unordered_map(hash_map)和map的比较
测试代码:
#include <iostream>
using namespace std;
#include <string>
#include <windows.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <map>
const int maxval = 2000000 * 5;
#include <unordered_map>
void map_test()
{
printf("map_test\n");
map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval]++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand()%maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
void hash_map_test()
{
printf("hash_map_test\n");
unordered_map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval] ++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand() % maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
int main(int argc, char *argv[])
{
srand(0);
map_test();
Sleep(1000);
srand(0);
hash_map_test();
system("pause");
return 0;
}
详解:
map(使用红黑树)与unordered_map(hash_map)比较
map理论插入、查询时间复杂度O(logn)
unordered_map理论插入、查询时间复杂度O(1)
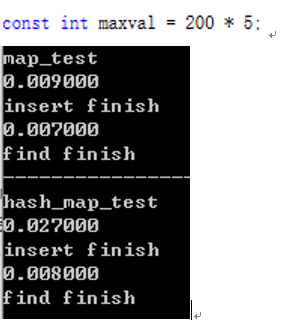
数据量较小时,可能是由于unordered_map(hash_map)初始大小较小,大小频繁到达阈值,多次重建导致插入所用时间稍大。(类似vector的重建过程)。
哈希函数也是有消耗的(应该是常数时间),这时候用于哈希的消耗大于对红黑树查找的消耗(O(logn)),所以unordered_map的查找时间会多余对map的查找时间。
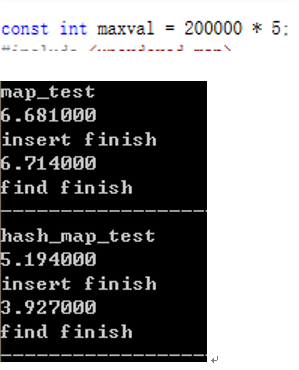
数据量较大时,重建次数减少,用于重建的开销小,unordered_map O(1)的优势开始显现
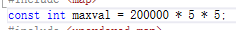
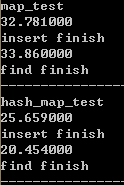
数据量更大,优势更明显
使用空间:


前半部分为map,后半部分为unordered_map
unordered_map占用的空间比map略多,但可以接受。
map和unordered_map内部实现应该都是采用达到阈值翻倍开辟空间的机制(16、32、64、128、256、512、1024……)浪费一定的空间是不可避免的。并且在开双倍空间时,若不能从当前开辟,会在其他位置开辟,开好后将数据移过去。数据的频繁移动也会消耗一定的时间,在数据量较小时尤为明显。
一种方法是手写定长开散列。这样做在数据量较小时有很好地效果(避免了数据频繁移动,真正趋近O(1))。但由于是定长的,在数据量较大时,数据重叠严重,散列效果急剧下降,时间复杂度趋近O(n)。
一种折中的方法是自己手写unordered_map(hash_map),将初始大小赋为一个较大的值。扩张可以模仿STL的双倍扩张,也可以自己采用其他方法。这样写出来的是最优的,但是实现起来极为麻烦。
综合利弊,我们组采用unordered_map。
附:使用Dev测试与VS2017测试效果相差极大???
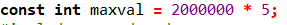
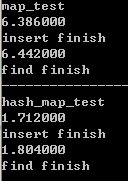
效率差了10倍???
原因:
Dev

VS2017

在Debug下,要记录断点等调试信息,的确慢。
Release:不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。
VS2017切到release后,还更快

