Solr第一讲——概述与入门
一、solr介绍
1.什么是solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
实现方案:
索引流程:solr客户端(浏览器、java程序)可以向solr服务端发送POST请求,请求内容是包含Field等信息的一个xml文档,通过该文档,solr实现对索引的维护(增删改)
搜索流程:solr客户端(浏览器、java程序)可以向solr服务端发送GET请求,solr服务器返回一个xml文档。
Solr同样没有视图渲染的功能。
2.solr和lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。

最核心得区别是由工具包变成了独立服务,并且索引管理更加方便,可以集群!
二、solr安装配置
1.下载
Solr和lucene的版本是同步更新的,最新的版本是5.2.1
本课程使用的版本:4.10.3
下载地址:http://archive.apache.org/dist/lucene/solr/
下载版本:4.10.3
Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
下载lucene-4.10.3.zip并解压:
各目录概述如下:

2.安装配置
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器。
SolrCore的配置
1.SolrCore和SolrHome
SolrHome是Solr运行的主目录,该目录中包括了多个SolrCore目录。SolrCore目录中包含了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore。
一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
每一个solrcore都可以单独对外提供搜索和索引服务。
多个solrcore之间没有关系。
2.solr界面简介

Dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
Logging
Solr运行日志信息
Cloud
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单
Core Admin
Solr Core的管理界面。在这里可以添加SolrCore实例
java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
Core selector(重点)
Analysis(重点)

通过此界面可以测试索引分析器和搜索分析器的执行情况。
注:solr中,分析器是绑定在域的类型中的。
dataimport
可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。
默认没有配置,需要手工配置。
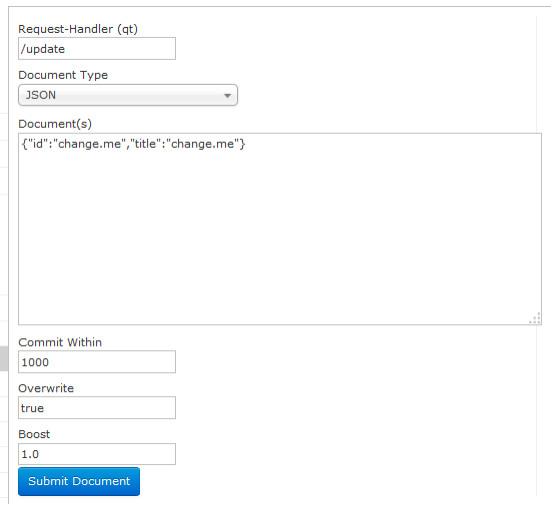
Document(重点)
通过/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
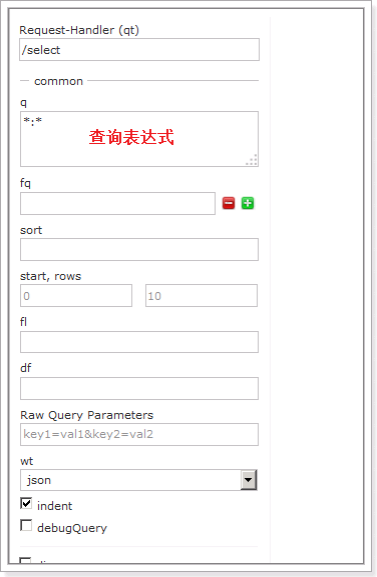
Query(重点)
通过/select执行搜索索引,必须指定“q”查询条件方可搜索。
solr的详细配置与教程请参见 易百教程:http://www.yiibai.com/solr/apache_solr_on_windows_environment.html#article-start
solr中国:https://www.solr.cc/blog/
三、solr的基本使用
1.schema文件
在schema.xml文件中,主要配置了solrcore的一些数据信息,包括Field和FieldType的定义等信息,
在solr中,Field和FieldType都需要先定义后使用。
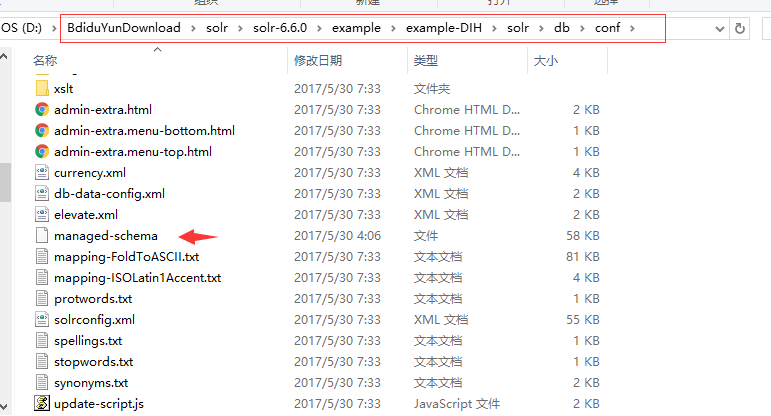
注意:solr的各版本差异导致文件位置等可能会发生变化,比如这里搜索到的其中一个位置是(具体各文件待阅读文档):
