为什么我要放弃javaScript数据结构与算法(第八章)—— 树
之前介绍了一些顺序数据结构,介绍的第一个非顺序数据结构是散列表。本章才会学习另一种非顺序数据结构——树,它对于存储需要快速寻找的数据非常有用。
本章内容
- 树的相关术语
- 创建树数据结构
- 树的遍历
- 添加和移除书的节点
- AVL 树
第八章 树
树数据结构
树是一种分层数据的抽象模型。现实生活中最常见的树的典型例子就是家谱,或是公司的组织架构。如下图所示。
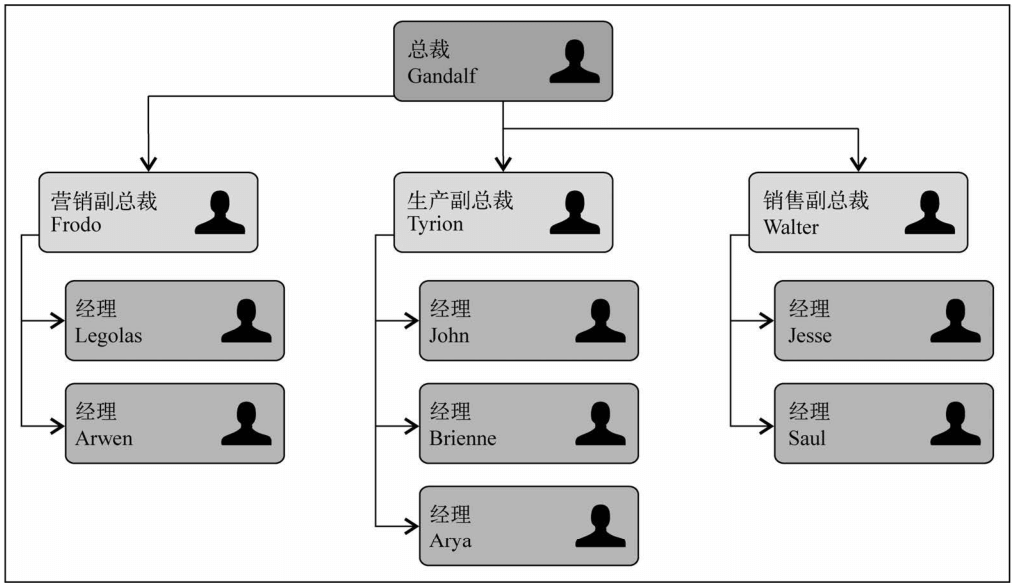
树的相关术语
一个树结构包含一系列存在父子关系的节点。每个节点都有一个父节点(除了顶部的第一个节点)已经零个或者多个子节点:
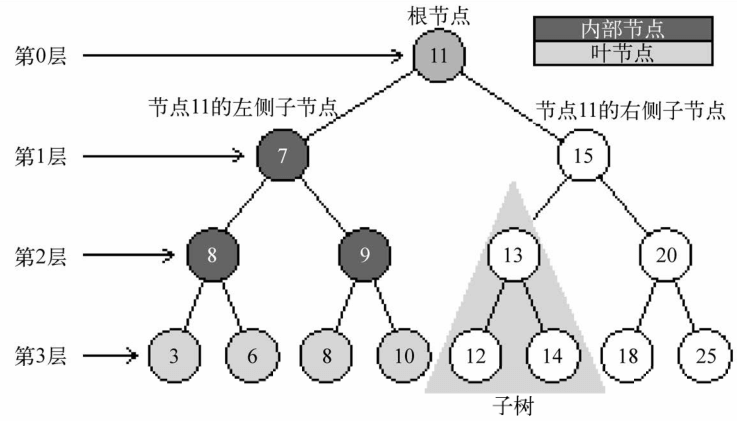
位于树顶部的节点叫做根节点(11)。它没有父节点。树中的每个元素都叫做节点,节点分成内部节点和外部节点。至少有一个子节点的节点称为内部节点(7/5/9/12/13/20是内部节点)。没有子元素的节点被称为外部节点或者是叶节点(3/6/8/10/12/14/18/25 是叶节点)、
一个节点可以有祖先和后代,一个节点(除了根节点)的祖先包括父节点、祖父节点、增祖父节点等。一个节点的后代包括子节点、孙子节点、增孙子节点等。例如,节点5的祖先有节点7和节点11,后代有节点3和节点6.
