Spark standalone简介与运行wordcount(master、slave1和slave2)
前期博客
Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
1. Standalone模式
即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。从一定程度上说,该模式是其他两种的基础。借鉴Spark开发模式,我们可以得到一种开发新型计算框架的一般思路:先设计出它的standalone模式,为了快速开发,起初不需要考虑服务(比如master/slave)的容错性,之后再开发相应的wrapper,将stanlone模式下的服务原封不动的部署到资源管理系统yarn或者mesos上,由资源管理系统负责服务本身的容错。目前Spark在standalone模式下是没有任何单点故障问题的,这是借助zookeeper实现的,思想类似于Hbase master单点故障解决方案。将Spark standalone与MapReduce比较,会发现它们两个在架构上是完全一致的:
1) 都是由master/slaves服务组成的,且起初master均存在单点故障,后来均通过zookeeper解决(Apache MRv1的JobTracker仍存在单点问题,但CDH版本得到了解决);
2) 各个节点上的资源被抽象成粗粒度的slot,有多少slot就能同时运行多少task。不同的是,MapReduce将slot分为map
slot和reduce slot,它们分别只能供Map Task和Reduce
Task使用,而不能共享,这是MapReduce资源利率低效的原因之一,而Spark则更优化一些,它不区分slot类型,只有一种slot,可以供各种类型的Task使用,这种方式可以提高资源利用率,但是不够灵活,不能为不同类型的Task定制slot资源。总之,这两种方式各有优缺点。
Spark Standalone部署配置---Standalone架构

Spark Standalone部署配置---手工启动一个Spark集群
http://spark.apache.org/docs/latest/spark-standalone.html#starting-a-cluster-manually
这里,我带大家,看官网
http://spark.apache.org/docs/latest
http://spark.apache.org/docs/latest/spark-standalone.html
这里,我不多说,自行去看吧!
