大数据(2) - Hadoop完全分布式的部署
** Hadoop介绍
** HDFS:分布式存储文件
角色:NameNode和DataNode
** YARN:分布式资源调度框架(Hadoop2.x以上才引用)
角色:ResourceManager和NodeManager
** MapReduce:分布式数据处理框架
一、下载hadoop拉到linux中,并解压到指定目录
tips:用smb把hadoop压缩包从window拉到linux时,请注意smb的登陆用户,会导致后面一堆坑,慎用root登陆smb。
(1)将压缩包拉到/home/admin/softwares/installtions/目录
(2) 解压到/home/admin/modules目录
tar -zxf hadoop-2.7.2.tar.gz -C /home/admin/modules/
二、配置环境变量
vim /etc/profile 在最下面添加 export HADOOP_HOME=/home/admin/modules/hadoop-2.7.2/bin
export PATH=$PATH:$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" 保存退出后 source /etc/profile
配置成功后可用 hadoop version 查看版本,注意没有横杠!
三、配置
** 最终配置效果:
linux01:namenode、datanode、nodemanager
linux02:resourcemanager 、datanode 、nodemanager
linux03:datanode、nodemanager
(1)删除windows脚本
** 进入到hadoop的etc/hadoop目录下 $ rm -rf *.cmd
(2)重命名文件
$ mv mapred-site.xml.template mapred-site.xml
(3)配置evn文件
查看java路径:
echo $JAVA_HOME,我的机器:/home/admin/modules/jdk1.8.0_131

配置hadoop-env.sh
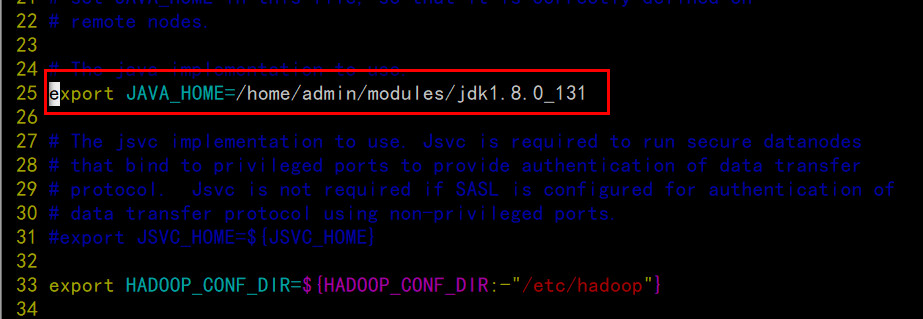
配置yarn-env.sh
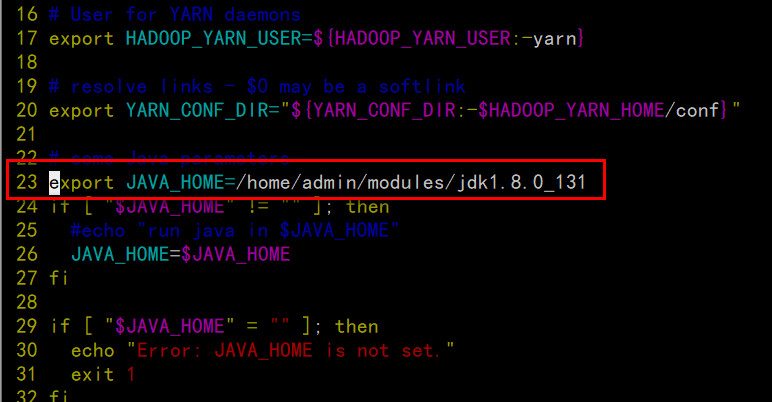
配置mapred-env.sh

(4)配置site文件
配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux01:8020</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/admin/modules/hadoop-2.7.2/hadoop-data</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!-- 指定数据冗余份数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property> <property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux03:50090</value>
</property> <property>
<name>dfs.namenode.http-address</name>
<value>linux01:50070</value>
</property> <property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.resourcemanager.hostname</name>
