【转】B树、B-树、B+树、B*树、红黑树、 二叉排序树、trie树Double Array 字典查找树简介
B 树 即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如: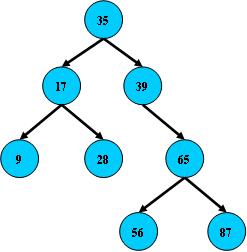
B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
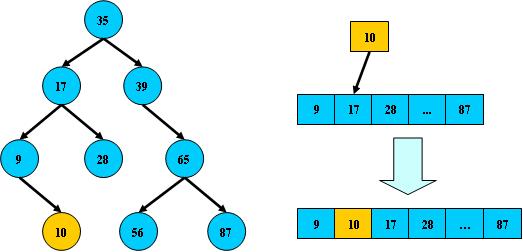
但B树在经过多次插入与删除后,有可能导致不同的结构:
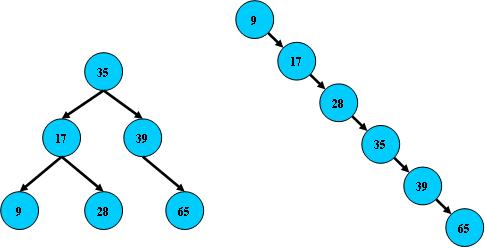
右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的策略;
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] <K[i+1];
7.非叶子结点的指针:P[1], P[2], …,P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1],K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
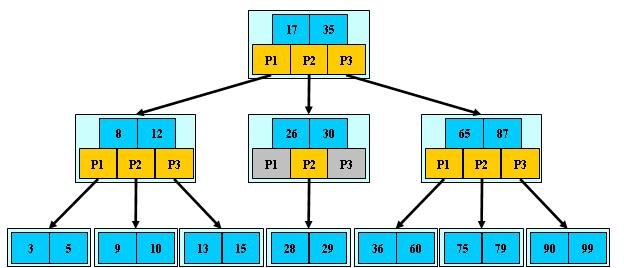
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
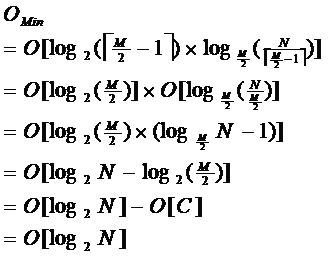
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
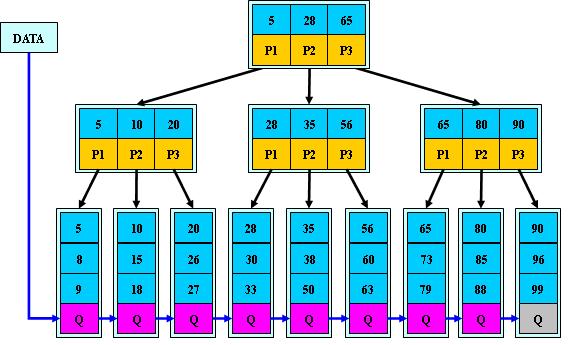
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
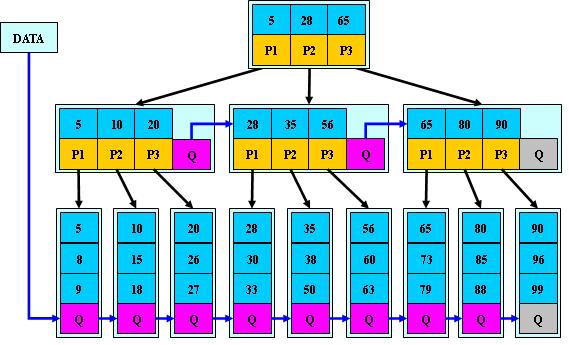
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
红黑树rbtree二叉排序树
map 就是采用红黑树存储的,红黑树(RBTree)是平衡二叉树,其优点就是树到叶子节点深度一致,查找的效率也就一样,为logN.在实行查找,插入,删除的效率都一致,而当是全部静态数据时,没有太多优势,可能采用hash表各合适。
hash_map是一个hashtable占用内存更多,查找效率高一些,但是hash的时间比较费时。
总体来说,hash_map查找速度会比map快,而且查找速度基本和数据数据量大小,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n)小,hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑hash_map。但若你对内存使用特别严格,希望程序尽可能少消耗内存,那么一定要小心,hash_map可能会让你陷入尴尬,特别是当你的hash_map对象特别多时,你就更无法控制了,而且hash_map的构造速度较慢。
现在知道如何选择了吗?权衡三个因素: 查找速度, 数据量,内存使用。
trie树Double Array字典查找树
每个节点相当于DFA的一个状态,终止状态为查找结束。有序查找的过程相当于状态的不断转换
对于给定的一个字符串a1,a2,a3,...,an.则
下面我们有and,as,at,cn,com这些关键词,那么如何构建trie树呢?