Spark Standalone部署配置---访问web ui
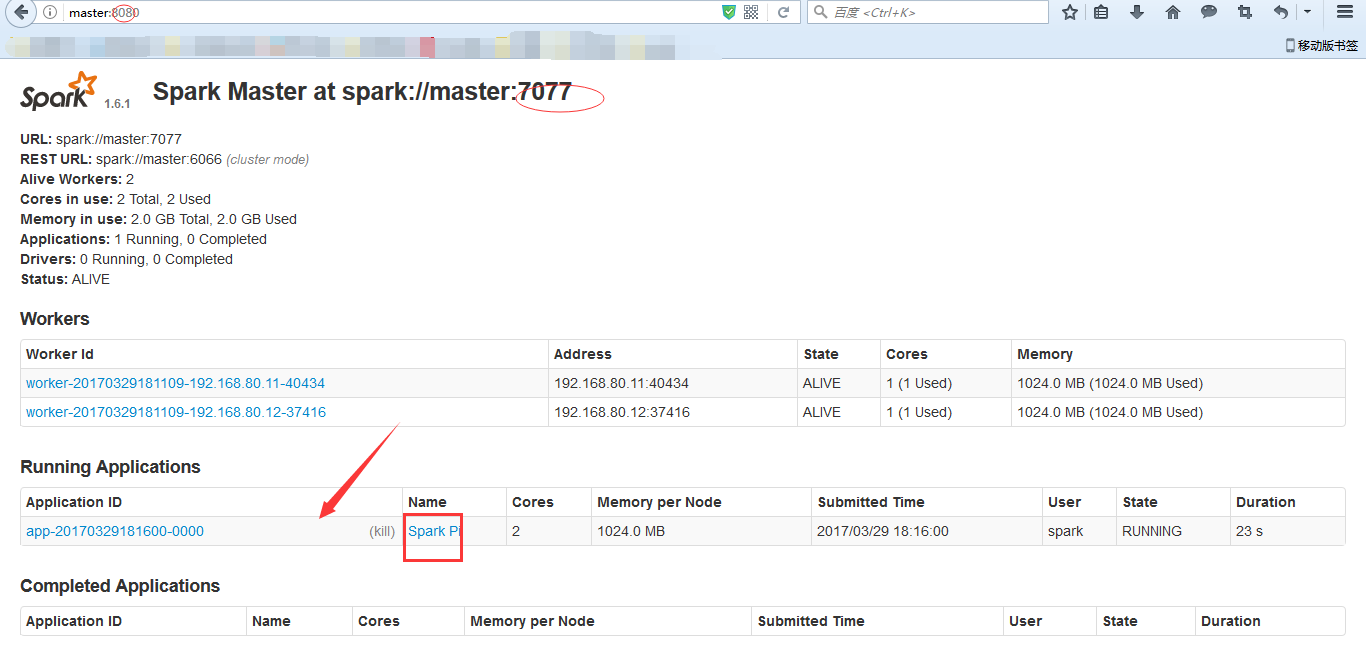
● 访问http://master:8080/(默认端口是8080,端口大家可以自己修改)
Job提交与运行
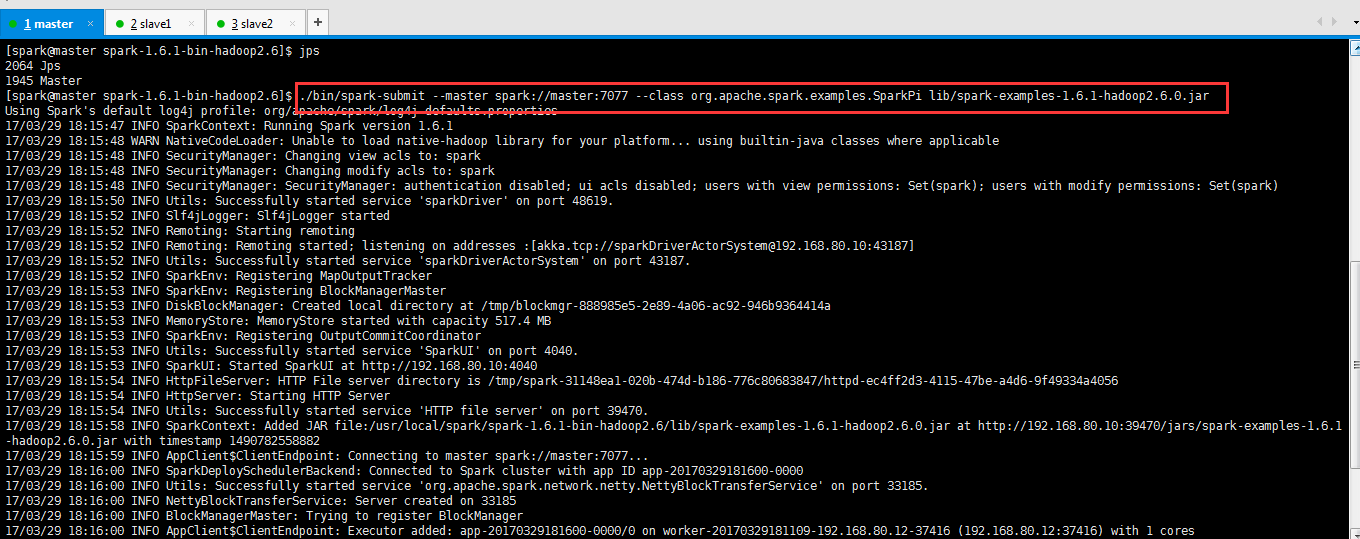
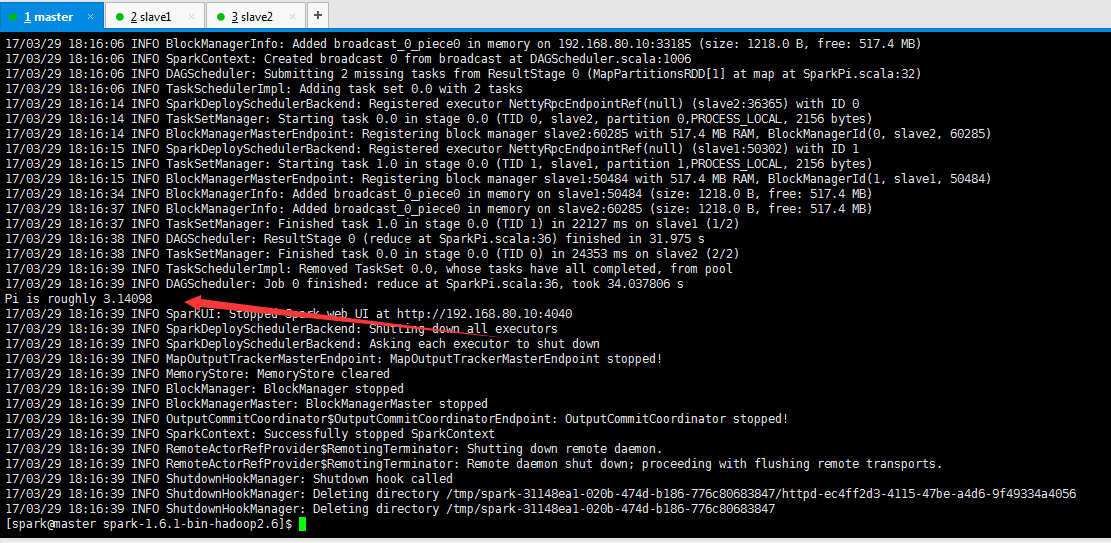
Job提交与运行---运行示例程序
$SPARK_HOME/bin/spark-submit \
--master spark://master:7077 \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar
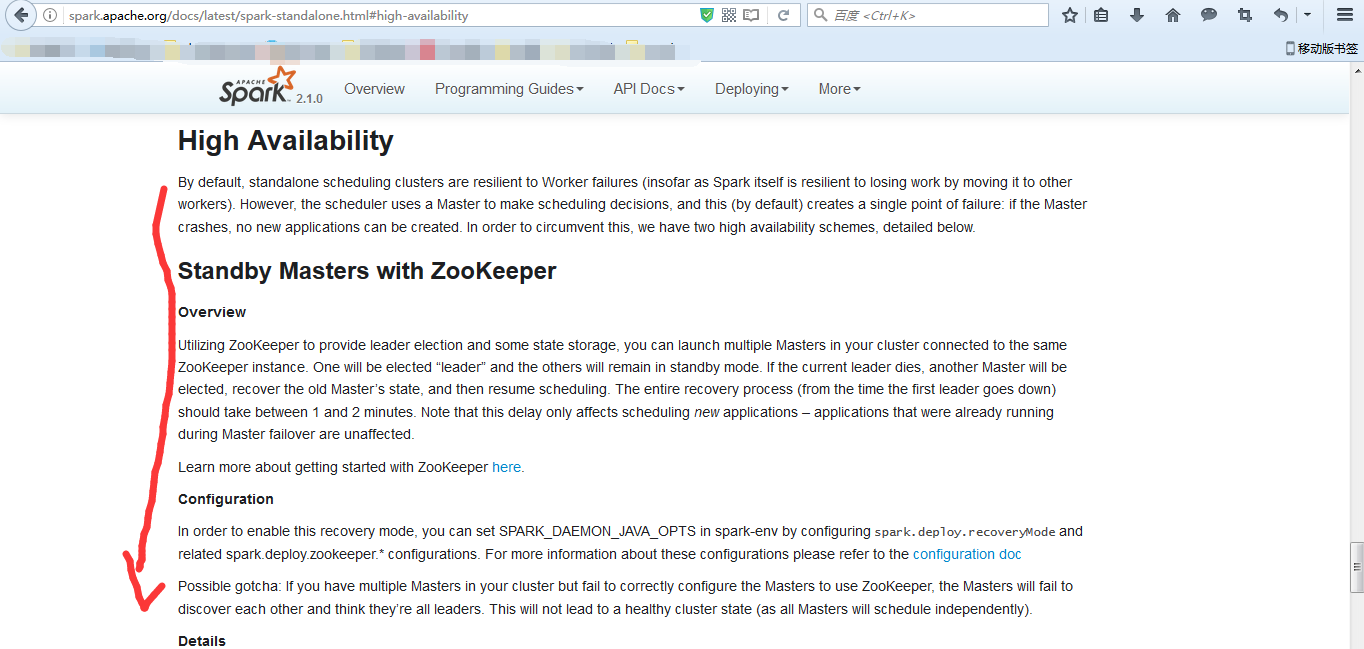
Spark Standalone HA
● Standby masters with Zookeeper
● Single-Node Recover with Local File System
http://spark.apache.org/docs/latest/spark-standalone.html#high-availability