有关树的另外一个术语是子树。子树由节点和它的后代构成。例如,节点13/12和14 构成了上图中的树的一颗子树。
节点的一个属性是深度,节点的深度取决于它的祖先节点的数量。比如,节点3有三个祖先节点(5/7/11),它的深度为3
树的高度取决于所有节点的深度的最大值。一颗树也可以被分解成层级。根节点在第0层,它的子节点在第1层,以此类推。上图中的树的高度为3
二叉树和二叉搜索树
二叉树的节点最多只能有两个子节点:一个是左侧子节点,另外一个右侧子节点。这些定义有助于我们写出更高效的从树中插入、查找和删除节点的算法。二叉树在计算机科学中的应用非常广泛。
二叉搜索树(BST)是二叉树的一种,但是它只允许你在左侧节点存储(比父节点)小的值,在右侧节点存储(比父节点)大(或者等于)的值。
二叉搜索树将是我们在本章要研究的数据结构。
创建BinarySearchTree 类
首先,声明它的结构:
function BinarySearchTree(){
var Node = function(key){
this.key = key;
this.left = null;
this.right = null;
}
var root = null;
}
下面展现了二叉搜索树结构的组织方式:
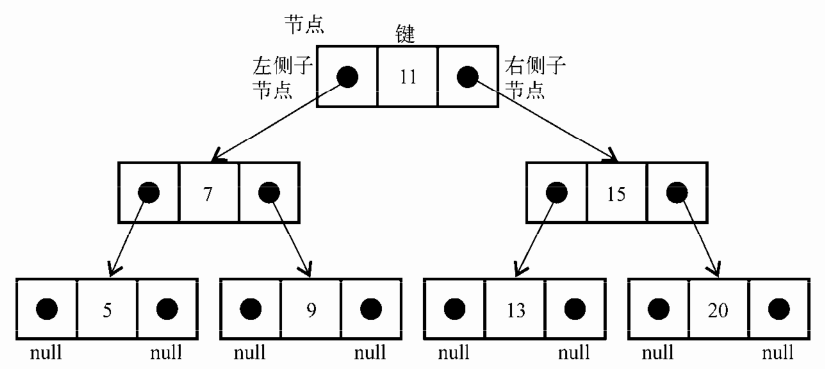
和链表一样,将通过指针来表示节点之间的关系(术语称其为边)。在双向链表中,每个节点包含两个指针,一个指向下一个节点,一个指向上一个节点。对于树,使用同样的方式(也是使用两个指针)。但是,一个指向左侧子节点,另一个指向右侧子节点。因此,将声明一个 Node 类来表示的书的每个节点。不同于前面的章节,我们会将节点本身称为键而不是节点或者是项。键是树相关的术语种对节点的称呼。
我们将会遵循第五章 LinkedList 类相同的模式,这表示也将声明一个变量以控制此数据结构的第一个节点。在树中,它不再是头节点,而是根元素。
下面是将要在树类中实现的方法
- insert(key):向树中插入一个新的键
- search(key):在树中查找一个键,如果节点存在,则返回 true,否则返回 false
- inOrderTraverse:通过中序遍历方式遍历所有节点
- preOrderTraverse:通过先序遍历方式遍历所有节点
- postOrderTraverse:通过后序遍历方式遍历所有节点
- min:返回树中最小的值/键
- max:返回树中最大的值/键
- remove(key):从树中移除某个键
向树中插入一个键
本章要实现的方法会比之前的要复杂很多,要用到递归。
this.insert = function(key){
var newNode = new Node(key);
if(root === null){
root = newNode;
}else{
insertNode(root,newNode)
}
}
要向树中插入一个新的节点,要经历三个步骤
- 是创建用来表示新节点的Node 类实例,只需要向构造函数传递我们想用来插入树的节点值,它的左指针和右指针会由构造函数与自动设置为 null
- 验证这个插入操作是否为一种特殊情况。这个特殊情况就是我们要插入的节点是树的第一个节点。如果是,就将节点指向新节点。
- 如果不是,就要将节点加在非根节点的其他位置。这种情况下,需要一个私有的辅助函数
var insertNode = function(node,newNode){
if(newNode.key < node.key){
if(node.left === null){
node.left = newNode;
}else{
insertNode(node.left,newNode)
}
}else{
if(node.right === null){
node.right = newNode;
}else{
insertNode(node.right,newNode)
}
}
}
insertNode 函数会帮助我们找到新节点应该插入的正确位置,下面是这个函数实现的步骤。
- 如果树非空,需要找到插入新节点的位置,因此在调用 insertNode 方法时要通过参数传入根书的根节点和要插入的节点。