实例讲解:
Field:定义Field域
<field name="title" type="text_simple" indexed="true" stored="true" multiValued="true"/>
其中:(与lucene的概念是基本相通的)
name——指定域的名称
type——指定域的类型(用哪个分词器等)
indexed——是否索引
stored——是否存储
multiValued——是否多值(比如商品信息中,一个商品有多张图片,一个Field像存储多个值的话,必须将multiValued设置为true。)
dynamicField:动态域
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
Name——指定动态域的命名规则,此例中匹配i为后缀的
uniqueKey:唯一键
<uniqueKey>id</uniqueKey>
其中的id是在Field标签中已经定义好的域名,而且该域要设置为required为true。
一个schema.xml文件中必须有且仅有一个唯一键
copyField:复制域
<copyField source="cat" dest="text"/>
Source:要复制的源域的域名
Dest:目标域的域名
由dest指的的目标域,必须设置multiValued为true。
可以通过复制将多个域复制到一个域进行操作
FieldType:定义域的类型
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
name——指定域的名称
class——指定域的类型对应的solr类型
analyzer——指定分析器
tokenizer——分词器
filter——过滤器
2.中文分词器
使用IKAnalyzer中文分析器
基本步骤:
第一步:把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下。
第二步:复制IKAnalyzer的配置文件和自定义词典和停用词词典到solr的classpath下。
第三步:在schema.xml中添加一个自定义的fieldType,使用中文分析器。
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
//这里的TextField与Lucene的TextField还是有差别的
第四步:定义field,指定field的type属性为text_ik
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
Solr第一讲——概述与入门的更多相关文章
- Lucene第一讲——概述与入门
一.概述 1.什么是Lucene? Lucene是apache下的一个开源的全文检索引擎工具包. 它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现全文检索的功能. 2.能干什 ...
- jquery实战第一讲---概述及其入门实例
就在5月28号周四下午五点的时候,接到xxx姐姐的电话,您是xxx吗?准备一下,周五上午八点半去远洋面试,一路风尘仆仆,颠颠簸簸,由于小编晕车,带着晕晕乎乎的脑子,小编就稀里糊涂的去面试了,温馨提醒, ...
- WebService第一天——概述与入门操作
一.概述 1.是什么 Web service是一个平台独立的,低耦合的,自包含的.基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准来描述.发布.发现.协调和配置这些 ...
- C语言_第一讲_C语言入门
一.C语言的简介 1.C语言是一个标准,而执行标准的时候产生的自动化程序则是编译器2.了解:1983年美国国家标准化歇会(ANSI)制定了C语言标准.C语言的特点:3.代码的可移植性(理想状态是代码可 ...
- c#委托事件入门--第一讲:委托入门
说起委托,有些刚刚入门c#的人感觉很高大上,没有接触过,但是其实很多人都用过Lambda表达式,实际上Lambda表达式就是一个委托. 关于委托入门有个大神写的很详细:张子阳的博客 C#中的委托和事 ...