但是,这里需。关于zookeeper的安装
我这里不多说,请移步
hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建(含zookeeper集群安装)
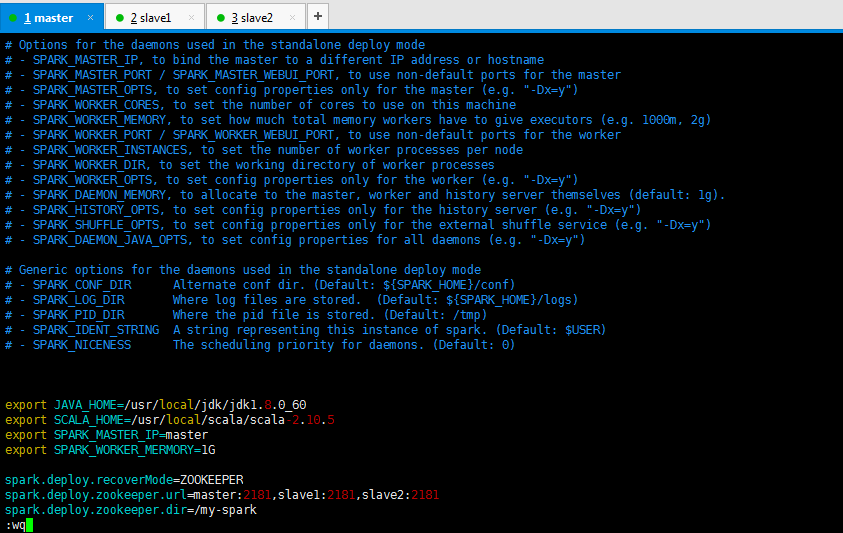
export JAVA_HOME=/usr/local/jdk/jdk1..0_60
export SCALA_HOME=/usr/local/scala/scala-2.10.
export SPARK_MASTER_IP=master
export SPARK_WORKER_MERMORY=1G spark.deploy.recoverMode=ZOOKEEPER
spark.deploy.zookeeper.url=master:,slave1:,slave2:
spark.deploy.zookeeper.dir=/my-spark
或者
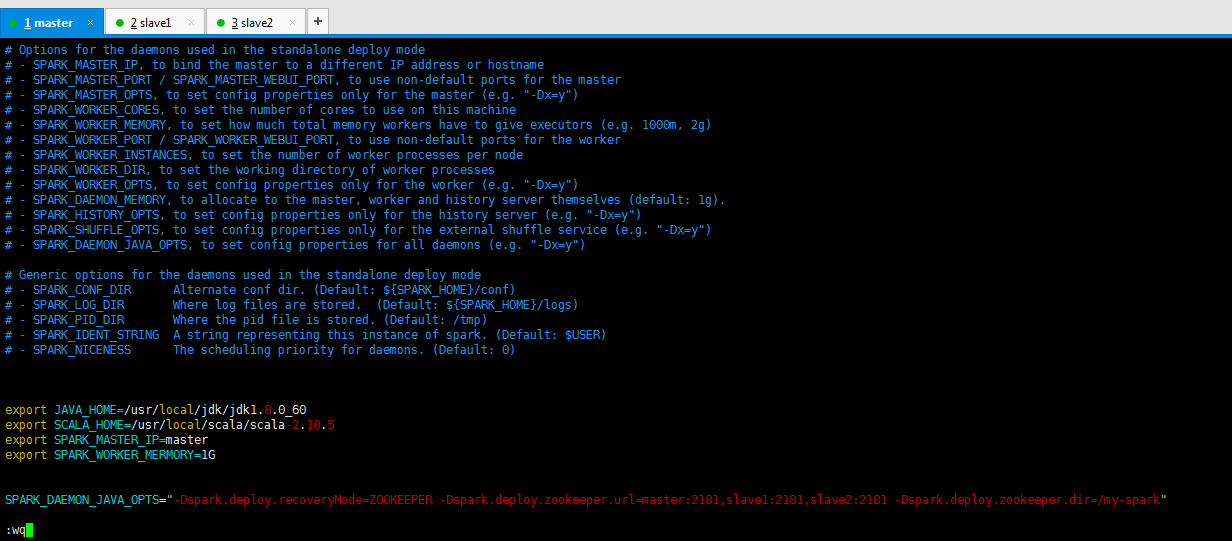
export JAVA_HOME=/usr/local/jdk/jdk1..0_60
export SCALA_HOME=/usr/local/scala/scala-2.10.
