LevelDB源码分析之:arena内存管理
一.原理
arena是LevelDB内部实现的内存池。
我们知道,对于一个高性能的服务器端程序来说,内存的使用非常重要。C++提供了new/delete来管理内存的申请和释放,但是对于小对象来说,直接使用new/delete代价比较大,要付出额外的空间和时间,性价比不高。另外,我们也要避免多次的申请和释放引起的内存碎片。一旦碎片到达一定程度,即使剩余内存总量够用,但由于缺乏足够的连续空闲空间,导致内存不够用的假象。
C++ STL为了避免内存碎片,实现一个复杂的内存池,LevelDB中则没有那么复杂,只是实现了一个"一次性"内存池arena。在leveldb里面,并不是所有的地方都使用了这个内存池,主要是memtable使用,主要是用于临时存放用户的更新数据,由于更新的数据可能很小,所以这里使用内存池就很合适。
为了避免小对象的频繁分配,需要减少对new的调用,最简单的做法就是申请大块的内存,多次分给客户。LevelDB用一个vector<char *>来保存所有的内存分配记录,默认每次申请4k的内存块,记录下当前内存块剩余指针和剩余内存字节数,每当有新的申请,如果当前剩余的字节能满足需要,则直接返回给用户。如果不能,对于超过1k的请求,直接new一个指定大小的内存块并返回,小于1K的请求,则申请一个新的4k内存块,从中分配一部分给用户。当内存池对象析构时,分配的内存均被释放,保证了内存不会泄漏。
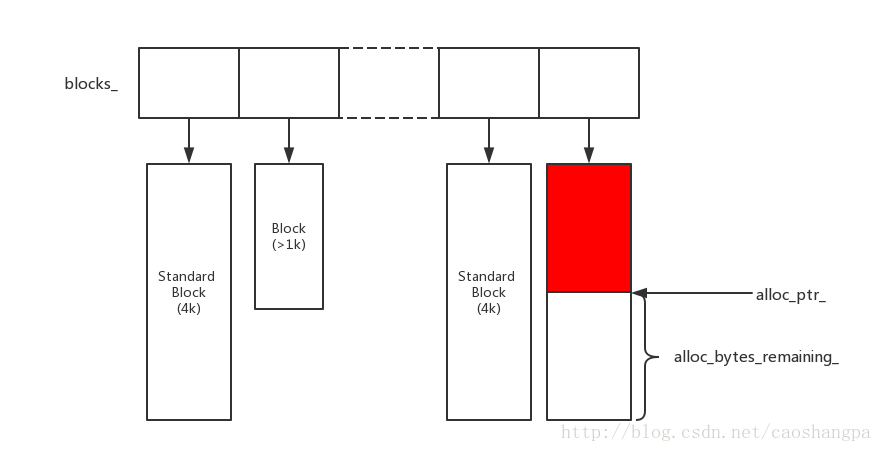
头文件
class Arena {
public:
Arena();
~Arena();
// Return a pointer to a newly allocated memory block of "bytes" bytes.
// 分配bytes大小的内存块,返回指向该内存块的指针
char* Allocate(size_t bytes);
// Allocate memory with the normal alignment guarantees provided by malloc
// 基于malloc的字节对齐内存分配
char* AllocateAligned(size_t bytes);
// Returns an estimate of the total memory usage of data allocated
// by the arena (including space allocated but not yet used for user
// allocations).
// 返回整个内存池使用内存的总大小(不精确),这里只计算了已分配内存块的总大小和
// 存储各个内存块指针所用的空间。并未计算alloc_ptr_和alloc_bytes_remaining_
// 等数据成员的大小。
size_t MemoryUsage() const {
return blocks_memory_ + blocks_.capacity() * sizeof(char*);
}
private:
char* AllocateFallback(size_t bytes);
char* AllocateNewBlock(size_t block_bytes);
// Allocation state
// 当前内存块(block)偏移量指针,也就是未使用内存的首地址
char* alloc_ptr_;
// 表示当前内存块(block)中未使用的空间大小
size_t alloc_bytes_remaining_;
// Array of new[] allocated memory blocks
// 用来存储每一次向系统请求分配的内存块的指针
std::vector<char*> blocks_;
// Bytes of memory in blocks allocated so far
// 迄今为止分配的内存块的总大小
size_t blocks_memory_;
// No copying allowed
Arena(const Arena&);
void operator=(const Arena&);
};
源文件
inline char* Arena::Allocate(size_t bytes) {
// The semantics of what to return are a bit messy if we allow
// 0-byte allocations, so we disallow them here (we don't need
// them for our internal use).