- 如果新节点的键小于当前节点的键(当前节点就是根节点),那么需要检查当前节点的左侧节点,需要通过递归调用 insertNode 方法继续需要树的下一层,在这里,下次将要比较的节点就会是当前节点的左侧节点。
- 如果节点的键大于当前节点的键,同时当前节点没有右侧子节点,就在那里插入洗的节点。如果有右侧子节点,同样需要递归调用 insertNode 方法,但是要用来和新节点比较的节点将会是右侧子节点。
树的遍历
遍历一颗树是指访问树的每个节点并对它们进行某种操作的过程。访问树的所有节点有三种方法:中序、先序和后序。
中序遍历
中序遍历是一种以上行顺序访问BST 所有节点的遍历方式,也就是以最小和最大的顺序访问所有节点。中序遍历的一种应用就是对数进行排序操作。实现:
this.inOrderTraverse = function(callback){
inOrderTraverseNode(root,callback);
}
inOrderTraverse 方法接受一个回调函数作为参数。回调函数用来定义我们对遍历到的每个节点进行的操作(这也叫做访问者模式)。由于我们在BST 中最常见实现的算法是递归,这里使用一个私有的辅助函数,来接受一个节点和对应的回调函数作为参数。
var inOrderTraverseNode = function(node, callback){
if(node !== null){
inOrderTraverseNode(node.left, callback);
callback(node.key)
inOrderTraverseNode(node.left, callback);
}
}
要通过中序遍历的方法遍历一棵树,首先要检查以参数形式传入的节点是否为 null (这就是停止递归继续执行的判断条件)
然后递归调用相同的函数来访问左侧子节点,或者对这个节点进行一些操作(callback),然后再访问右侧子节点。
测试。
const tree = new BinarySearchTree();
tree.insert(11);
tree.insert(7);
tree.insert(15);
tree.insert(5);
tree.insert(3);
tree.insert(9);
tree.insert(8);
tree.insert(10);
tree.insert(13);
tree.insert(12);
tree.insert(14);
tree.insert(20);
tree.insert(18);
tree.insert(25);
tree.insert(6);
tree.inOrderTraverse(printNode);
// 3 5 6 7 8 9 10 11 12 13 14 15 18 20 25
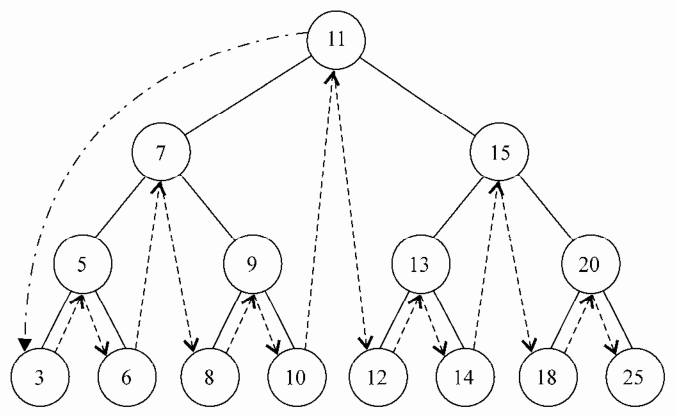
下面的图描述了 inOrderTraverse 方法的访问路径
先序遍历
先序遍历是以优于后代节点的顺序访问每个节点的。先序遍历的一种应用就是打印一个结构化的文档。
实现:
this.preOrderTraverse = function(callback){
preOrderTraverseNode(root,callback);
}
preOrderTraverseNode 方法的实现
var preOrderTraverseNode = function(node, callback){
if(node !== null){
callback(node.key)
preOrderTraverseNode(node.left, callback);
preOrderTraverseNode(node.right, callback);
}
}
先序遍历和中序遍历的不同点是,先序遍历会先访问节点的本身,然后再访问它的左侧子节点,最后是右侧子节点,而中序遍历的执行顺序是:先访问左侧子节点、接着节点本身,最后是右侧子节点。
下面是测试结果
tree.preOrderTraverse(printNode);
// 11 7 5 3 6 9 8 10 15 13 12 14 20 18 25
下面的描述了 preOrderTraverse 方法的访问路径
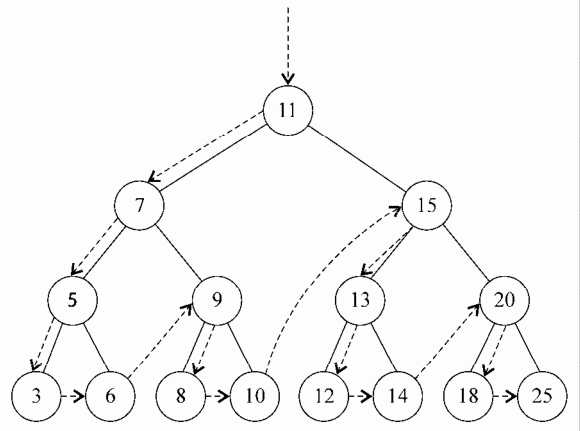