从上面的图中,我们或多或少的可以发现一些好玩的特性。
第一:根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
第二:从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
第三:每个单词的公共前缀作为一个字符节点保存。
使用范围:
既然学Trie树,我们肯定要知道这玩意是用来干嘛的。
第一:词频统计。
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么
玩吗?所以这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
第二: 前缀匹配
就拿上面的图来说吧,如果我想获取所有以"a"开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,
你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,
可以说这是秒杀的效果。
举个例子:现有一个编号为1的字符串”and“,我们要插入到trie树中,采用动态规划的思想,将编号”1“计入到每个途径的节点中,
那么以后我们要找”a“,”an“,”and"为前缀的字符串的编号将会轻而易举。
【转】B树、B-树、B+树、B*树、红黑树、 二叉排序树、trie树Double Array 字典查找树简介的更多相关文章
- 大名鼎鼎的红黑树,你get了么?2-3树 绝对平衡 右旋转 左旋转 颜色反转
前言 11.1新的一月加油!这个购物狂欢的季节,一看,已囊中羞涩!赶紧来恶补一下红黑树和2-3树吧!红黑树真的算是大名鼎鼎了吧?即使你不了解它,但一定听过吧?下面跟随我来揭开神秘的面纱吧! 一.2-3 ...
- 为什么Mysql用B+树做索引而不用B-树或红黑树
B+树做索引而不用B-树 那么Mysql如何衡量查询效率呢?– 磁盘IO次数. 一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上. ...
- 浅谈算法和数据结构: 七 二叉查找树 八 平衡查找树之2-3树 九 平衡查找树之红黑树 十 平衡查找树之B树
http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html 前文介绍了符号表的两种实现,无序链表和有序数组,无序链表在插入的 ...
- 论AVL树与红黑树
首先讲解一下AVL树: 例如,我们要输入这样一串数字,10,9,8,7,15,20这样一串数字来建立AVL树 1,首先输入10,得到一个根结点10 2,然后输入9, 得到10这个根结点一个左孩子结点9 ...
- 单例模式,堆,BST,AVL树,红黑树
单例模式 第一种(懒汉,线程不安全): public class Singleton { private static Singleton instance; private Singleton () ...
- 对B+树,B树,红黑树的理解
出处:https://www.jianshu.com/p/86a1fd2d7406 写在前面,好像不同的教材对b树,b-树的定义不一样.我就不纠结这个到底是叫b-树还是b-树了. 如图所示,区别有以下 ...
- B树,B+树,红黑树应用场景AVL树,红黑树,B树,B+树,Trie树
B B+运用在file system database这类持续存储结构,同样能保持lon(n)的插入与查询,也需要额外的平衡调节.像mysql的数据库定义是可以指定B+ 索引还是hash索引. C++ ...
- 二叉树,B树,B+树,红黑树 简介
什么是二叉树? 在计算机科学中,二叉树是每个节点最多有两个子树的树结构.通常子树被称作“左子树”和“右子树”,左子树和右子树同时也是二叉树.二叉树的子树有左右之分,并且次序不能任意颠倒.二叉树是递归定 ...
- 二叉搜索树、AVL平衡二叉搜索树、红黑树、多路查找树
1.二叉搜索树 1.1定义 是一棵二叉树,每个节点一定大于等于其左子树中每一个节点,小于等于其右子树每一个节点 1.2插入节点 从根节点开始向下找到合适的位置插入成为叶子结点即可:在向下遍历时,如果要 ...
随机推荐
- Git远程库
要关联一个远程主机,使用命令 git remote add origin <url> : 删除远程主机,使用命令 git remote rm origin ; git push 的一般形式 ...
- App功能测试的注意点
好几个月没有写博客记录学习心得了,这次回老家深夜闲来无事写一篇记录下这段时间的面试心得,这次面试过程很多面试官都问APP的有关测试,下面我就自己的认识和工作中的经验来谈谈自己对APP测试的认识: 1. ...
- codeforces1137B kmp(fail的妙用)
题目传送门 题意:给出$s$和$t$两个串,让你构造出一个答案串,使得答案串中的01数量和s一样,并且使$t$在答案串中作为子串出现次数最多. 思路: 要想出现的次数尽可能多,那么就要重复的利用,哪一 ...
- BASIC CONCEPTS ABOUT 4G
http://en.wikipedia.org/ 原版的维基,远比我认识的强大 http://www.3gpp.org/ http://www.ietf.org/ http://www.wiresha ...
- UVALive - 6436、HYSBZ - 2435 (dfs)
这两道题都是用简单dfs解的,主要是熟悉回溯过程就能做,据说用bfs也能做 道路修建(HYSBZ - 2435) 在 W 星球上有n 个国家.为了各自国家的经济发展,他们决定在各个国家 之间建设双向道 ...
- 文献综述十四:基于Oracle11g的超市进销存管理系统设计与实现
一.基本信息 标题:基于Oracle11g的超市进销存管理系统设计与实现 时间:2016 出版源:技术创新 文件分类:对数据库的研究 二.研究背景 为超市设计开发的超市管理系统,采用的是 VC+ Or ...
- js函数声明提升与变量提升
变量提升 变量提升: 在指定作用域里,从代码顺序上看是变量先使用后声明,但运行时变量的 “可访问性” 提升到当前作用域的顶部,其值为 undefined ,没有 “可用性”. alert(a); // ...
- ubuntu中ANT的安装和配置
一. 自动安装可以使用sudo apt-get install ant安装,但是这种装法不好.首先安装的ant不是最新的版本,其次还要装一堆其他的附带的东西.所以我才用自己手动ant安装. 二. 手动 ...
- Bash编程(6) String操作
1. 拼接 1) 简单的字符串拼接如:PATH=$PATH:$HOME/bin.如果拼接的字符串包含空格或特殊字符,需要使用双引号括起,如: var=$HOME/bin # 注释并不是赋值的一部分 v ...
- python3根据地址批量获取百度地图经纬度
python3代码如下: import requests import time def get_mercator(addr): url= 'http://api.map.baidu.com/geoc ...