Redis源码解析之ziplist
Ziplist是用字符串来实现的双向链表,对于容量较小的键值对,为其创建一个结构复杂的哈希表太浪费内存,所以redis 创建了ziplist来存放这些键值对,这可以减少存放节点指针的空间,因此它被用来作为哈希表初始化时的底层实现。下图即ziplist 的内部结构。
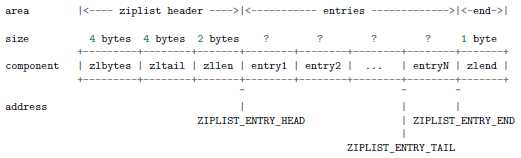
Zlbytes是整个ziplist 所占用的空间,必要时需要重新分配。
Zltail便于快速的访问到表尾节点,不需要遍历整个ziplist。
Zllen表示包含的节点数。
Entries表示用户增加上去的节点。
Zlend是一个255的值,表示ziplist末尾
Ziplist比dict更节省内存,所以在创建hash的时候默认ziplist作为其底层实现,当有需要时,再转换回来。
举例:用户创建一个以ziplist为底层的hash键:
Redis-cli > hset book name "programing"
首先进入hsetCommand()函数的hashTypeLookupWriteOrCreate()函数
void hsetCommand(redisClient *c) {
int update;
robj *o;
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[])) == NULL) return;
hashTypeTryConversion(o,c->argv,,);
hashTypeTryObjectEncoding(o,&c->argv[], &c->argv[]);
update = hashTypeSet(o,c->argv[],c->argv[]);
addReply(c, update ? shared.czero : shared.cone);
signalModifiedKey(c->db,c->argv[]);
notifyKeyspaceEvent(REDIS_NOTIFY_HASH,"hset",c->argv[],c->db->id);
server.dirty++;
}
robj *hashTypeLookupWriteOrCreate(redisClient *c, robj *key) {
robj *o = lookupKeyWrite(c->db,key);
if (o == NULL) {
o = createHashObject();
dbAdd(c->db,key,o);
} else {
if (o->type != REDIS_HASH) {
addReply(c,shared.wrongtypeerr);
return NULL;
}
}
return o;
}
先创建一个空的ziplist,编码方式默认为ziplist ,再add这个Key(book)到DB中
主要的添加操作在hashTpyeSet()中
/* Add an element, discard the old if the key already exists.
* Return 0 on insert and 1 on update.
* This function will take care of incrementing the reference count of the
* retained fields and value objects. */
int hashTypeSet(robj *o, robj *field, robj *value) {
int update = ; if (o->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr; field = getDecodedObject(field);
value = getDecodedObject(value); zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
fptr = ziplistFind(fptr, field->ptr, sdslen(field->ptr), );
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
redisAssert(vptr != NULL);
update = ; /* Delete value */
zl = ziplistDelete(zl, &vptr); /* Insert new value */
zl = ziplistInsert(zl, vptr, value->ptr, sdslen(value->ptr));
}
} if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
zl = ziplistPush(zl, field->ptr, sdslen(field->ptr), ZIPLIST_TAIL);
zl = ziplistPush(zl, value->ptr, sdslen(value->ptr), ZIPLIST_TAIL);
}
o->ptr = zl;
decrRefCount(field);
decrRefCount(value); /* Check if the ziplist needs to be converted to a hash table */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, REDIS_ENCODING_HT);
} else if (o->encoding == REDIS_ENCODING_HT) {
if (dictReplace(o->ptr, field, value)) { /* Insert */
incrRefCount(field);
} else { /* Update */
update = ;
}
incrRefCount(value);
} else {
redisPanic("Unknown hash encoding");
}
return update;
}
首先会搜索ziplist ,如果发现有相同的键值,则替换掉,如果找不到,则把新加入的键值push到ziplist 的末尾,在源码中可以发现当其长度大于hash_max_ziplist_entries就需要转换为hash table的编码方式。
完成上述操作之后,就使用addReply()把结果存到buffer中传给客户端。
Redis源码解析之ziplist的更多相关文章
- .Net Core缓存组件(Redis)源码解析
上一篇文章已经介绍了MemoryCache,MemoryCache存储的数据类型是Object,也说了Redis支持五中数据类型的存储,但是微软的Redis缓存组件只实现了Hash类型的存储.在分析源 ...