后序遍历
后序遍历是先访问节点的后代节点,再访问节点本身。后序遍历的一种应用是计算一个目录和它的子目录中所有文件所占空间的大小。
实现:
this.postOrderTraverse = function(callback){
postOrderTraverseNode(root,callback);
}
postOrderTraverseNode 方法的实现:
var postOrderTraverseNode = function(node, callback){
if(node !== null){
postOrderTraverseNode(node.left, callback);
postOrderTraverseNode(node.right, callback);
callback(node.key)
}
}
这个例子中,后序遍历会先访问左侧子节点,然后是右侧子节点,最后是父节点。
下面是测试结果
tree.postOrderTraverse(printNode);
// 3 6 5 8 10 9 7 12 14 13 18 25 20 15 11
下图描述了 postOrderTraverse 方法的访问路径
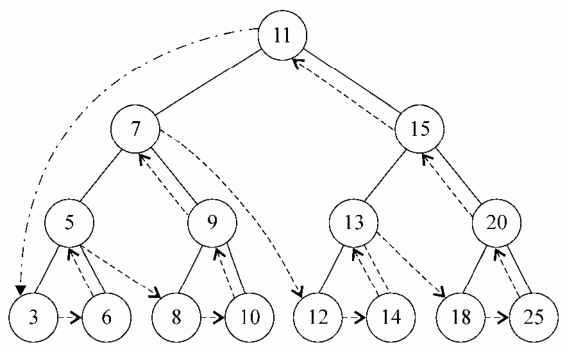
搜索树中的值
在树中,有三种经常执行的搜索类型
- 搜索最大值
- 搜索最小值
- 搜索特定的值
搜索最小值和最大值
我们使用下面的树作为实例
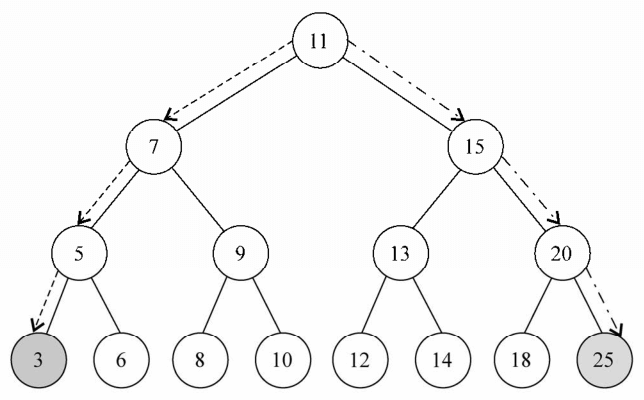
可以一眼发现树最后一层最左侧的节点的值为3,这是这棵树最小的键,如果你再看一眼最右端的树的节点,会发现是25,这是这棵树中最大的键。
首先,我们来寻找树的最小键的方法
this.min = function(){
return minNode(root);
}
min 方法将会暴露给用户,这个方法调用了 minNode方法。
var minNode = function(node){
if(node){
while(node && node.left !== null){
node = node.left
}
return node.key
}
return null;
}
minNode 方法允许我们从树中任意一个节点开始寻找最小的键。我们可以使用它来知道一颗树或者它的子树中最小的键。因为,我们调用 minNode 方法的时候传入树的根节点,因为我们想找到这棵树的最小键。
在 minNode 内部,我们会遍历树的左边,直到找到树的最下层(最左端)
相似的方式,可以实现 max 方法
this.max = function(){
return maxNode(root);
}
var maxNode = function(node){
if(node){
while(node && node.right !== null){
node = node.right
}
return node.key
}
return null;
}
测试
console.log('这棵树的最大值:'+tree.max()); // 25
console.log('这棵树的最小值:'+tree.min()); // 3
搜索一个特定的值
实现
this.search = function(key){
return searchNode(root,key)
}
var searchNode = function(node,key){
if(node === null){
return false;
}
if(key < node.key){
return searchNode(node.left, key)
}else if(key > node.key){
return searchNode(node.right, key)
}else{
return true
}
}
我们要做的第一件事就是声明 search 方法。和 BST 中声明的其他方法的模式相同,我们将会使用一个辅助函数。
searchNode 方法可以用来寻找一棵树或者它的任意子树中的一个特定的值。
在开始算法前,先验证作为传入参数的node 是否为 null.是则证明要找的键没有找到,返回 false.