// 如果允许分配0字节的内存,那么返回值在语义上会比较难以理解,因此这里禁止bytes=0
// 如果需求的内存小于当前内存块中剩余的内存,那么直接从当前内存快中获取
assert(bytes > );
if (bytes <= alloc_bytes_remaining_) {
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
// 因为alloc_bytes_remaining_初始为0,因此第一次调用Allocate实际上直接调用的是AllocateFallback
// 如果需求的内存大于内存块中剩余的内存,也会调用AllocateFallback
return AllocateFallback(bytes);
}
char* Arena::AllocateFallback(size_t bytes) {
// 如果需求的内存大于内存块中剩余的内存,而且大于1K,则给这内存单独分配一块bytes大小的内存。
// 这样可以避免浪费过多的空间(因为如果bytes大于1K也从4K的内存块去取用,那么如果当前内存块中刚好剩余
// 1K,只能再新建一个4K的内存块,并且取用bytes。此时新建的内存块是当前内存块,后续操作都是基于当前内
// 存块的,那么原内存块中的1K空间就浪费了)
if (bytes > kBlockSize / ) {
// Object is more than a quarter of our block size. Allocate it separately
// to avoid wasting too much space in leftover bytes.
char* result = AllocateNewBlock(bytes);
return result;
}
// 如果需求的内存大于内存块中剩余的内存,而且小于1K,则重新分配一个内存块,默认大小4K,
// 原内存块中剩余的内存浪费掉(这样虽然也会浪费,但是浪费的空间小于1K)。并在新内存块
// 中取用bytes大小的内存。
// We waste the remaining space in the current block.
alloc_ptr_ = AllocateNewBlock(kBlockSize);
alloc_bytes_remaining_ = kBlockSize;
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
// 提供了字节对齐内存分配,一般情况是4字节或8个字节对齐分配,
// 对齐内存的好处简单的说就是加速内存访问。
// 首先获取一个指针的大小const int align = sizeof(void*),
// 很明显,在32位系统下是4 ,64位系统下是8 ,为了表述方便,我们假设是32位系统,即align = 4,
// 然后将我们使用的char * 指针地址转换为一个无符号整型(reinterpret_cast<uintptr_t>(result):
// It is an unsigned int that is guaranteed to be the same size as a pointer.),通过与操作来
// 获取size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align-1);当前指针模4
// 的值,有了这个值以后,我们就容易知道,还差 slop = align - current_mod多个字节,内存才是对齐的,
// 所以有了result = alloc_ptr + slop。那么获取bytes大小的内存,实际上需要的大小为needed = bytes + slop。
char* Arena::AllocateAligned(size_t bytes) {
const int align = sizeof(void*); // We'll align to pointer size
assert((align & (align-)) == ); // Pointer size should be a power of 2
size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align-); //这里就判断出了当前指针地址和字节对齐整数倍所差的个数
size_t slop = (current_mod == ? : align - current_mod);
size_t needed = bytes + slop;
char* result;
if (needed <= alloc_bytes_remaining_) {
result = alloc_ptr_ + slop;
alloc_ptr_ += needed;
alloc_bytes_remaining_ -= needed;
} else {
// AllocateFallback always returned aligned memory
result = AllocateFallback(bytes);
}
assert((reinterpret_cast<uintptr_t>(result) & (align-)) == );
return result;
}
// 分配新的内存块
char* Arena::AllocateNewBlock(size_t block_bytes) {
char* result = new char[block_bytes];
blocks_memory_ += block_bytes;
blocks_.push_back(result);
return result;
}
// 释放整个内存池所占内存
Arena::~Arena() {
for (size_t i = ; i < blocks_.size(); i++) {
delete[] blocks_[i];
}
}
LevelDB源码分析之:arena内存管理的更多相关文章
- Leveldb源码分析--1
coming from http://blog.csdn.net/sparkliang/article/details/8567602 [前言:看了一点oceanbase,没有意志力继续坚持下去了,暂 ...
- leveldb源码分析--SSTable之block
在SSTable中主要存储数据的地方是data block,block_builder就是这个专门进行block的组织的地方,我们来详细看看其中的内容,其主要有Add,Finish和CurrentSi ...