- Redis源码解析:15Resis主从复制之从节点流程
Redis的主从复制功能,可以实现Redis实例的高可用,避免单个Redis 服务器的单点故障,并且可以实现负载均衡. 一:主从复制过程 Redis的复制功能分为同步(sync)和命令传播(comma ...
- Redis源码解析之跳跃表(三)
我们再来学习如何从跳跃表中查询数据,跳跃表本质上是一个链表,但它允许我们像数组一样定位某个索引区间内的节点,并且与数组不同的是,跳跃表允许我们将头节点L0层的前驱节点(即跳跃表分值最小的节点)zsl- ...
- Redis源码解析:13Redis中的事件驱动机制
Redis中,处理网络IO时,采用的是事件驱动机制.但它没有使用libevent或者libev这样的库,而是自己实现了一个非常简单明了的事件驱动库ae_event,主要代码仅仅400行左右. 没有选择 ...
- Redis源码解析
一.src/server.c 中的redisCommandTable列出的所有redis支持的命令,其中字符串命令包括从get到mget:列表命令从rpush到rpoplpush:集合命令包括从sad ...
- Redis源码解析:26集群(二)键的分配与迁移
Redis集群通过分片的方式来保存数据库中的键值对:一个集群中,每个键都通过哈希函数映射到一个槽位,整个集群共分16384个槽位,集群中每个主节点负责其中的一部分槽位. 当数据库中的16384个槽位都 ...
- Redis源码解析:25集群(一)握手、心跳消息以及下线检测
Redis集群是Redis提供的分布式数据库方案,通过分片来进行数据共享,并提供复制和故障转移功能. 一:初始化 1:数据结构 在源码中,通过server.cluster记录整个集群当前的状态,比如集 ...
- Redis源码解析之跳跃表(一)
跳跃表(skiplist) 有序集合(sorted set)是Redis中较为重要的一种数据结构,从名字上来看,我们可以知道它相比一般的集合多了一个有序.Redis的有序集合会要求我们给定一个分值(s ...
- jedis的publish/subscribe[转]含有redis源码解析
首先使用redis客户端来进行publish与subscribe的功能是否能够正常运行. 打开redis服务器 [root@localhost ~]# redis-server /opt/redis- ...
随机推荐
- select下拉箭头改变,兼容ie8/9
各个浏览器下select默认的下拉箭头差别较大,通常会清除默认样式,重新设计 <html> <head> <meta charset="utf-8"& ...
- 通过or注入py脚本
代码思路 1.主要还是参考了别人的代码,确实自己写的和别人写的出路很大,主要归咎还是自己代码能力待提高吧. 2.将功能集合成一个函数,然后通过*args这个小技巧去调用.函数的参数不是argv的值,但 ...
- Linux进程调度与源码分析(一)——简介
本系列文章主要是近期针对Linux进程调度源码进行阅读与分析后的经验总结,分析过程中可能结合部分Linux网络编程的相关知识以便于理解,加深对Linux进程调度的理解和知识分享. 本系列文章主要结合L ...
- linux中断线程化分析【转】
转自:http://blog.csdn.net/qq405180763/article/details/24120895 版权声明:本文为博主原创文章,未经博主允许不得转载. 最近在为3.8版本的Li ...
- 如何更新远程主机上的 Linux 内核
如何更新远程主机上的 Linux 内核 http://blog.csdn.net/robertsong2004/article/details/47277121 转载至:http://www.tiny ...
- Open WATCOM指南 - 哦这样的孤单 你冷若冰霜
https://my.oschina.net/GIIoOS/blog/126701 WATCOM的历史可以追溯到1965年 加拿大的学生Waterloo的团队开发了叫WATFOR的Fortran编译器 ...
- spark 环境搭建坑
spark的新人会有什么坑 spark是一个以java为基础的,以Scala实现的,所以在你在安装指定版本的spark,需要检查你用的是对应spark使用什么版本的scala,可以通过spark-sh ...
- 【bzoj4033】HAOI2015树上染色
树形dp. #include<bits/stdc++.h> #define N 2010 using namespace std; typedef long long ll; ,head[ ...
- 关于移动端audio自动播放问题
本人小白全栈一枚,给公司写了一个监控中心,要求严重报警的时候需要触发音频播放,于是就有了以下的折腾. 刚开始一切都很顺利,自然而然的写了以下代码. <audio id="myaudio ...
- 使用GitLab进行落地项目的管理,并且自动更新、重启、回滚
Gitlab 清空项目历史commit,节省空间 http://blog.csdn.net/dounine/article/details/77840416?locationNum=6&f ...