Mysql Sql Explain
1.使用mysql explain的原因
在我们php程序员的日常写代码中,有时候会发现我们写的sql语句运行的特别慢,导致响应时间特别长,这种情况在高并发的情况下,我们的网站会直接崩溃,为什么双十一的淘宝在如此高的并发访问量的情况下依旧运转良好,除了过硬的设备以及服务器分流等技术外,良好的sql查询语句也是功不可没的! 我们会去寻找并且记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,此时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
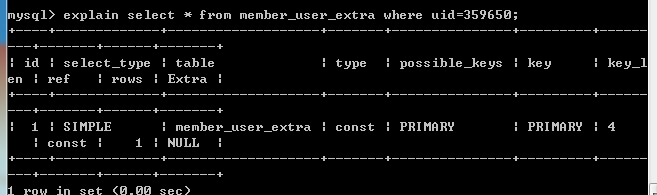
一个完整的查询语句的explain展现在我们眼前(explain也只能使用在select语句中):
expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra,下面对这些字段出现的可能进行解释:
1. id:
包含一组数字,表示查询中执行select子句或操作表的顺序
id相同,执行顺序由上至下,否则id值越大(通常子查询会产生)优先级越高,越先被执行
id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
id列为null的就表是这是一个结果集,不需要使用它来进行查询。
2.select_type列常见的有:
表示查询中每个select子句的类型
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
Mysql Sql Explain的更多相关文章
- MySQL SQL Explain输出学习
MySQL的explain命令语句提供了如何执行SQL语句的信息,解析SQL语句的执行计划并展示,explain支持select.delete.insert.replace和update等语句,也支持 ...
- MySQL的EXPLAIN命令用于SQL语句的查询执行计划
MySQL的EXPLAIN命令用于SQL语句的查询执行计划(QEP).这条命令的输出结果能够让我们了解MySQL 优化器是如何执行SQL 语句的.这条命令并没有提供任何调整建议,但它能够提供重要的信息 ...
- mysql sql优化实例
mysql sql优化实例 优化前: pt-query-degist分析结果: # Query 3: 0.00 QPS, 0.00x concurrency, ID 0xDC6E62FA021C85B ...
- Mysql之EXPLAIN显示using filesort
索引使用经验: 1. 一条 SQL 语句只能使用 1 个索引 (5.0-),MySQL 根据表的状态,选择一个它认为最好的索引用于优化查询 2. 联合索引,只能按从左到右的顺序依次使用 Using w ...
- 详解MySQL中EXPLAIN解释命令
Explain 结果解读与实践 基于 MySQL 5.0.67 ,存储引擎 MyISAM . 注:单独一行的"%%"及"`"表示分隔内容,就象分开“第一 ...
- 巧用MySQL之Explain进行数据库优化
前记:很多东西看似简单,那是因为你并未真正了解它. Explain命令用于查看执行效果.虽然这个命令只能搭配select类型语句使用,如果你想查看update,delete类型语句中的索引效果,也不是 ...
- mysql sql执行顺序
<pre name="code" class="html">mysql> explain select * from (select * fr ...
- mysql sql语句执行时是否使用索引检查方法
在日常开发中,使用到的数据表经常都会有索引,这些索引可能是开发人员/DBA建表时创建的,也可能是在使用过程中新增的.合理的使用索引,可以加快数据库查询速度.然而,在实际开发工作中,会出现有些sql语句 ...
- MYSQL SQL语句技巧初探(一)
MYSQL SQL语句技巧初探(一) 本文是我最近了解到的sql某些方法()组合实现一些功能的总结以后还会更新: rand与rand(n)实现提取随机行及order by原理的探讨. Bit_and, ...
随机推荐
- 通过反射获取T.class代码片段
说明 持久化框架MyBatis和Hibernate中我们多多少少都会自己取写工具类!但是我们一般都会处理结果集转换成持久化对象,但是我们都要使用类! 代码片段 abstract public clas ...
- 耗子学Python了(2)__Python开发“Hello World”
一:开发工具 在网上看到的用的开发工具Aptana Studio,我下载的是Aptana_Studio_3_Setup_3.6.1.exe,在安装的过程中啊,出现了各种问题,然后安装后了也出现打不开的 ...
- C语言数据结构-栈
一.栈的定义 栈(statck)这种数据结构在计算机中是相当出名的.栈中的数据是先进后出的(First In Last Out, FILO).栈只有一个出口,允许新增元素(只能在栈顶上增加). 移出元 ...
- ssh 远程执行命令简介
在写这篇博客之前,我google了一堆相关文章,大都是说修改/etc/sudoers,然后NOPASSWD:指定的cmd,但是真心不管用,没有远程虚拟终端这个方法就是浮云,ubuntu10.04 se ...
- 「6月雅礼集训 2017 Day8」infection
[题目大意] 有$n$个人,每个人有一个初始位置$x_i$和一个速度$v_i$,你需要选择若干个人来感染一个傻逼病毒. 当两个人相遇(可以是正面和背面),傻逼病毒会传染,求经过无限大时间后,传染完所有 ...
- bzoj3172 Ac自动机
根据fail树的性质 我们在建树的时候每建一个串就将他路径上的点全部加1表示这个串的后缀又出现了一次 然后从下到上把sum加起来就可以得到答案了 #include<cstdio> #inc ...
- JS之document例题讲解2
例题三.图片轮播 <body> <div style="width:1000px; height:250px; margin-top:30px"> < ...
- Quick-Cocos2dx-Community_3.6.3_Release 编译时libtiff.lib 无法解析
Quick-Cocos2dx-Community_3.6.3_Release 使用VS2012编译,报错: libtiff.lib lnk2001 无法解析的外部符号 ltod3 类似于上面这种,刚才 ...
- 用python玩微信(聊天机器人,好友信息统计)
1.用 Python 实现微信好友性别及位置信息统计 这里使用的python3+wxpy库+Anaconda(Spyder)开发.如果你想对wxpy有更深的了解请查看:wxpy: 用 Python 玩 ...
- IBM InfoSphere DataStage and QualityStage
Info coms from https://www.ibm.com/support/knowledgecenter/en/SSZJPZ_9.1.0/com.ibm.swg.im.iis.ds.nav ...