征点方向用的 高斯分布 权值与坐标 */
Mat G_ori = getGaussianKernel( * ORI_RADIUS + , SURF_ORI_SIGMA, CV_32F); // SURF_ORI_SIGMA = 1.2 *2 =2.5
nOriSamples = ;
for (int i = -ORI_RADIUS; i <= ORI_RADIUS; i++)
{
for (int j = -ORI_RADIUS; j <= ORI_RADIUS; j++)
{
if (i*i + j*j <= ORI_RADIUS*ORI_RADIUS) // 限制在圆形区域内
{
apt[nOriSamples] = cvPoint(i, j);
// 下面这里有个坐标转换,因为i,j都是从-ORI_RADIUS开始的。
aptw[nOriSamples++] = G_ori.at<float>(i + ORI_RADIUS, ) * G_ori.at<float>(j + ORI_RADIUS, );
}
}
}
CV_Assert(nOriSamples <= nOriSampleBound); // nOriSamples为圆形区域内的点,nOriSampleBound是正方形区域的点 /* 用于特征点描述子的高斯 权值 */
Mat G_desc = getGaussianKernel(PATCH_SZ, SURF_DESC_SIGMA, CV_32F); // 用于生成特征描述子的 高斯加权 sigma = 3.3s (s初取1)
for (int i = ; i < PATCH_SZ; i++)
{
for (int j = ; j < PATCH_SZ; j++)
DW[i*PATCH_SZ + j] = G_desc.at<float>(i, ) * G_desc.at<float>(j, );
} /* x与y方向上的 Harr小波,参数为4s */
const int NX = , NY = ;
const int dx_s[NX][] = { { , , , , - }, { , , , , } };
const int dy_s[NY][] = { { , , , , }, { , , , , - } }; float X[nOriSampleBound], Y[nOriSampleBound], angle[nOriSampleBound]; // 用于计算特生点主方向
uchar PATCH[PATCH_SZ + ][PATCH_SZ + ];
float DX[PATCH_SZ][PATCH_SZ], DY[PATCH_SZ][PATCH_SZ]; // 20s * 20s区域的 梯度值
CvMat matX = cvMat(, nOriSampleBound, CV_32F, X);
CvMat matY = cvMat(, nOriSampleBound, CV_32F, Y);
CvMat _angle = cvMat(, nOriSampleBound, CV_32F, angle);
Mat _patch(PATCH_SZ + , PATCH_SZ + , CV_8U, PATCH); int dsize = extended ? : ; int k, k1 = , k2 = (int)(*keypoints).size();// k2为Harr小波的 模板尺寸
float maxSize = ;
for (k = k1; k < k2; k++)
{
maxSize = std::max(maxSize, (*keypoints)[k].size);
}
// maxSize*1.2/9 表示最大的尺度 s
int imaxSize = std::max(cvCeil((PATCH_SZ + )*maxSize*1.2f / 9.0f), );
Ptr<CvMat> winbuf = cvCreateMat(, imaxSize*imaxSize, CV_8U);
for (k = k1; k < k2; k++)
{
int i, j, kk, nangle;
float* vec;
SurfHF dx_t[NX], dy_t[NY];
KeyPoint& kp = (*keypoints)[k];
float size = kp.size;
Point2f center = kp.pt;
/* s是当前层的尺度参数 1.2是第一层的参数,9是第一层的模板大小*/
float s = size*1.2f / 9.0f;
/* grad_wav_size是 harr梯度模板的大小 边长为 4s */
int grad_wav_size = * cvRound( * s);
if (sum->rows < grad_wav_size || sum->cols < grad_wav_size)
{
/* when grad_wav_size is too big,
* the sampling of gradient will be meaningless
* mark keypoint for deletion. */
kp.size = -;
continue;
} float descriptor_dir = .f - .f;
if (upright == )
{
// 这一步 是计算梯度值,先将harr模板放大,再根据积分图计算,与前面求D_x,D_y一致类似
resizeHaarPattern(dx_s, dx_t, NX, , grad_wav_size, sum->cols);
resizeHaarPattern(dy_s, dy_t, NY, , grad_wav_size, sum->cols);
for (kk = , nangle = ; kk < nOriSamples; kk++)
{
int x = cvRound(center.x + apt[kk].x*s - (float)(grad_wav_size - ) / );
int y = cvRound(center.y + apt[kk].y*s - (float)(grad_wav_size - ) / );
if (y < || y >= sum->rows - grad_wav_size ||
x < || x >= sum->cols - grad_wav_size)
continue;
const int* ptr = &sum->at<int>(y, x);
float vx = calcHaarPattern(ptr, dx_t, );
float vy = calcHaarPattern(ptr, dy_t, );
X[nangle] = vx*aptw[kk];
Y[nangle] = vy*aptw[kk];
nangle++;
}
if (nangle == )
{
// No gradient could be sampled because the keypoint is too
// near too one or more of the sides of the image. As we
// therefore cannot find a dominant direction, we skip this
// keypoint and mark it for later deletion from the sequence.