如果传入的不是 null,需要继续验证,如果要找的键比当前的节点小,那么继续在左侧的子树上搜索,反之在右侧子节点开始继续搜索,否则就说明要找的键和当前节点的键相等,就返回 true来表示找到了这个键。
测试
console.log(tree.search(3)); // true
console.log(tree.search(28)); // false
移除一个节点
移除方法是最复杂的,实现
this.remove = function(key){
root = removeNode(root,key);
}
这个方法接受要移除并且它调用了 removeNode 方法,传入 root 和要移除的键作为参数。
removeNode 复制在于我们处理不同的运行场景,还是通过递归来实现。
var removeNode = function(node,key){
if(node === null){
return null;
}
if(key < node.key){
node.left = removeNode(node.left,key)
return node;
}else if(key > node.key){
node.right = removeNode(node.right,key)
return node;
}else{
// 一个叶节点
if(node.left === null && node.right === null){
node = null;
return node;
}
// 只有一个子节点的节点
if(node.left === null){
node = node.right
return node;
}else if(node.right === null){
node = node.right;
return node;
}
// 一个有两个子节点的节点
var aux = findMinNode(node.right);
node.key = aux.key;
node.right = removeNode(node.right,aux.key);
return node;
}
}
移除一个叶节点
第一种情况是该节点是一个没有左侧或者右侧子节点的叶节点。在这种情况下,我们要做的就是给这个节点赋予 null 来移除它。但是学习了链表的实现后,我们知道仅仅赋予一个 null 值是不够的,还需要处理指针。在这里,这个节点没有任何的子节点,但是它有一个父节点,需要通过返回 null 来将对应的父节点指针赋值 null (return node)。
现在节点的值已经是 null ,父节点指向它的指针也会接收这个值,这也是我们在函数中返回节点的值的原因。父节点总是会接受到函数的返回值、另外一个可行的方法就是将父节点和节点本身都作为参数传入方法内部。
移除有一个左侧或右侧子节点的节点
移除有一个左侧子节点或右侧子节点的节点。在这种情况下,需要跳过这个节点,直接将父节点指向它的指针指向子节点。
如果这个节点没有左侧子节点,也就是说它有一个右侧子节点。因为我们把对它的引用改为对它右侧子节点的引用,并返回更新后的节点。如果这个节点没有右侧子节点,也是一样——把对它的引用改为对它左侧子节点的引用并返回更新后的值。
移除有两个子节点的节点
最复杂的情况就是要移除的节点有两个子节点——左侧子节点和右侧子节点。要移除有两个子节点的节点,需要执行四个步骤
- 当找到了需要移除的节点后,需要找到它右边子树中最小的节点(它的继承者 var aux = finMinNode(node.right))
- 然后,用它右侧子树中最小节点的键去更新这个节点的值(node.key = zux.key)。通过这一步,我们改变了这个节点的键,也就是它被移除了。
- 但是,这样在树中就有两个拥有相同键的节点了,需要继续把右侧子树中的最小节点移除,毕竟它已经被移至要移除的节点的位置了。
- 最后,向它的父节点返回更新后节点的引用。
findMinNode 方法的实现和 min 方法的实现方式是一样的。唯一不同之处在于,在 min 方法中只返回键,而在 findMinNode 中返回了节点。
完整代码
var insertNode = function(node,newNode){
if(newNode.key < node.key){
if(node.left === null){
node.left = newNode;
}else{
insertNode(node.left,newNode)
}
}else{
if(node.right === null){
node.right = newNode;
}else{
insertNode(node.right,newNode)
}
}
}
var inOrderTraverseNode = function(node, callback){
if(node !== null){
inOrderTraverseNode(node.left, callback);
callback(node.key)
inOrderTraverseNode(node.right, callback);
}
}
var preOrderTraverseNode = function(node, callback){
if(node !== null){
callback(node.key)
preOrderTraverseNode(node.left, callback);
preOrderTraverseNode(node.right, callback);
}
}
var postOrderTraverseNode = function(node, callback){
if(node !== null){
postOrderTraverseNode(node.left, callback);
postOrderTraverseNode(node.right, callback);
callback(node.key)
}
}
var minNode = function(node){
if(node){
while(node && node.left !== null){
node = node.left
}
return node.key
}
return null;
}