export SPARK_MASTER_IP=master
export SPARK_WORKER_MERMORY=1G SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/my-spark"
Spark Standalone运行架构解析
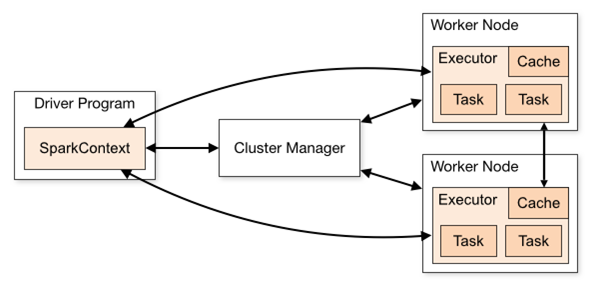
Spark Standalone运行架构解析---Spark基本工作流程
以SparkContext为程序运行的总入口,在SparkContext的初始化过程中,Spark会分别创建DAGScheduler作业调度和TaskScheduler任务调度两级调度模块。
其中作业调度模块是基于任务阶段的高层调度模块,它为每个Spark作业计算具有依赖关系的多个调度阶段(通常根据shuffle来划分),然后为每个阶段构建出一组具体的任务(通常会考虑数据的本地性等),然后以TaskSets(任务组)的形式提交给任务调度模块来具体执行。而任务调度模块则负责具体启动任务、监控和汇报任务运行情况。
Spark Standalone运行架构解析---Spark local模式
Local,本地模式,默认情况是本地模式运行,如运行的spark-shell,开发测试环境,运行任务命令:
$SPARK_HOME/bin/run-example org.apache.spark.examples.SparkPi local

LocalBackend响应Scheduler的receiveOffers请求,根据可用的CPU核的设定值[N]直接生成CPU资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表,其核心事件循环由内部类LocalActor以Akka Actor的消息处理形式来实现。
Spark Standalone运行架构解析---Spark local cluster模式
伪分布式模式启动两个Worker,每个Worker管理两个CPU核和1024MB的内存
$SPARK_HOME/bin/run-example org.apache.spark.examples.SparkPi local[2,2,1024]
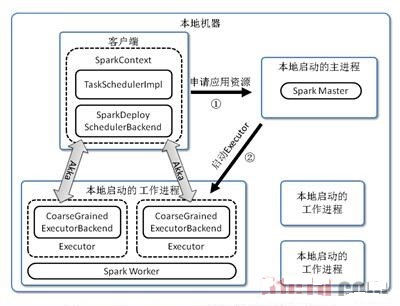