kp.size = -;
continue;
}
matX.cols = matY.cols = _angle.cols = nangle;
// 计算邻域内每个点的 梯度角度
cvCartToPolar(&matX, &matY, , &_angle, ); float bestx = , besty = , descriptor_mod = ;
for (i = ; i < ; i += SURF_ORI_SEARCH_INC) // SURF_ORI_SEARCH_INC 为扇形区域扫描的步长
{
float sumx = , sumy = , temp_mod;
for (j = ; j < nangle; j++)
{
// d是 分析到的那个点与 现在主方向的偏度
int d = std::abs(cvRound(angle[j]) - i);
if (d < ORI_WIN / || d > - ORI_WIN / )
{
sumx += X[j];
sumy += Y[j];
}
}
temp_mod = sumx*sumx + sumy*sumy;
// descriptor_mod 是最大峰值
if (temp_mod > descriptor_mod)
{
descriptor_mod = temp_mod;
bestx = sumx;
besty = sumy;
}
}
descriptor_dir = fastAtan2(-besty, bestx);
}
kp.angle = descriptor_dir;
if (!descriptors || !descriptors->data)
continue; /* 用特征点周围20*s为边长的邻域 计算特征描述子 */
int win_size = (int)((PATCH_SZ + )*s);
CV_Assert(winbuf->cols >= win_size*win_size);
Mat win(win_size, win_size, CV_8U, winbuf->data.ptr); if (!upright)
{
descriptor_dir *= (float)(CV_PI / ); // 特征点的主方向 弧度值
float sin_dir = -std::sin(descriptor_dir); // - sin dir
float cos_dir = std::cos(descriptor_dir); float win_offset = -(float)(win_size - ) / ;
float start_x = center.x + win_offset*cos_dir + win_offset*sin_dir;
float start_y = center.y - win_offset*sin_dir + win_offset*cos_dir;
uchar* WIN = win.data; int ncols1 = img->cols - , nrows1 = img->rows - ;
size_t imgstep = img->step;
for (i = ; i < win_size; i++, start_x += sin_dir, start_y += cos_dir)
{
double pixel_x = start_x;
double pixel_y = start_y;
for (j = ; j < win_size; j++, pixel_x += cos_dir, pixel_y -= sin_dir)
{
int ix = cvFloor(pixel_x), iy = cvFloor(pixel_y);
if ((unsigned)ix < (unsigned)ncols1 &&
(unsigned)iy < (unsigned)nrows1)
{
float a = (float)(pixel_x - ix), b = (float)(pixel_y - iy);
const uchar* imgptr = &img->at<uchar>(iy, ix);
WIN[i*win_size + j] = (uchar)
cvRound(imgptr[] * (.f - a)*(.f - b) +
imgptr[] * a*(.f - b) +
imgptr[imgstep] * (.f - a)*b +
imgptr[imgstep + ] * a*b);
}
else
{
int x = std::min(std::max(cvRound(pixel_x), ), ncols1);
int y = std::min(std::max(cvRound(pixel_y), ), nrows1);
WIN[i*win_size + j] = img->at<uchar>(y, x);
}
}
}
}
else
{ float win_offset = -(float)(win_size - ) / ;
int start_x = cvRound(center.x + win_offset);
int start_y = cvRound(center.y - win_offset);
uchar* WIN = win.data;
for (i = ; i < win_size; i++, start_x++)