var maxNode = function(node){
if(node){
while(node && node.right !== null){
node = node.right
}
return node.key
}
return null;
}
var searchNode = function(node,key){
if(node === null){
return false;
}
if(key < node.key){
return searchNode(node.left, key)
}else if(key > node.key){
return searchNode(node.right, key)
}else{
return true
}
}
var removeNode = function(node,key){
if(node === null){
return null;
}
if(key < node.key){
node.left = removeNode(node.left,key)
return node;
}else if(key > node.key){
node.right = removeNode(node.right,key)
return node;
}else{
// 一个叶节点
if(node.left === null && node.right === null){
node = null;
return node;
}
// 只有一个子节点的节点
if(node.left === null){
node = node.right
return node;
}else if(node.right === null){
node = node.right;
return node;
}
// 一个有两个子节点的节点
var aux = findMinNode(node.right);
node.key = aux.key;
node.right = removeNode(node.right,aux.key);
return node;
}
}
var findMinNode = function(node){
while(node && node.left !== null){
node = node.left;
}
return node;
}
var heightNode = function(node){
if(node === null){
return -1;
}else{
return Math.max(heightNode(node.left),heightNode(node.right))+ 1;
}
}
var printNode = function(value){
console.log(value);
}
function BinarySearchTree(){
var Node = function(key){
this.key = key;
this.left = null;
this.right = null;
}
var root = null;
this.insert = function(key){
var newNode = new Node(key);
if(root === null){
root = newNode;
}else{
insertNode(root,newNode)
}
}
this.search = function(key){
return searchNode(root,key)
}
this.inOrderTraverse = function(callback){
inOrderTraverseNode(root,callback);
}
this.preOrderTraverse = function(callback){
preOrderTraverseNode(root,callback);
}
this.postOrderTraverse = function(callback){
postOrderTraverseNode(root,callback);
}
this.min = function(){
return minNode(root);
}
this.max = function(){
return maxNode(root);
}
this.remove = function(key){
root = removeNode(root,key);
console.log(root);
}
this.deep = function(){
return heightNode(root);
}
}
自平衡树
BST 存在一个问题:取决于你添加的节点数,树的一条边可能会非常深,也就是说,树的一条分支会有很多层,而其他的分支却只有几层。
为了解决这个问题,有一种树叫做 Sdelson-Velskii-Land 树(AVL 树)。一种自平衡的二叉搜索树,意思是任何一个节点左右两侧子树的高度之差最多为1,也就是说这种树会在添加和移除节点时尽量试着成为一颗完全的树。
这里不做具体深入实现,尽管AVL树是自平衡的,其插入和移除节点的性能并不总是最好的。更好的选择是红黑树。红黑树可以高效有序的遍历其节点。有兴趣的请自行百度
小结
这章介绍了广泛使用的基本树数据结构——二叉搜索树中添加、移除和搜索项的算法。同样介绍了访问树中每个节点的三种遍历方式——中序、先序、后序遍历
下一章,将学习图的基本概念,也是一种非线性的数据结构。
书籍链接: 学习JavaScript数据结构与算法
为什么我要放弃javaScript数据结构与算法(第八章)—— 树的更多相关文章
- 为什么我要放弃javaScript数据结构与算法(第十一章)—— 算法模式
本章将会学习递归.动态规划和贪心算法. 第十一章 算法模式 递归 递归是一种解决问题的方法,它解决问题的各个小部分,直到解决最初的大问题.递归通常涉及函数调用自身. 递归函数是像下面能够直接调用自身的 ...
- 为什么我要放弃javaScript数据结构与算法(第十章)—— 排序和搜索算法
本章将会学习最常见的排序和搜索算法,如冒泡排序.选择排序.插入排序.归并排序.快速排序和堆排序,以及顺序排序和二叉搜索算法. 第十章 排序和搜索算法 排序算法 我们会从一个最慢的开始,接着是一些性能好 ...
