五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门

我的搜素简单实现原理
我们可以用js来实现,首先用js获取到输入的搜索词
设置一个数组里存放搜素词,
判断搜索词在数组里是否存在如果存在删除原来的词,重新将新词放在数组最前面
如果不存在直接将新词放在数组最前面即可,然后循环数组显示结果即可
热门搜索
实现原理,当用户搜索一个词时,可以保存到数据库,然后记录搜索次数,
利用redis缓存搜索次数最到的词,过一段时间更新一下缓存
备注:Django结合Scrapy的开源项目可以学习一下
django-dynamic-scraper
https://github.com/holgerd77/django-dynamic-scraper
补充
默认的elasticsearch(搜索引擎)只能搜索1万条数据,在大就会报错了
设置方法
步骤一:
打开项目的索引库地址,将该索引先关闭,否则设置操步骤二无法提交
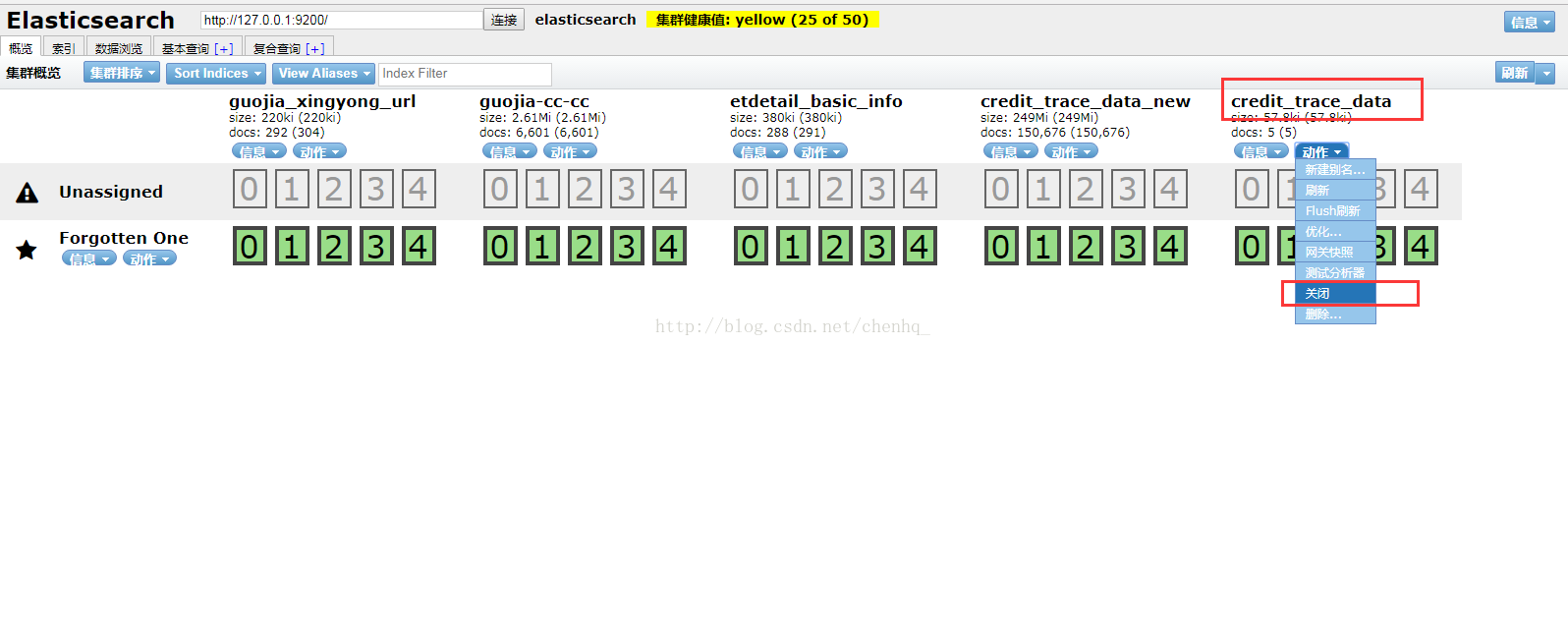
步骤二:
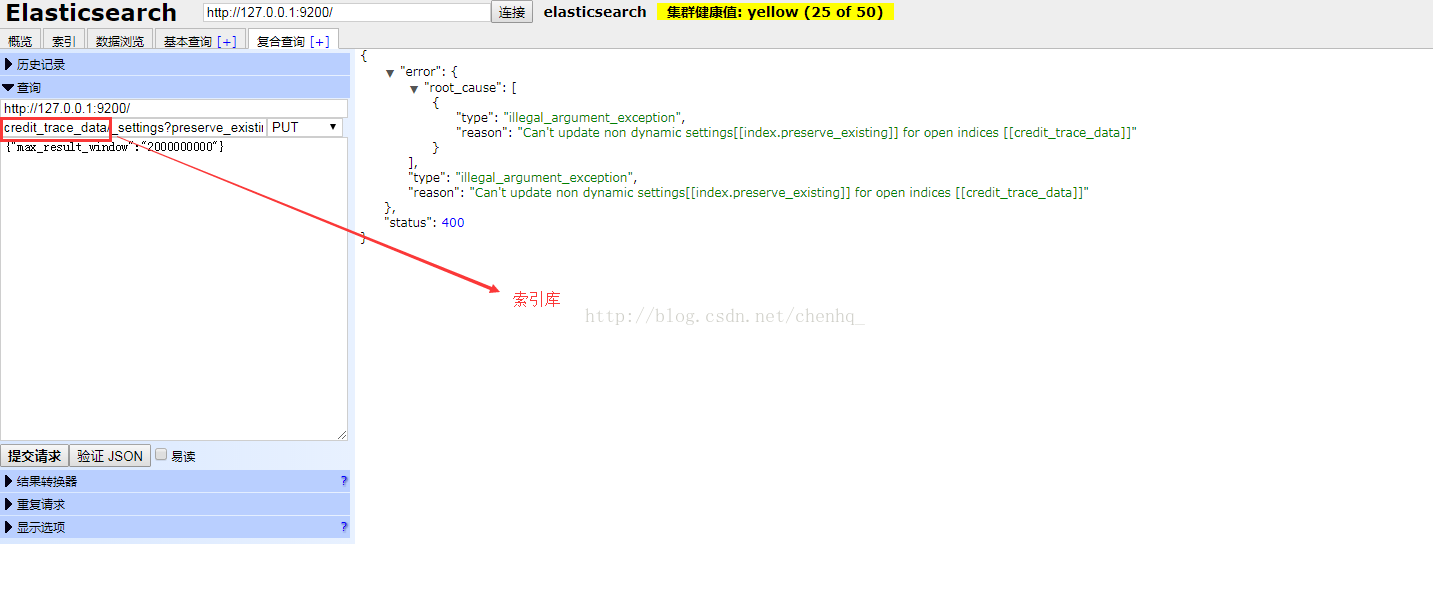
打开复合查询,填入如下信息,记得选择PUT方式提交,credit_trace_data改为本索引库中的索引,max_result_window设为20亿,此值是integer类型,不能无限大
http://127.0.0.1:9200/ PUT
credit_trace_data/_settings?preserve_existing=true
{
"max_result_window" : "2000000000"
}
