scrapy-splash抓取动态数据例子四
一、介绍
本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息。
给定关键字:打通;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
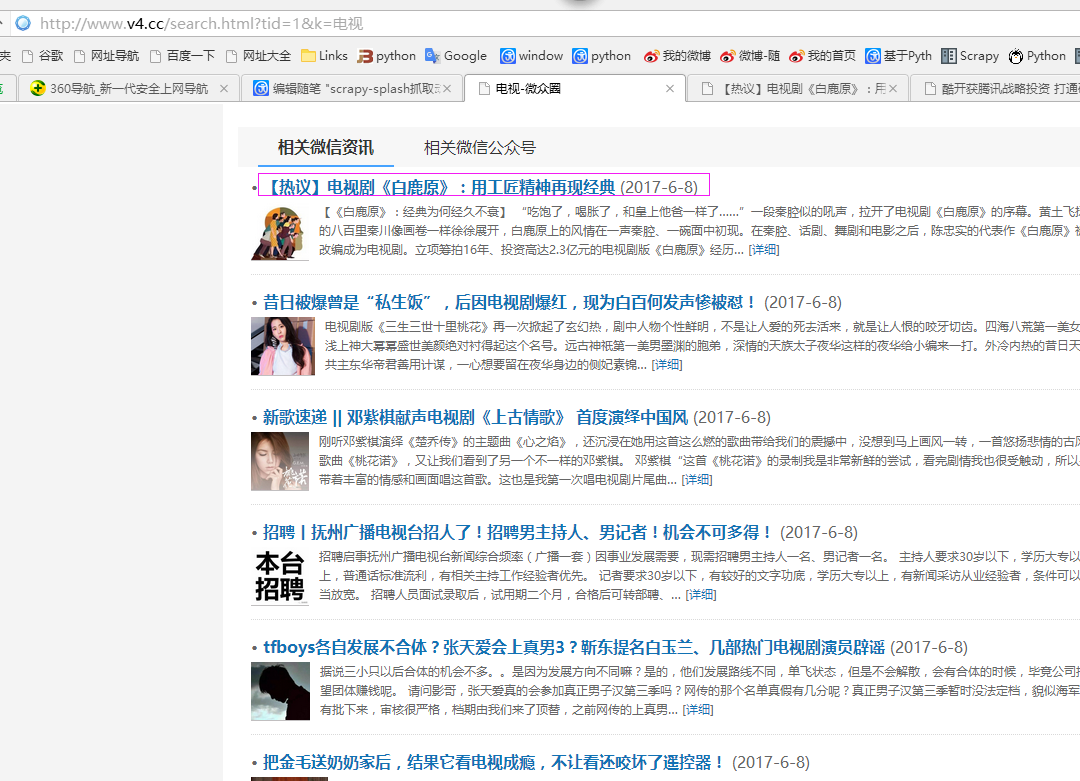

三、数据抓取
针对上面的网站信息,来进行抓取
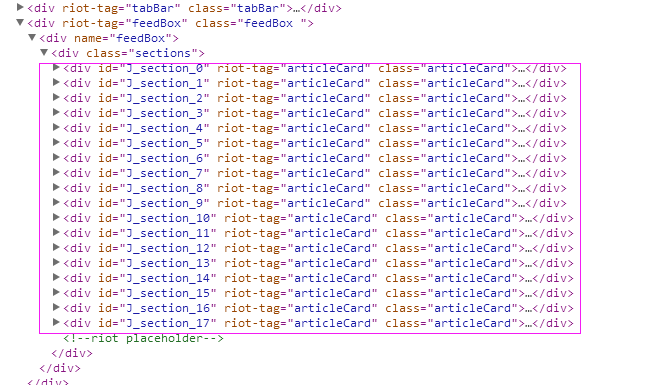
1、首先抓取信息列表
抓取代码:sels = site.xpath('//li[@class="itemtitle"]')
2、抓取标题
首先列表页面,根据标题和日期来判断是否自己需要的资讯,如果是,就今日到资讯对应的链接,来抓取来源,如果不是,就不用抓取了
抓取代码:titles = sel.xpath('.//text()')
title =str(titles[1].extract())
3、抓取链接
抓取代码:url = 'http://www.v4.cc'+ str(sel.xpath('.//a/@href')[0].extract())
4、抓取日期
抓取代码:flag,date =self.date_isValid(str(titles[2].extract()))
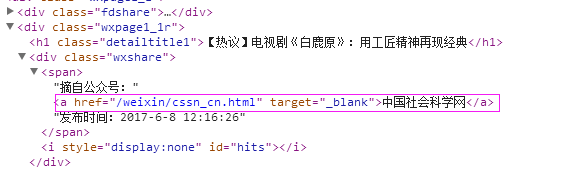
5、抓取来源
抓取代码:sources = site.xpath('//div[@class="wxshare"]/span/a/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') sys.stdout = open('output.txt', 'w') class weizhongquanSpider(Spider):
name = 'weizhongquan' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_keywords = cf.GetValue("section", "information_keywords")
information_wordlist = information_keywords.split(';')
websearchurl = cf.GetValue("weizhongquan", "websearchurl")
start_urls = []
for word in information_wordlist:
start_urls.append(websearchurl + word) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
index = url.rfind('=')
yield SplashRequest(url
, self.parse
, args={'wait': ''},
meta={'keyword': url[index + 1:]}
) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate,strDate[0])==0:
return True,currentDate
return False, ''
def parse(self, response):
site = Selector(response)
keyword = response.meta['keyword']
sels = site.xpath('//li[@class="itemtitle"]')
for sel in sels:
titles = sel.xpath('.//text()')
title =str(titles[1].extract())
flag,date =self.date_isValid(str(titles[2].extract()))
if flag and title.find(keyword)>-1:
url = 'http://www.v4.cc'+ str(sel.xpath('.//a/@href')[0].extract())
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword,'title':title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//div[@class="wxshare"]/span/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
return it
scrapy-splash抓取动态数据例子四的更多相关文章
- scrapy-splash抓取动态数据例子十四
一.介绍 本例子用scrapy-splash爬取超级TV网站的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4. ...
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
随机推荐
- 微信小程序-ios系统-下拉上拉出现白色,如何处理呢?
这几天做小程序,有些页面都是全屏的背景,在安卓上背景是固定的,而在ios上上拉下拉出现白色,测试说体验不太好,一开始我以为是下拉上拉刷新造成的,关闭了依然是这样.为了体验好点,可以按一下解决: 方式一 ...
- [BZOJ5305][Haoi2018]苹果树 组合数
题目描述 小 C 在自己家的花园里种了一棵苹果树, 树上每个结点都有恰好两个分支. 经过细心的观察, 小 C 发现每一天这棵树都会生长出一个新的结点. 第一天的时候, 果树会长出一个根结点, 以后每一 ...
- SQL Error: 1064, SQLState: 42000
这个错误是因为mysql有些关键字被我们用了,需要更改关键字成其他名字 ADD ALL ALTER ANALYZE AND AS ASC ASENSITIVE BEFORE BETWEEN BIGIN ...
- Homebrew安装gradle及配置myeclipse
brew install gradle 对,你没看错.就只有一行命令搞定. 然后验证安装 nicknailodeMacBook-Pro:~ nicknailo$ gradle -v --------- ...
- 2015 ACM-ICPC 沈阳站
题目链接 2015 ACM-ICPC Shenyang Problem A Problem B Problem C Problem D 签到题,所有gcd的倍数都可以被写出来. 那么判断一下这类数的 ...
- 【我要学python】愣头青之小数点精度控制
写在最前面:今天遇到了棘手的问题,看了两遍才看懂,本文属于转载+修改,原出处是Herbert's Blog 基础 浮点数是用机器上浮点数的本机双精度(64 bit)表示的.提供大约17位的精度和范围从 ...
- 小试牛刀之Django
Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了ORM.模型绑定.模板引擎.缓存.Session等诸多功能. ...
- HDU 5862 Counting Intersections(离散化 + 树状数组)
Counting Intersections Time Limit: 12000/6000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/ ...
- Linux命令之chattr
chattr [-RVf] [-v version] [mode] files… chattr修改文件在Linux第二扩展文件系统(E2fs)上的特有属性.符号模式(mode)有+-=[aAcCdDe ...
- 【vim】mac配置vim,molokai配色
效果如下: 首先修改主目录下的.vimrc: "======================================================================= ...