- 为什么我要放弃javaScript数据结构与算法(第九章)—— 图
本章中,将学习另外一种非线性数据结构--图.这是学习的最后一种数据结构,后面将学习排序和搜索算法. 第九章 图 图的相关术语 图是网络结构的抽象模型.图是一组由边连接的节点(或顶点).学习图是重要的, ...
- 为什么我要放弃javaScript数据结构与算法(第七章)—— 字典和散列表
本章学习使用字典和散列表来存储唯一值(不重复的值)的数据结构. 集合.字典和散列表可以存储不重复的值.在集合中,我们感兴趣的是每个值本身,并把它作为主要元素.而字典和散列表中都是用 [键,值]的形式来 ...
- 为什么我要放弃javaScript数据结构与算法(第六章)—— 集合
前面已经学习了数组(列表).栈.队列和链表等顺序数据结构.这一章,我们要学习集合,这是一种不允许值重复的顺序数据结构. 本章可以学习到,如何添加和移除值,如何搜索值是否存在,也可以学习如何进行并集.交 ...
- 为什么我要放弃javaScript数据结构与算法(第五章)—— 链表
这一章你将会学会如何实现和使用链表这种动态的数据结构,这意味着我们可以从中任意添加或移除项,它会按需进行扩张. 本章内容 链表数据结构 向链表添加元素 从链表移除元素 使用 LinkedList 类 ...
- 为什么我要放弃javaScript数据结构与算法(第四章)—— 队列
有两种结构类似于数组,但在添加和删除元素时更加可控,它们就是栈和队列. 第四章 队列 队列数据结构 队列是遵循FIFO(First In First Out,先进先出,也称为先来先服务)原则的一组有序 ...
- 为什么我要放弃javaScript数据结构与算法(第三章)—— 栈
有两种结构类似于数组,但在添加和删除元素时更加可控,它们就是栈和队列. 第三章 栈 栈数据结构 栈是一种遵循后进先出(LIFO)原则的有序集合.新添加的或待删除的元素都保存在栈的同一端,称为栈顶,另一 ...
- 为什么我要放弃javaScript数据结构与算法(第二章)—— 数组
第二章 数组 几乎所有的编程语言都原生支持数组类型,因为数组是最简单的内存数据结构.JavaScript里也有数组类型,虽然它的第一个版本并没有支持数组.本章将深入学习数组数据结构和它的能力. 为什么 ...
随机推荐
- ACM HDU-2952 Counting Sheep
Counting Sheep Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- web服务器、app(应用)服务器、DB后端性能瓶颈和分析
性能测试day07_性能瓶颈和分析 https://www.cnblogs.com/leixiaobai/p/9463748.html 其实如果之前都做的很到位的话,那么再加上APM工具(dynaTr ...
- Python模块(进阶3)
转载请标明出处: http://www.cnblogs.com/why168888/p/6411917.html 本文出自:[Edwin博客园] Python模块(进阶3) 1. python中模块和 ...
- 可变对象(immutable)和不可变对象(mutable)
可变对象(immutable)和不可变对象(mutable) 这个是之前一直忽略的一个知识点,比方说说起String为什么是一个不可变对象,只知道因为它是被final修饰的所以不可变,而没有抓住不可变 ...
- 关于Hibernate懒加载问题的最终解决方案
看到一篇Hibernate懒加载的文章,所以转载,原地址如下: http://tuoxie007.iteye.com/blog/334853 Hibernate的强大之处之一是懒加载功能,可以有效的降 ...
- UVa 12034 - Race(递推 + 杨辉三角)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- PHP----练习-----三级联动
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- php开发规范-psr系列规范
转自:http://www.cnblogs.com/x3d/p/php-psr-standards.html PSR 是PHP Standard Recommendation的简写,它其实应该叫PSR ...
- EasyPoi导入Excel
EasyPoi的导出Excel功能和导入功能同样简单.我之前强调过,EasyPoi的原理本质就是Poi,正如MyBatis Plus的本质原理就是MyBatis. POI导入功能可以参考如下地址:ht ...
- 学习openGL-windows环境配置
windows对openGL的支持直到1.1,而如今openGL版本已经更新到4.5,为了使用高版本的API,需要安装拓展库(glew). openGL只是个渲染系统,但是它不能产生窗口,需要依赖其它 ...