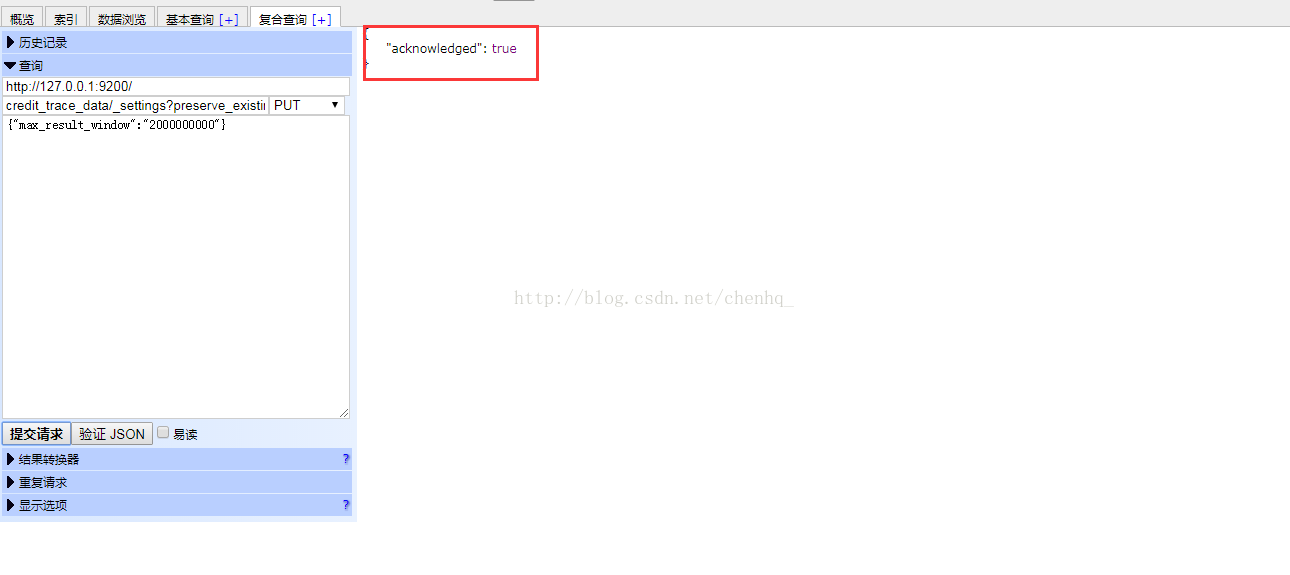
最后点击提交申请,如果配置正确右侧窗口会显示如下信息
如果要查询max_result_window时只需要将PUT改为get即可
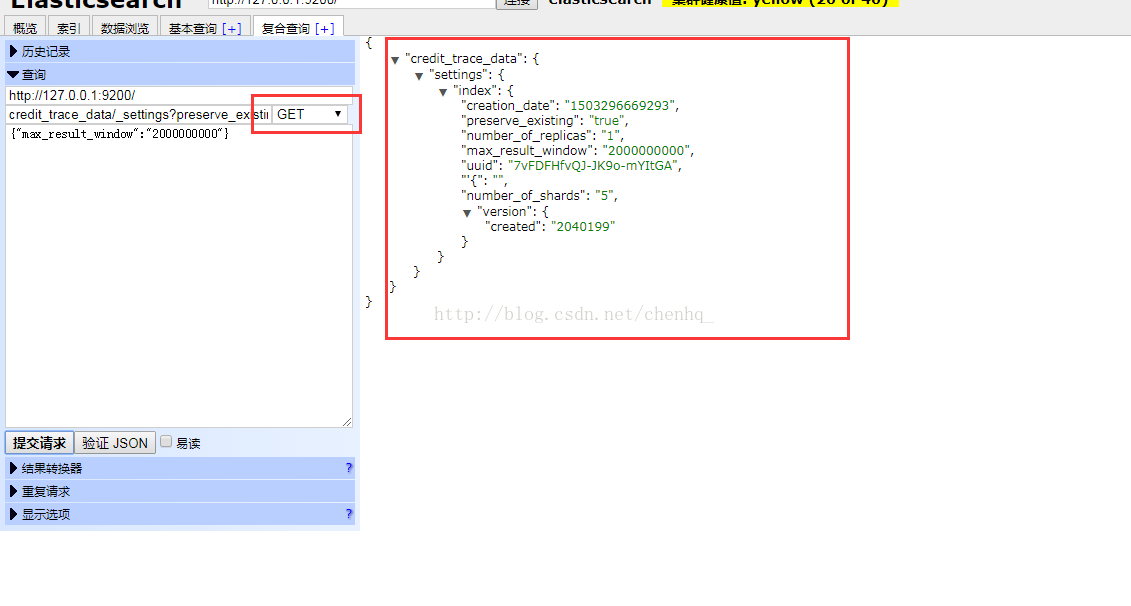
最后记得开启索引!
五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索的更多相关文章
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- 4.Data Types in the mongo Shell-官方文档摘录
总结: 1.MongoDB 的BSON格式支持额外的数据类型 2 Date 对象内部存储64位字节存整数,存储使用NumberLong()这个类来存,使用NumberInt()存32位整数,128位十 ...
- Python获取指定目录下所有子目录、所有文件名
需求 给出制定目录,通过Python获取指定目录下的所有子目录,所有(子目录下)文件名: 实现 import os def file_name(file_dir): for root, dirs, f ...
- django自带过滤器大全
1.可以通过过滤器来修改变量的显示,过滤器的形式是:{{ variable | filter }},管道符号'|'代表使用过滤器 2.过滤器能够采用链式的方式使用,例如:{{ text | escap ...
- 转载一篇pandas和,mysql
http://pandas.pydata.org/pandas-docs/stable/comparison_with_sql.html#compare-with-sql-join http://bl ...
- CNN结构
神经网络 卷积神经网络依旧是层级网络,只是层的功能和形式做了变化,可以说是传统神经网络的一个改进.多了许多传统神经网络没有的层次. 卷积神经网络的层级结构 数据输入层/Input Layer 卷积计算 ...
- 0501-Hystrix保护应用-超时机制、断路器模式简介
一.概述 hystrix对应的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,这与hystrix本身的功能不谋而合,因此Netflix团队将该框架命名为Hystri ...
- n个数里选出m个不重复的数
void change(int *p,int a,int b) { int tmp = *(p + a); *(p + a) = *(p + b); *(p + b) = tmp; } int mai ...
- Linux环境Oracle相关操作命令行
打开Oracle监听:lsnrctl start 关闭监听: lsnrctl stop 监听关闭那么客户端无法连接 进入sqlplus:sqlplus /nolog 使 ...
- 中文Appium API 文档
该文档是Testerhome官方翻译的源地址:https://github.com/appium/appium/tree/master/docs/cn官方网站上的:http://appium.io/s ...
- Django之查询总结
models.Book.objects.filter(**kwargs): querySet [obj1,obj2]models.Book.objects.filter(**kwargs).value ...