LocalBackend响应Scheduler的receiveOffers请求,根据可用的CPU核的设定值[N]直接生成CPU资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表,其核心事件循环由内部类LocalActor以Akka Actor的消息处理形式来实现
Spark Standalone运行架构解析---Spark standalone模式
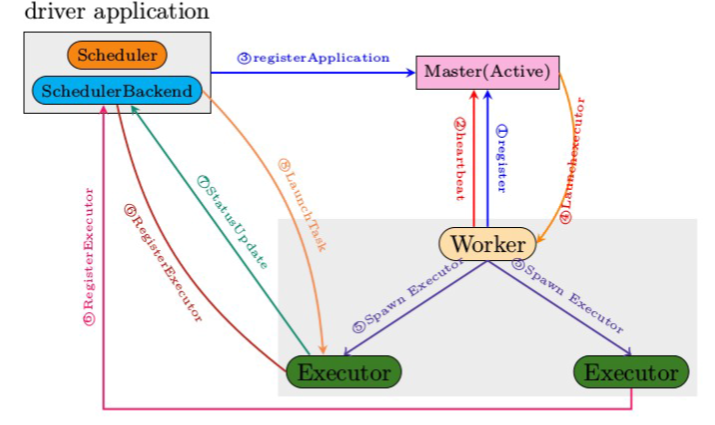
Spark Standalone运行架构解析---Spark standalone详细过程解析
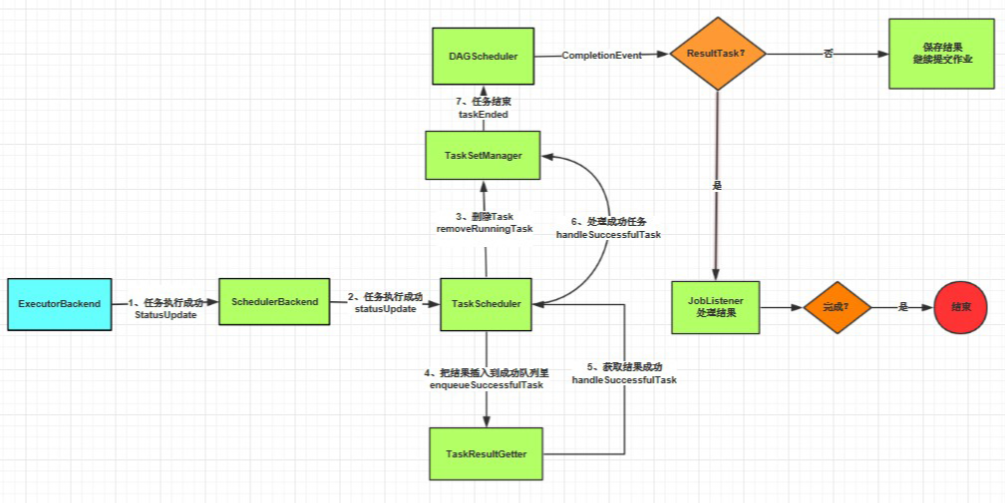
Spark Standalone 下运行wordcount
具体,请移步
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
● wordcount代码
● mvn 项目打包上传至Spark集群。
● Spark 集群提交作业
[spark@master hadoop-2.6.]$ $HADOOP_HOME/bin/hadoop fs -mkdir -p hdfs://master:9000/testspark/inputData/wordcount
[spark@master ~]$ mkdir -p /home/spark/testspark/inputData/wordcount
[spark@master hadoop-2.6.]$ $HADOOP_HOME/bin/hadoop fs -copyFromLocal /home/spark/testspark/inputData/wordcount/wc.txt hdfs://master:9000/testspark/inputData/wordcount/
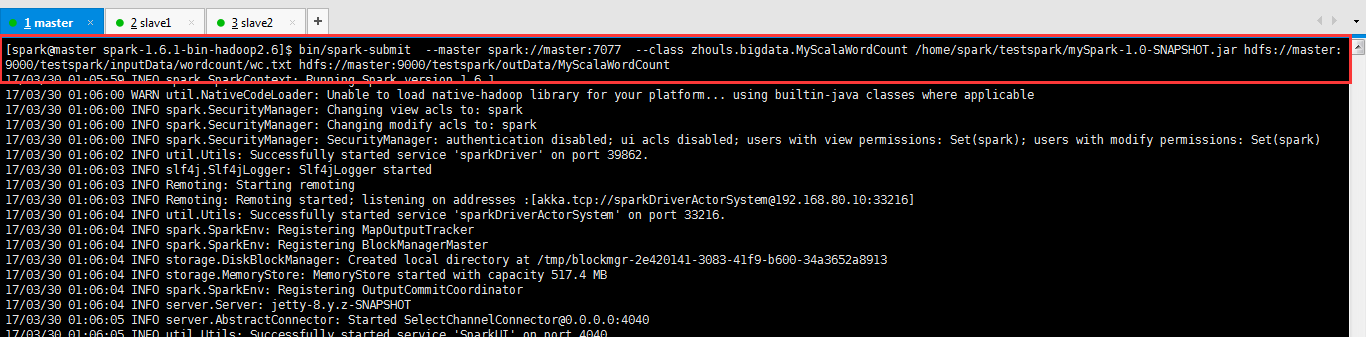
$SPARK_HOME/bin/spark-submit \
--master spark://master:7077 \
--class zhouls.bigdata.MyScalaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
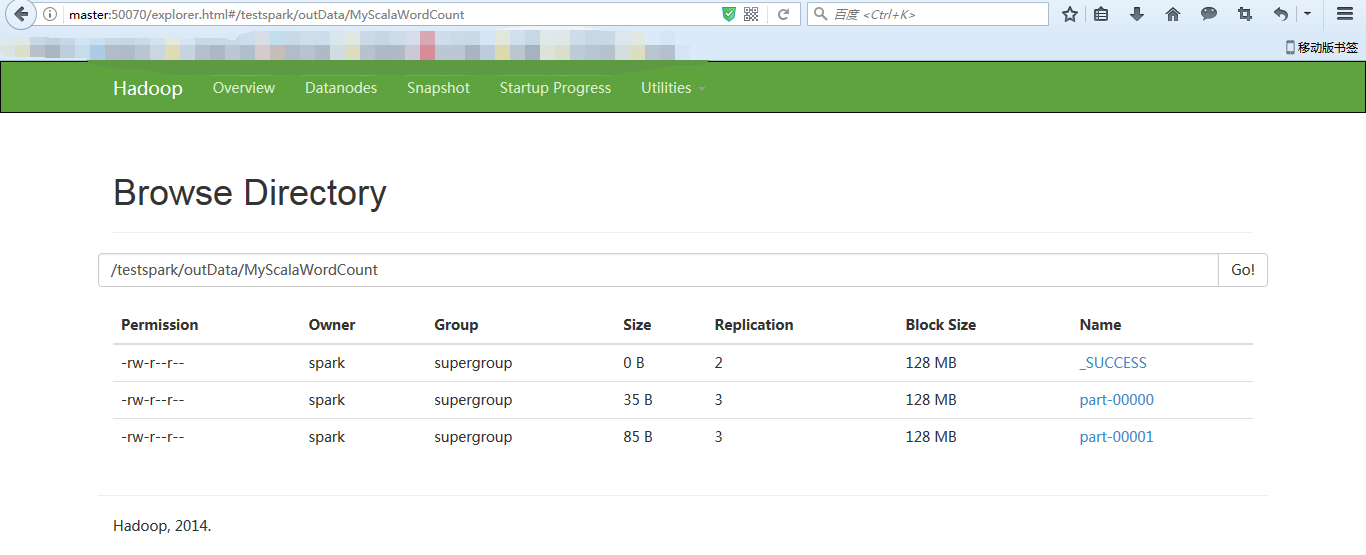
hdfs://master:9000/testspark/outData/MyScalaWordCount