除了前面说的Debug与release导致效率差异外,编译器的不同也会导致效率差异。
学到了。
unordered_map(hash_map)和map的比较的更多相关文章
- hash_map和map的区别
hash_map和map的区别 分类: STL2008-10-15 21:24 5444人阅读 评论(0) 收藏 举报 class数据结构编译器存储平台tree 这里列几个常见问题,应该对你理解和使用 ...
- C++中的hash_map和map的区别
hash_map和map的区别在哪里?构造函数.hash_map需要hash函数,等于函数:map只需要比较函数(小于函数). 存储结构.hash_map采用hash表存储,map一般采用红黑树(RB ...
- boost::unordered_map 和 std::map 的效率 与 内存比较
例子链接:http://blog.csdn.net/gamecreating/article/details/7698719 结论: unordered_map 查找效率快五倍,插入更快,节省一定内存 ...
- std::unordered_map与std::map
前者查找更快.后者自动排序,并可指定排序方式. 资料参考: https://blog.csdn.net/photon222/article/details/102947597
- 福大软工1816 · 第五次作业 - 结对作业2_map与unordered map的比较测试
测试代码: #include <iostream> using namespace std; #include <string> #include <windows.h& ...
- STL中的map、unordered_map、hash_map
转自https://blog.csdn.net/liumou111/article/details/49252645 在之前使用STL时,经常混淆的几个数据结构,特别是做Leetcode的题目时,对于 ...
- map、hash_map、unordered_map 的思考
#include <map> map<string,int> dict; map是基于红黑树实现的,可以快速查找一个元素是否存在,是关系型容器,能够表达两个数据之间的映射关系. ...
- map vs hash_map
1. map, multimap, set, multiset g++ 中 map, multimap, set, multiset 由红黑树实现 map: bits/stl_map.h multim ...
- c++ map unordered_map
map operator<的重载一定要定义成const.因为map内部实现时调用operator<的函数好像是const. #include<string> #include& ...
随机推荐
- vi模式下的编辑、删除、保存和退出
vi + 文件名:进入 vi 模式 编辑模式:shift+: 退出编辑模式:Esc 退出编辑模式后可进行光标的上下左右移动(偶尔会出现ABCD,还不知道怎么解决,目前只能出来一个删除一个) 光标处:按 ...
- php比较两个数组的差异array_diff()函数
下面简单介绍php比较两个数组的差异array_diff()函数. 原文地址:小时刻个人技术博客 > http://small.aiweimeng.top/index.php/archives/ ...
- freeswitch对话机320信令在专有网络情况下不生效的处理
昨天处理客户提出的话机设置呼叫转移不生效的问题, 经过多次测试发现这个问题与freeswitch版本和配置没有关系, 后来分析freeswitch正常转移日志与不转移日志发现不转移的日志少了一行 Re ...
- MapReduce之Reduce Join
一 介绍 Reduce Join其主要思想如下: 在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag), 比如:t ...
- 爬虫-爬虫介绍及Scrapy简介
在编写案例之前首先理解几个问题,1:什么是爬虫2:为什么说python是门友好的爬虫语言?3:选用哪种框架编写爬虫程序 一:什么是爬虫? 爬虫 webSpider 也称之为网络蜘蛛,是使用一段编写好的 ...
- wordpress网站程序漏洞修复办法
近日wordpress被爆出高危的网站漏洞,该漏洞可以伪造代码进行远程代码执行,获取管理员的session以及获取cookies值,漏洞的产生是在于wordpress默认开启的文章评论功能,该功能在对 ...
- C程序设计语言笔记-第一章
The C Programming language notes 一 基础变量类型.运算符和判断循环 char 字符型 character ...
- 解决WinScp连接被拒绝的问题
尝试以下方法: 1) 开启|关闭防火墙(这里需要关闭) sudo ufw enable|disable 2) 开启远程服务 在终端界面输入:service sshd start.结果显示:ssh:un ...
- 【8086汇编-Day7】关于多个段的程序的实验
实验一 实验二 实验三 实验四 实验五 实验六 总结 在集成环境下,内存从0770段开始按照段的先后顺序和内容多少分配,并且分配的都是16的倍数 关于实际占用的空间公式的话其实极容易想到(假设有N个字 ...
- 无偏方差为什么除以n-1
设样本均值为,样本方差为,总体均值为,总体方差为,那么样本方差有如下公式:. 很多人可能都会有疑问,为什么要除以n-1,而不是n,但是翻阅资料,发现很多都是交代到,如果除以n,对样本方差的估计不是无偏 ...