{
int pixel_x = start_x;
int pixel_y = start_y;
for (j = ; j < win_size; j++, pixel_y--)
{
int x = MAX(pixel_x, );
int y = MAX(pixel_y, );
x = MIN(x, img->cols - );
y = MIN(y, img->rows - );
WIN[i*win_size + j] = img->at<uchar>(y, x);
}
}
}
// Scale the window to size PATCH_SZ so each pixel's size is s. This
// makes calculating the gradients with wavelets of size 2s easy
resize(win, _patch, _patch.size(), , , INTER_AREA); // Calculate gradients in x and y with wavelets of size 2s
for (i = ; i < PATCH_SZ; i++)
for (j = ; j < PATCH_SZ; j++)
{
float dw = DW[i*PATCH_SZ + j]; // 高斯加权系数
float vx = (PATCH[i][j + ] - PATCH[i][j] + PATCH[i + ][j + ] - PATCH[i + ][j])*dw;
float vy = (PATCH[i + ][j] - PATCH[i][j] + PATCH[i + ][j + ] - PATCH[i][j + ])*dw;
DX[i][j] = vx;
DY[i][j] = vy;
} // Construct the descriptor
vec = descriptors->ptr<float>(k);
for (kk = ; kk < dsize; kk++)
vec[kk] = ;
double square_mag = ;
if (extended)
{
// 128维描述子,考虑dx与dy的正负号
for (i = ; i < ; i++)
for (j = ; j < ; j++)
{
// 每个方块内是一个5s * 5s的区域,每个方法由8个特征描述
for (int y = i * ; y < i * + ; y++)
{
for (int x = j * ; x < j * + ; x++)
{
float tx = DX[y][x], ty = DY[y][x];
if (ty >= )
{
vec[] += tx;
vec[] += (float)fabs(tx);
}
else {
vec[] += tx;
vec[] += (float)fabs(tx);
}
if (tx >= )
{
vec[] += ty;
vec[] += (float)fabs(ty);
}
else {
vec[] += ty;
vec[] += (float)fabs(ty);
}
}
}
for (kk = ; kk < ; kk++)
square_mag += vec[kk] * vec[kk];
vec += ;
}
}
else
{
// 64位描述子
for (i = ; i < ; i++)
for (j = ; j < ; j++)
{
for (int y = i * ; y < i * + ; y++)
{
for (int x = j * ; x < j * + ; x++)
{
float tx = DX[y][x], ty = DY[y][x];
vec[] += tx; vec[] += ty;
vec[] += (float)fabs(tx); vec[] += (float)fabs(ty);
}
}
for (kk = ; kk < ; kk++)
square_mag += vec[kk] * vec[kk];
vec += ;
}
}
// 归一化 描述子 以满足 光照不变性
vec = descriptors->ptr<float>(k);
float scale = (float)(. / (sqrt(square_mag) + DBL_EPSILON));
for (kk = ; kk < dsize; kk++)
vec[kk] *= scale;
}
}
};
5. 总结
实际上有文献指出,SURF比SIFT工作更出色。他们认为主要是因为SURF在求取描述子特征矢量时,是对一个子块的梯度信息进行求和,而SIFT则是依靠单个像素梯度的方向。
SURF算法与源码分析、下的更多相关文章
- SURF算法与源码分析、上
如果说SIFT算法中使用DOG对LOG进行了简化,提高了搜索特征点的速度,那么SURF算法则是对DoH的简化与近似.虽然SIFT算法已经被认为是最有效的,也是最常用的特征点提取的算法,但如果不借助于硬 ...
- 知识小罐头07(tomcat8请求源码分析 下)
感觉最近想偷懒了,哎,强迫自己也要写点东西,偷懒可是会上瘾的,嘿嘿!一有写博客的想法要赶紧行动起来,养成良好的习惯. ok,继续上一篇所说的一些东西,上一篇说到Connector包装了那两个对象,最后 ...