或者
$SPARK_HOME/bin/spark-submit \
--master spark://master:7077 \
--class zhouls.bigdata.MyJavaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyJavaWordCount

具体,请移步
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
Spark Standalone HA下运行wordcount (这里我不演示了)
具体,请移步
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
● wordcount代码
● mvn 项目打包上传至Spark集群。
● Spark 集群提交作业
$SPARK_HOME/bin/spark-submit \
--master spark://master1:7077,master2:7077 \
--class zhouls.bigdata.MyScalaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyScalaWordCount
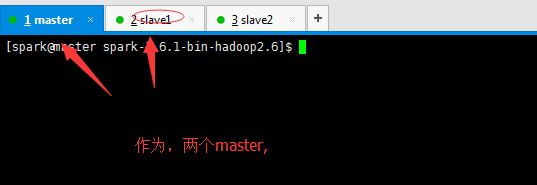
需要你搞两个master。比如。我这里。
或者
[spark@master spark-1.6.1-bin-hadoop2.6]$ bin/spark-submit \
--master spark://master1:7077,master2:7077 \ --class zhouls.bigdata.MyJavaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyJavaWordCount
Spark standalone简介与运行wordcount(master、slave1和slave2)的更多相关文章
- Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客 Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz +hadoop-2.6.0.tar.gz)(master.slave1和slave2)(博主 ...