<value>linux02</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property> <property>
<name>yarn.log.server.url</name>
<value>http://linux01:19888/jobhistory/logs/</value>
</property> </configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>linux01:10020</value>
</property> <!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>linux01:19888</value>
</property>
</configuration>
(5)配置slaves文件

四、分发安装配置完成的hadoop到linux02以及linux03
$ scp -r hadoop-2.7.2/ linux02:/home/admin/modules/
$ scp -r hadoop-2.7.2/ linux03:/home/admin/modules/
五、 格式化namenode(在hadoop-2.7.2的根目录下执行)
$ bin/hdfs namenode -format
如果正常格式化会生成haddop-data文件夹
六、启动服务
HDFS:(linux01)
$ sbin/start-dfs.sh
YARN:(一定要在ResourceManager所在机器启动,linux02)
$ sbin/start-yarn.sh
JobHistoryServer:(linux01)
$ ssh admin@linux01 '/home/admin/modules/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver'
常见启动失败情况:
(1)hadoop处于安全模式,namenode启动失败,参考链接
解决:磁盘空间不足,需要手动释放资源后再用命令 hdfs dfsadmin -safemode leave 离开安全模式
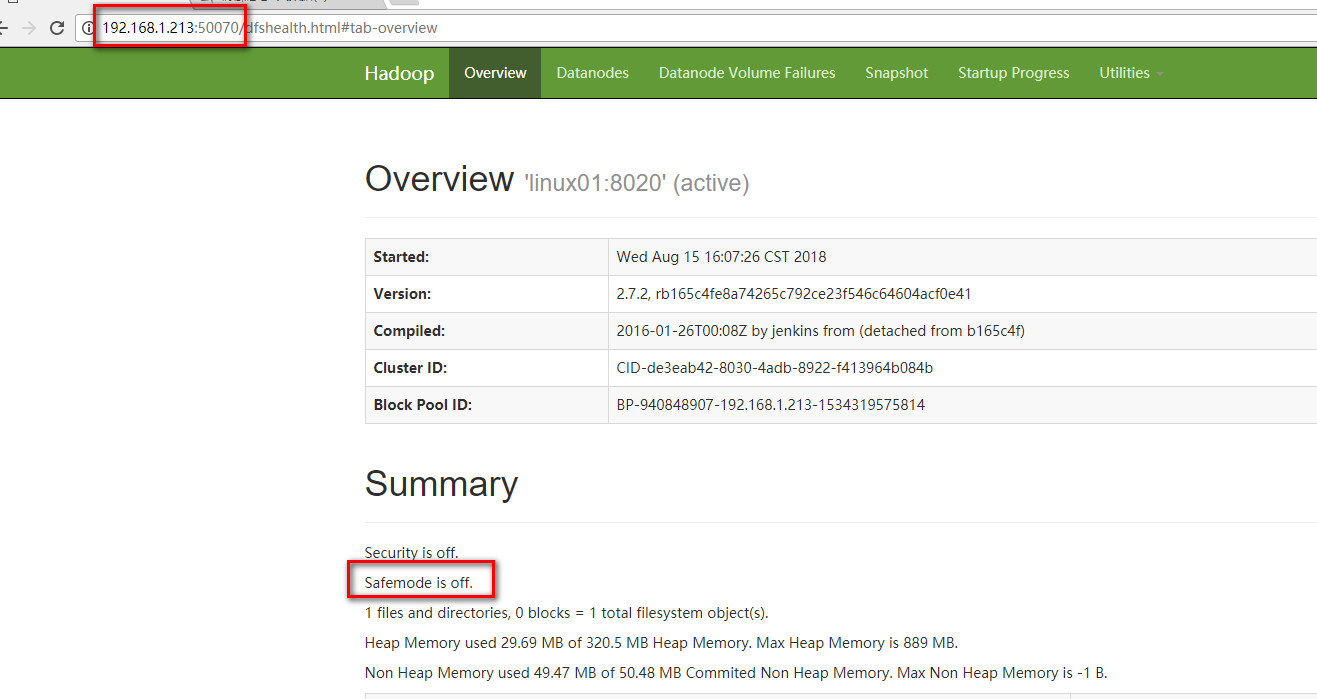
全部完成后查看:
在浏览器输入192.168.1.213:50070,如果不在安全模式证明namenode启动正常
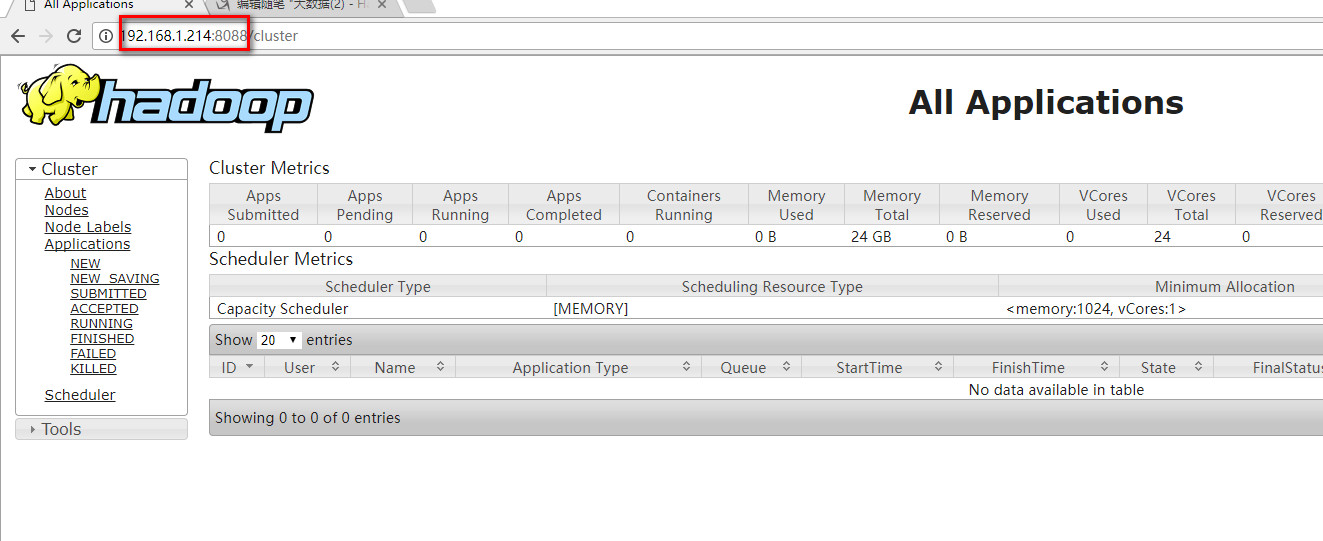
输入192.168.1.214:8088
七、关闭全部服务
$ sbin/stop-all.sh
八、将系统变量追加到用户变量中(3台机器都要操作)
$ cd ~ $ cat /etc/profile >> .bashrc
生效 $ source ~/.bashrc
九、编写脚本批量操作三台机器
$ cd ~
$ mkdir tools
$ vim /tools/jpsutil.sh 添加批量查看jps服务的脚本 #!/bin/bash
for i in admin@linux01 admin@linux02 admin@linux03
do
echo "==================$i==================="
ssh $i 'jps'
done 保存后查看 sh jpsutil.sh
十、遇到问题
关闭虚拟机后重启,重启集群时,namenode启动失败,需要使用命令:bin/hdfs namenode -format
格式化,才能启动。
