吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import mixture
from sklearn.metrics import adjusted_rand_score
from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true #混合高斯聚类GMM模型
def test_GMM(*data):
X,labels_true=data
clst=mixture.GaussianMixture()
clst.fit(X)
predicted_labels=clst.predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels)) # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# 调用 test_GMM 函数
test_GMM(X,labels_true)
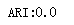
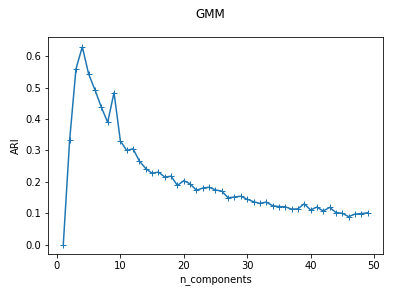
def test_GMM_n_components(*data):
'''
测试 GMM 的聚类结果随 n_components 参数的影响
'''
X,labels_true=data
nums=range(1,50)
ARIs=[]
for num in nums:
clst=mixture.GaussianMixture(n_components=num)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(nums,ARIs,marker="+")
ax.set_xlabel("n_components")
ax.set_ylabel("ARI")
fig.suptitle("GMM")
plt.show() # 调用 test_GMM_n_components 函数
test_GMM_n_components(X,labels_true)
def test_GMM_cov_type(*data):
'''
测试 GMM 的聚类结果随协方差类型的影响
'''
X,labels_true=data
nums=range(1,50) cov_types=['spherical','tied','diag','full']
markers="+o*s"
fig=plt.figure()
ax=fig.add_subplot(1,1,1) for i ,cov_type in enumerate(cov_types):
ARIs=[]
for num in nums:
clst=mixture.GaussianMixture(n_components=num,covariance_type=cov_type)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
ax.plot(nums,ARIs,marker=markers[i],label="covariance_type:%s"%cov_type) ax.set_xlabel("n_components")
ax.legend(loc="best")
ax.set_ylabel("ARI")
fig.suptitle("GMM")
plt.show() # 调用 test_GMM_cov_type 函数
test_GMM_cov_type(X,labels_true)

吴裕雄 python 机器学习——混合高斯聚类GMM模型的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——数据预处理流水线Pipeline模型
from sklearn.svm import LinearSVC from sklearn.pipeline import Pipeline from sklearn import neighbor ...
随机推荐
- Git bash 终止git log 命令
Git bash中 可以通过键入: q ,结束该命令.
- CF#538(div2) B. Yet Another Array Partitioning Task 【YY】
任意门:http://codeforces.com/contest/1114/problem/B B. Yet Another Array Partitioning Task time limit p ...
- vue - 简单实例(vue-router + webpack + vuex)
分享 + 实践 基于公司部分产品技术栈转型使用vue,部分同事需要学习一下,快速上手,那么我很荣幸的成为了给大家分享vue技术栈的‘ ’导师‘,在这里我分享一下: 讲解大纲为:(我是有一份PPT的, ...
- Linux下安装Qt5.6.1
我的环境:CentOS 6.7 64位. 1.下载Qt: Qt版本有很多,自己比较菜,希望安装的过程越简单越好,感觉比较新的版本会好安装一些,5.4版本还要更新 /usr/lib64/libstdc ...
- 【Node.js】新建一个NodeJS 4.X项目
前提工作 1.安装Node.js 各种下一步就好 2.安装NPM(node package manager) 安装好Node.js之后,打开cmd,输入npm install npm -g,程序会自动 ...
- 数据库——MySQL——索引
索引的功能就是加速查找,MySQL中的primary key,unique,联合唯一也都是索引,只是这些索引除了加速查找以外,还有约束功能. 一般的应用系统,读写比例在10:1左右,而且插入操作和一般 ...
- 解决MyEclipse JAVA EE无法识别Base64问题
第一步:右击项目选择Build Path,选择Configure Build Path 第二步:点击JRE System Library选择右边的Edit 第三步:选择Alternate JRE,点击 ...
- Spark Streaming编程示例
近期也有开始研究使用spark streaming来实现流式处理.本文以流式计算word count为例,简单描述如何进行spark streaming编程. 1. 依赖的jar包 参考<分别用 ...
- Kadane算法
Kadane算法用于解决连续子数组最大和问题,我们用ci来表示数组a[0...i]的最大和. 观察可以发现当ci-1 < 0时,ci = ai.用e表示以当前为结束的子数组的最大和,以替代数组c ...
- ie浏览器下载文件时文件名乱码
做一个文件下载功能时,用ie浏览器下载时文件名乱码,火狐和谷歌正常,修改后ie显示正常,修改方法如下: @RequestMapping(value = "fileDownload" ...