- 大话Spark(5)-三图详述Spark Standalone/Client/Cluster运行模式
之前在 大话Spark(2)里讲过Spark Yarn-Client的运行模式,有同学反馈与Cluster模式没有对比, 这里我重新整理了三张图分别看下Standalone,Yarn-Client 和 ...
- Spark学习笔记-如何运行wordcount(使用jar包)
IDE:eclipse Spark:spark-1.1.0-bin-hadoop2.4 scala:2.10.4 创建scala工程,编写wordcount程序如下 package com.luoga ...
- Spark在Yarn上运行Wordcount程序
前提条件 1.CDH安装spark服务 2.下载IntelliJ IDEA编写WorkCount程序 3.上传到spark集群执行 一.下载IntellJ IDEA编写Java程序 1.下载IDEA ...
- Spark RDD简介与运行机制概述
RDD工作原理: 主要分为三部分:创建RDD对象,DAG调度器创建执行计划,Task调度器分配任务并调度Worker开始运行. SparkContext(RDD相关操作)→通过(提交作业)→(遍历RD ...
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客 Spark运行模式概述 Spark standalone简介与运行wordcount(master.slave1和slave2) 开篇要明白 (1)spark-env.sh 是环境变量配 ...
- Spark standalone运行模式(图文详解)
不多说,直接上干货! 请移步 Spark standalone简介与运行wordcount(master.slave1和slave2) Spark standalone模式的安装(spark-1.6. ...
- Spark standalone运行模式
Spark Standalone 部署配置 Standalone架构 手工启动一个Spark集群 https://spark.apache.org/docs/latest/spark-standalo ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
随机推荐
- Java多线程设计模式(四)
目录(?)[-] Future Pattern Two-Phase Termination Pattern Thread-Specific Storage Pattern Active Object ...
- 怎么用谷歌浏览器查看请求或响应HTTP头?
要使用谷歌浏览器查看请求或响应HTTP标头,可以采取以下步骤: 在Chrome浏览器,访问一个网址,点击右键,选择检查,打开开发人员工具(或直接按F12). 选择 Network 选项卡. 重新加载页 ...
- Partition--分区切换
现有数据表[dbo].[staging_TB1_20131018-104722]和分区表[dbo].[TB1],需要将分区表和数据表中做数据交换 CREATE TABLE [dbo].[staging ...
- NLP常用开源/免费工具
一些常见的NLP任务的开源/免费工具, *Computational Linguistics ToolboxCLT http://complingone.georgetown.edu/~linguis ...
- Qt keyPressEvent keyReleaseEvent 分析
最近使用Qt时,在增加一个按下某键(M),临时显示图层,键(M)弹起时隐藏图层的功能时,碰到了一些问题: keyPressEvent 事件不响应 这个问题,网上搜到的结果是可能是控件没获取焦点,比如Q ...
- RabbitMq初探——安装
rabbitmq Server安装 rabbitmq server安装很简单. 安装erlang环境 rpm -ihv erlang-18.1-1.el6.x86_64.rpm rpm -ihv ra ...
- [Maven实战-许晓斌]-[第二章]-2.1在Windows上安装maven
来源:<maven实战> 1.检查JAVA_HOME和java -version C:\Users\admin>echo %JAVA_HOME% C:\Users\admin&g ...
- SPOJ QTREE2 Query on a tree II
传送门 倍增水题…… 本来还想用LCT做的……然后发现根本不需要 //minamoto #include<bits/stdc++.h> using namespace std; #defi ...
- 模拟实现strstr和strrstr
strstr函数用于判断str2是否是str1的子串,如果是,则返回str2在str1中首次出现位置的地址,如果不是则返回NULL.其模拟实现代码如下:#include<iostream> ...
- ArchLinux 下安装 SecureCRT
相关说明: 上篇发了个Linux(Ubuntu) 下 SecureCRT 7 30天循环破解在启动的时候会多输入一次确认窗口, 后来maz-1网友留言说可以用Windows破解后程序替换Linux下的 ...