- c#委托事件入门--第二讲:事件入门
上文 c#委托事件入门--第一讲:委托入门 中和大家介绍了委托,学习委托必不可少的就要说下事件.以下思明仍然从事件是什么.为什么用事件.怎么实现事件和总结介绍一下事件 1.事件是什么:. 1.1 NE ...
- CS193P - 2016年秋 第一讲 课程简介
Stanford 的 CS193P 课程可能是最好的 ios 入门开发视频了.iOS 更新很快,这个课程的最新内容也通常是一年以内发布的. 最新的课程发布于2016年春季.目前可以通过 iTunes ...
- [EntLib]微软企业库5.0 学习之路——第一步、基本入门
话说在大学的时候帮老师做项目的时候就已经接触过企业库了但是当初一直没明白为什么要用这个,只觉得好麻烦啊,竟然有那么多的乱七八糟的配置(原来我不知道有配置工具可以进行配置,请原谅我的小白). 直到去年在 ...
- [信息检索] 第一讲 布尔检索Boolean Retrieval
第一讲 布尔检索Boolean Retrieval 主要内容: 信息检索概述 倒排记录表 布尔查询处理 一.信息检索概述 什么是信息检索? Information Retrieval (IR) is ...
随机推荐
- 你是怎么调试 JavaScript 程序
你是怎么调试 JavaScript 程序的?最原始的方法是用 alert() 在页面上打印内容,稍微改进一点的方法是用 console.log() 在 JavaScript 控制台上输出内容.嗯~,用 ...
- 为什么说 Java 程序员必须掌握 Spring Boot ?
原作者https://www.cnblogs.com/ityouknow/p/9175980.html Spring Boot 2.0 的推出又激起了一阵学习 Spring Boot 热,就单从我个人 ...
- 使用commons-fileupload-1.2.1.jar等组件实现文件上传
使用的主要jar包:commons-io-1.3.2.jar包;commons-fileupload-1.2.1.jar包:commons-lang-2.3.jar,在使用组件实现文件上传时候要注意前 ...
- 苹果手机(ios系统)蓝牙BLE的一些特点
摘自<BluetoothDesignGuidelines.pdf>文档 1. pairing: 苹果手机无法主动发起SMP配对流程,可通过以下两种方式发起配对流程: (1)从端主动发起配对 ...
- 交叉熵Cross-Entropy
1.交叉熵:用来描述通信中将一个概率分布的最优编码用到另一个概率分布的平均比特数 公式: 2.交叉熵是不对称的 3.交叉熵的作用是表达两个概率分布的差异性 设概率分布p(x)和q(x),两个概率分布差 ...
- PHP基础系列(二) PHP数组相关的函数分类整理
之前写过一篇介绍 PHP字符串函数 的博文,这里写第二篇,本文主要介绍PHP 数组相关的函数: 一.检查数组中是否存在 array_key_exists — 检查给定的键名或索引是否存在于数组中 ar ...
- php模板引擎的原理与简单实例
模板引擎其实就是将一个带有自定义标签的字符串,通过相应的规则解析,返回php可以解析的字符串,这其中正则的运用是必不可少的,所以要有一定的正则基础.总体思想,引入按规则写好的模板,传递给标签解析类(_ ...
- Mac python3.5 + Selenium 开发环境配置
一. python 3.5 1. 下载 2. Mac默认为2.7,所以这里主要介绍如何将系统Python默认修改为3.5. 原理: 1)Mac自带的python环境在: python2.7: /Sys ...
- HDU 1273 漫步森林(数学 找规律)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1273 漫步森林 Time Limit: 2000/1000 MS (Java/Others) M ...
- LwIP协议栈开发嵌入式网络的三种方法分析
LwIP协议栈开发嵌入式网络的三种方法分析 摘要 轻量级的TCP/IP协议栈LwIP,提供了三种应用程序设计方法,且很容易被移植到多任务的操作系统中.本文结合μC/OS-II这一实时操作系统,以 ...