格式化后datanode又有异常,需要把/hadoop-2.7.2/hadoop-data/dfs/name/current/VERSION里面的clusterID复制下来,依次替换/hadoop-2.7.2/hadoop-data/dfs/data/current/VERSION里的clusterID,再执行:sbin/hadoop-daemon.sh start datanode(全部机器都要操作)。
格式化会导致集群原本存储的数据全部丢失,如何正常关机后,正常开启集群,这个有待研究。
大数据(2) - Hadoop完全分布式的部署的更多相关文章
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- 大数据和Hadoop时代的维度建模和Kimball数据集市
小结: 1. Hadoop 文件系统中的存储是不可变的,换句话说,只能插入和追加记录,不能修改数据.如果你熟悉的是关系型数据仓库,这看起来可能有点奇怪.但是从内部机制看,数据库是以类似的机制工作,在一 ...
- 大数据与Hadoop
figure:first-child { margin-top: -20px; } #write ol, #write ul { position: relative; } img { max-wid ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
随机推荐
- How to publish a WordPress blog to a static GitLab Pages site
https://opensource.com/article/18/8/publish-wordpress-static-gitlab-pages-site A long time ago, I se ...
- taglib.jsp
<%@ taglib prefix="shiro" uri="/WEB-INF/tlds/shiros.tld" %><%@ taglib p ...
- animateBackground-plugin
(function ($) { if (!document.defaultView || !document.defaultView.getComputedStyle) { var oldCurCSS ...
- Node.js 2017.11.5-2017.11.16期间制作的图片爬虫总结
2017年11月18日12:33:06
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- wifi简单笔记
什么是wifi: Wi-Fi是一种可以将个人电脑.手持设备(如PDA.手机)等终端以无线方式互相连接的技术.Wi-Fi是一个无线网路通信技术的品牌,由Wi-Fi联盟(Wi-Fi Alliance)所持 ...
- 如何使用angularjs实现表单验证
<!DOCTYPE html> <html ng-app="myApp"> <head> <title>angularjs-vali ...
- git push --set-upstream origin
设置本地分支追踪远程分支 之后就可以直接使用git push提交代码
- swagger 生成的接口文档,隐藏接口的某个参数
[问题描述] controller 中的处理请求的方法,有时候会添加一些额外的参数.比如下面代码中 UserVo: @PostMapping(value = "/add-office-par ...
- linux系统常用命令 -设置文件夹读写权限
设置文件夹的读写权限: sudo chmod -R 777 /data 权限码描述 sudo chmod 600 ××× (只有所有者有读和写的权限)sudo chmod 644 ××× (所有者有读 ...