- JVM源码分析之堆内存的初始化
原创申明:本文由公众号[猿灯塔]原创,转载请说明出处标注 “365篇原创计划”第十五篇. 今天呢!灯塔君跟大家讲: JVM源码分析之堆内存的初始化 堆初始化 Java堆的初始化入口位于Univ ...
- 鸿蒙内核源码分析(物理内存篇) | 怎么管理物理内存 | 百篇博客分析OpenHarmony源码 | v17.01
百篇博客系列篇.本篇为: v17.xx 鸿蒙内核源码分析(物理内存篇) | 怎么管理物理内存 | 51.c.h .o 内存管理相关篇为: v11.xx 鸿蒙内核源码分析(内存分配篇) | 内存有哪些分 ...
- leveldb源码分析--WriteBatch
从[leveldb源码分析--插入删除流程]和WriteBatch其名我们就很轻易的知道,这个是leveldb内部的一个批量写的结构,在leveldb为了提高插入和删除的效率,在其插入过程中都采用了批 ...
- leveldb源码分析--Key结构
[注]本文参考了sparkliang的专栏的Leveldb源码分析--3并进行了一定的重组和排版 经过上一篇文章的分析我们队leveldb的插入流程有了一定的认识,而该文设计最多的又是Batch的概念 ...
- leveldb源码分析之内存池Arena
转自:http://luodw.cc/2015/10/15/leveldb-04/ 这篇博客主要讲解下leveldb内存池,内存池很多地方都有用到,像linux内核也有个内存池.内存池的存在主要就是减 ...
- dubbo源码分析6-telnet方式的管理实现
dubbo源码分析1-reference bean创建 dubbo源码分析2-reference bean发起服务方法调用 dubbo源码分析3-service bean的创建与发布 dubbo源码分 ...
- 并发编程(四):ThreadLocal从源码分析总结到内存泄漏
一.目录 1.ThreadLocal是什么?有什么用? 2.ThreadLocal源码简要总结? 3.ThreadLocal为什么会导致内存泄漏? 二.ThreadLoc ...
- leveldb源码分析--日志
我们知道在一个数据库系统中为了保证数据的可靠性,我们都会记录对系统的操作日志.日志的功能就是用来在系统down掉的时候对数据进行恢复,所以日志系统对一个要求可靠性的存储系统是极其重要的.接下来我们分析 ...
随机推荐
- Xcode 常用路径收集
Xcode证书 路径: ~/Library/MobileDevice/Provisioning Profiles Xcode 插件路径: ~/Library/Application Support/D ...
- Grunt:任务自动管理工具(收藏+转载)
原文:http://javascript.ruanyifeng.com/tool/grunt.html 安装 命令脚本文件Gruntfile.js Gruntfile.js实例:grunt-contr ...
- Thread 的join方法
package com.cn.test.thread; public class TestJoin extends Thread{ private String name; public TestJo ...
- js 去除空格回车换行
开发中遇到特殊需求,需要将空格回车换行替换成逗号 直接使用正则表达式解决: 变量.replace(/\s+/g,","); 如果想要去除则将后面逗号变成空就OK了.
- Linux 更新python至2.7后ImportError: No module named _ssl
原文:http://blog.51cto.com/hunt1574/1630961 编译安装python 2.7后无法导入ssl包 解决办法: 1 下载地址:http://www.openssl.or ...
- python使用元类
原文:https://blog.csdn.net/youzhouliu/article/details/51906158 type() 动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义 ...
- 关于使用flying-saucer-pdf,实现xhtml2pdf
@author Guoguo 2013.11.24 关于flying-saucer-pdf 是一个XML/CSS渲染器,flying-saucer-pdf工具以XML标准文件作为输入,CSS进行排版. ...
- Maven打包时,不包含jar包
在给Maven项目打war包时,如果不想把依赖中的jar包也包含进去,可以在plugins中加入 <span style="white-space:pre"> < ...
- Memcache 学习笔记(一)----Memcache — Linux部署
Memcache 一.Memcache简介(内容摘自 --百度百科) memcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用以 ...
- sublime_key 快捷键
1.Ctrl+H :查找替换 2.Ctrl+D :选择游标所在单词,连续Ctrl+D 实现多行选择(选择与第一次选择相同的单词) 3.Ctrl+K Ctrl+D 跳过当前选择,选择下一个 4.Ctrl ...