- 知识小罐头09(tomcat8启动源码分析 下)
初始化已经完成,现在就是启动这些组件,Tomcat中的start方法就是用于启动的,其实start的原理还是和上一篇说的初始化几乎一样!这里我就大概说一下,看几个比较关键的地方就行了. 前面的步骤就大 ...
- memcached学习笔记——存储命令源码分析上篇
原创文章,转载请标明,谢谢. 上一篇分析过memcached的连接模型,了解memcached是如何高效处理客户端连接,这一篇分析memcached源码中的process_update_command ...
- Fabric2.2中的Raft共识模块源码分析
引言 Hyperledger Fabric是当前比较流行的一种联盟链系统,它隶属于Linux基金会在2015年创建的超级账本项目且是这个项目最重要的一个子项目.目前,与Hyperledger的另外几个 ...
- SparkMLlib之 logistic regression源码分析
最近在研究机器学习,使用的工具是spark,本文是针对spar最新的源码Spark1.6.0的MLlib中的logistic regression, linear regression进行源码分析,其 ...
- 内核通信之Netlink源码分析-用户内核通信原理
2017-07-05 本节从一个小案例入手,结合源码分析下通过netlink进行内核和用户通信的流程. 内核端 按照传统CS模式,其实内核端可以作为是服务器端,用以接收用户的请求并作出处理,但是从ne ...
- illuminate/routing 源码分析之注册路由
我们知道,在 Laravel 世界里,外界传进来一个 Request 时,会被 Kernel 处理并返回给外界一个 Response.Kernel 在处理 Request 时,会调用 illumina ...
- commons-logging + log4j源码分析
分析之前先理清楚几个概念 Log4J = Log For Java SLF4J = Simple Logging Facade for Java 看到Facade首先想到的就是设计模式中的门面(Fac ...
随机推荐
- C#中Delegate和Event以及它们的区别(转载)
一.Delegate委托可以理解为一个方法签名. 可以将方法作为另外一个方法的参数带入其中进行运算.在C#中我们有三种方式去创建委托,分别如下: public delegate void Print( ...
- 模板插件aTpl
摘要: 前面给大家分享了一款js模板插件,后来经过完善推荐给大家.该插件支持ie5+,chrome等浏览器以及移动端浏览器,支持for和if语法,以及表达式. 项目地址:https://github. ...
- tomcat服务器配置及使用
序:tomcat作为免费开源的web服务器,广受大家喜欢,但是该如何使用此服务器呢?下面就一步一步教大家操作tomcat服务器 一.权限配置 编辑tomcat-users.xml文件配置tomcat服 ...
- Ubuntu下编译SuiteSparse-4.4.1和METIS-4.0.3
网上关于编译的介绍非常多,其实ubuntu系统自带编译好的SuiteSparse,不想折腾的话,用新立得很容易就搞定 准备工作: 下载并编译OpenBLAS(会连带Lapack也下载和编译),图省事请 ...
- cocos进阶教程(2)多分辨率支持策略和原理
cocos2d-x3.0API常用接口 Director::getInstance()->getOpenGLView()->setDesignResolutionSize() //设计分辨 ...
- CoreLoation
- (CLLocationManager *)locationManager { if (!_locationManager) { _locationManager = [[CLLocationMan ...
- apache2:Invalid option to WSGI daemon process definition
版本说明: ubuntu 12.04 server /apache 2.2 / mod_wsgi 3.3 / python 2.7.3 /django 1.7 在ubuntu12的服务器上配置djan ...
- 什么是响应式Web设计?怎样进行?
http://beforweb.com/node/6/page/0/3 开始第一篇.老规矩,先无聊的谈论天气一类的话题.十一长假,天气也终于开始有些秋天的味道,坐在屋里甚至觉得需要热咖啡.话说两年前也 ...
- 使用MegaCli和Smartctl获取普通磁盘
设备名称: [root@DB232 shell]# cat /proc/scsi/scsi Attached devices:Host: scsi0 Channel: 02 Id: 00 Lun: 0 ...
- static-const 类成员变量
[本文链接] http://www.cnblogs.com/hellogiser/p/static-const.html [分析] const数据成员必须在构造函数初始化列表中初始化; static数 ...